Fail-safe processing of 10M OAuth tokens on Tarantool

Many have already heard about the performance of the Tarantool DBMS, its capabilities and features. For example, he has a cool disk storage - Vinyl, in addition, he knows how to work with JSON-documents. But in numerous publications bypass one important feature. Usually, databases are considered simply as storage, but still the distinctive feature of Tarantool is the ability to write code inside and work very effectively with this data. Under the cut, the story of how we built one system almost entirely inside Tarantool, written in collaboration with Igor igorcoding Latkin.
All of you have come across Mail.Ru Mail and you probably know that it is possible to configure the collection of letters from other mailboxes. To do this, we do not need to ask the user for a username and password from a third-party service if OAuth is supported. In this case, OAuth tokens are used for access. In addition, Mail.Ru Group has many other projects that also need authorization through third-party services, and which need to issue OAuth – tokens of users to work with this or that application. We were engaged in the development of such a service for the storage and updating of tokens.
Probably everyone knows what an OAuth – token is. Recall, most often this is a structure of three or four fields:
{ "token_type" : "bearer", "access_token" : "XXXXXX", "refresh_token" : "YYYYYY", "expires_in" : 3600 } - access_token , with which you can perform an action, get information about a user, download a list of his friends, and so on;
- refresh_token , with which you can get a new
access_token, and as many as you like; - expires_in - the timestamp of either the expiration of the token or another predefined time. If you come with an expired access token, you will not have access to the resource.
Now consider the approximate architecture of the service. Imagine that there are some frontends that just put tokens into our service and read them, and there is a separate entity called refresher. The task of the refresher is to go to the OAuth provider for a new access_token at about the moment when it expires.

The structure of the base is also quite simple. We have two database nodes (master and slave replicas). The vertical bar is a conditional division of data centers. In one data center there is a master with its frontend and a refresher, and in the other - a slave with its frontend and a refresher that goes to the master.
What are the difficulties?
The main problem is the time (one hour) during which the token lives. If you look at the project, the thought arises: “Is this highload scale - 10 million records that need to be updated within an hour? If we divide one into another, see, we get an RPS of about 3000 ". Problems begin at the moment when something stops refreshening, for example, some maintenance of the base, or if it falls, or if the machine falls - anything happens. The fact is that if our service, master base, for some reason does not work for 15 minutes, we get 25% outage, i.e. a quarter of our data is not valid, not updated, it can not be used. If the service is 30 minutes, then without updating already half of the data. Hour - no valid token. Suppose the base was lying for an hour, we raised it, and all 10 million tokens need to be updated very quickly. And this is no longer 3000 RPS, this is quite a high-load service.
I must say that initially everything was handled normally, but two years after the launch, we added different logic, additional indexes, began to add secondary logic - in general, Tarantool ran out of processor. It was unexpected, but after all any resource can be spent.
For the first time, admins helped us. We put the most powerful processor, which we found, it allowed us to grow for another six months, but during this time we had to somehow solve the problem. We caught the eye of the new Tarantool (the system was written in the old Tarantool 1.5, which practically does not occur outside the Mail.Ru Group). In Tarantool 1.6 at that time there was already master-master replication. And the first thing that came to mind: let's put in three data centers on the copy of the database, between them run the master-master replication, and everything will be fine.
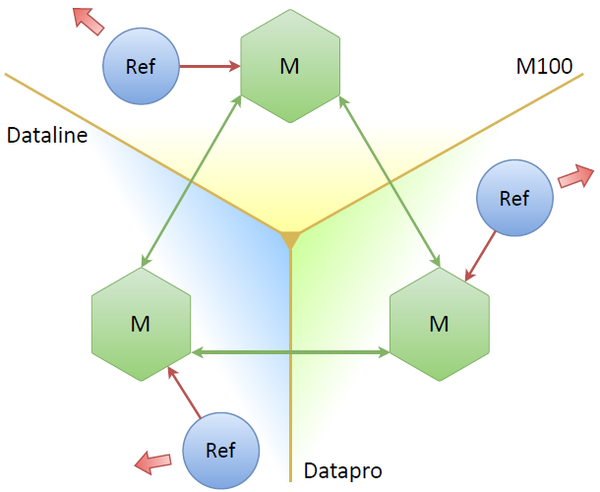
Three masters, three data centers, three refresher, each working with his master. We can drop one or two, everything seems to be working. But what are the potential problems here? The main problem is that we increase the number of requests to the OAuth-provider three times. We refresh almost the same tokens, and as many times as we have replicas. This is not the case. The obvious solution: the nodes themselves must somehow decide which of them will be the current leader (i.e., to keep refreshing tokens from only one replica).
Leader Selection
There are several consensus algorithms. The first one is Paxos. Pretty complicated stuff. We were not able to properly figure out how to make something simple based on it. As a result, we stopped at Raft. This is a very simple consensus algorithm, in which there is a choice of a leader with whom we can work until a new leader is selected when the connection is broken or for other reasons. This is how we did it:

In Tarantool from the box there is neither Raft, nor Paxos. But we take the finished module, which is in the delivery - net.box. This module allows us to connect nodes with each other using a full mesh scheme: each node connects to all the rest. And then everything is simple: on top of these connections we will implement the choice of the leader, which is described in Raft. After that, each node begins to have the property: it is either a leader or a follower, or does not see either a leader or a follower.
If you think it's hard to implement Raft, here’s an example of Lua code:
local r = self.pool.call(self.FUNC.request_vote, self.term, self.uuid) self._vote_count = self:count_votes(r) if self._vote_count > self._nodes_count / 2 then log.info("[raft-srv] node %d won elections", self.id) self:_set_state(self.S.LEADER) self:_set_leader({ id=self.id, uuid=self.uuid }) self._vote_count = 0 self:stop_election_timer() self:start_heartbeater() else log.info("[raft-srv] node %d lost elections", self.id) self:_set_state(self.S.IDLE) self:_set_leader(msgpack.NULL) self._vote_count = 0 self:start_election_timer() end Here we make requests to remote servers, to other replicas of Tarantool, we count the number of votes that we received from the node. If a quorum has accumulated, we have been voted for, we become the leader and start heart-beat - we notify the other nodes that we are alive. If we lose the election, we initiate it again. After a while we can vote or be selected.
After obtaining a quorum and determining a leader, we can direct our refresher to all nodes, but at the same time tell them to work only with the leader.
So we get normal traffic. Since the tasks are distributed by one node, one third will go to each refresher. Only here we can safely lose any of the masters - re-election will happen, the refressers will switch to another node. But, as in any distributed system, problems arise with a quorum.
"Abandoned" node
If connectivity between data centers is lost, then a mechanism is needed that makes the system continue to live, as well as a mechanism that should restore the integrity of the system. This problem solves Raft.
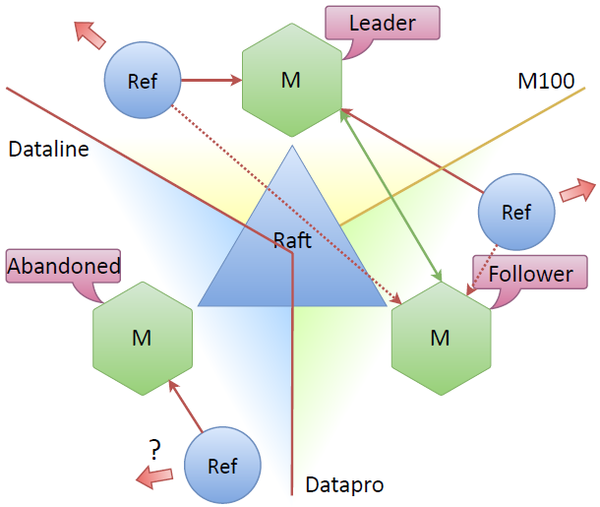
Suppose the Dataline data center is gone. It turns out that the node standing there becomes “abandoned” - it does not see other nodes. The rest of the cluster sees that the node is lost, re-election takes place, the leader becomes a new node in the cluster, say, the top one. And the system continues to work, because there is still a consensus between the nodes, because more than half of the nodes see each other.
The main question is: what happens to the refresher that is located in the departed data center when connectivity is lost? The Raft specification does not have a separate name for such a node. Usually, a node that does not have a quorum and no connection with a leader is inactive. But he can still go to the network, independently update tokens. Usually, tokens are updated in the connected mode, but can it be possible to update the tokens with a refresher that is connected to the “abandoned” node? Initially, it was not clear whether it makes sense to update tokens? Will there be unnecessary update operations?
We addressed this issue in the process of implementing the system. The first thought is that we have a consensus, a quorum, and if we have lost someone from the quorum, we do not perform updates. But then another idea appeared. Let's look at the implementation of master-master in Tarantool. Suppose at some point there are two nodes, both master. There is a variable, the key X, the value of which is 1. Suppose that at the same time, until replication has reached this node, we simultaneously change this key to two different values: set 2 in one node and 3 in the other. exchange replication logs, that is, values. From the point of view of consistency, such a master-master implementation is some kind of horror, forgive me for the Tarantool developers.
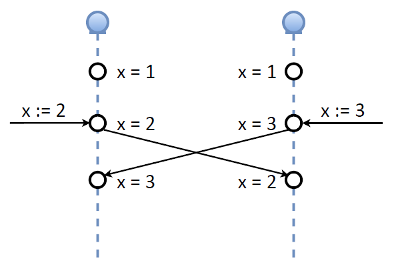
If we need strict consistency - it does not work. However, remember our OAuth token, which consists of two important parts:
- refresh-token, which, conditionally, lives endlessly,
- and access-token - lives for one hour.
But at the same time, our refresher carries the refresh function, which from the refresh-token can always receive any number of access-tokens. And they will all operate within an hour from the date of issue.
Consider the scheme: two nodes worked normally with the leader, updated tokens, received the first access token. He replicated, now everyone has this access token. There was a gap, the follower became a “abandoned” node, it does not have a quorum, it does not see either a leader or other followers. At the same time, we allow our refresher to update tokens that live on the “abandoned” node. If there is no network, the circuit will not work. But if this is a simple split - the network is broken, then that's okay, this part will work autonomously.
After the connection is broken and the node joins, then either re-election will take place or data will be exchanged. In this case, the second and third token are equally “good”.
After the cluster is reunited, the next update procedure will be executed only on one node, and it will replicate. That is, for some time our cluster is divided, and each updates in its own way, and after reunification, we return to normal consistent data. This gives us the following: usually for the operation of the cluster, N / 2 + 1 active nodes are needed (in the case of three nodes, these are two). In our case, at least one active node is enough for the system to work. Out there will be exactly as many requests as needed.
We talked about the problem of increasing the number of requests. At the time of the split or downtime, we can afford to live at least one node. We will update it, we will add the data. If this is a marginal split, that is, all the nodes are separated and everyone has a network, then we will get the same tripling of the number of requests to the OAuth provider. But due to the short duration of the event - this is not terrible, and we do not intend to constantly work in the separation mode. Usually the system is in quorum, connectivity, and in general all nodes work.
Sharding
There was one problem - we rested against the ceiling on the CPU. The obvious solution: sharding.

Suppose there are two shards - databases, each of them is replicated. There is a certain function which some key comes to an input, on this key we can define, in what shard the data lies. If we shard by e-mail, then some of the addresses are stored in one shard, some - in the other, and we always know where our data lies.
There are two approaches to the implementation of sharding. The first is the client. We select the function of consistent hashing, which returns the number of the shard, for example, CRC32 key, Guava, Sumbur. This feature is implemented in the same way on all clients. This approach has an undoubted advantage: the DB does not know anything about sharding at all. You raised the base, it works as standard, and sharding is somewhere on the side.
But there is a serious drawback. First, the clients are pretty fat. If you want to make a new one, then you need to add the logic of sharding to it. But the most terrible problem is that some clients can work according to one scheme, and others - according to another. At the same time, the base itself does not know anything about the fact that you are in different ways.
We chose a different approach - sharding inside the database. In this case, its code becomes more complicated, but we can use simple clients. Any client connecting to this database goes to any node, there is a function that calculates which node to contact and which one to transfer control to. Clients are simpler - the base is more complicated, but at the same time it is fully responsible for its data. In addition, the most difficult - it is Resarding. When the database is responsible for its data, it is much easier to perform rewarding than when you have customers that you cannot update yet.
How did we do it?
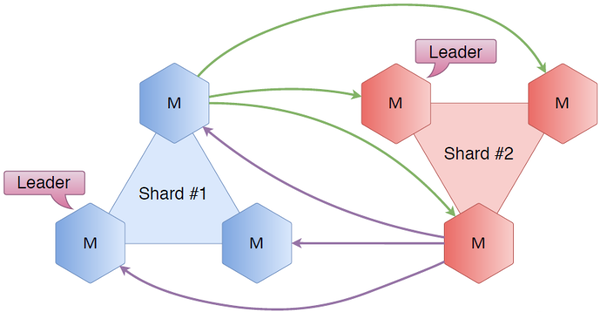
Hexagons are Tarantools. Take the top three nodes, call the shard number one. We put exactly the same cluster and call it shard number two. Connect all the nodes with each other. What does this give? First, we have Raft, where inside the top three servers we know who the leader is, who is the follower, what is the status of the cluster. Thanks to the new connections of sharding, we now know the state of another shard. We know perfectly well who is the leader in the second shard, who is the follower, and so on. In general, we always know where to redirect the user who came to the first shard, if he needs not the first shard.
Consider simple examples.
Suppose a user requests a key that lies on the first shard. He comes in a knot from the first shard. Since he knows who is the leader, the request is redirected to the leader, he in turn receives or writes the key, and the answer is then returned to the user.
Suppose now that the user comes to the same node, and he needs a key, which is actually on the second shard. The same: the first shard knows who is the leader in the second, goes to this node, receives or writes data, returns to the user.
Very simple scheme, but with it there are difficulties. The main problem: are there too many connections? In the scheme, when each node is connected to each, it turns out 6 * 5 - 30 connections. Put another shard - we get already 72 connections in the cluster. Too much.
We solve this problem in the following way: we simply put a couple of Tarantools, just call them no longer shards or bases, but proxies that will deal exclusively with sharding: calculate the key, find out who is the leader in a particular shard, but Raft clusters remain closed in themselves and will work only within the shard itself. When a client comes to the proxy, it calculates which shard it needs, and if it needs a leader, we redirect to the leader. If it doesn't matter who, we redirect to any node from this shard.

The complexity is obtained linear, depending on the number of nodes. If we have three shards with three nodes in each, then we will get many times fewer connections.
The proxy scheme is designed for further scaling when there are more than two shards. With two shards, we have the same number of connections, but with an increase in the number of shards, we significantly save on connections. The list of shards is stored in the Lua config, and in order to get a new list, simply reload the code and everything works.
So, we started with a master-master, implemented Raft, screwed a sharding on it, then a proxy, rewrote it all. It turned out a brick cluster. Our scheme began to look pretty simple.
Our front-ends remain, which only put or take tokens. There are refressers who update tokens, take a refresh-token, give to the OAuth-provider, put a new access-token.
We said that we still have a secondary logic, because of which the processor has run out of resources. Let's move it to another cluster.
Such secondary logic mainly includes address books. If there is a user token, then it corresponds to the address book of this user. And there are as many data on the number as there are tokens. In order not to exhaust processor resources on one machine, obviously, the same cluster is needed, replicated again, and so on. We put another pack of other refreshers for updating address books (this is a rarer task, therefore we do not update address books together with tokens).
As a result, combining two such clusters, we got such a fairly simple architecture of the entire system:
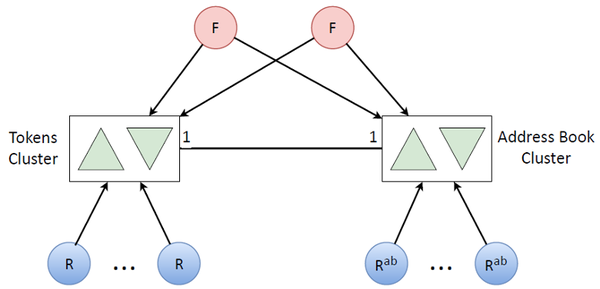
Token Update Queue
Why do we turn around? It was possible to take something standard. The point is in our model update tokens. After receiving the token lives one hour. When it comes to the end of its time, it must be updated. This is a deadline: the token must be updated before a certain time.

Suppose an outage happened, short-term or not, but we have some volume of expired tokens. If we update them, then some more will become obsolete. We, of course, will catch up with everything, but it would be better to first update those that are about to die (after 60 seconds), and then update the remaining resources anyway with the remaining resources. Last, we update the more distant horizon (5 minutes to death).
To implement this logic on something third-party, you have to sweat. In the case of Tarantool, this is implemented very simply. Consider a simple scheme: there is a tuple, where Tarantool data is located, it has some kind of ID, which has a primary key. And to make the queue that we need, we simply add two fields: status and time. The status indicates the status of the token in the queue, the time - the same expire time, or some other.
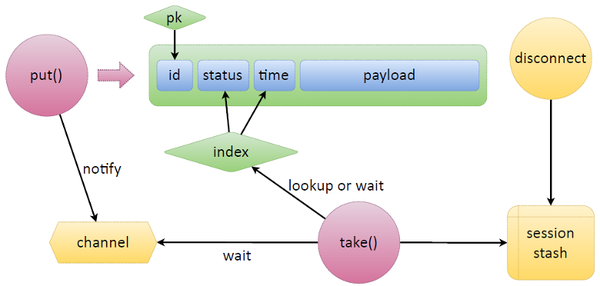
Take the two main functions from the queue - put and take . The task of put is to bring and put data. They give us some kind of payload, put the status itself, put the time and put the data. A new tuple appears.
Comes in, looks at the index. Creates an iterator, starts looking at it. Selects waiting tasks (ready), checks whether it is time to take them, or they are outdated. If there are no tasks, take goes into standby mode. In addition to the built-in Lua in Tarantool, there are also primitives for synchronization between file servers - channels. Any fayber can create a channel and say: "I'm waiting here." Any other fayber can wake this channel and send messages to it.
The function that is waiting for something - the release of tasks, the arrival of time or something else - creates a channel, marks it in a special way, puts it somewhere, and waits on it further. If they bring us a token that needs urgent updating, say put , then it will send notify to this channel.
Tarantool has one feature: if a token is accidentally released, someone took it at a refresh or just takes a task, you can monitor client connection breaks. We remember in the session stash, to which connection which task was given. We associate that such and such tasks were associated with this session. Suppose the refresh process drops, the network is simply broken — we don’t know whether it will refresh the token or not, whether it will be able to put it back or not. Disconnect triggers here, which finds all tasks in a session and automatically releases them. put , .
, :
function put(data) local t = box.space.queue:auto_increment({ 'r', --[[ status ]] util.time(), --[[ time ]] data --[[ any payload ]] }) return t end function take(timeout) local start_time = util.time() local q_ind = box.space.tokens.index.queue local _,t while true do local it = util.iter(q_ind, {'r'}, { iterator = box.index.GE }) _,t = it() if t and t[F.tokens.status] ~= 't' then break end local left = (start_time + timeout) - util.time() if left <= 0 then return end t = q:wait(left) if t then break end end t = q:taken(t) return t end function queue:taken(task) local sid = box.session.id() if self._consumers[sid] == nil then self._consumers[sid] = {} end local k = task[self.f_id] local t = self:set_status(k, 't') self._consumers[sid][k] = { util.time(), box.session.peer(sid), t } self._taken[k] = sid return t end function on_disconnect() local sid = box.session.id local now = util.time() if self._consumers[sid] then local consumers = self._consumers[sid] for k,rec in pairs(consumers) do time, peer, task = unpack(rec) local v = box.space[self.space].index[self.index_primary]:get({k}) if v and v[self.f_status] == 't' then v = self:release(v[self.f_id]) end end self._consumers[sid] = nil end end Put space , , , FIFO-, , .
take , : . taken , — , . on_disconnect , , .
?
Of course. . , , . , . , . ( ). . , , , , , in memory, .
, , . — 7 tuple, . , .
outage, . .
. N 2 , -: , - . : Google, Microsoft, - OAuth-, .
, , , . Tarantool . Thank.
')
Source: https://habr.com/ru/post/325582/
All Articles