Flexible release planning for 101 releases (based on Excel)
Translator's Foreword: Recently, I talked about how to implement a release planning procedure for products using the Atlassian product family and gave links to articles on how to do the same in Team Foundation Server and Redmine.
And what if the company did not mature to buy JIRA, TFS or Redmine, how to get by with Excel alone?
And this article is about how to do it.

In this article I want to talk about a simple mechanism for drawing up a release plan. I will not go into the principles and values underlying flexible release planning, but at the end of the article you will find links to materials that will help to figure this out.
')
This is just one of the ways to make a release plan and I am sure that there are many other options. I used this approach with many teams of different sizes in many projects of varying size and complexity. In many cases I have expanded and supplemented it, but the basics have always remained the same and work well. I would be happy to comment on how you do it with your teams.
List of user stories (Product Backlog)
First we need a list of user stories (Product Backlog). For simplicity, there will only be four fields:
ID is a unique identifier for each story. In my example, I started from 1000. I recommend not using the ID as the default priority field (I have seen such options for using it).
User Story is a simple short title for each user story. You should not try to write the history completely in the “Name of user history” field; in the extended version of the list you can add separate fields: a full description of the history, acceptance criteria, classification option and others.
Priority - this field indicates the order in which the Product Owner wants to receive stories. This number should not have any hidden logic built into the number (I'll explain later what I mean).
Evaluation of labor intensity - estimated by the team the complexity of the implementation of history. I will not offer to immediately use Story Points, days of development, hours. Let me just say that at the beginning I suggest using the high-level rating system, which will be convenient for using the Scrum team (it will also become clear later what I mean).
Add custom stories
There are many methods for collecting user stories, such as working groups for generating user stories, customer focus groups, etc. I will not now about this as it is not the subject of this article. However, the Product Owner collects and adds them to the list. Usually, when we brainstorm stories, we simply write them down in the order in which we generate and do not try to classify or prioritize at this stage. Sometimes it can interfere with the flow of ideas. So you need to make a list of stories.
Here is a simple example of an initial list of stories in Excel (the simplest tool that can be used after wall stickers).

Initial high-level prioritization
When you have a list, some say that you need to ask the team to rate it, but I advise you to do the first round of high-level prioritization, so you will focus the time and attention of the team on those stories that you first consider the most important.
Do not make it harder than necessary. Use a simple metric with several values, such as: must (required), need (definitely needed), want (wanted). Or use 1,2,3. Or - High, Medium, Low. In fact, there is not much difference between them. For my example, I will use 1,2,3, since then it will be easier to sort the list in Excel.
Look at the list and take no more than one minute to discuss each story in order to give each of them its initial priority. Make sure that everyone who participates in this event understands that this is not a final priority and that during the course of the project it can be re-evaluated and changed. This will help curb the desire to analyze every thing to death.
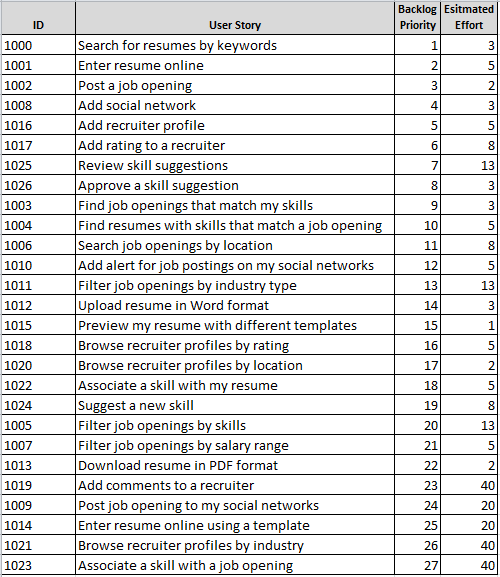
Here is our list of stories (Product Backlog) with primary priorities. (NOTE: I made up stories, so don’t cling to them).

Initial high-level estimates of labor intensity
Once we have a list of stories sorted by initial priorities, give it to the Scrum team so that it will provide some initial high-level estimates of the complexity. At this stage of the process, a similar approach can be used, as with priorities, using a simple indicator such as Small (small), Medium (medium) and Large (large). As in the case of priorities, these assessments are not final and the team will be asked to study them more carefully in the future, so try not to spend too much time on them. Good luck with this, because engineers love to be accurate and it’s very difficult to get them to be superficial (not go deep). You can use any of the evaluation methods that you know, for example, Planing Poker or something else that suits your team.
If your team is confident that they can use their normal metrics for evaluation (for example, the Fibonacci sequence), then let them use it. The approaches I proposed proved in practice that they are the best at the beginning, when everything is still in general, and you just want to get an idea of what needs to be done first and how much it will cost. As already said, you will constantly clarify priorities and assessments during the project. If your list of stories is large enough (long), you should focus on the top stories, as they should be the most valuable for business.
List of user stories with initial estimates of the complexity.

Updating user stories and priorities
Now that the Product Owner has some idea of how time consuming the stories are, he may want to change priorities and / or share some stories. After he decided in what order he would like to receive them, it is time to change the approach to indicate the priority of history.
As he said, there should be no additional logic in the priority field (execution order). I saw the use of the number in this form - 1102, which meant that the interested parties wanted the story to be realized by February 2011. This is not a very good approach, as it puts pressure on the team to implement the story before this date and the interested parties imply that this is the date when this will be done. But this number is usually not based on the speed of the team, nor on any assessment provided by the team, so this is a recipe for disaster.
The best way to ensure that the field is not used in this way is to always start at 1 and assign numbers to the rest of the stories in sequence. Each time you rearrange the stories in the list, the priority number starts at 1. After the development iteration (Sprint) is completed, you re-assign a priority to all the remaining stories in the list again starting at 1. This makes it quite difficult to embed any type of logic number.
List of stories with priority - the order of execution.

Refinement estimates of labor intensity
As after the initial prioritization, submit a list of Scrum stories to the team so that it refines its estimates in your usual measurement system (unless it did it at the very beginning). Spend more time on the top stories, as they are likely to be implemented in the next upcoming iterations. Then try to go through the list of stories as far as you can (depending on its size and available team time). In general, your Scrum team should spend from 10% to 15% of their time during each iteration to help groom (grooming) the list of stories when new User Stories (User Story) appear in it that were not announced at the beginning making it up.
Now we have a list of stories that is prioritized and evaluated according to the team’s capabilities.

You will notice that some of the stories on the list have fairly large ratings. This can be caused by many factors, such as uncertainty, risk, net size, complexity, and something else. The scrum team must determine the maximum size for the story, which it will allow to include in the iteration. Setting this boundary gives the team a tool for returning stories that, in their opinion, cannot be completed in a single iteration. The Product Owner must break these stories or provide answers to the team’s questions so that she can refine and reduce her ratings.
Large user stories are at the bottom of the list, since we do not expect them to be implemented soon, we will return to them later, when they rise in the list and get closer to being included in the iteration. If you have large stories at the top of the list, you need to split them until they are of an acceptable size or are moved down the list.
In this list, the large stories are moved to the bottom, and the priority field is re-filled starting from 1. In my example, the Scrum team determined that any story larger than 13 is too large for one iteration.
Determination of initial performance
Performance (Velocity) - is the sum of all the estimates of the complexity, which the team completes during the iteration. At the beginning of the project, you may not have an idea of what the performance (power) of your team will be. Saw all sorts of options with online algorithms and great math, based on the length of the iteration, available developer days, team size, etc. Whatever method you use, just know that you are most likely wrong and that is normal. After the first iteration, you will have real performance to start using and tracking.
I propose to meet with the Scrum team and discuss the stories at the top of the list, and ask how many stories they can take in the first iteration. Since the chances of being mistaken are still great, do not waste too much time on it and do not delay the team to calculate it.
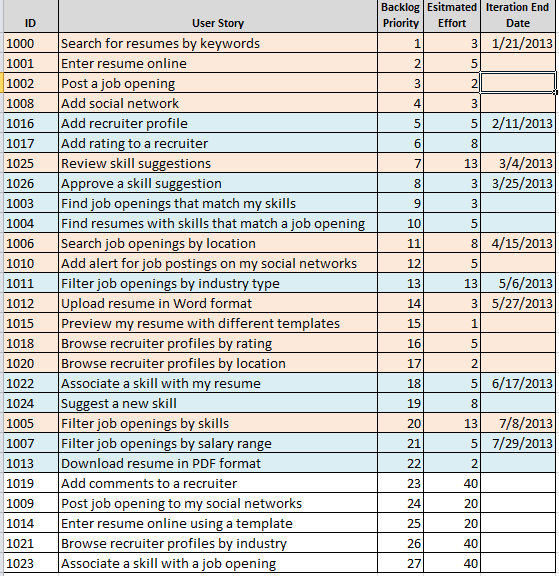
For example, we will consider the initial planned performance equal to 15. The duration of the iteration will be 3 weeks and our project starts 01/01/2013.
Creating an initial release plan
Having a prioritized and assessed list of stories, as well as the initial performance of the team (which I like to call the planned performance when planning releases), we can make our first pass on drawing up a release plan. Just start at the top of the list and make your way down, summing the estimates, until we reach 15 (or right before we go through that number). If we have a story with a rating of 13, and then the next one has a rating of 3, then we should not combine them in the iteration, as this will result in excess of the planned performance of 15. When we get to the stories at the bottom of the list, which are too large for implementations in one iteration, we stop at them.
When doing this in Excel, I use alternate colors to easily show the grouping of stories in iterations, as shown below.

Now that the stories are grouped in an iteration, based on planned performance, we can use the proposed project start date and the length of our iteration to add dates to groups and get an idea of the timing of the stories. Remember that this is a very high level and you will constantly review the plan with each new iteration, so consider it as a living document.
At this stage, your Product Owner will be able to start a discussion with the relevant stakeholders on the release date. Some companies release a release whenever they think they have enough value for their customers, so at the beginning, stakeholders will mostly ignore dates and just see how many stories from the list they have already received and how much is left until the functionality can be transferred to customer. Then they will have some idea of when this may be, given that this will be revised at the next iteration.
If your company makes scheduled releases of releases (for example, a planned release in the middle of the year or some other option), you can find the end date of the iteration close to the release date of the release. Then you can see what functionality will be implemented and what value you deliver to the client. Problems can arise when the planned implementation time of a functionality group that needs to be delivered as a unit to provide the customer with the greatest value exceeds your target release date, in which case the Product Owner may have to make some difficult choices.
Most likely the grooming of the story list will occur as soon as it becomes clear. Thus, the Product Owner can move stories, break them, combine, etc. Whenever a Product Owner polls a list of stories, he must notify the team to revise his ratings. This should happen even if it just moves some stories, since some estimates may have assumptions about item B, which is easier to implement if history A has already been made and if it changes them in places, then the estimates need to be clarified.
Consider creating a separate Sheet in a spreadsheet with stories that are not needed in the upcoming version, and use Sheet with those that are needed as a work plan for a release. Then the Product Owner will be able to move the stories between the sheets. It helps if you have a large list of stories, but in terms of release there are not so many of them. Maintaining them separately can facilitate their management.
Revision of the release plan at each iteration
During each iteration, the Product Owner will constantly brush the list of stories, working with interested parties to add, delete, clarify and prioritize, as well as get ratings from the Scrum team.
At the end of the iteration, you can take the latest actual performance of the Scrum team and use it along with your historical data to adjust the planned performance. One approach is to take the lowest 3 and average to calculate the worst planned performance, and then average the 3 highest for the best scenario. Providing stakeholders with a release plan with this range will help them not to cling to specific dates in them.
The updated release plan should be given to the team and stakeholders after each iteration. As you move to the target release date, the list of stories and the release plan will become clearer and more accurate. The main thing is to understand that the release plan is similar to Etch-A-Sketch, which you shake and recreate at the end of each iteration, based on the latest factual data.
Addition and improvement of the release plan
This simple approach works well, but in most cases you will need to expand and complement it to meet your specific needs. Be careful not to add too much and make it out of the release plan. That it will cease to be a plan. It is very easy to do. Here are some common additions that I had to do for various reasons.
Adding bugs - I participated in many discussions about how to handle bugs when it comes to including them in the list and release plan. Many people do not like to spend time on assessing the complexity of troubleshooting, as it is often necessary to first understand its causes before making a more or less accurate assessment. In these cases, I saw how they put errors into their own lists and simply allocated a certain percentage of the performance of each iteration to solve the most critical ones. If this is also your approach, then adjust the planned performance to eliminate the highlighted effort to correct errors when planning releases.
Unfortunately, many companies come to Agile with a significant list of errors that need to be fixed. In their cases, we added errors to the list of stories as well as stories. They were evaluated and prioritized in the same way as other stories from the list. This leads to increased overhead, but sometimes this is justified if you need to control the effect of accumulated errors on the product. Since errors are listed, you can use normal planned performance during release planning. If you still have a significant amount of new errors, then you can adjust your planned performance based on historical information about the average number of new errors that appear as a result of each iteration. Of course, if you are in such a situation, you obviously have a quality problem, and you need to take some steps to improve the quality of your processes and quality processes.
At the same time as adding errors to the list, we also added a new field called Type (Type), which can be either User Story or Bug, so that they can be distinguished when viewing the list or release plan. You can also use different colors so that later, based on their meaning (for example, green for user stories and red for errors), a quick glance at the release plan to get an idea of how many new features in this release.
Categorization and grouping - often a group of stories constitutes a “feature” (business function) and must be put all together in order to give the client enough value from a new release. Interested parties like such reports on these “features”, which show when all the necessary stories will be implemented or how many stories in the group have already been done and how much is left to be done. To show this, it is enough to add a column called "Category". Problems using this report arise when there is a need for multiple or hierarchical groupings. You can try a few simple options for such cases, for example, by adding additional category columns (Category 1, Category 2 or Main Category, SubCategory, etc.). You can also stick to one field and use the delimiter, but it is not so easy to filter in Excel to create a simple report.
Baselines are not surprising that there will always be someone who asks how the current release plan looks compared to how it looked in the past. This can be very dangerous because it reflects the inability to accept change, which is the core value of Agile. If you are asked to do something similar, I recommend to understand why they need to know this and what they are going to do with this information. It is assumed that the list of stories (Product Backlog) will change, and since the release plan is a simple overlay on its upper part, this means that it must also change.
Business Value and Return on Investment (ROI) - business value is sometimes mistakenly considered as the only indicator to sort a list of stories. Usually business value is something tangible, for example, adding “features” X will lead to an increase of 10% in the number of customers in the next quarter and will result in additional sales of $ 1,000,000. With this you can not argue. But what if the assessment of the complexity of the implementation of "features" X is 1 500 000 dollars?
There are also cases where you can implement a feature for less compelling reasons. You may have an important client who is very helpful in testing pre-beta releases. They may have a “feature” that they really want very much, but it is not so much needed by a wider circle of clients (the market). You can decide to implement this feature to maintain this relationship.
This suggests that there are many variables that can be included in the definition of the “Value” of a story from the list. I believe that giving a business value assessment justifies itself and I use it as another parameter when determining the priority of history in the general list. Try to keep it simple and give an explanation of how to use it. One example would be a rating from 0 to 1000, where 1000 is the highest value. Of course, immediately all the stories put up 1000 and just need a guide here (explanation). For example, a range from 750 to 1000 for stories that, if not implemented in the next release, will cost the company a significant market share through the loss of existing or potential customers.
Using this scale makes it possible to perform simple calculations of return on investment (ROI). Divide the business value by the estimated effort required to get an idea of the relative profitability. This is a very simplified approach to calculating ROI, but it is good at a high level. You can see that the story, estimated at 1000, but with an estimate of labor intensity of 20, has less ROI than history per 500 and labor intensity of 5.
What else to read on the topic at Habrahabr
How to do it with other tools
- in Team Foundation Server - About flexible planning and work management in TFS 11 Beta
- in Redmine - Operational Planning in Redmine
- at JIRA - Implementation of the “Release Planning for Products” procedure using Atlassian family tools
Conceptual articles
Source: https://habr.com/ru/post/325476/
All Articles