Examples of real patches in PostgreSQL: part 3 of N
Today I would like to tell you again about some of the recent patches in PostgreSQL (as well as the pg_filedump utility). The similar articles published on Habré earlier gained quite a lot of pluses, which makes one think that they are of interest to someone. If you missed the previous articles, here they are - one , two , three . Despite the fact that the considered patches were written by me, do not forget about the contribution of the people who reviewed them and tested them. The work done by these people is often more and more difficult than the work of the author himself. Fedor Sigaev, Robert Haas, Tom Lane, Dmitry Ivanov, Grigory Smolkin, Andres Freund, Anastasia Lubennikova and Tels took an active part in the development of the reviewed packages.
11. pg_filedump: return a non-zero return code in case of errors
Let me remind you that the pg_filedump utility is designed to decode table segments and display information about page headers and tuples. It was noticed that if the checksums of the pages do not match their contents, pg_filedump displays a corresponding warning, however, it returns a zero return code. Which is not quite right, especially if the utility is used in shell scripts.
The patch corrects this situation. Now pg_filedump returns a non-zero code when it detects any errors, either in checksums or any other:
+/* Program exit code */ +static int exitCode = 0; + /*** * Function Prototypes */ @@ -191,6 +194,7 @@ ConsumeOptions(int numOptions, char **options) { rc = OPT_RC_INVALID; printf("Error: Missing range start identifier.\n"); + exitCode = 1; break; } @@ -205,6 +209,7 @@ ConsumeOptions(int numOptions, char **options) rc = OPT_RC_INVALID; printf("Error: Invalid range start identifier <%s>.\n", optionString); + exitCode = 1; break; } (... ...) @@ -1746,5 +1823,5 @@ main(int argv, char **argc) if (buffer) free(buffer); - exit(0); + exit(exitCode); } Patch: 1c9dd6b728810ea7d2f196e6e15064017e4b9eef
12. Improving the documentation on the internal representation of the timestamp type
The documentation for the timestamp type read as follows:
When <type>timestamp</> values are stored as eight-byte integers (currently the default), microsecond precision is available over the full range of values. When <type>timestamp</> values are stored as double precision floating-point numbers instead (a deprecated compile-time option), the effective limit of precision might be less than 6. <type>timestamp</type> values are stored as seconds before or after midnight 2000-01-01. [...] In the course of work on the patch discussed in the next section, it was noted that the above text creates an incorrect presentation. In fact, by default timestamp stores time in micro seconds. If the user chose an outdated representation as floating point numbers, then time is indeed stored in seconds.
After a brief discussion in the mailing list, the misleading piece of documentation was rewritten.
Patch: 44f7afba79348883da110642d230a13003b75f62
13. pg_filedump: partial data recovery
This patch was described in detail in the note PostgreSQL Table Recovery Example with the help of the new mega features pg_filedump , so here I will not dwell on it in detail. TL; DR version - now with the help of pg_filedump you can restore at least some part of the data from the table, even if the PostgreSQL instance does not start.
Patch: 52fa0201f97808d518c64bcb9696f2a350678aa5
14. pg_filedump: decoding catalog tables
Like the previous patch, a whole hotel article was devoted to this. Another new pg_filedump feature: restore the PostgreSQL directory . TL; DR version for those who are still not going to read it - before pg_filedump did not support some of the types used in the catalog tables. After applying this patch, it became possible to decode the catalog tables, and therefore restore the database schema, if we do not know it.
Patch: 5c5ba458fa154183d11d43218adf1504873728fd
15a. Partition acceleration: fix batlneck in find_tabstat_entry () / get_tabstat_entry ()
In PostgreSQL 10, which at the time of this writing, is being developed and is in a state of featurefree, the possibility of declarative table partitioning has been added. That is, now the table can be divided into several physical tables by hash or range. This was possible earlier with the help of table inheritance, but it was less convenient and generally looked like a dirty hack. Examples of using declarative partitioning can be found here and here .
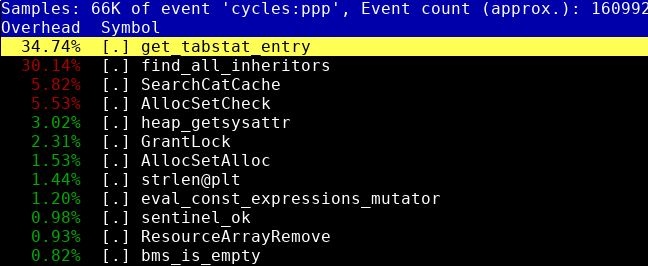
Well, I thought, and I will create more (say, 10,000) partitions and see where it will slow down. The topic of profiling C / C ++ code I previously devoted a whole article , even a few, if you count the articles about DTrace , SystemTap and HeapTrack . In addition, I made a report on this topic on HighLoad ++ 2016 , the video of which is on YouTube . Therefore, I will not dwell on the description of the process here. I can only say that perf top showed two obvious battles, which you can see in the illustration at the beginning of this article.
So, patch fixes the first of these batlnekov. It turned out that table statistics use a small memory allocator built on lists. A search by the table identifier of the PgStat_TableStatus structure corresponding to the table was made by scanning this list, which does not work very well when there are 10,000 tables. Adding a hash table that displays the table identifier to the pointer to the structure immediately eliminated the battles.
Patch: 090010f2ec9b1f9ac1124dc628b89586f911b641
15b. Partition acceleration: fix patch in find_all_inheritors ()
A similar problem was present in the recursive search procedure for all the heirs of a given table. Few people know that PostgreSQL supports multiple table inheritance . Therefore, when traversing child tables, the procedure follows the list of previously visited tables. If the next table is not listed, it is added to it. If it is already there, the parent's counter increases at the table. A list of all child tables and the number of their parents are returned from the procedure as a result.
As you might have guessed, the battlefield was again eliminated by adding a hash table to speed up the search in the list. In my benchmarks, two patches have totally accelerated declarative partitioning by 64%. Interestingly, patches speed it up not only with a large number of partitions, but also when there are only a few partitions. Although in the latter case, of course, the effect is not so noticeable.
Patch: 827d6f977940952ebef4bd21fb0f97be4e20c0c4
Conclusion
As before, the goal of all these articles is to show that in the development of RDBMS, in particular PostgreSQL, despite the extreme interest of the process, there is nothing magical or downright incomprehensible. Hopefully, this series of articles will be able to motivate a couple of people to take part in the development of PostgreSQL, as a hobby, or professionally.
In particular, the company Postgres Professional, in which I currently work, permanently hires , moreover, not only programmers, but also, for example, QA and DBA. As already noted, quality testing and code review in our business are often more important than writing code.
')
Source: https://habr.com/ru/post/325850/
All Articles