Kaggle: British satellite imagery. How we took the third place
I’ll just make a reservation that this text is not a dry squeeze of basic ideas with beautiful graphs and an abundance of technical terms (this text is called a scientific article and I will definitely write it, but then when they pay us $ 20,000 in prizes, and then, God forbid, conversations begin about the license, copyright, etc.. (UPD: https://arxiv.org/abs/1706.06169 ). To my regret, until all the details are fixed, we cannot share the code that we wrote for this task, because we want to receive money. As everything settles down - be sure to deal with this issue. (UPD: https://github.com/ternaus/kaggle_dstl_submission )
So, this text is more like stories based on motives in which, on the one hand, everything is true, and on the other hand, the abundance of lyrical digressions and other ad-libs does not allow to consider it as something science-intensive, but rather just as useful and fascinating. reading matter, the purpose of which is to show how the process of working on tasks in the competitive machine learning discipline can occur. In addition, there is a lot of vocabulary in the text that is specific to Kaggle and I will explain something along the way, and leave something like this, for example, the question about geese will not be disclosed.
A few weeks ago at Kaggle ended the next competition in computer vision. Despite all our efforts, in the team with Sergei Mushinsky we still managed to finish third (the original marshal's plan was to stay in the top 50), which made us involved in the cut of the prize fund, which the British Ministry of Defense allocated. The top three winners share $ 100k: Malaysian Kyle ($ 50k) won first, Roman Solovyov and Arthur Kuzin’s team won the second place ($ 30k), and we, that is, Sergey Mushinsky ($ 20k) and the third. As a side effect, I was in the top 100 in the global ranking, which, of course, does not bother anyone, but is a pleasant addition to the summary.
Hereinafter, I will call Data Scientists the code word "Scientologist", which, on the one hand, underlines the deep connection of Data Sciene with basic science, and on the other, is the standard neologism in slack Open Data Science , which I will call simply - "chat."
')
The success of Kaggle among the Scientologists of Silicon Valley, where I currently live, is quoted roughly next to nothing, and counting on receiving prize money is quite a bold move, so the only true motivation to participate in competitions is the knowledge that is acquired in the process. To whom it is very interesting, a few months ago, when I wrote a similar text , but about a different task , I devoted the entire introduction to the question of motivation in the context of competitive machine learning, where Russian and white described how and why it makes sense to invest some piece of free time in this lesson.
It should be noted that there is a lot of competition, but there is little free time, plus life outside the monitor and keyboard does exist, so the planning process is quite acute.
Each competition at Kaggle, as a rule, is about three months, and at the same time there are several. The organizers are trying to shift them in time, so I have a pretty good method when the competitions are sorted in the order of the deadlines and you work on the task that ends next.
One of the advantages is that closer to the end of the forum is full of fruitful discussions, which, in turn, greatly reduces the time to check what works and what does not, and from the minuses that a couple of weeks in the evenings after work may not be enough to offer something worthy, and with such an approach in the top 10 it is extremely difficult to leave, in any case, I did it only once.
But, since we are not checkers, but go, this approach allowed us to pick up machine learning to a level that was enough to find an adequately paid position Sr. Data Scientist, on which machine learning is much used for work.
All this is wonderful, but there is a nuance. Classical machine learning is fine, but neural networks are much more exciting, and the fact that during the day at work I screw machine learning in production, and in the evenings I read all sorts of clever books and articles about Deep Learning, it seems to me unsatisfactory. Anyway, I want to go to DeepMind, but there is a hypothesis that if I submit there now, no one will look at my resume, for all my articles on theoretical physics, and not on machine learning, but, more fundamentally, I have corny may not have enough knowledge to correctly answer the questions in the interview.
I distribute all these lyrics in order to uncover a simple idea: to cut competitions on Deep Learning, if I want to find interesting work with this very Deep Learning - it’s very necessary and this is almost the most effective option to learn how to work with neural networks in a short time.
Last summer, I stuck on ImageNet and it immediately became clear that my infrastructure was not prepared, some trifles always come out about which the authors of the articles either deliberately or accidentally keep silent about, but you need to know about the various frameworks, not as good as I would like.
All autumn, there were some uninteresting tasks at Kaggle, and in every second - data leak, so instead of machine learning, the public exploited the curvature of the hands of the organizers, but with the beginning of winter the map went to me. In the past couple of months, thousands of experienced Kagglers have been sitting and blinking their eyes in surprise from the fact that since December 6 Deep Learning competitions have started with a total prize pool of $ 1,475,000. As usual, the stacks of xgboost will not go away, you have to spend money on GPU / cloud, go out of your comfort zone, knead your brains and start working with neural networks.
The first among these six competitions was the task that I will continue to talk about.
Formulation of the problem
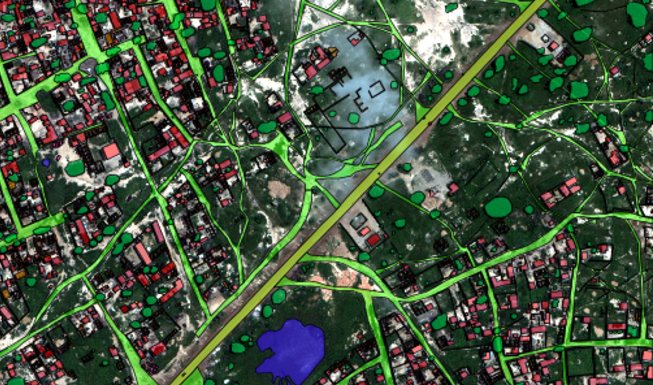
The data were provided by a research laboratory at the Department of Defense of the United Kingdom and compiled 450 satellite images of the Nigerian jungle with a total area of 450 . The fact that this is Nigeria, we learned after the end. The organizers quite well anonymized the data, so for us it was just pictures, without reference to the terrain. I do not think that the purpose of the competition was to get a code that can be inserted into production and boldly begin to direct rockets to African villages. Rather, it was something from the series “send the task, take the popcorn and we will see what these Scientologists succeed in,” that is, the usual Proof Of Concept. The results pleased them so much that they filed their own copy of Kaggle .
In contrast to the classical problems of image segmentation, in this problem each of the pictures is available in a large number of spectral channels. Moreover, these channels have different resolutions and may have shifts in time and space.

At the output, it is necessary to predict class by pixel pixel. It is worth noting that the classes are not mutually exclusive, that is, the same pixel can belong to the car, and the road along which this car drives, and the tree that hangs over this car and the road.
In total, it was necessary to predict belonging to 10 classes, which are extremely unevenly distributed, and even these distributions differ in train and test, plus many classes are few, and there are fewer machines than few.
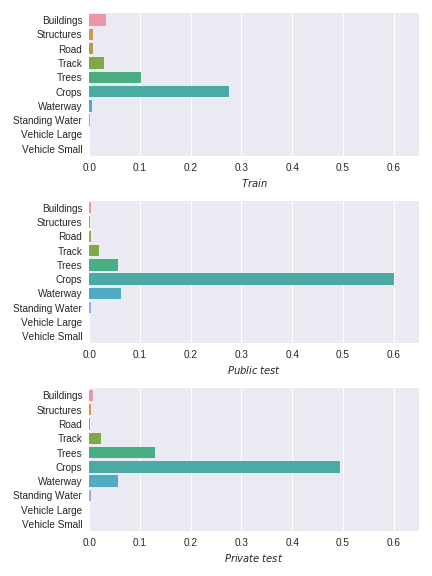
As mentioned above, all data is divided into 26 train set pictures (masks are available for them), and 425 test set pictures, for which the masks should have been predicted. Test set, in turn, was also divided into two parts in the best traditions of Kaggle:
- 19% - Public test
- 81% - Private test
All three months, while the competition was going on, the model's accuracy rating on the Public was known, and when the competition was over, the final result is calculated by the Private part.
Metrics
Accuracy was calculated as the average Jaccard Index for all classes, that is, the fields made the same contribution as the machines, despite the fact that judging by train pixels with fields 60 thousand times more.

That's how it all looks offhand, that is, the task is quite straightforward, especially considering that the similar task , though not about satellite imagery, but about ultrasound scans, and not for roads and houses, but for finding the nerves, I already worked. But in general, from the technical side, it is image segmentation as it is.
Nuances
For any competition, and indeed machine learning tasks, the most important first step is to write a pipeline that takes raw data, cleans, caches, trains something, performs validation and prepares a submit. And usually, for what, often rightly, Kaggle is poor, the data is more or less clean and everything is quite straightforward from the technical side and the main problems arise at the stages of feature engineering and training of models, but then the British military added British exotics.
Problem one
I look at what the organizers have marked for us and do not understand what to do with it. To train a neural network, I need a matrix
(height, width, num_channels) , and I don’t have the slightest understanding how to get it.Something like this looks like this:
'MULTIPOLYGON (((0.005311 -0.009044999999999999, 0.00531 -0.009035, 0.00531 -0.009024000000000001, 0.005318 -0.009018999999999999, 0.005327 -0.009016, 0.005341 -0.009016, 0.005356 -0.009017000000000001, 0.005372 -0.009023, 0.005375 -0.009031000000000001, 0.005375 -0.009044999999999999, 0.005311 -0.009044999999999999)), ...Some polygons, and a lot of non-integer digits. We climb to the forum and, as usual, there is a good soul who shared the code that performs the desired transformation.
Problem two
Proper validation is 90% success. There is no such question on ImageNet - there the organizers choose a subsample that represents the full distribution well and provides it to the participants. Anyway, there are so many pictures there that almost any subsample will work fine. On Kaggle everything is usually different. Precedents, when the data is well balanced, and local validation corresponds to what we see on the leaderboard, exist, but this is the exception rather than the rule. Looking ahead, I will say that we, as well as, probably, all the others, have not solved the problem with the validation of our results. Roman Solovyov (his team finished in second place) had some kind of system, with cross-validation , but I treat it with a certain degree of skepticism.
The idea is that there are few pictures, and they correspond to quite different areas. That is, Train, Public and Private are three different distributions, strongly correlated, but, nevertheless, different, as can be seen in the picture above.
Problem three
God bless her with validation to get to the first submission, you can disable it. I take the standard workhorse of Unet segmentation tasks, write the entire infrastructure with the formation of batches on the fly, augmentation with transformations of the D4 group , I train the network predicting all 10 classes at a time, something even converges somewhere.
I trained. Cool. Then what? The next problem is how to make the prediction itself. The network was trained on random crocs of 112x112 in size from 3600x3600 images and at this stage it was necessary to create an infrastructure that would cut a large image into small ones, predict, correctly handle edge effects, and then assemble everything back. This is a dreary, but straightforward piece, although, as it turned out later, I nakosyachil on it too.

Fourth problem
Cool. I already sense that I have almost reached a submission, and for every big picture I can create a mask. But this is not enough. Kaggle takes the prediction in the form of polygons, and it is not a trivial task to overtake masks into polygons on the fly. I climb on a forum. There is some kind of code. I screw it. I collect - size 4Gb. I upload to the site, the download takes longer than a long time, something starts to count, and the submit fails. I climb to the forum, and there already is a branch, in which intelligently, but without a mate, they discuss this particular problem. I attach some of the proposed solutions to the submission, now the file is only 2Gb, which is still a lot, but it's better to load it, and this time the download lasts two times faster than a very long time, something starts spinning, and on the screen This is a capacious message.

And now, after all the movements, a month has already passed, and I never made the first submit. It is worth noting that, in parallel with this whole process, I began to look for work focused on Deep Learning, in order to aggravate my knowledge in this area as part of paid work, and not in the evenings, killing my free time. The pompous Indians who interviewed me more than once said something like: “Kaggle for children, there is clean data, and you don’t really need to write the code, not what we have here in Horns and Hooves.” And in many respects they are right, but in the context of this task about satellite imagery on the head to hit such characters, of course, I wanted to.
So, I suffer. Not a damn thing and it’s not clear where to dig. I strongly sinned on the net, saying that it mows me, and therefore the error in the broken polygons because it predicts badly, the polygons in the submite are highly fragmented, which leads to a large submission size, plus the polygons have some kind of wrong format, which leads to mistakes. And the whole month with all this, I unsuccessfully snuggled. It should be noted that I was not the only one who had a similar success, but also the majority of the participants, which led to the fact that many did not want to suffer with all this overhead projector and piled it on to more straightforward but equally dull parallel contests on the classification of small fish and lung cancer. . A month before the end, there were about 200 people on the Leadeboard, and only 50 of them were above the sample submission.
So what do we want? Get a lot of knowledge in the problem of segmentation of satellite imagery. But what do we have? Yes, we don't have a damn thing, a bunch of code with some kind of networks that do not understand how they work, if they work at all.
There remained 30 days, and in order for something to stick together during this period, it was necessary to make a knight's move, which was successfully accomplished. In chatik (Slack channel Open Data Science) there is a room kaggle_crackers, in which, in theory, there is an intelligent discussion of current and past tasks on machine learning. Actually, there I started to actively ask questions about this problem, in the mode “here is an error, who faced?”. One of the chat participants, namely, a simple brutal guy Kostya Lopukhin (finished fifth in the extremely strong DL quartet), while I bleated and stumbled, hacked through the OpenCV documentation and shapely, and wrote the correct and fast code for driving from the mask to the polygons, which allowed to make submissions of adequate size, and this was a turning point for the whole competition, I would even say epochal. Actually, it all started with this. This function was used by 90% of the participants, and indeed, if it were not for Kostya, the British military would be sitting and swearing at Scientologists, and not filed their Kaggle.
I screwed the function, made a submit, got 0 and the last place on the Leaderboard. It was connected with the next trick from the organizers: it turns out that there were some muddy coefficients that were used for anonymization, and they had to be taken into account, and after I took them into account, it turned out that I had very adequate networks and gave the result in the top 10%. The issue with errors in sabmite was decided to blow up the polygons, because, it turns out, the Kaggle code does not like polygons with strongly sharp corners, and if I don’t lie, Alexander Movchan suggested this solution.
Word for word, the discussion of this task in the core channel began to attract those to whom this task seemed interesting, especially when it became clear that all unhealthy engineering, which everyone does at work for money, but no one wants to do it in their free time and for free, surmountable
The second landmark event happened when Arthur Kuzin (finished second in command with Roman Solovyov ) decided to show that analysts at Avito were not done with a finger, and that now he will show his high class to a Scientologist from the valley, and started the kernel on Kaggle, which gives the end2end solution that is, it cleans the data, trains the model and makes a prediction that attracted a couple of hundred more people to participate in solving this problem.
A separate channel was created for this case, Arthur invited Roman Solovyov to chat, who is known on Kaggle as the legendary ZFTurbo, and in Russia as a modest researcher in one of the design offices. Also Alexey Noskov joined the chat. Apparently, he was invited after being on the second place in the Outbrain Click Prediction competition, which ended in January. My future partner, Sergei Mushinsky, also decided that it was enough to kick the noodle in the Siberian snows and took up the code and reading literature. Separately, I would like to mention Andrei Stromnova , who did not even participate in the competition, but since he was very knowledgeable in the subject area, he advised us a lot on the specifics of working with satellite imagery.
The team caught up with the engineering, we figured out, there were three weeks left, and what did we have?
It is absolutely incomprehensible how to locally validate. The standard way - to take 5 pictures in holdout set and use them for validation - I was very worried, because it led to the fact that we have train, validation, Public and Private - these are four different distributions, and to cut down an already small train is not very wanted to.
Sasha Movchan suggested another way - to bite off a piece from each picture and sprinkle validation from it. In theory, this was better, because it guaranteed that train and validation were from one distribution. But this, of course, is also not a solution, because test is still quite different, although we certainly tested this hypothesis.
In the end, everyone came up with something different. The novel did not spare computer resources and did 5 fold, Kostya and Alexey identified several pictures for validation, someone just believed the Public leaderboard, motivated by the fact that there are 80 pictures, and indeed, it’s hard to overfill the segmentation task.
Sergey and I used the worker-peasant solution and did not use validation at all. Trained until the train loss went to the plateau. After that, predictions were made for the whole test, side by side - a mask and a picture.

And all this was visible through the eyes. On the one hand, it was possible to catch obvious flaws in the code, for example, my network liked to add houses evenly around the edges of the picture, which I decided with the same technique that was used in the original article about Unet, namely, to make padding a reflection of the nearest area of the original picture .
Or in the picture above:
- Ponds predicted in houses and in the middle of roads.
- Incomprehensible pieces of asphalt roads here and there. You can filter at the post-processing stage by the minimum area of polygons.
- Gaps in the predictions of asphalt roads - you can try to fix it through morphological transformations.
It also made it possible to understand what we are burning on False Positive or False Negative and to correct the binarization thresholds. After visually it seemed to us that it was better, the prediction was sent to the Leaderboard. On the one hand, such an approach is a violation of the rules, like, to look at the test is a low style, but on the other hand, it is life, and we did it from despair. At work, they do manual review from time to time, for machine learning without Human In the Loop is a crime.
Summing up about validation - from what I have seen, our approach is the most reliable.
The next question, to which we all the team tried to get an answer - how to catch cars and trucks. There are two classes of them, that is, 20% of the final result is incorporated in them. With machines, the main problems were that there are few of them, each of them is a few pixels on the asphalt, and they are marked in Hindu - somewhere the machine is not marked, somewhere instead of a car there is a trash can, various bands in one the same picture can be taken at intervals of a few seconds, so if the car moves, you can easily get the car in different places on the same picture.

This is the same truck.
Other teams used solutions of varying degrees of efficiency, but our team decided, again, to do it in a simple way: we scored on machines, aware that we were definitely losing this. Perhaps now, when I greatly improved my skills and knowledge in localization tasks, I would have acted differently, but at that moment, it seems to me, this was the most correct decision.
Another nuance that this competition possessed is the submission format and the metric, which allowed to make predictions for individual classes and check what this corresponds to on the Leaderboard. On the one hand, this allowed the participants to go into silent mode, and on the other, to have a more accurate assessment of the predictions. Classes are so different that it’s very difficult to measure progress in predicting them all at once. From these considerations, everyone began to make predictions class-by-class, which led to the appearance of a summary table, which looked like this:
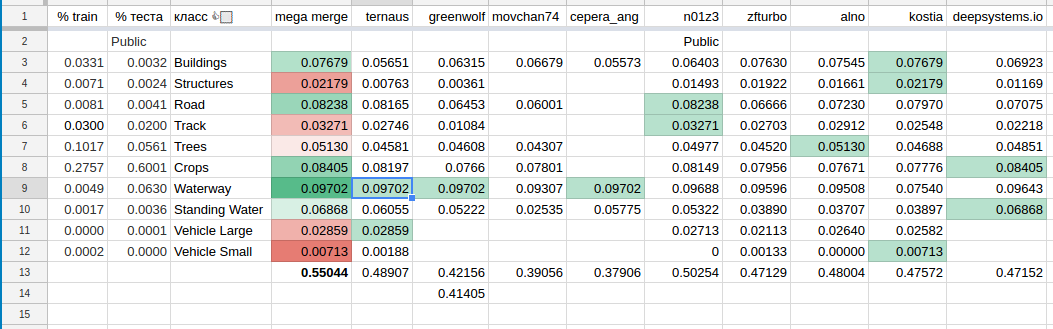
In turn, this led to the formation of teams among those who believed that this would greatly improve the result. At first Arthur and Roman got into the team, after them Alexey, Kostya and the guys from deepsystems.io . And then Sergey and I formed a team, and we got quite comfortable because of the very different time zones (Angarsk - San Francisco), a sort of shift work.
Standard technical question: which network to use? Each article claims that they, the State of The Art, even if they do not lie, then this State Of The Art was on other data, and their experience is not necessarily transferred. To assess what can be used from the literature and what is not, adequate validation is needed, and we, as noted above, did not have it. All the articles that we discussed operate with some kind of pure big data, but something like that has never been encountered in this Nigerian foul-heartedness with which we worked.
And, of course, a person who understands segmentation tasks may have a legitimate question: “Have you tried using method X from article Y, for example, CRF for post-processing?” Or “Have you tried network architecture Z, say, DenseNet variation for segmentation? Most likely, the answer is yes, we shoveled the cubic meters of literature, and many of the ideas were embodied in the code and checked, but not in the mode that everyone tried everything, more likely this way: someone tried it, it didn’t go down, he shared it with the others, and those already for this time did not lose.
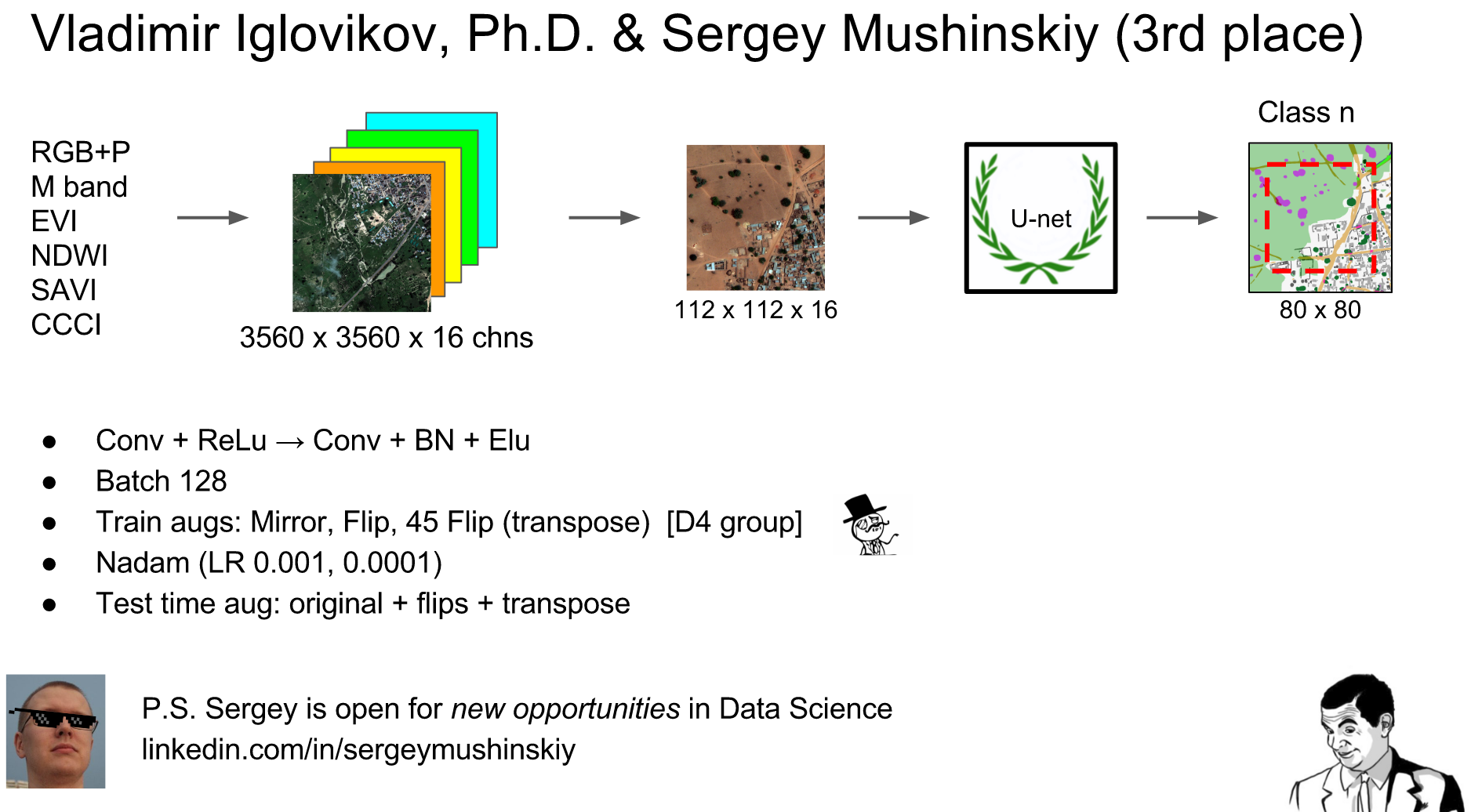
Unlike the standard segmentation task, where in RGB pictures we need to distinguish cinderella from Cheburashek pixel by pixel, we had a lot of input channels in different ranges and this had to be somehow taken into account. The simple option is to stick everything together in one big sandwich and train on it (Roman did this), or make a tricky network with different entrances, what did Arthur do? Trust the network or help her old-fashioned methods, namely, to do segmentation through indices? What to do with RGB? RGB satellite does not produce. It turns out that the M band in low resolution is mixed with the P band, which is high, a pinch of tobacco is added and RGB is obtained. This was shown in the first Vladimir Osin kernel .
Our team did this: we found fast and slow water through indexes based on the second kernel from Vladimir Osin.
And for the rest of the classes we collected RGB, P, M and glued 4 additional indexes Enhanced vegetation index (EVI) , Normalized difference water index (NDWI) , Canopy Chlorophyl Content Index (CCCI) , Soil-Adjusted Vegetation Index (SAVI) . All of these indices do not add any new information, so the network would figure it out, but, bearing in mind how adding quadratic interactions between features helped the gradient boosting in the Allstate problem , even though this boosting should find the high-level interactions itself, we have added.
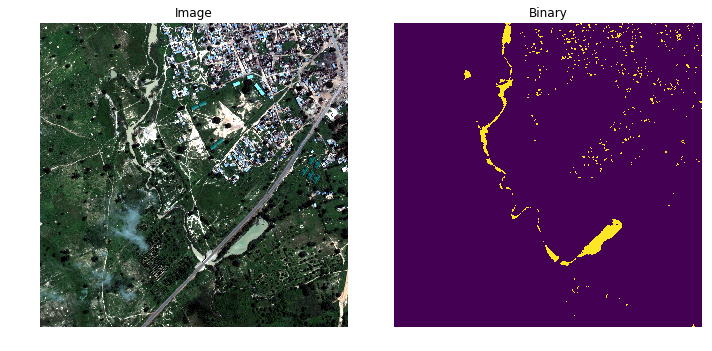
As you can see, in this picture the water through the indices is very good, so similar techniques have been used since multispectral satellite imagery began to be taken.
After that, all of this was fed into the input of the stranded Unet. Unet is something like this:
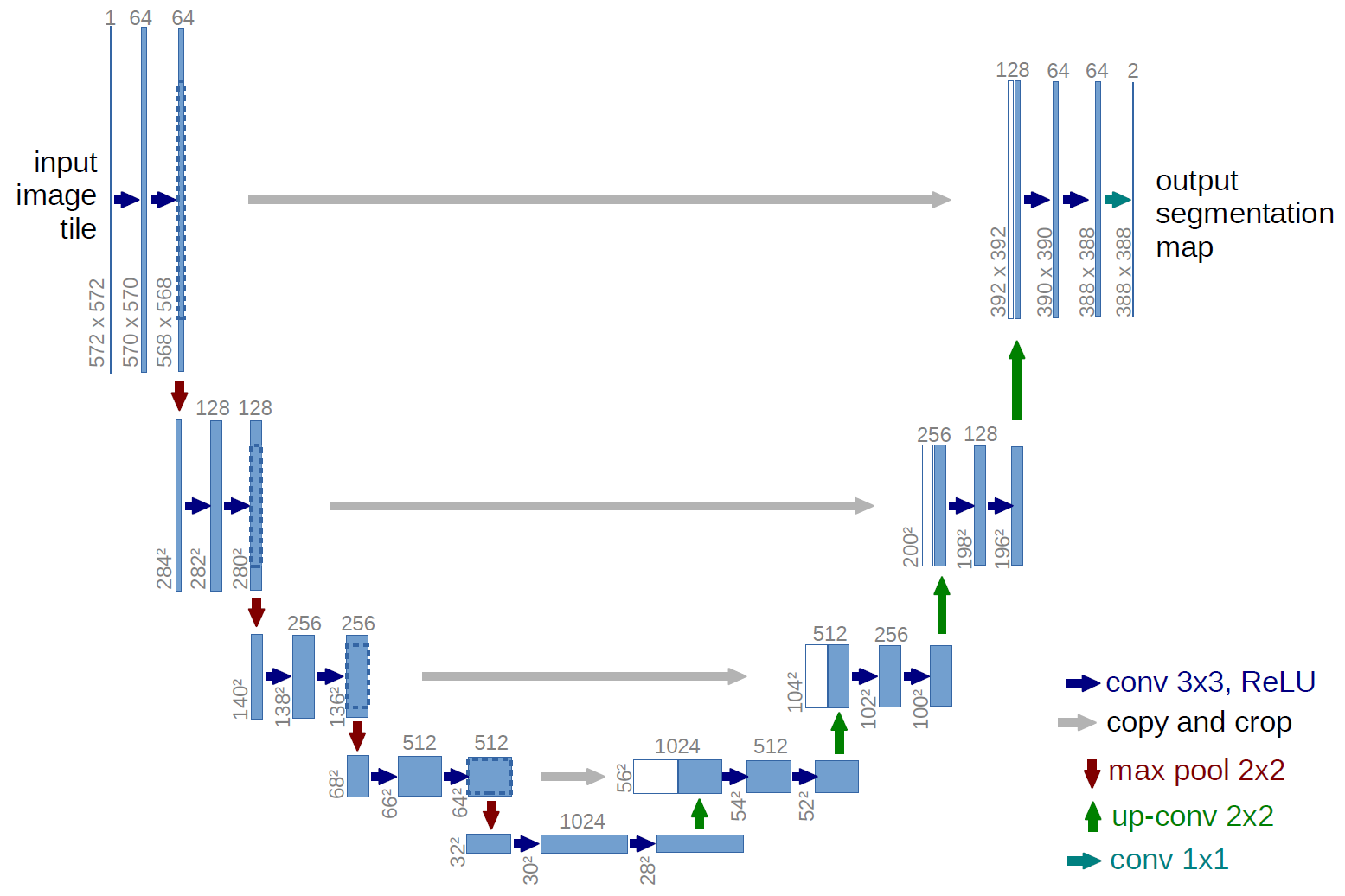
(a picture from the original article , we had a slightly different way (we added BatchNormalization, replaced Relu with Elu, cropped differently and changed the number of filters), but in Unet it is also conceptual of Unet in Africa, although there are many An interesting example is the Tiramisu network , to which we had high hopes, but somehow it somehow did not go to anyone but Alexei Noskov.)
We had an unstable impression that since the images in Train are very different, in this problem a large batch is more important than a large receptive field, so we used a batch of 128 images of 112x112 in size and 16 channels each. That is, we fed a matrix to the network input (128, 112, 112, 16).
Sergey checked on his GPU with a 96-picture batch, it went fine, so it might have made sense to use (96, 128, 128, 16), which is generally similar, but slightly better.
I would say more, different classes required different receptive field and different number of channels, say, the fields most likely could be predicted on one M band, the resolution of 1.24 m / pixel was enough for the eyes. You can even reduce. And since there are many of these fields, a large batch size was not required.
There is little data, so during training a random transformation from the D4 group (a symmetry group of the square) was applied to each picture from the batch. Other teams additionally used turns at small angles, but my hands did not reach, and without this, what worked worked more or less, and for machines this was not enough anyway.
We used Nadam as an Optimizer and coached every network of 50 epochs with 400 updates with learning rate = 1e-3, and then another 50 with learning rate = 1e-4
As a loss function, we used the following expression:
$$ display $$ loss = \ left (\ mbox {binary_cross_entropy} \ right) - log \ left (\ frac 1 {10} \ sum_ {i = 1} ^ {10} \ frac {\ sum y_ {true} \ times y_ {pred}} {\ sum y_ {true} + \ sum y_ {pred} - \ sum y_ {true} \ times y_ {pred}} \ right) $$ display $$
A similar loss function performed well in another segmentation task. Intuition for our choice was this: on the one hand, we need the probability of belonging to each class, so binary_crossentropy will show itself well, and on the other, our metric is jaccard, which means it would be nice to add its approximation to the loss function. As a bonus, such a combination simplified life at the threshold selection stage when moving from the probability that a pixel belongs to a mask to a binary value. With this loss function it becomes not very important that you use: 0.3, 0.5 or 0.7. Rather, the difference is, but it is smaller than it would be when using the bare binary_crossentropy.
Each Fully Convolutional Network suffers from the fact that predictions reduce accuracy with distance from the center, which is usually solved by cutting the prediction around the edges and / or overlapping the predictions. We did both.Each predicted mask at the edges was cut off by 16 pixels. Plus, we used test time augmentation, in this mode, which partly reduced the edge effects:
For example, the initial image size (3348, 3396) through ZeroPadding to (3392, 3472)
Leaving the edges in such a ZeroPadding mode is impossible, when I did this, this sharp edge was perceived by the network as a wall of a house, and they turned out at home smeared with an even layer around the perimeter. This is quite easily solved. As I already mentioned, in the original article on Unet this was solved by adding reflection from the original image to this area, and we did the same.

This picture is cut into intersecting pieces 112x112, with 16 pixel overlap. It is going to be in one big batch (and it’s really big: one picture is 3600x3600 ~ 1800 patches 112x112), it is predicted, it can be broken back into a big picture.

But you can aggravate. If you reflect / rotate the original big picture, make a prediction, and then return to the original orientation, it turns out that the cutting was a little different. And if we repeat this several times for different orientations and average (in this case, we used the geometric mean), then on the one hand the question with edge effects will be partially closed, and on the other, test time augmentation, which we have done, reduces the variance of predictions that reinforced concrete adds a little bit to accuracy.
It adds to accuracy, but it also takes considerably longer to predict. Something like five hours for the whole test. Another thing is that it can be parallelized, but at that time only Titan was at home on the computer, so it probably makes sense to use test time augmentation for such tasks closer to the final. Well, it is very expensive.
Made predictions. Everything? Of course not.Remains post processing. For example, you can try to remove all the predictions of houses from fast water, which we believe more than houses, and all the slow water from houses, which we believe more than this slow water.
After that Kostin's function is applied, we make our way through the submission errors, everything becomes good and pleasant, and we get some more points on LeaderBoard.
If we summarize a piece of our decision about neural networks in a nutshell, it may turn out to be something like what Arthur did when he gave a report at ML-training in Yandex that week :
In the last few days, when everyone was already emotionally exhausted, and someone else was physically (closer to the end I got up for an alarm clock a night to restart the network training, predictions, or something else), I wanted, if not bread, then spectacles, and Sergei put Arthur’s script on the forum, in which he corrected bugs + added a couple of improvements, and Mikhail Kamenshchikov donated ready-made weights for the network for this script. And this script gave 0.42 on the Public Leaderboard, that is, at that moment something around 30 places out of 420. Freebies are a sweet word, so people started to massively launch this script, causing anger moans on the forum, though, as it turned out later , on Private Leaderboard everything was much worse, and the whole team of freeloaders flew 100 places down.
Under this case, Mikhail instantly gave birth to such a meme.

This is me to the fact that everyone is exhausted. Those in the top 10 are wondering if they will stay there (dreaming of a Kaggle gold medal, which is a prerequisite for another Kaggle Master / GrandMaster level), and those in the top 3 have similar thoughts, but already about the money.
At the finish, on the Public Leaderboard at top 10:
- 0.5858 - Kyle - Alpha Goose from Malaysia
- 0.5569 - Quartet from Kostya Lopukhin , Alexey Noskov , Renat Bashirov , Ruslan Baykulov
- 0.5484 - Roman Soloviev , Arthur Kuzin
- 0.5413 - Dmitry Tsybulevsky
- 0.5413 - Octet deepsense.io
- 0.5345 - ironbar - unknown Spaniard
- 0.5338 — Kohei —
- 0.5287 —
- 0.5222 — Daniel FG — -
- 0.51725 —
So, in Moscow - the night of March 7, in the top 10 on the Public Leaderboard half of the teams come from our friendly chat. Everyone is waiting for three in the morning, the announcement of the results. It should be noted here that this whole monthly movement around satellite images has fueled the interest not only of the participants, but of a large number of fans who themselves did not try to plunge into the abyss of the reservoir of this engineering mud, which we not only plunged into, but also swam safely by supporting each other from not drowning. It's a little easier for me - I have a different time zone, so I screwed another model in production at work, while simultaneously watching and participating in discussions.
The seventh of March, 3 o'clock in the morning in Moscow, the end of the competition, everyone breathed in, looked at the site - but I do not want to exhale. Everyone wants a denouement, whatever it may be, but it does not occur. But instead, it comes from the admin polite:
I’ve been the one who kept the leader of the leaderboard.
Little chattered, moaned and cursed, emotions poured over the edge.
A week later, a press release came out , with a powerful title: "Dstl's Kaggle competition has been a great success" of the British military about how they are all impressed, and told how much money they possibly spent for it (2,500k), how much they paid Kagge ( 350k for hosting competitions, 100k for prizes), and that they actively and thoroughly analyze the decisions of the winners.
And a little later these winners were announced. In the top ten, only Kyle's alpha goose remained unchanged, the rest mixed a bit, which is not surprising, considering that the Public test and Private test were so different. Arthur and Roman went up from third place to second, with Sergey and me from eighth to third, the quartet lost 3 places and went to fifth, Dmitry Tsybulevsky also lost a couple of places, but Yevgeny Nekrasov rose by three.
The people below ranked much stronger, + - 100 places light. For example, motion 129 => 19 (this is a good card), or 20 => 133 (this is bad). Such movements are a classic example of what happens when Train, Public / Private is different distributions, and either luck or the correct cross validation mechanism will help: by this I mean not what they write in books like “divide by 5 statified fold and everything is fine ", but about the fact that a couple of orders of magnitude more intricate. For example, there is a technique in competitive machine learning that explains how to choose the correct random seed when splitting into folds so that your models have a better ability to predict on data that your model has not yet seen.
But nevertheless, all this movement is still strange. Yes, the team of the overfitt Public LB in the hope that the accuracy of the Private model will be the same. And in theory, it had to be done that way. This is simply because in a train there are 25 pictures, and in Public it is 19% of 425, that is, 80. And 80 are much more than any hold out that you can bite off of a train. The belief that the accuracy of 80 pictures of Public will be similar to the 397 pictures in Private, if not reinforced, but quite logical.
But what happened in reality. After the end of the competition, the admins admitted that in fact only 57 images were marked up. There is a hypothesis that initially the British military had 450 pictures, they hired the Indians to mark the data, and someone on the forum even posted a link to the announcement of this work. Those managed to mark only 57 pictures. But since the competition must begin, we made a knight's move - 25 pictures in Train, 6 in Public, 26 in Private and 397 for noise. That is, the predictions in these 397 pictures we did, but they were not taken into account. Such a focus is done often enough to prevent manual marking, but usually it is announced before the start of the competition, and not after. And chat again raged, moaned and swore.
Rounding out, I will say that I personally wanted to pick up knowledge about the use of neural networks for image segmentation. There are both DL articles and OpenCV tutorials, all this is embodied in the code, plus an infrastructure was written that can be used for any other segmentation task.
I have access to a team of very smart people who can and want to cut down the evil problems in machine learning. The last two years, after registering at Kaggle, I tried to persuade classmates in graduate school, colleagues at work, even co-founded the San Francisco Kagglers meetup group, but all was unsuccessful. And then the card lay down. And this is very, very important.
For the third place I was raised in the Kaggle rating right up to 67 places out of 55,000, which hopefully helps a little with finding Deep Learning oriented work, and the money, which we, by the way, have not yet received, is a pleasant bonus.
What did not work out: I have not yet found a job directly connected with DL, although I am in the process with a couple of companies. But being in the process and getting an offer is not at all the same. Two parallel competitions about fish (150k prize) and about lung cancer (million dollar prize) passed by me, that is, I also received neither knowledge nor money from these tasks. But these are all trifles, against the background of the fact that I figured out the tasks of segmentation of everything that can be done both by classical methods and through Deep Learning.
What did the British military get: they got a Proof Of Concept, what to do with satellite imagery is possible, and that competition is a cheap option to have algorithms for little money, plus a bit of PR.
As I already mentioned, they even filed their own version of Kaggle , and even launched a couple of competitions there, and one of them was about identifying machines on satellite images. True, since at the level of the British Government Russian citizens are considered second-rate people, we cannot claim a prize, the Chinese, it is true, too.
How far are the proposed solutions far from production?
In the form in which they are now, you probably should not be allowed into production, although if you add data, hire DL specialists, test it, tighten the heuristics, you can get more than decent results. But right now, according to our predictions, the British missiles are probably not worth suggesting, so Nigeria can sleep peacefully.
Our blog post on Kaggle (for him it seems promise to give a T-shirt with the inscription Kaggle). It is in English, it has less dynamics, but a bit more technical details - a link .
For those who did get to this part of the text and it’s still not enough, here’s a link to a video from Arthur’s speech in Yandex about his solution of this task plus his post on Habré .
In addition, a video fromRomana (he has professional deformation, interesting visualizations to do.)
And finally, I would like to say a special thank you to all those with whom we have long and stubbornly discussed this task, which allowed us to get to the top. Noted for the better: Sergei Mushinsky , Arthur Kuzin , Konstantin Lopukhin , Andrei Stromnov , Roman Solovyov , Alexander Movchan , Artem Yankov , Evgeny Nizhbitsky , Vladimir Osin , Alexey Noskov , Alexey Romanov , Mikhail Kamenschikov , Rasim Akhunzyanov , Gleb Filatov , Egor Panfilov .
Special thanks to Nastya bauchgefuehl for editing.
Source: https://habr.com/ru/post/325096/
All Articles