.NET Managed + C unmanaged: what is the price?
When programming in C #, I often put out resource-intensive tasks in unmanaged C code, because the performance of .NET caused questions. And over a cup of tea, the following questions began to go to my mind: What is the real gain from this code separation? Is it possible to win something, and if so how much? What is the best way to build an API with this approach?
After some time, I still took the time to study this issue in more detail, and I want to share my observations with you.
What for?
This question will be asked by any self-respecting programmer. To run the project in two different languages is a very dubious business, especially unmanaged code is really difficult to implement, debug and support. But only the ability to implement functionality that will work faster is worthy of consideration, especially in critical areas or in highly loaded applications.
')
Another possible answer: the functionality is already implemented in the unamaged form! Why rewrite the solution entirely, if you can not wrap everything in .NET and use it from there, not at a very high cost?
In a nutshell - this really happens. And we just see what and how.
Lyrics
All code was written in Visual Studio Community 2015. For evaluation, I used my work-gaming computer, with i5-3470 on board, 12-gigabytes of 1333MHz dual-channel RAM, and also a hard disk at 7200 rpm. Measurements were made using System.Diagnostics.Stopwatch, which is more accurate to DateTime, because it is implemented on top of PerformanceCounter. The tests were run on the Release versions of the builds to eliminate the possibility that in reality everything will be a little different. The version of the .NET framework 4.5.2, and the C ++ project was compiled with the / TC flag (Compile as C).
I apologize in advance for the abundance of code, but without it it will be difficult to understand exactly what I wanted. Most of the too tedious or insignificant code I took out into spoilers, and the other part was cut out of the article altogether (initially it was even longer).
Function call
I decided to start my research with measuring the speed of calling functions. There were several reasons for this. First, the functions will still have to be called, and the functions from the loaded dll are not called very quickly, compared to the code in the same module. Secondly, most of the existing C # wrappers are implemented on top of any unmanaged code (for example, sharpgl , openal-cs ,and sharpdx has gone the wrong way ). Actually, this is the most obvious way to embed unmanaged code, and the easiest one.
Before you start measuring directly, you need to think about how we will store and evaluate the results of our measurements. “CSV!”, I thought, and wrote a simple class for storing data in this format:
Not the most functional option, but for my purpose it will go with interest. And for testing, it was decided to write a simple class that can only summarize the numbers and store the result. This is how it looks like:
But this is a manageable option. We also need more uncontrollable. Therefore, we create a template dll project and immediately add a file there, for example, api.h, into which we push export definitions:
Let us put summer.c alongside, and implement all the functionality we need:
Now we need a wrapper class over this disgrace:
The result was exactly what I wanted. There are two absolutely identical implementations to use: one in C #, the second in C. Now you can and see what comes of it! Let's write a code that measures the execution time of n calls of one and another class:
It remains only to call this function somewhere in Maine, and look at the report in fun_call.csv. For clarity, I will not give the boring and dry numbers, but will only display a graph. Vertically - time in ticks, horizontally - the number of function calls.
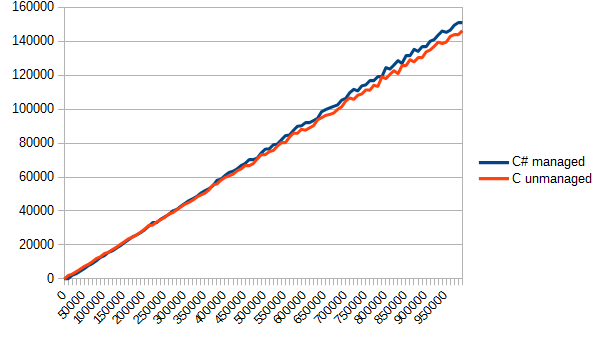
The result surprised me a little. C # was clearly the favorite in this test. Still, the same module, and the ability to inline ... but as a result, both options turned out to be approximately the same. Actually, in this case, this separation of the code turned out to be meaningless - they did not win anything, and the project was complicated.
Arrays
Reflections on the results were not long, and I immediately realized that you need to send data not in a single element, but in arrays. It's time to upgrade the code. We add a functional:
And, actually, C part:
Accordingly, it was necessary to rewrite the function of measuring performance. The full version is in the spoiler, and in two words: now we generate an array of n random elements and call the function of their addition.
Run, check the report. Vertically, there is still time in ticks, horizontally - the number of elements in the array.
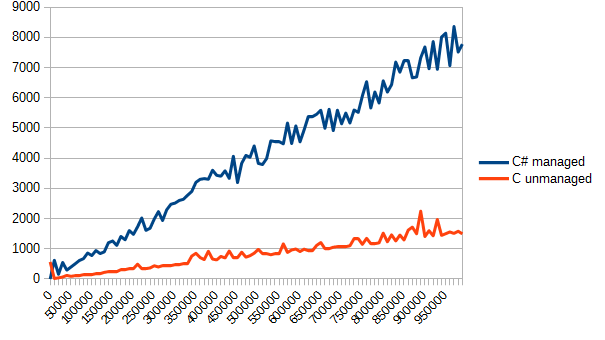
It can be seen with the naked eye - C copes with banal processing of arrays much better. But this is the price for “controllability” - while the managed code in the event of overflow, overrun of the array,mismatch of the moon phase with the phase of Mars gently throws an exception, then the C code can easily overwrite its memory and pretend that's the way it should be.
Reading file
After making sure to process large data arrays in C faster, I decided to read the files. This decision was caused by the desire to check how quickly the code can communicate with the system.
For these purposes, I generated a stack of files (of course, linearly increasing in size)
As a result, the largest file turned out 75 megabytes, which was quite enough for yourself. For the test, I did not allocate a separate class, and on thecattle is a coded directly into the Maine class. Why not, actually.
As you can see from the code, I set the task as follows: sum up all the integers from the file. Relevant implementation in C:
Now it remains to cyclically read all the files, but measure the speed of each implementation. I will not give the code of the measurement function (I can make it myself) and proceed directly to visual demonstrations.
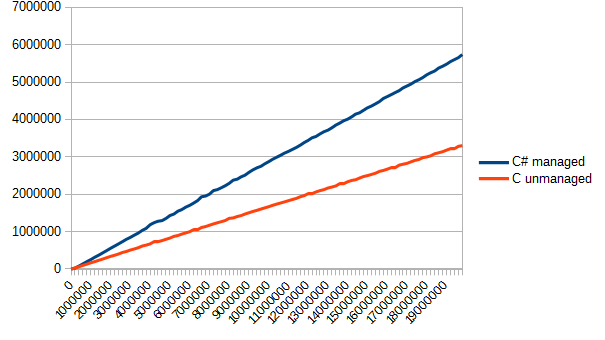
As can be seen from this graph, C was a little faster (about one and a half times). But winning is winning.
Somewhere at this moment I was carried a little to the steppe (or somewhere else), but I cannot not share these thoughts. Curious please spoiler, and all the rest, please go to the next part of my research.
Return arrays
The next step in performance measurements was the return of more complex types, because it would not always be convenient to communicate with integers and floating point numbers. Therefore, you need to check how quickly you can bring unmanaged memory to managed. To this end, it was decided to implement a simple task: reading the entire file and returning its contents as an array of bytes.
On pure C #, such a task is implemented quite simply, but in order to associate C code with C # code, in this case you will have to do something else.
First, a C # solution
And the corresponding decision on C:
To successfully call such a function from C #, we will have to write a wrapper that will call this function, copy the data from the unmanaged memory to the managed one, and free the unmanaged section:
In the measurement function, only the corresponding calls of the measured functions have changed. And the result looks like this:
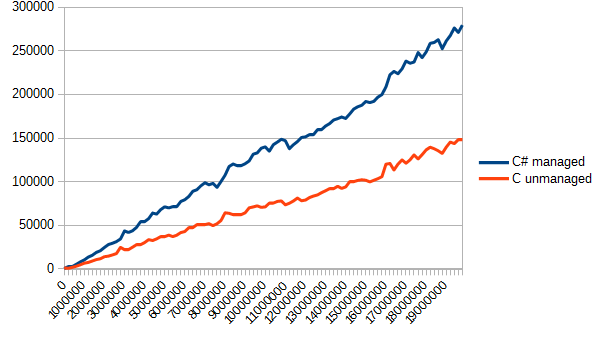
Even with the loss of time to copy the memory, C again found himself in the lead, completing the task about 2 times faster. Honestly, I expected some other results (considering the data of the second test). Most likely due to the fact that reading data, even in a large packet in C #, is quite slow. In C, the loss of time goes by copying unmanaged memory into managed memory.
Real challenge
The logical conclusion of all the tests I carried out was this: to implement some full-fledged algorithm in C # and in C. Performance rate to evaluate.
I took the reading of an uncompressed TGA file with 32 bits per pixel, and casting it into anormal RGBA representation (TGA format implies storing color as BGRA). So that life does not seem to be oil, we will return not bytes, but Color structures:
The implementation of the algorithm is quite capacious, and it is hardly interesting. Therefore, it is taken out in the spoiler so as not to be an insult to those who are not interested.
Now it's up to small. Draw a simple TGA image and load it n times. The result is as follows (vertically as usual, horizontally - the number of file reads).
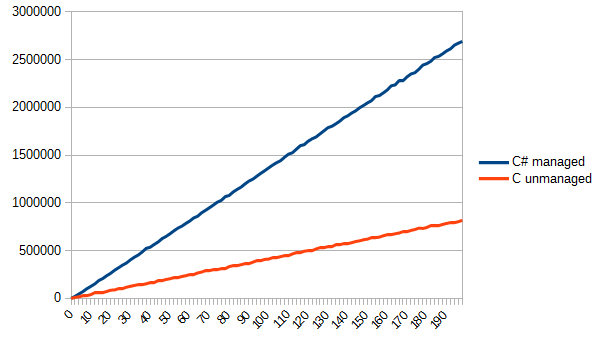
Here it should be noted that I brazenly used the possibilities of C in his favor. Reading from the file directly into the structures has made life much easier (and in the case when the structures are not aligned with 4 bytes, there will be fun debugging). However, I am pleased with the result. Such an uncomplicated algorithm turned out to be efficiently implemented in C, and effectively used in C #. Accordingly, I received an answer to the original question: you can really win, but not always. Sometimes you can win slightly, sometimes not win at all, and sometimes win several times and more.
Dry residue
In general, the very idea of carrying out the implementation of something in another language is doubtful, as I wrote at the very beginning. In the end, the application of this method of code acceleration can be found quite a bit. If opening a file starts to hang UI - you can put the download in a separate background thread, and then loading even per second will not cause anyone serious difficulties.
Accordingly, it is worthwhile to pervert so only when productivity is really necessary, and it is no longer possible to achieve it in other ways (and in such cases they usually write right away to C or C ++). Or if you already have a ready-made algorithm that you can use, and not reinvent the wheel.
It should be noted that a simple wrapper over an unmanaged dll will not give much performance gain, and all the “nimbleness” of unmanaged languages begins to be revealed only when processing large enough data, so you should also pay attention to this. However, the use of such a wrapper will not become worse.
C # does very well with the transfer of managed resources to unmanaged code, but the reverse is not as fast as we would like. Therefore, frequent data conversion is desirable to avoid and keep unmanaged resources in unmanaged code. If it is not necessary to edit / read this data in managed code, then IntPtr can be used to store pointers, and the rest of the work can be rendered entirely in unmanaged code.
Of course, it is possible (and even necessary) to conduct additional research before making a final decision on the transfer of code to unmanaged assemblies. But with current information you can decide on the appropriateness of such actions.
And on this I have everything. Thank you if you have read to the end!
After some time, I still took the time to study this issue in more detail, and I want to share my observations with you.
What for?
This question will be asked by any self-respecting programmer. To run the project in two different languages is a very dubious business, especially unmanaged code is really difficult to implement, debug and support. But only the ability to implement functionality that will work faster is worthy of consideration, especially in critical areas or in highly loaded applications.
')
Another possible answer: the functionality is already implemented in the unamaged form! Why rewrite the solution entirely, if you can not wrap everything in .NET and use it from there, not at a very high cost?
In a nutshell - this really happens. And we just see what and how.
Lyrics
All code was written in Visual Studio Community 2015. For evaluation, I used my work-gaming computer, with i5-3470 on board, 12-gigabytes of 1333MHz dual-channel RAM, and also a hard disk at 7200 rpm. Measurements were made using System.Diagnostics.Stopwatch, which is more accurate to DateTime, because it is implemented on top of PerformanceCounter. The tests were run on the Release versions of the builds to eliminate the possibility that in reality everything will be a little different. The version of the .NET framework 4.5.2, and the C ++ project was compiled with the / TC flag (Compile as C).
I apologize in advance for the abundance of code, but without it it will be difficult to understand exactly what I wanted. Most of the too tedious or insignificant code I took out into spoilers, and the other part was cut out of the article altogether (initially it was even longer).
Function call
I decided to start my research with measuring the speed of calling functions. There were several reasons for this. First, the functions will still have to be called, and the functions from the loaded dll are not called very quickly, compared to the code in the same module. Secondly, most of the existing C # wrappers are implemented on top of any unmanaged code (for example, sharpgl , openal-cs ,
Before you start measuring directly, you need to think about how we will store and evaluate the results of our measurements. “CSV!”, I thought, and wrote a simple class for storing data in this format:
Simple implementation of CSV
public class CSVReport : IDisposable { int columnsCount; StreamWriter writer; public CSVReport(string path, params string[] header) { columnsCount = header.Length; writer = new StreamWriter(path); writer.Write(header[0]); for (int i = 1; i < header.Length; i++) writer.Write("," + header[i]); writer.Write("\r\n"); } public void Write(params object[] values) { if (values.Length != columnsCount) throw new ArgumentException("Columns count for row didn't match table columns count"); writer.Write(values[0].ToString()); for (int i = 1; i < values.Length; i++) writer.Write("," + values[i].ToString()); writer.Write("\r\n"); } public void Dispose() { writer.Close(); } } Not the most functional option, but for my purpose it will go with interest. And for testing, it was decided to write a simple class that can only summarize the numbers and store the result. This is how it looks like:
class Summer { public int Sum { get; private set; } public Summer() { Sum = 0; } public void Add(int a) { Sum += a; } public void Reset() { Sum = 0; } } But this is a manageable option. We also need more uncontrollable. Therefore, we create a template dll project and immediately add a file there, for example, api.h, into which we push export definitions:
#ifndef _API_H_ #define _API_H_ #define EXPORT __declspec(dllexport) #define STD_API __stdcall #endif Let us put summer.c alongside, and implement all the functionality we need:
#include "api.h" int sum; EXPORT void STD_API summer_init( void ) { sum = 0; } EXPORT void STD_API summer_add( int value ) { sum += value; } EXPORT int STD_API summer_sum( void ) { return sum; } Now we need a wrapper class over this disgrace:
class SummerUnmanaged { const string dllName = @"unmanaged_test.dll"; [DllImport(dllName)] private static extern void summer_init(); [DllImport(dllName)] private static extern void summer_add(int v); [DllImport(dllName)] private static extern int summer_sum(); public int Sum { get { return summer_sum(); } } public SummerUnmanaged() { summer_init(); } public void Add(int a) { summer_add(a); } public void Reset() { summer_init(); } } The result was exactly what I wanted. There are two absolutely identical implementations to use: one in C #, the second in C. Now you can and see what comes of it! Let's write a code that measures the execution time of n calls of one and another class:
static void TestCall() { Console.WriteLine("Function calls..."); Stopwatch sw = new Stopwatch(); Summer s_managed = new Summer(); SummerUnmanaged s_unmanaged = new SummerUnmanaged(); Random r = new Random(); int[] data; CSVReport report = new CSVReport("fun_call.csv", "elements", "C# managed", "C unmanaged"); data = new int[1000000]; for (int j = 0; j < 1000000; j++) data[j] = r.Next(-1, 2); // for (int i=0; i<100; i++) { // Console.Write("\r{0}/100", i+1); int length = 10000*i; long managedTime = 0, unmanagedTime = 0; Thread.Sleep(10); s_managed.Reset(); sw.Start(); for (int j = 0; j < length; j++) { s_managed.Add(data[j]); } sw.Stop(); managedTime = sw.ElapsedTicks; sw.Reset(); sw.Start(); for(int j=0; j<length; j++) { s_unmanaged.Add(data[j]); } sw.Stop(); unmanagedTime = sw.ElapsedTicks; report.Write(length, managedTime, unmanagedTime); } report.Dispose(); Console.WriteLine(); } It remains only to call this function somewhere in Maine, and look at the report in fun_call.csv. For clarity, I will not give the boring and dry numbers, but will only display a graph. Vertically - time in ticks, horizontally - the number of function calls.
The result surprised me a little. C # was clearly the favorite in this test. Still, the same module, and the ability to inline ... but as a result, both options turned out to be approximately the same. Actually, in this case, this separation of the code turned out to be meaningless - they did not win anything, and the project was complicated.
Arrays
Reflections on the results were not long, and I immediately realized that you need to send data not in a single element, but in arrays. It's time to upgrade the code. We add a functional:
public void AddMany(int[] data) { int length = data.Length; for (int i = 0; i < length; i++) Sum += i; } And, actually, C part:
EXPORT int STD_API summer_add_many( int* data, int length ) { for ( int i = 0; i < length; i++ ) sum += data[ i ]; } [DllImport(dllName)] private static extern void summer_add_many(int[] data, int length); public void AddMany(int[] data) { summer_add_many(data, data.Length); } Accordingly, it was necessary to rewrite the function of measuring performance. The full version is in the spoiler, and in two words: now we generate an array of n random elements and call the function of their addition.
New performance measurement feature
static void TestArrays() { Console.WriteLine("Arrays..."); Stopwatch sw = new Stopwatch(); Summer s_managed = new Summer(); SummerUnmanaged s_unmanaged = new SummerUnmanaged(); Random r = new Random(); int[] data; CSVReport report = new CSVReport("arrays.csv", "elements", "C# managed", "C unmanaged"); for (int i = 0; i < 100; i++) { Console.Write("\r{0}/100", i+1); int length = 10000 * i; long managedTime = 0, unmanagedTime = 0; data = new int[length]; for (int j = 0; j < length; j++) // data[j] = r.Next(-1, 2); s_managed.Reset(); sw.Start(); s_managed.AddMany(data); sw.Stop(); managedTime = sw.ElapsedTicks; sw.Reset(); sw.Start(); s_unmanaged.AddMany(data); sw.Stop(); unmanagedTime = sw.ElapsedTicks; report.Write(length, managedTime, unmanagedTime); } report.Dispose(); Console.WriteLine(); } Run, check the report. Vertically, there is still time in ticks, horizontally - the number of elements in the array.
It can be seen with the naked eye - C copes with banal processing of arrays much better. But this is the price for “controllability” - while the managed code in the event of overflow, overrun of the array,
Lyrics
By the way, I could not come to a reasonable conclusion about why the graphics are so uneven. Probably, GC phases or other processes eat up CPU time, but this is not accurate. Nevertheless, even a simple averaging shows that C is many times faster in a particular case.
Reading file
After making sure to process large data arrays in C faster, I decided to read the files. This decision was caused by the desire to check how quickly the code can communicate with the system.
For these purposes, I generated a stack of files (of course, linearly increasing in size)
Generating files
static void Generate() { Random r = new Random(); for(int i=0; i<100; i++) { BinaryWriter writer = new BinaryWriter(File.OpenWrite("file" + i.ToString())); for(int j=0; j<200000*i; j++) { writer.Write(r.Next(-1, 2)); } writer.Close(); Console.WriteLine("Generating {0}", i); } } As a result, the largest file turned out 75 megabytes, which was quite enough for yourself. For the test, I did not allocate a separate class, and on the
static int FileSum(string path) { BinaryReader br = new BinaryReader(File.OpenRead(path)); int sum = 0; long length = br.BaseStream.Length; while(br.BaseStream.Position != length) { sum += br.ReadInt32(); } br.Close(); return sum; } As you can see from the code, I set the task as follows: sum up all the integers from the file. Relevant implementation in C:
EXPORT int STD_API file_sum( const char* path ) { FILE *f = fopen( path, "rb" ); if ( !f ) return 0; int sum = 0; while ( !feof( f ) ) { int add; fread( &add, sizeof( int ), 1, f ); sum += add; } fclose( f ); return sum; } Now it remains to cyclically read all the files, but measure the speed of each implementation. I will not give the code of the measurement function (I can make it myself) and proceed directly to visual demonstrations.
As can be seen from this graph, C was a little faster (about one and a half times). But winning is winning.
Somewhere at this moment I was carried a little to the steppe (or somewhere else), but I cannot not share these thoughts. Curious please spoiler, and all the rest, please go to the next part of my research.
Steppe
The time of reading the files terrified me. An experienced programmer will immediately tell you what is wrong with my code - it too often accesses the system for data from a file. It is slow, very slow. As a result, I slightly upgraded the reading algorithm, adding forced buffering to 400Kb of data from the file, which noticeably accelerated everything. Relevant changes in C and C # code:
I did not want to include this test in the “basis” of the article, and there was one reason for this: the test is not entirely fair. C was obviously better suited for such a task, because he could write anything and anywhere, but in C # I had to convert everything byte-by-by, because of what I got what I got:
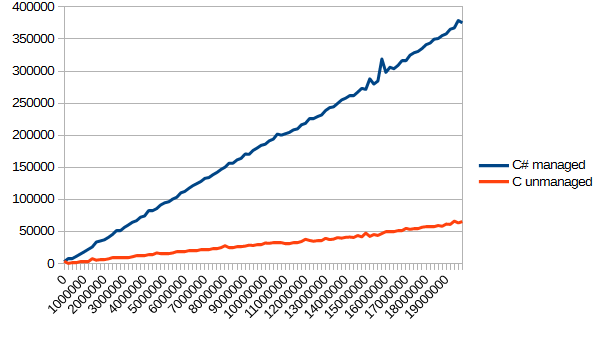
I am inclined to think that such a performance difference is caused precisely by the need to additionally convert bytes into words. In general, this topic deserves a separate article, which I can even write.
long length = br.BaseStream.Length; byte[] buffer = new byte[100000*4]; while(br.BaseStream.Position != length) { int read = br.Read(buffer, 0, 100000*4); for(int i=0; i<read; i+=4) { sum += BitConverter.ToInt32(buffer, i); } } int sum = 0; int *buffer = malloc( 100000 * sizeof( int ) ); while ( !feof( f ) ) { int read = fread( buffer, sizeof( int ), 100000, f ); for ( int i = 0; i < read; i++ ) { sum += buffer[ i ]; } } I did not want to include this test in the “basis” of the article, and there was one reason for this: the test is not entirely fair. C was obviously better suited for such a task, because he could write anything and anywhere, but in C # I had to convert everything byte-by-by, because of what I got what I got:
I am inclined to think that such a performance difference is caused precisely by the need to additionally convert bytes into words. In general, this topic deserves a separate article, which I can even write.
Return arrays
The next step in performance measurements was the return of more complex types, because it would not always be convenient to communicate with integers and floating point numbers. Therefore, you need to check how quickly you can bring unmanaged memory to managed. To this end, it was decided to implement a simple task: reading the entire file and returning its contents as an array of bytes.
On pure C #, such a task is implemented quite simply, but in order to associate C code with C # code, in this case you will have to do something else.
First, a C # solution
static byte[] FileRead(string path) { BinaryReader br = new BinaryReader(File.OpenRead(path)); byte[] ret = br.ReadBytes((int)br.BaseStream.Length); br.Close(); return ret; } And the corresponding decision on C:
EXPORT char* STD_API file_read( const char* path, int* read ) { FILE *f = fopen( path, "rb" ); if ( !f ) return 0; fseek( f, 0, SEEK_END ); long length = ftell( f ); fseek( f, 0, SEEK_SET ); read = length; int sum = 0; uint8_t *buffer = malloc( length ); int read_f = fread( buffer, 1, length, f ); fclose( f ); return buffer; } To successfully call such a function from C #, we will have to write a wrapper that will call this function, copy the data from the unmanaged memory to the managed one, and free the unmanaged section:
static byte[] FileReadUnmanaged(string path) { int length = 0; IntPtr unmanaged = file_read(path, ref length); byte[] managed = new byte[length]; Marshal.Copy(unmanaged, managed, 0, length); Marshal.FreeHGlobal(unmanaged); // ? return managed; } In the measurement function, only the corresponding calls of the measured functions have changed. And the result looks like this:
Even with the loss of time to copy the memory, C again found himself in the lead, completing the task about 2 times faster. Honestly, I expected some other results (considering the data of the second test). Most likely due to the fact that reading data, even in a large packet in C #, is quite slow. In C, the loss of time goes by copying unmanaged memory into managed memory.
Lyrics
A little later, I noticed that Marshal.Free ... crashes in the Debug build. What caused this I did not understand, but in the Release assembly everything worked as it should and did not flow. However, the very first test hints that a free call from the C library will have little effect on it.
Real challenge
The logical conclusion of all the tests I carried out was this: to implement some full-fledged algorithm in C # and in C. Performance rate to evaluate.
I took the reading of an uncompressed TGA file with 32 bits per pixel, and casting it into a
struct Color { public byte r, g, b, a; } The implementation of the algorithm is quite capacious, and it is hardly interesting. Therefore, it is taken out in the spoiler so as not to be an insult to those who are not interested.
A simple implementation of reading TGA
And Sishny option:
static Color[] TGARead(string path) { byte[] header; BinaryReader br = new BinaryReader(File.OpenRead(path)); header = br.ReadBytes(18); int width = (header[13] << 8) + header[12]; // , short int height = (header[15] << 8) + header[14]; // Little-Endian, byte[] data; data = br.ReadBytes(width * height * 4); Color[] colors = new Color[width * height]; for(int i=0; i<width*height*4; i+=4) { int index = i / 4; colors[index].b = data[i]; colors[index].g = data[i + 1]; colors[index].r = data[i + 2]; colors[index].a = data[i + 3]; } br.Close(); return colors; } static Color[] TGAReadUnmanaged(string path) { int width = 0, height = 0; IntPtr colors = tga_read(path, ref width, ref height); IntPtr save = colors; Color[] ret = new Color[width * height]; for(int i=0; i<width*height; i++) { ret[i] = Marshal.PtrToStructure<Color>(colors); colors += 4; } Marshal.FreeHGlobal(save); return ret; } And Sishny option:
#include "api.h" #include <stdlib.h> #include <stdio.h> // , // 4 typedef struct { char r, g, b, a; } COLOR; // , #pragma pack(push) #pragma pack(1) typedef struct { char idlength; char colourmaptype; char datatypecode; short colourmaporigin; short colourmaplength; char colourmapdepth; short x_origin; short y_origin; short width; short height; char bitsperpixel; char imagedescriptor; } TGAHeader; #pragma pack(pop) EXPORT COLOR* tga_read( const char* path, int* width, int* height ) { TGAHeader header; FILE *f = fopen( path, "rb" ); fread( &header, sizeof( TGAHeader ), 1, f ); COLOR *colors = malloc( sizeof( COLOR ) * header.height * header.width ); fread( colors, sizeof( COLOR ), header.height * header.width, f ); for ( int i = 0; i < header.width * header.height; i++ ) { char t = colors[ i ].r; colors[ i ].r = colors[ i ].b; colors[ i ].b = t; } fclose( f ); return colors; } Now it's up to small. Draw a simple TGA image and load it n times. The result is as follows (vertically as usual, horizontally - the number of file reads).
Here it should be noted that I brazenly used the possibilities of C in his favor. Reading from the file directly into the structures has made life much easier (and in the case when the structures are not aligned with 4 bytes, there will be fun debugging). However, I am pleased with the result. Such an uncomplicated algorithm turned out to be efficiently implemented in C, and effectively used in C #. Accordingly, I received an answer to the original question: you can really win, but not always. Sometimes you can win slightly, sometimes not win at all, and sometimes win several times and more.
Dry residue
In general, the very idea of carrying out the implementation of something in another language is doubtful, as I wrote at the very beginning. In the end, the application of this method of code acceleration can be found quite a bit. If opening a file starts to hang UI - you can put the download in a separate background thread, and then loading even per second will not cause anyone serious difficulties.
Accordingly, it is worthwhile to pervert so only when productivity is really necessary, and it is no longer possible to achieve it in other ways (and in such cases they usually write right away to C or C ++). Or if you already have a ready-made algorithm that you can use, and not reinvent the wheel.
It should be noted that a simple wrapper over an unmanaged dll will not give much performance gain, and all the “nimbleness” of unmanaged languages begins to be revealed only when processing large enough data, so you should also pay attention to this. However, the use of such a wrapper will not become worse.
C # does very well with the transfer of managed resources to unmanaged code, but the reverse is not as fast as we would like. Therefore, frequent data conversion is desirable to avoid and keep unmanaged resources in unmanaged code. If it is not necessary to edit / read this data in managed code, then IntPtr can be used to store pointers, and the rest of the work can be rendered entirely in unmanaged code.
Of course, it is possible (and even necessary) to conduct additional research before making a final decision on the transfer of code to unmanaged assemblies. But with current information you can decide on the appropriateness of such actions.
And on this I have everything. Thank you if you have read to the end!
Source: https://habr.com/ru/post/325954/
All Articles