Making a spell checker on phonetic algorithms with your own hands
When launching a super-mega-tricked fuzzy search system with morphology support, which showed brilliant results on test cases, the developer is faced with a harsh reality. Users spoiled by the autocorrection of Yandex and Google make mistakes and typos. And instead of a neat page with search results, they get a sad smiley - the car did not understand the request.
Machine spell-caching is a whole art and it’s not for nothing that search giants hire talented mathematicians to work on this task. But there are also simple auto-correction mechanisms based on phonetic principles that are already capable of producing results and improving user experience. We will talk about them in the article. Moreover, they somehow are the foundation for more complex solutions.
At the end of the article there is a link to an open dataset with errors and typos. You can collect valuable statistics on it and test your spellchecking algorithms.
')
All typing errors can be divided into two large classes - spelling and typos. We'll talk about the causes of the first one below, and people make typos why it’s clear - fingers are thick, keyboard is unusual, didn’t get enough sleep (it was, it was), etc.
From the point of view of building an autocorrection system, these errors can be separated, and a universal mechanism can be built. But from the standpoint of user experience, these two types of errors have a fundamentally different weight. If the user is able to quickly see and correct the typo, then this is a spelling mistake, especially if there are several places of uncertainty, the person is much more difficult to correct. Most likely he will google a controversial word, you miss the user's attention and, possibly, lose a site visitor.
Russian letter - phonetic. The principle is simple: the letters are tied to certain sounds and on the letter we convey the sound of the word. (In a very simplified version, of course.) It would seem that business, learned the correspondence of letters and sounds and went to scribble text. Actually it was originally the same - different people wrote the same words differently. There are two problems here. First, all the features of pronunciation are transmitted in writing. And if you can understand someone else's speech, because when we speak we use intonation, there is stress in the words, nonverbalism is added, etc. - to read such a text is quite difficult. Below is an example from Janko Krul Albani :
NB Pay attention! It is especially difficult to recognize short words - the number of options begins to grow at high speed. This feature is also present during machine spelling.
The second problem in the "free letter" arises with legal documents, in which any ambiguity of death is similar. Try to prove that you meant what I meant, if everyone writes and interprets what is written in his own way.
In general, people began to understand the need for unification of letters for a long time. And, we must pay tribute, a great work in this direction was done under the Soviet regime. Actually the modern spelling of the Russian language is not that modern. With some amendments, we all study and use the 1956 system.
So let's summarize. Spelling is an agreement between people, enshrined at the official level, which allows in any situation to convey in a letter a certain meaning expressed in words. In rare situations, there are equivalent spellings of words (tunnel and tunnel), but they can be counted on the fingers.
Any agreement implies a learning curve and, in the case of the Russian language, it is rather long. Because of this, all people own literate letters in varying degrees, and let’s be honest with ourselves, now the literacy situation is not the most optimistic.
The good news is that the reflection of the word on the letter is connected with its sound embodiment. Consequently, there are a limited number of ways to make spelling mistakes in one word.
Further more. All letters can be divided into equivalence classes according to the principle of phonetic proximity of the sounds to which they correspond. Within the boundaries of each class, there is some not very small probability that, on the place of one class letter, the user, having made a mistake, writes another. Choosing one representative from each class and replacing all the letters in the word with a representative of their class, we get a phonetic label.
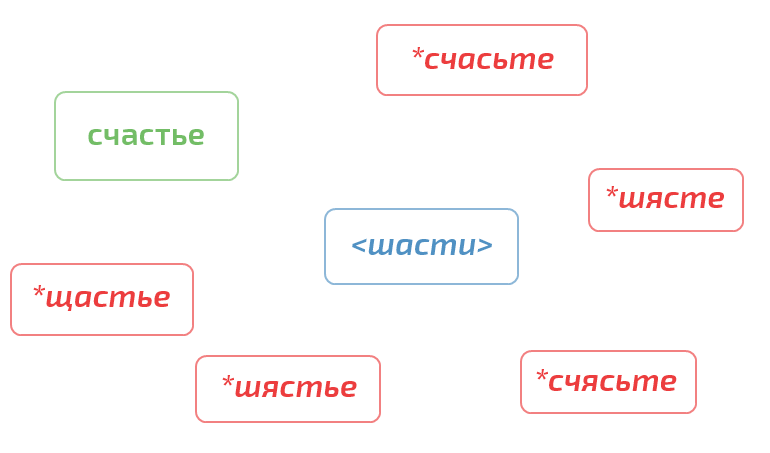
Something reminiscent of the phonetic analysis, which make primary school students. Only now this technique is quite a practical application.
Actually, the idea is not new - similar algorithms, only for the English language, were proposed as early as the beginning of the 20th century and continue to evolve and improve. See Soundex , Metaphone .
From a bird's eye view, the algorithm looks like this:
NB Here and below, phonetic labels at any stage of processing will be enclosed in angle brackets. Erroneous spelling of words will be preceded by an asterisk and italicized. This allows you to reduce the negative effect of working with erroneous spellings of words.
A large class of spelling errors - writing separately / together / hyphenated. Therefore, when compiling a phonetic label, all characters except Russian letters are deleted. This clause applies to vocabulary entries that are stable groups of several words (because; for, abroad).
differently → <differently>
because → <because>
during → <in>
abroad → <abroad>
The second most popular complexity is double consonants. Accordingly, all two or more identical letters are replaced by one:
Art → → Art
It makes sense to repeat the gluing at the last stage, gluing together not the letters, but the sound meters, in order to take into account errors like:
* MANUFACTURING
French (the most popular incorrect spelling is French ).
Soft and hard signs are removed from the word. Often these letters are either forgotten to be put in the right place, or vice versa - they are placed where they should not be ( * Japanese ).
edible → <gray>
space → <space>
stn → sn: local, honest, unknown, skillful
Ndsh → nsh: landscape, mouthpiece, endgame
Stl → sl: happy, pitiful, conscientious
zdn → sign: late, abyss, holiday
vstv → STV: hello, feel, pampering, witchcraft
And also less productive:
Zdts → SC: bridle
LHP → NC: Sun
NDC → NTS: Dutch
ntg → ng: x-ray
RDC → RC: heart
rdch → rf: heart
Typical two-letter combinations with statistically significant cases of errors:
sc, zch, zhch, ssh, ssch, tch → sh ( * sSchastye, * zakShchik, * muschina, * sumashego, * ASChistka )
stg → sg ( * byuzgalter )
xg → g ( * buGalter, * two-year, * three headed )
ts, dts → q ( * detstvo, * gods tsvo, * sporTsmen )
Vowels are replaced by the principle:
a, o, e → a
u, y → y
I, s, and, e, e → and
Consonants are stunning:
b → n
h → s
d → t
in → f
g → k
In some implementations, it is proposed not to stun in a strong position (i.e. if the letter is followed by one of the letters p, l, m, n, v, d or vowel). In fact, it turns out over-complication and the algorithm starts to work worse.
A separate story with hissing and C, not for nothing that they pay so much attention when studying spelling:
w, w, h, w, c → w
The main advantage of the proposed algorithm is that it can be used wherever there is a quick search by index. Those. with any, even the most ancient DBMS. The second important advantage is that such an algorithm is written and implemented in a couple of hours (with a margin).
Its serious drawback is the inability to work with typos, omissions and redundant letters.
NB If we compare it with the common Levenshtein distance test, the phonetic algorithm gives a gain if there are several spelling errors. At the same time, the algorithm L. allows you to catch typos. By combining the strengths of both approaches, one can come to a weighted Levenshtein algorithm.
If you provide users with options to choose from, it would be better, in terms of user experience, to rank them according to the degree of compliance with the original request. It's easy to do this: after stuffing options with an algorithm, compare them with the original query, remembering its probability for each substitution. Then the probabilities of individual replacements are multiplied together and the resulting figure is obtained.
The second opportunity to improve the algorithm is to make additional labels, where one of the symbols is replaced by a joker symbol (for example, an asterisk). This will make it possible to work with typos or specific errors, but the number of tags will increase by an order of magnitude.
The algorithm is a pure heuristic based on the phonetic features of the Russian language and the study of statistics on the errors actually made (you can download the datasheet at the end of the article and experiment on your own). Moreover, the replacements are made intentionally coarse - in experiments, any attempt to fine-tune the algorithm gave deterioration.
If you want filigree rules - look towards machine learning.
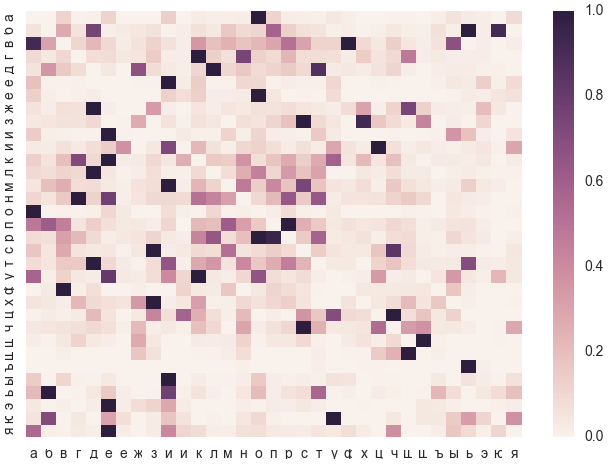
Heat map is readable in rows. For example, for a letter and the most probable error is oh . All other errors are significantly less likely.
And, for example, for b, the most likely error would be typos, w and, rarely, d . Phonetic error n is inferior in frequency to the previous three.
Evaluation of results strongly depends on how to measure.
On the test dataset L1.5 (roughly: the Levenshtein distance in a pair of word-error is not greater than one), which also includes typos, the algorithm gives an accuracy of 25%. But it is in words of any length. If you take the minimum length of 5, then the accuracy will be 34%. For seven (average word length in Russian) - 41%.
There are not enough stars from the sky, but for a simple algorithm this is more than a decent result. If you add a rough stemming with clipping endings, you can pull another 2-3%.
On the test dataset L1.5 + PHON (the previous dataset + word-error pairs equivalent to the phonetic label), the algorithm gives an increase in accuracy by as much as 5%. From the point of view of statistics, mixing the result of the algorithm into the test set is a deadly sin, but this figure indicates that the proportion of multi-orf errors, i.e. where the user is mistaken in several places at the same time, not so small. And this is the ridge of the phonetic algorithm.
If the given quality does not suit you, you will have to invest in smarter algorithms, but it is not so easy to build them on the basis of SUBD indexes.
To practice your auto-correction algorithm, as well as to collect valuable statistics, pick up an open dataset for errors made by real people. Includes both typing and spelling:
Dataset: spelling errors and typos
Machine spell-caching is a whole art and it’s not for nothing that search giants hire talented mathematicians to work on this task. But there are also simple auto-correction mechanisms based on phonetic principles that are already capable of producing results and improving user experience. We will talk about them in the article. Moreover, they somehow are the foundation for more complex solutions.
At the end of the article there is a link to an open dataset with errors and typos. You can collect valuable statistics on it and test your spellchecking algorithms.
')
Spelling errors and typos
All typing errors can be divided into two large classes - spelling and typos. We'll talk about the causes of the first one below, and people make typos why it’s clear - fingers are thick, keyboard is unusual, didn’t get enough sleep (it was, it was), etc.
From the point of view of building an autocorrection system, these errors can be separated, and a universal mechanism can be built. But from the standpoint of user experience, these two types of errors have a fundamentally different weight. If the user is able to quickly see and correct the typo, then this is a spelling mistake, especially if there are several places of uncertainty, the person is much more difficult to correct. Most likely he will google a controversial word, you miss the user's attention and, possibly, lose a site visitor.
Where do spelling errors come from
Russian letter - phonetic. The principle is simple: the letters are tied to certain sounds and on the letter we convey the sound of the word. (In a very simplified version, of course.) It would seem that business, learned the correspondence of letters and sounds and went to scribble text. Actually it was originally the same - different people wrote the same words differently. There are two problems here. First, all the features of pronunciation are transmitted in writing. And if you can understand someone else's speech, because when we speak we use intonation, there is stress in the words, nonverbalism is added, etc. - to read such a text is quite difficult. Below is an example from Janko Krul Albani :
Quote from the play of Ilya Zdanevich
here they do not know Albanian delicacy and the Bishop’s murder gives an action to the Nivoli bis pyrivode, since the Albanian izyk with the Rus goes at yvonnava ... pachimu don’t forget the memory of the staff
... for the harnessing Diruza
... for the harnessing Diruza
NB Pay attention! It is especially difficult to recognize short words - the number of options begins to grow at high speed. This feature is also present during machine spelling.
The second problem in the "free letter" arises with legal documents, in which any ambiguity of death is similar. Try to prove that you meant what I meant, if everyone writes and interprets what is written in his own way.
In general, people began to understand the need for unification of letters for a long time. And, we must pay tribute, a great work in this direction was done under the Soviet regime. Actually the modern spelling of the Russian language is not that modern. With some amendments, we all study and use the 1956 system.
So let's summarize. Spelling is an agreement between people, enshrined at the official level, which allows in any situation to convey in a letter a certain meaning expressed in words. In rare situations, there are equivalent spellings of words (tunnel and tunnel), but they can be counted on the fingers.
Any agreement implies a learning curve and, in the case of the Russian language, it is rather long. Because of this, all people own literate letters in varying degrees, and let’s be honest with ourselves, now the literacy situation is not the most optimistic.
Phonetic principle
The good news is that the reflection of the word on the letter is connected with its sound embodiment. Consequently, there are a limited number of ways to make spelling mistakes in one word.
Further more. All letters can be divided into equivalence classes according to the principle of phonetic proximity of the sounds to which they correspond. Within the boundaries of each class, there is some not very small probability that, on the place of one class letter, the user, having made a mistake, writes another. Choosing one representative from each class and replacing all the letters in the word with a representative of their class, we get a phonetic label.
Something reminiscent of the phonetic analysis, which make primary school students. Only now this technique is quite a practical application.
Actually, the idea is not new - similar algorithms, only for the English language, were proposed as early as the beginning of the 20th century and continue to evolve and improve. See Soundex , Metaphone .
Implementation details
From a bird's eye view, the algorithm looks like this:
- For each word in the dictionary, we apply a series of rules and get a phonetic label at the output - a conditionally simplified sound of the word.
- The word to be checked is compiled into a tag according to the SAME RULES and a dictionary search is performed by a tag.
- The user is offered a choice of several fixes.
- You can use the algorithm for auto-correcting wordy word sequences (for example, search queries), but without additional information about the compatibility of words, quality can suffer on long queries.
- The algorithm is designed to provide the user with options for corrections; it is not worth building it into the search system itself.
Phonetic label compilation rules
NB Here and below, phonetic labels at any stage of processing will be enclosed in angle brackets. Erroneous spelling of words will be preceded by an asterisk and italicized. This allows you to reduce the negative effect of working with erroneous spellings of words.
1. Together, separately, under a hyphen
A large class of spelling errors - writing separately / together / hyphenated. Therefore, when compiling a phonetic label, all characters except Russian letters are deleted. This clause applies to vocabulary entries that are stable groups of several words (because; for, abroad).
differently → <differently>
because → <because>
during → <in>
abroad → <abroad>
2. Double consonants
The second most popular complexity is double consonants. Accordingly, all two or more identical letters are replaced by one:
Art → → Art
It makes sense to repeat the gluing at the last stage, gluing together not the letters, but the sound meters, in order to take into account errors like:
* MANUFACTURING
French (the most popular incorrect spelling is French ).
3. Soft sign, hard sign
Soft and hard signs are removed from the word. Often these letters are either forgotten to be put in the right place, or vice versa - they are placed where they should not be ( * Japanese ).
edible → <gray>
space → <space>
4. Simplify groups of consonants
stn → sn: local, honest, unknown, skillful
Ndsh → nsh: landscape, mouthpiece, endgame
Stl → sl: happy, pitiful, conscientious
zdn → sign: late, abyss, holiday
vstv → STV: hello, feel, pampering, witchcraft
And also less productive:
Zdts → SC: bridle
LHP → NC: Sun
NDC → NTS: Dutch
ntg → ng: x-ray
RDC → RC: heart
rdch → rf: heart
5. Characteristic letter combinations
Typical two-letter combinations with statistically significant cases of errors:
sc, zch, zhch, ssh, ssch, tch → sh ( * sSchastye, * zakShchik, * muschina, * sumashego, * ASChistka )
stg → sg ( * byuzgalter )
xg → g ( * buGalter, * two-year, * three headed )
ts, dts → q ( * detstvo, * gods tsvo, * sporTsmen )
6. Vowels
Vowels are replaced by the principle:
a, o, e → a
u, y → y
I, s, and, e, e → and
Comment on the letters E and I
With the letters E and I, there is an ambiguity to which class they are assigned when compiling a label.

Phonetically, the letter E can transmit two sounds YOT-O. And if you look at the statistics of user errors, then the pair E - O is the most likely. But in practice, if your dictionary is not ötified or users do not use E when typing, then it is better to reduce E to an E-class (s, u, e, e).
The letter I, by analogy, can transmit two sounds YOT-A. But according to statistics, people more often, making a mistake, write E or And instead of I ( * preaya, * kipetok, * extract ). So, the assignment of the I to the E-class (s, i, e, e) will definitely be more profitable.
NB If to be completely corrosive, then after sizzling and C, error A - Z will be more likely. (On the contrary, it cannot be - I never write in Russian spelling after this class of consonants.) You can embed this rule into the algorithm.

Phonetically, the letter E can transmit two sounds YOT-O. And if you look at the statistics of user errors, then the pair E - O is the most likely. But in practice, if your dictionary is not ötified or users do not use E when typing, then it is better to reduce E to an E-class (s, u, e, e).
The letter I, by analogy, can transmit two sounds YOT-A. But according to statistics, people more often, making a mistake, write E or And instead of I ( * preaya, * kipetok, * extract ). So, the assignment of the I to the E-class (s, i, e, e) will definitely be more profitable.
NB If to be completely corrosive, then after sizzling and C, error A - Z will be more likely. (On the contrary, it cannot be - I never write in Russian spelling after this class of consonants.) You can embed this rule into the algorithm.
What letters precede the reference-error pairs indicated on the heat map.
7. Stunning consonants
Consonants are stunning:
b → n
h → s
d → t
in → f
g → k
In some implementations, it is proposed not to stun in a strong position (i.e. if the letter is followed by one of the letters p, l, m, n, v, d or vowel). In fact, it turns out over-complication and the algorithm starts to work worse.
8. Hissing and C
A separate story with hissing and C, not for nothing that they pay so much attention when studying spelling:
w, w, h, w, c → w
Applicability and comparison with other algorithms
The main advantage of the proposed algorithm is that it can be used wherever there is a quick search by index. Those. with any, even the most ancient DBMS. The second important advantage is that such an algorithm is written and implemented in a couple of hours (with a margin).
Its serious drawback is the inability to work with typos, omissions and redundant letters.
NB If we compare it with the common Levenshtein distance test, the phonetic algorithm gives a gain if there are several spelling errors. At the same time, the algorithm L. allows you to catch typos. By combining the strengths of both approaches, one can come to a weighted Levenshtein algorithm.
Ways to improve
If you provide users with options to choose from, it would be better, in terms of user experience, to rank them according to the degree of compliance with the original request. It's easy to do this: after stuffing options with an algorithm, compare them with the original query, remembering its probability for each substitution. Then the probabilities of individual replacements are multiplied together and the resulting figure is obtained.
The second opportunity to improve the algorithm is to make additional labels, where one of the symbols is replaced by a joker symbol (for example, an asterisk). This will make it possible to work with typos or specific errors, but the number of tags will increase by an order of magnitude.
Justification of the algorithm
The algorithm is a pure heuristic based on the phonetic features of the Russian language and the study of statistics on the errors actually made (you can download the datasheet at the end of the article and experiment on your own). Moreover, the replacements are made intentionally coarse - in experiments, any attempt to fine-tune the algorithm gave deterioration.
If you want filigree rules - look towards machine learning.
Heat map is readable in rows. For example, for a letter and the most probable error is oh . All other errors are significantly less likely.
And, for example, for b, the most likely error would be typos, w and, rarely, d . Phonetic error n is inferior in frequency to the previous three.
Absolute (non-normalized) error weights for letter A
469.71785203582147
65.14134525309888
56.298463123398875
55.03770053515469
54.09659475563201
40.64468406336955
28.36510732470879
...I want the same hitmap
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd df = pd.read_csv('https://raw.githubusercontent.com/dkulagin/kartaslov/master/dataset/orfo_and_typos/letter.matrix.csv', sep=';', index_col='INDEX_LETTER') sns.heatmap(df) plt.show() Evaluation of results
Evaluation of results strongly depends on how to measure.
On the test dataset L1.5 (roughly: the Levenshtein distance in a pair of word-error is not greater than one), which also includes typos, the algorithm gives an accuracy of 25%. But it is in words of any length. If you take the minimum length of 5, then the accuracy will be 34%. For seven (average word length in Russian) - 41%.
There are not enough stars from the sky, but for a simple algorithm this is more than a decent result. If you add a rough stemming with clipping endings, you can pull another 2-3%.
On the test dataset L1.5 + PHON (the previous dataset + word-error pairs equivalent to the phonetic label), the algorithm gives an increase in accuracy by as much as 5%. From the point of view of statistics, mixing the result of the algorithm into the test set is a deadly sin, but this figure indicates that the proportion of multi-orf errors, i.e. where the user is mistaken in several places at the same time, not so small. And this is the ridge of the phonetic algorithm.
If the given quality does not suit you, you will have to invest in smarter algorithms, but it is not so easy to build them on the basis of SUBD indexes.
Dataset
To practice your auto-correction algorithm, as well as to collect valuable statistics, pick up an open dataset for errors made by real people. Includes both typing and spelling:
Dataset: spelling errors and typos
Links
Source: https://habr.com/ru/post/325364/
All Articles