Cross a hedgehog (Marathon) with a snake (Spring Cloud). Episode 1
When switching to distributed systems with a large number of service instances, full-length problems arise with their service discovery and load balancing between them. As a rule, specialized tools such as Consul , Eureka or good old Zookeeper are used to solve them, in combination with Nginx , HAProxy and some bridge between them (see registrator ).
The main problem in this approach is a large number of integrations, and, as a result, there are points where something can go wrong. Indeed, in addition to the above solutions, a local small PaaS (for example, Mesosphere Marathon or Kubernetes ) will probably be used. The latter, by the way, already store the necessary configuration about the environment (after all, the whole deployment goes through them). And the question arises, can we abandon the specialized tools for service discovery and reuse the same Marathon for this task?
The short answer is we can. If you are interested in how - read on.
Disposition
So, what we have in stock:
- Apache Mesos and its loyal Marathon framework as a service orchestration system
- Services that are written using the Spring Boot framework and its Spring Cloud extensions
Sugar- free mesos (read without frameworks) is a cluster resource management system that can be expanded with frameworks. Frameworks serve different purposes. Some are able to run a wide range of short-term tasks ( Chronos ), others long-lived ( Marathon ). And some are sharpened for specific products, such as Hadoop or Jenkins .
Mesosphere Marathon is the very framework that can manage the start, stop and overall planning of long-lived tasks, which include services that process client, and not so, requests for a long period of time.
Spring Cloud is also a framework, but for the development of these same services, which implement both the basic patterns for their work in distributed systems, and the specific integration of these patterns with existing solutions on the market (for example, with the same Consul ).
As part of the Spring Cloud , there are actually two implementations for solving the problem of discovering services.
The first, using Netflix Zuul , can be attributed to the Server-Side Service Discovery pattern. The essence of the template is that we make a number of routers that know the current location and various meta-information about the instances of services, and provide constant http-resources through which proxying requests to them go. If we abstract from Spring, then the classic router is nginx , provided it is dynamically configured.
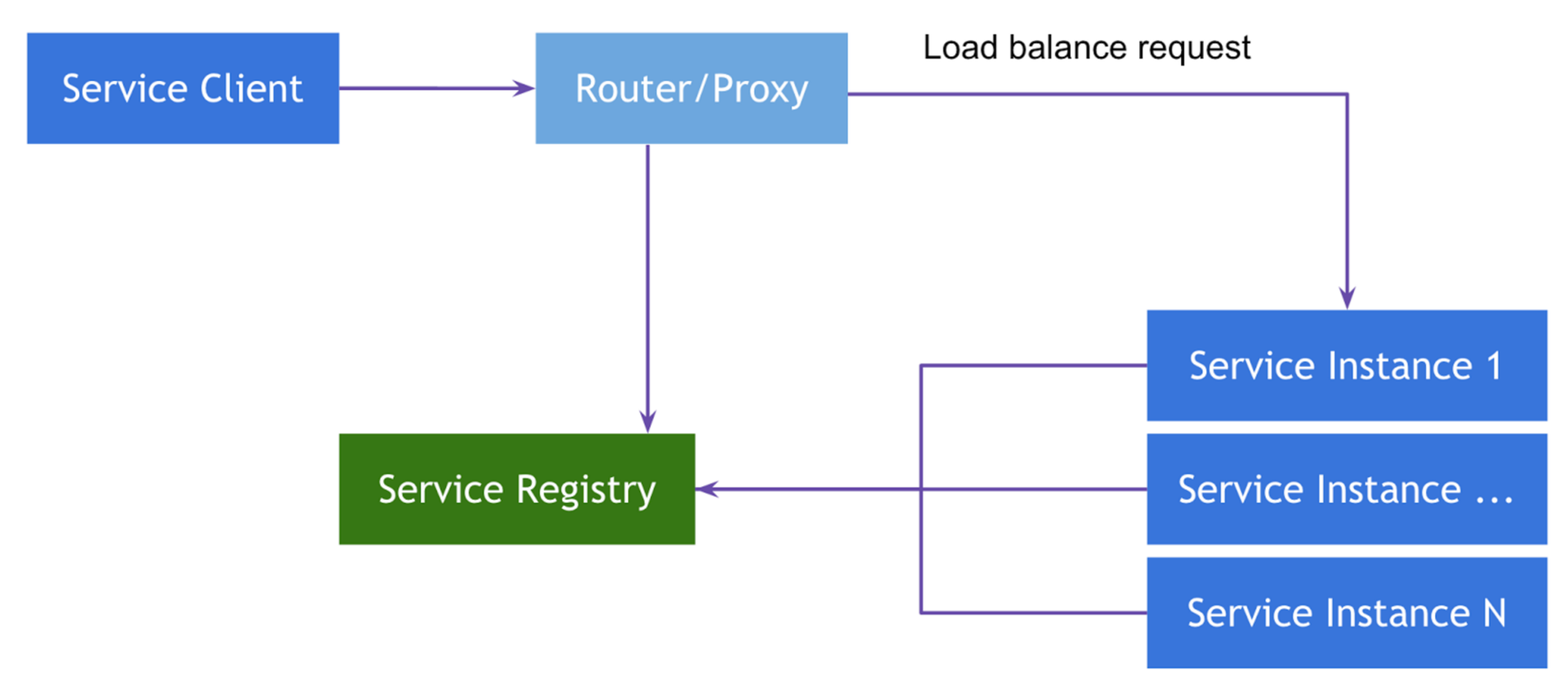
The second implementation belongs to the class Client-Side Service Discovery . Its main difference from the previous one is the absence of a router, and therefore an intermediate link and an extra point of failure, as a class. Instead, a smart client balancer is used as a router, which also knows everything you need to know about the instances of the services it calls. In Spring Cloud , Netflix Ribbon is used as such balancer.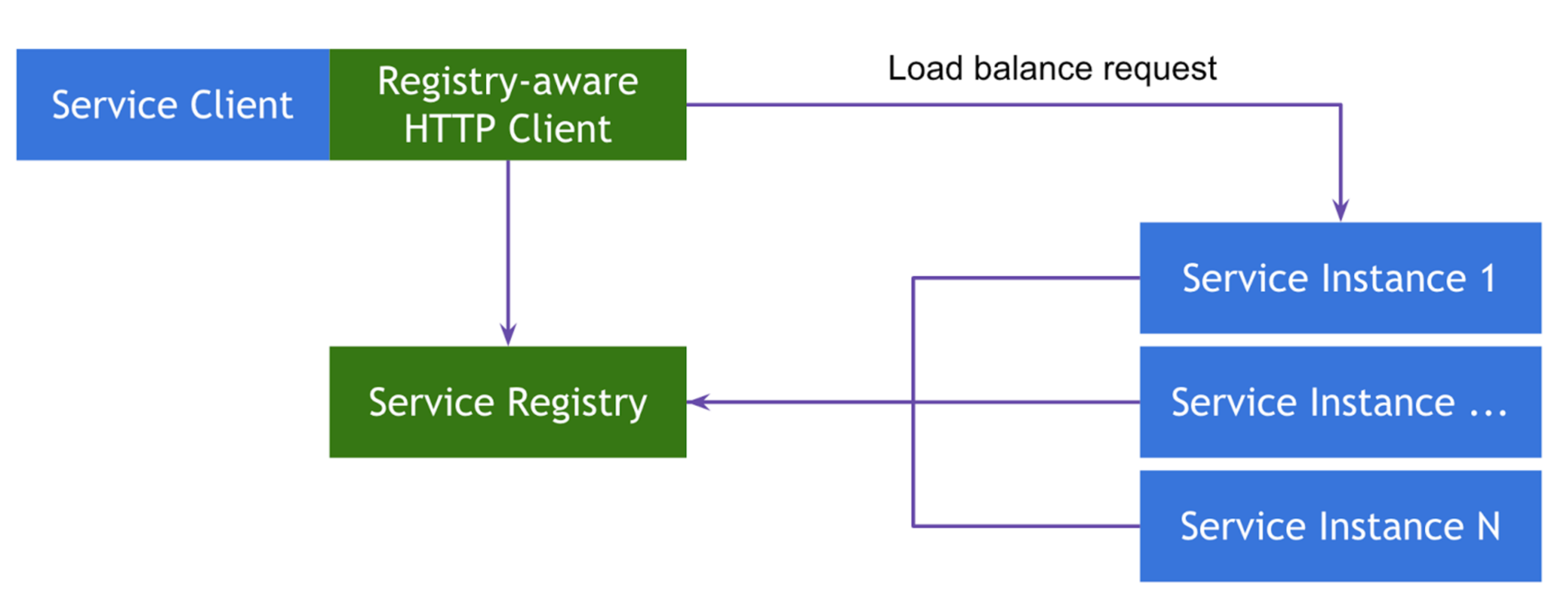
In this series of articles, we will dwell on the client implementation of the template, although we'll also talk about the server one.
@EnableDiscoveryClient
In Spring, almost everything can be done by working on a class / method / variable one or two dozen annotations and writing a little configuration in the yaml file. Well, ok, let's say that not everything, but a lot.
The manual teaches us that by adding the @EnableDiscoveryClient magic annotation on our application, we will have to work (after a couple of dependencies and settings, but more on that later) the discovery of services. At least locally inside our application. This can be done very simply, even it is not necessary to strain:
@SpringBootApplication @EnableDiscoveryClient public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } After this begins the magic in which there is no magic. Spring seeing this annotation loads all configurations that are listed in META-INF / spring.factories as downloadable for EnableDiscoveryClient :
org.springframework.cloud.client.discovery.EnableDiscoveryClient=\ org.springframework.cloud.xxx.discovery.XXXDiscoveryClientConfiguration From where and what configurations can be downloaded at all? To answer this question, it must be said that Spring Cloud itself consists of the basic part, which has the necessary interfaces and the general logic for implementing various patterns, and connectors, which are supplied in the form of starters , and which have specific implementation for specific solutions. Schematically, we can depict it like this: 
For example, if we connect a starter for Netflix Eureka , then we will have one factory configuration in the classpath . If the starter for Consul , then another.
The ambush here, however, is that the abstract itself, with industrial, not hellworld development, is slightly less than completely useless, since all the profit is in the area of prescribing the correct settings in bootstap.yml . And for each connector they are, as you probably guessed, their own.
Why it is so easy to understand. Eureka , Consul and Marathon are arranged completely differently. They need to connect in different ways. They have a different API and features that are specific to a particular solution. It is impossible to make a universal config, and in general there is no need.
But back to the configuration that is pulled using @EnableDiscoveryClient . And the first thing that comes to mind, and what is quickly found through a search in your favorite IDE, is the implementation of the DiscoverClient interface. The most important (at least at first glance) interface looks like this:
public interface DiscoveryClient { public String description(); public ServiceInstance getLocalServiceInstance(); public List<ServiceInstance> getInstances(String serviceId); public List<String> getServices(); } In principle, everything is pretty obvious. We can get a description for HealthIndicator . We can get ourselves. We can get all instances for some service id. And finally, we can get a list of all known services (more precisely, their identifiers).
It's time to implement the interface in order to receive data from Marathon .
First blood
How to get data? This is the first question we need to solve. And it is not that difficult.
First, it has a powerful API . Secondly, there is already ready for Java SDK .
We take legs in hands and we realize receipt of the list of all services:
@Override public List<String> getServices() { try { return client.getApps() .getApps() //, .parallelStream() .map(App::getId) // .map(ServiceIdConverter::convertToServiceId) // .collect(Collectors.toList()); } catch (MarathonException e) { return Collections.emptyList(); } } No magic except for ServiceIdConverter::convertToServiceId . What is this strange converter you ask. And here I must say about one feature of the representation of service identifiers in Marathon . In general, they follow the following pattern:
/group/path/app but the / symbol cannot be used to build a virtual host. And thus, some parts of Spring Cloud that use the service ID as a virtual host will not work. Therefore, instead of / we will use another separator that is allowed to be present in the host name, namely, a dot. That is why we are forced to get a match for /group/path/app on group.path.app . What the converter actually does.
Getting all service instances is somewhat more complicated, but also no rocket science:
@Override public List<ServiceInstance> getInstances(String serviceId) { try { return client.getAppTasks(ServiceIdConverter.convertToMarathonId(serviceId)) .getTasks() .parallelStream() .filter(task -> null == task.getHealthCheckResults() || //health- , task.getHealthCheckResults() .stream() .allMatch(HealthCheckResult::isAlive) // ) .map(task -> new DefaultServiceInstance( ServiceIdConverter.convertToServiceId(task.getAppId()), task.getHost(), task.getPorts().stream().findFirst().orElse(0), //magi zero false )) .collect(Collectors.toList()); } catch (MarathonException e) { log.error(e.getMessage(), e); return Collections.emptyList(); } } The main thing we need to check is that for the service all health checks HealthCheckResult::isAlive : HealthCheckResult::isAlive , because our task is to work only with those who are alive. The mechanism of health checks is provided by Marathon itself, which makes it possible to set them up and itself monitors the health of the services entrusted to it, distributing this information free of charge through the API.
In addition, we need to remember again to convert the identifier into the correct representation and select only one, first, port: task.getPorts().stream().findFirst().orElse(0) .
So so, you say. And what to do if the application has several ports? Unfortunately, our choice is small. On the one hand, we need to return an object that implements the ServiceInstance interface, which has a getPort method getPort , of course, can return only one port. And on the other hand, we really do not know which port to take from the list. Marathon does not give us any information about this. Therefore, take the one that is listed first. Perhaps lucky.
You can try to solve this problem as registrator solves it when registering services in the same Consul . This is to take into account the port of the service in its identifier. Then the service identifier will be approximately like this: group.path.app.8080 in case there are more ports than one.
A little distracted. It's time to add the new implementation as a bin:
@Configuration @ConditionalOnMarathonEnabled @ConditionalOnProperty(value = "spring.cloud.marathon.discovery.enabled", matchIfMissing = true) @EnableConfigurationProperties public class MarathonDiscoveryClientAutoConfiguration { @Autowired private Marathon marathonClient; @Bean public MarathonDiscoveryProperties marathonDiscoveryProperties() { return new MarathonDiscoveryProperties(); } @Bean @ConditionalOnMissingBean public MarathonDiscoveryClient marathonDiscoveryClient(MarathonDiscoveryProperties discoveryProperties) { MarathonDiscoveryClient discoveryClient = new MarathonDiscoveryClient(marathonClient, marathonDiscoveryProperties()); return discoveryClient; } } What is important here? First, we use conditional annotations: @ConditionalOnMarathonEnabled and @ConditionalOnProperty . That is, if the functionality is disabled in the settings, for example, through the spring.cloud.marathon.discovery.enabled configuration, the configuration will not be loaded.
Secondly, the @ConditionalOnMissingBean magic annotation stands above our client, which makes it possible in a particular application to redefine a bin in the way that a user needs.
We have to do just a little. Configure the client for Marathon . A naive but working implementation of the configuration looks like this:
spring: cloud: marathon: scheme: http #url scheme host: marathon #marathon host port: 8080 #marathon port For this we need a class with its settings:
@ConfigurationProperties("spring.cloud.marathon") @Data //lombok is here public class MarathonProperties { @NotNull private String scheme = "http"; @NotNull private String host = "localhost"; @NotNull private int port = 8080; private String endpoint = null; public String getEndpoint() { if (null != endpoint) { return endpoint; } return this.getScheme() + "://" + this.getHost() + ":" + this.getPort(); } } and very similar to the previous configuration:
@Configuration @EnableConfigurationProperties @ConditionalOnMarathonEnabled public class MarathonAutoConfiguration { @Bean @ConditionalOnMissingBean public MarathonProperties marathonProperties() { return new MarathonProperties(); } @Bean @ConditionalOnMissingBean public Marathon marathonClient(MarathonProperties properties) { return MarathonClient.getInstance(properties.getEndpoint()); } } After this, we can happily go to our application to customize the DiscoveryClient :
@Autowired private DiscoveryClient discoveryClient; and, for example, get a list of all instances for a certain service:
@RequestMapping("/instances") public List<ServiceInstance> instances() { return discoveryClient.getInstances("someservice"); } And here we are in for the first surprise. Our goal, after all, is not to get a list of instances, but to do a balancing between them. And it turns out that DiscoveryClient not so much useful for this, because it simply doesn’t participate in the implementation of balancing. Ok, I'm lying. A little involved, for example, with dynamic registration of endpoint s in Zuul . It is also used for health indicators. But this is basically all its standard use. Not so much truth?
Total
We were able to integrate with Marathon . It's good. We can even now get a list of services and their instances.
But at the same time, we still have at least two unsolved problems. The first is related to the fact that we have only one instance of the Marathon Wizard for connection specified in our configuration. If he falls, then we will cease to possess information, and therefore the world.
The second is that we haven’t gotten to the implementation of client balancing and in our hands so far a child’s toy, not a tool for solving problems.
To be continued
')
Source: https://habr.com/ru/post/325714/
All Articles