How not to step on a rake in Go
This post is a version of my English-language article "How to avoid gotchas in Go" , but the word gotcha is not translated into Russian, so I will use this word without translation, and a little indirect option - "step on the rake."
Gotcha is the correct design of a system, program, or programming language that works as described, but is counterintuitive and causes errors, since it is easy to use incorrectly.
In the Go language there are several such gotchas and there are quite a few good articles that describe and explain them in detail . I believe that these articles are very important, especially for newcomers to Go, because I regularly see people falling for the same rake.
But one question tormented me for a long time - why did I never make these mistakes myself? Seriously, the most popular of them, like a confusion with a nil-interface or an incomprehensible result with append () - e slices - have never been a problem in my practice. Somehow I was lucky to get around these pitfalls from the first days of my work with Go. What helped me?
And the answer was quite simple. I just read a few good articles about the internal structure of data structures in Go and other implementation details. And this, quite superficial in fact, knowledge was enough to develop some intuition and avoid these pitfalls.
Let's go back to the definition, "gotcha ... this is a valid construction ... which is counterintuitive ..." . That's the whole point. We actually have two options:
- fix language
- fix intuition
The first option, which will appeal to many habratchitelemi, of course not an option. In Go, there is a promise of backward compatibility - the language will not change anymore, and that's fine - programs written in 2012 are compiled today with the latest version of Go without a single Vorning. By the way, there are no goings in Go :)
The second option would be more correct to call develop intuition . As soon as you learn how interfaces or slices work from the inside, intuition will prompt you more correctly and help you avoid mistakes. This method has helped me well and will certainly help others. Therefore, I decided to gather this basic knowledge of Go internals in one post, to help others develop intuition about how Go works from within.
Let's start with a basic understanding of how data types are stored in memory. Here is a brief list of what we will learn:
Pointers
Go, with C in the genealogical tree, is actually quite close to the gland. If you create an int64 variable (a 64-bit integer value), you can be sure exactly how much space it takes in memory, and you can always use unsafe.Sizeof () to find out for any other type.
I really like to use a visual representation of data in memory to "see" the sizes of variables, arrays or data structures. The visual approach helps to quickly understand the scale, develop intuition and clearly assess even things such as performance.
For example, let's start with the simplest base types in Go:
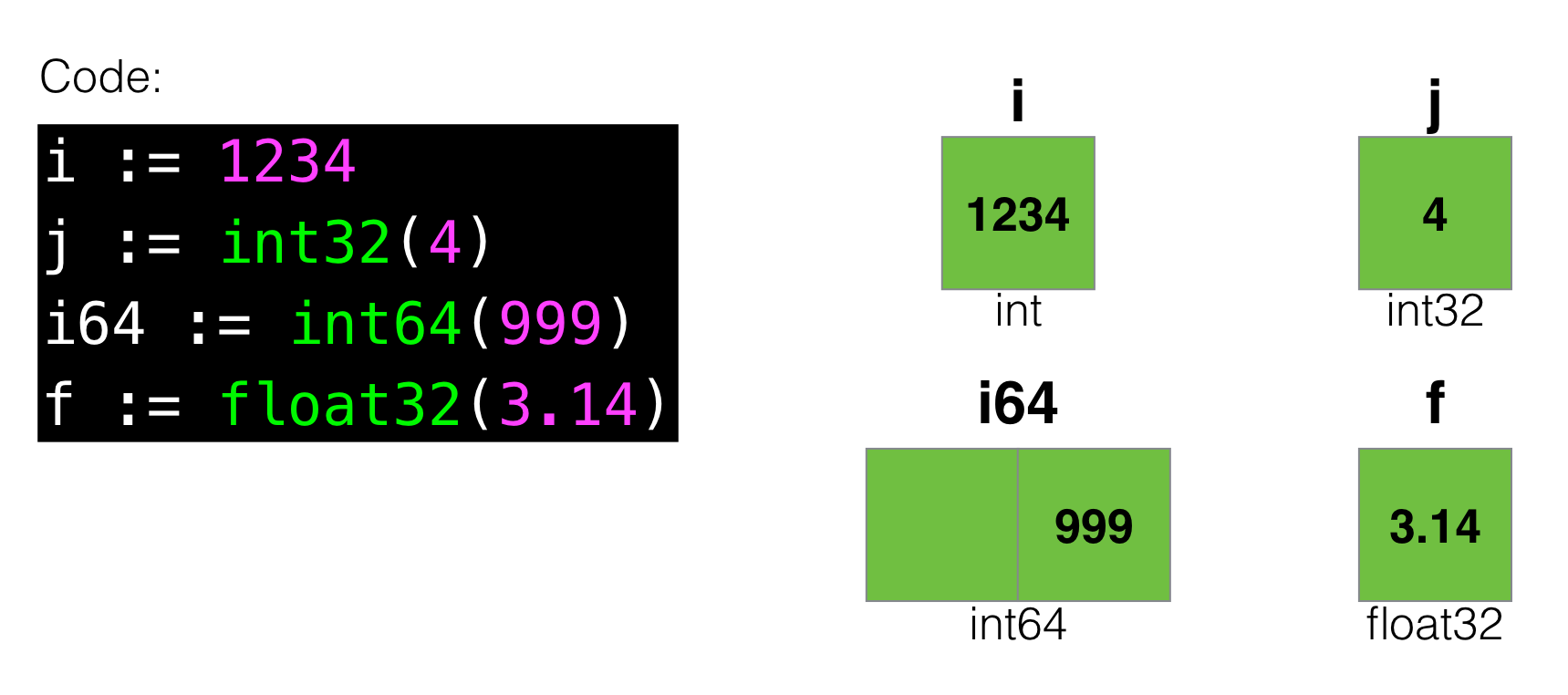
For example, in such a visualization you can see that a variable of int64 type will take twice as much “space” as int32 , and int takes up as much as int32 (implying that this is a 32-bit machine).
Pointers, on the other hand, look a little more complicated - in fact, this is one block of memory that contains an address in memory that points to another block of memory where the data lies. If you hear the phrase "dereference pointer", it means "to find data from the memory block pointed to by the address in the memory block of the pointer". You can think of it this way:

The address in memory is usually indicated in hexadecimal form, hence the "0x ..." in the picture. But the important point here is that the “memory block of the pointer” can be in one place, and the “data pointed to by the address” can be completely different. We need it a little further.
And here we come to one of the gotchas in Go, which people encounter who have not had experience working with pointers in other languages - this is a confusion in understanding what "transfer by value" of parameters in a function is. As you probably know, everything is transferred to Go "by value", that is, it is literally copied. Let's try to visualize it for functions in which the parameter is passed as it is and through the pointer:

In the first case, we copy all these blocks of memory - and, in reality, they can easily be more than 2, at least 2 million blocks, and they will all be copied, and this is one of the most expensive operations. In the second case, we copy only one block of memory — in which the address is stored in memory — and this is fast and cheap. However, for small data it is recommended to pass all the same by value, because pointers create an additional load on the GC, and, as a result, turn out to be more expensive, but about this somehow in another article.
But now, having this visual representation, how pointers are passed to a function, you can naturally “see” that in the first case changing the variable p in the Foo() function, you will work with a copy and do not change the value of the original variable ( p1 ), change the second one, since the pointer will refer to the original variable. Although in either case, when passing parameters, data is copied.
Okay, the warm-up is over, let's dig deeper and see things a little more complicated.
Arrays and Slices
Slices are initially taken as a regular array. But this is not the case, and, in fact, these are two different types in Go. Let's first look at the arrays.
Arrays
var arr [5]int var arr [5]int{1,2,3,4,5} var arr [...]int{1,2,3,4,5} An array is just a sequential set of memory blocks, and if we look at the Go source ( src / runtime / malloc.go ), we will see that creating an array is essentially just selecting a piece of memory of the right size. Good old malloc, just a little smarter:
// newarray allocates an array of n elements of type typ. func newarray(typ *_type, n int) unsafe.Pointer { if n < 0 || uintptr(n) > maxSliceCap(typ.size) { panic(plainError("runtime: allocation size out of range")) } return mallocgc(typ.size*uintptr(n), typ, true) } What does this mean for us? This means that we can visually present an array simply as a set of memory blocks arranged one after the other:

Each array element is always initialized with a zero value of this type — 0 in this case, an array of integers of length 5. We can refer to them by index and use the built-in len() function to find out the size of the array. When we refer to an individual element of an array by index and do something like this:
var arr [5]int arr[4] = 42 Then we simply take the fifth (4 + 1) element and change the value of this block in the memory:

Okay, now let's figure it out with slices.
Slices
At first glance, they look like arrays. Well, that's very similar:
var foo []int But if we look at the Go source ( src / runtime / slice.go ), then we see that the slice is, in fact, a structure of three fields - a pointer to an array, length and capacity (capacity):
type slice struct { array unsafe.Pointer len int cap int } When you create a new slice, the runtime “under the hood” will create a new variable of this type, with a zero pointer ( nil ) and a length and capacity equal to zero. This is the zero value for the slice. Let's try to visualize it:
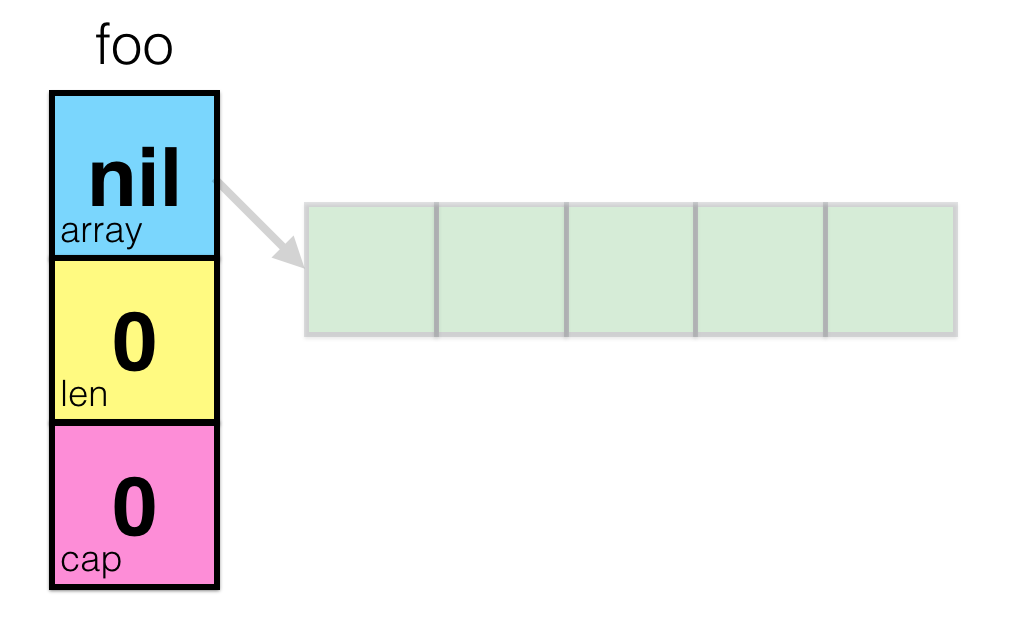
This is not very interesting, so let's initialize the slice of the size we need using the make() built-in command:
foo = make([]int, 5) This command will first create an array of 5 elements (allocate memory and fill them with zeros), and set the values of len and cap to 5. Cap means capacity and helps to reserve memory space for the future to avoid unnecessary memory allocations as the slice grows. You can use a slightly more advanced form - make([]int, len, cap) to specify the capacity initially. To work confidently with slices, it is important to understand the difference between length and capacity.
foo = make([]int, 3, 5) Let's look at both calls:

Now, combining our knowledge of how pointers, arrays and slices are arranged, let's visualize what happens when we call the following code:
foo = make([]int, 5) foo[3] = 42 foo[4] = 100 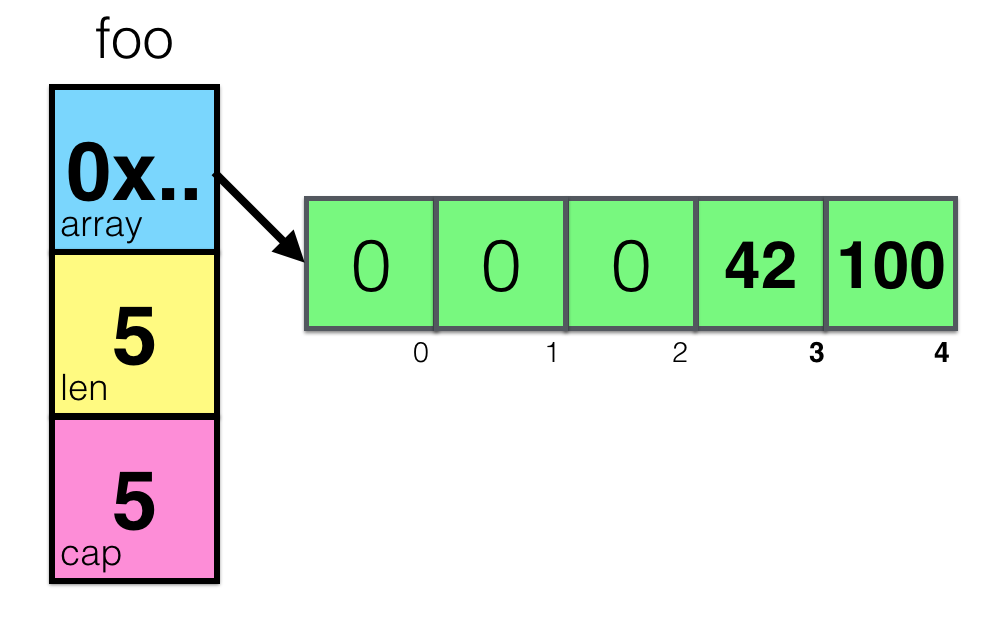
It was easy. But what happens if we create a new sub-element from foo and change some element? Let's get a look:
foo = make([]int, 5) foo[3] = 42 foo[4] = 100 bar := foo[1:4] bar[1] = 99 
Seen the same? By modifying the bar slice, we actually change the array, but this is the same array that the foo slice points to. And this is, in fact, the real thing - you can write code like this:
var digitRegexp = regexp.MustCompile("[0-9]+") func FindDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) return digitRegexp.Find(b) } And, say, having read 10MB of data in a slice from a file, find 3 bytes containing digits, but you will return a slice that refers to an array of 10MB in size!
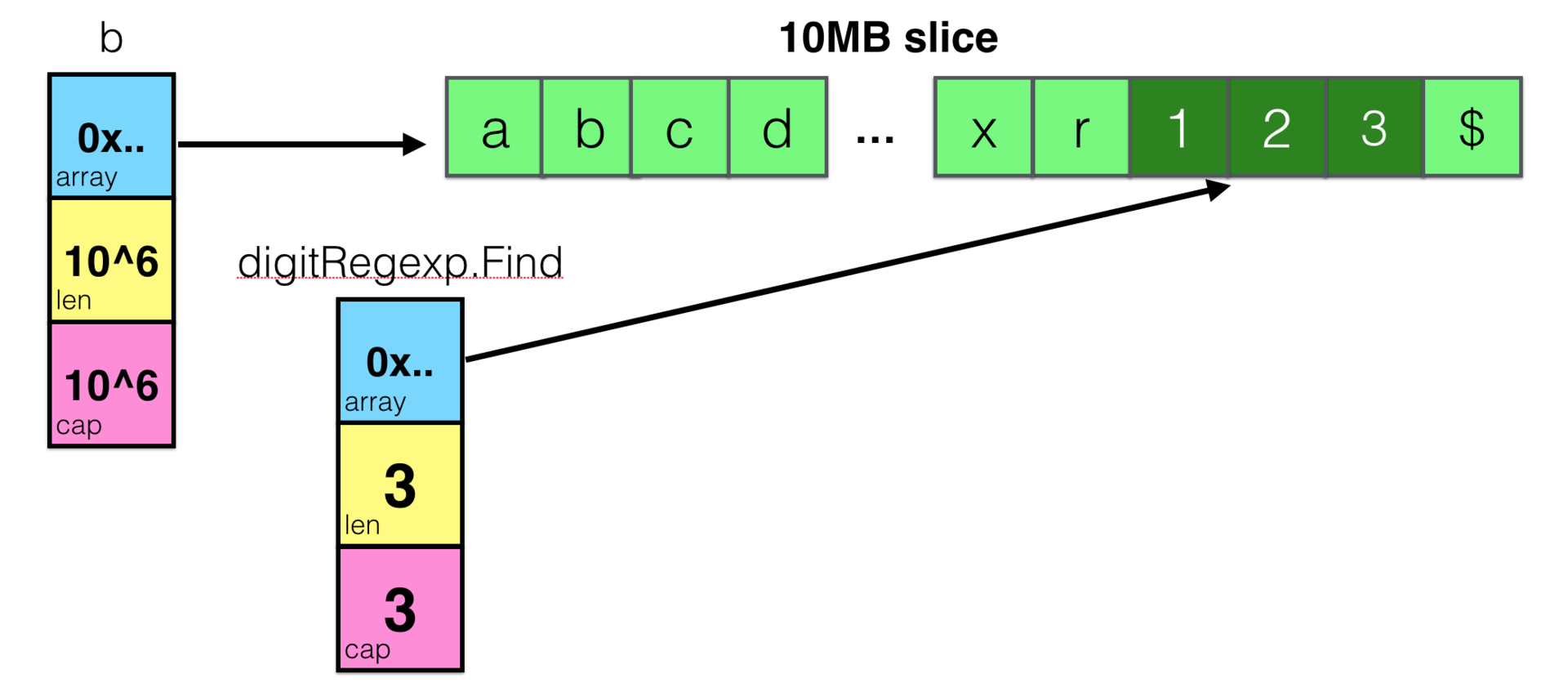
And this is one of the most frequently mentioned gotchas in Go. But now, clearly understanding how it works, it will be hard for you to make such an error.
Append to slice (append)
Following a tricky error with slices, there is a not very obvious behavior of the built-in function append() . She, in principle, makes one simple operation - adds elements to it. But under the hood there are made quite complex manipulations to allocate memory only when necessary and do it effectively.
Take a look at the following code:
a := make([]int, 32) a = append(a, 1) He creates a new slice of 32 integers and adds another, 33rd element to it.
Remember about cap - slice capacity? Capacity means the amount of allocated space for an array. The append() function checks if the slice has enough space to add another element there, and if not, allocates more memory. Memory allocation is always an expensive operation, so append() tries to optimize it, and in this case it requests memory not for one variable, but for 32 more - twice as large as the initial size. Allocating a pack of memory once is cheaper than many times in pieces.
The unobvious thing here is that for various reasons, allocating memory usually means allocating it to a different address and moving data from the old place to the new. This means that the address of the array referenced by the slice will also change! Let's visualize this:
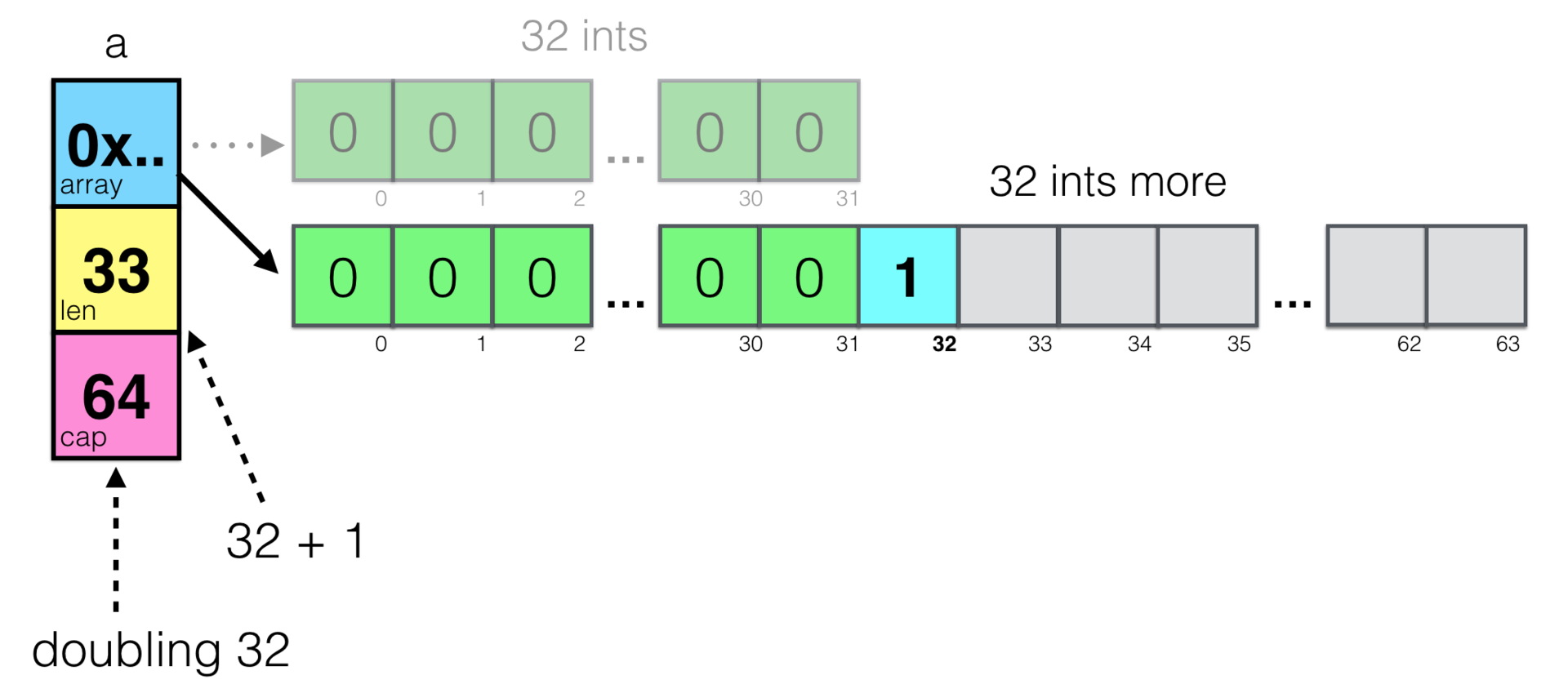
It is easy to see two arrays - old and new. It seems to be nothing complicated, and the garbage collector will simply free up the space occupied by the old array on the next pass. But this is, in fact, one of those very gotchas with slices. What if we make the sub- b , then increase the slice a , meaning that they use the same array?
a := make([]int, 32) b := a[1:16] a = append(a, 1) a[2] = 42 We get this:

This is how we get two different arrays, and two slices will point to completely different memory areas! And this, to put it mildly, is quite counterintuitive, agree. Therefore, as a rule, if you work with append() and subslices - be careful and keep in mind this feature.
By the way, append() increases the slice by doubling only up to 1024 bytes, and then starts using a different approach - the so-called "memory size classes", which guarantee that no more than ~ 12.5% will be allocated. Allocating 64 bytes for a 32-byte array is normal, but if a 4GB slice, then allocating another 4GB, even if we want to add only one element, is too expensive.
Interfaces
Okay, interfaces are probably the weirdest thing in Go. Usually it takes some time before understanding fits into your head, especially after the difficult consequences of long work with classes in other languages. And one of the most popular problems is understanding the nil interface.
As usual, let's go to the Go source code. What is the interface? This is the usual structure of two fields, here is its definition ( src / runtime / runtime2.go ):
type iface struct { tab *itab data unsafe.Pointer } itab stands for interface table and is also a structure in which additional information about the interface and the base type is stored:
type itab struct { inter *interfacetype _type *_type link *itab bad int32 unused int32 fun [1]uintptr // variable sized } Now we will not go into how type conversion works in interfaces, but it is important to understand that, by its very nature, an interface is just a set of data about types (interface and type of variable inside it) and a pointer to the variable itself with static (specific) type ( data field in iface ). Let's see how it looks and define the err variable of the interface type error :
var err error 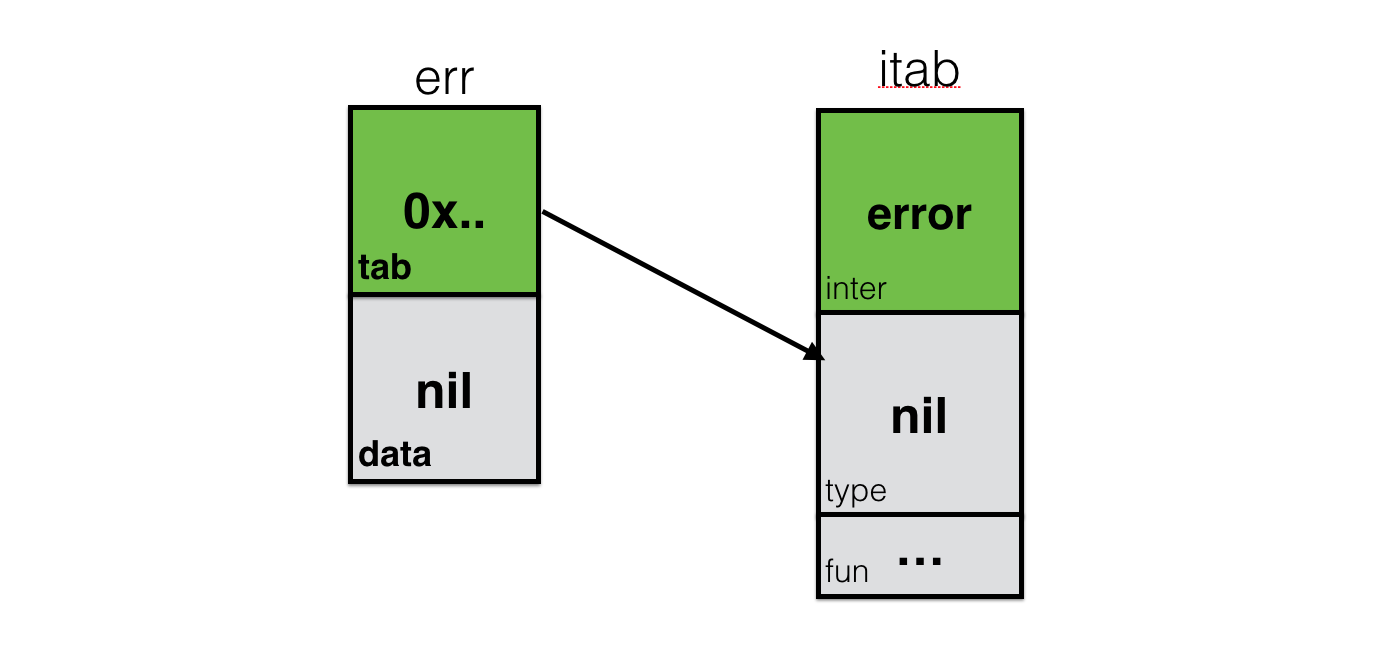
What we see on this visualization is the nil interface. When we return nil in the function that returns error , we return exactly this object. It stores information about the interface itself ( itab.inter ), but the data and itab.type empty - equal to nil . Comparing this object with nil will return true in the if err == nil {} condition.
func foo() error { var err error // nil return err } err := foo() if err == nil {...} // true Now, take a look at this case here, which is also the famous gotcha in Go:
func foo() error { var err *os.PathError // nil return err } err := foo() if err == nil {...} // false These two pieces of code are very similar if you don’t know what the interface is. But let's see how the error interface looks like, in which a variable of the type *os.PathError is "wrapped":

We clearly see here the variable of the type *os.PathError is a piece of memory in which nil written, because it is a zero value for any pointer. But the object that we return from the foo() function is already a more complex structure, which stores not only information about the interface, but also information about the type of the variable, and the address in memory for the block that contains the nil pointer. Feel the difference?
In both cases we see nil as it were, but there is a big difference between "interface with variable inside, whose value is nil" and "interface without variable inside" . Now, understanding this difference, try confusing these two examples:

Now it should be difficult for you to come across such a problem in your code.
Empty interface
A few words about the so-called empty interface - interface{} . In Go sources, it is implemented by a separate structure - eface ( src / runtime / malloc.go ):
type eface struct { _type *_type data unsafe.Pointer } It is easy to see that this structure is similar to iface , but it does not have an interface table (itab). Which is logical, because, by definition, any static type satisfies an empty interface. Therefore, when you "wrap" a variable — either explicitly or implicitly (passing as an argument or returning from a function, for example) interface{} , you are actually working with this structure.
func foo() interface{} { foo := int64(42) return foo } 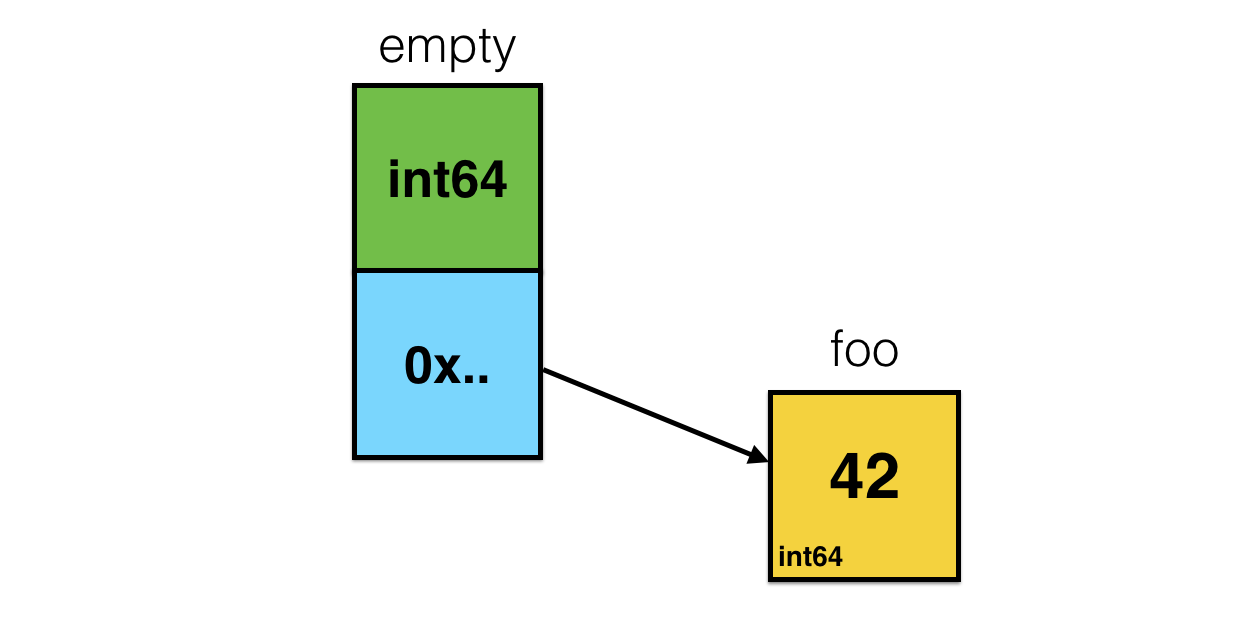
One of the known problems with an empty interface is that it is impossible to bring a slice of specific types to an interface slice in one fell swoop. If you write something like this:
func foo() []interface{} { return []int{1,2,3} } Kompliyator quite clearly swear:
$ go build cannot use []int literal (type []int) as type []interface {} in return argument At first, it is confusing. Like, what's the matter - I can bring one variable of any type into an empty interface, why can't I do the same with a slice? But when you know what an empty interface is and how the slices are arranged, then you must intuitively understand that this “slice cast” is actually a rather expensive operation, which will involve going through the entire slice length and allocating memory directly proportional number of items. And, since one of the principles in Go is - you want to do something expensive - do it explicitly , then such a conversion is left to the programmer.
Let's try to visualize what the cast of []int in []interface{} :
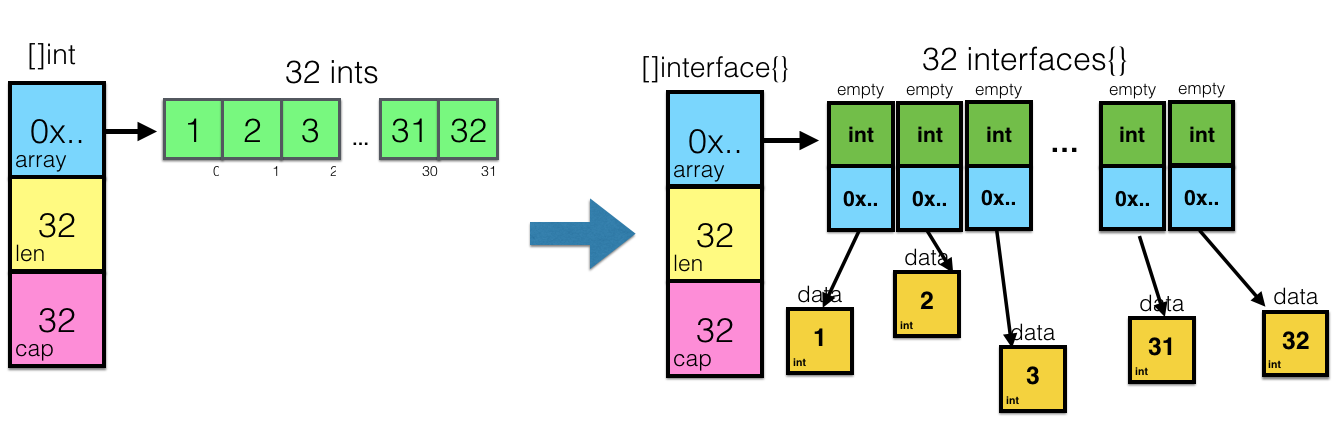
Hopefully now this moment makes sense for you.
Conclusion
Of course, not all gotchas and misunderstandings of the language can be solved by delving into the guts of realization. Some of them are just the difference between the old and the new experience, and it is different for all of us. And yet, the most popular of them, this approach helps to get around. I hope this post will help you to understand more deeply what is happening in your programs and how Go is arranged under the hood. Go is your friend, and knowing him a little better will always benefit.
If you are interested in reading more about Go internals, here is a small selection of articles that helped me in my time:
Well, of course, as without these resources :)
Good coding!
')
Source: https://habr.com/ru/post/325468/
All Articles