Myths about Spark, or Can a Sparkle Java Developer Use Spark?
We continue to decode and in some places improve the hardcore reports of speakers of JPoint 2016. Today the report is smaller, only an hour with a penny, respectively, the concentration of benefit and annealing for one minute exceeds the limit.
So, Evgeny EvgenyBorisov Borisov about Spark, myths and a little about whether Pink Floyd's texts are more valid than Katy Perry’s.
')
This will be an unusual report on Spark.
Usually they talk a lot about Spark, how cool it is, they show Scala code. But I have a slightly different goal. First, I will talk about what Spark is and why it is needed. But the main goal is to show that you, as Java developers, can perfectly use it. In this report we will dispel a few myths about Spark.
I have been a Java programmer since 2001.
By 2003, he started teaching in parallel.
Since 2008, began to engage in consultations.
Since 2009, engaged in the architecture of different projects.
Startup opened in 2014.
Since 2015, I have been the technical leader for Big data at Naya Technologies, which implements big data wherever it can. We have a huge number of clients who want us to help them. We are sorely lacking people who understand new technologies, so we are constantly looking for employees.
There are quite a few myths about Spark.
First, there are some conceptual myths about which we will talk in more detail:
There are a number of technical myths (this is for people who work with Spark or more or less know it):
And the most important myth is about the Pink Floyd group. There is a myth that Pink Floyd wrote (wrote) clever texts, not at all like Britney Spears or Katie Perry. And today we will write a sentence on Spark, which will help analyze the lyrics of all these musicians and reveal similar words in them. Let's try to prove that Pink Floyd is writing the same rubbish as pop performers.
Let's see which of these myths will turn out to be refuted.
By and large, Hadoop is just a repository of information. This is a distributed file system. Plus, it offers a specific set of tools and an API, with which this information can be processed.
In the context of Spark, it is more correct to say that it is not Spark that needs Hadoop, but vice versa, because information that can be stored in Hadoop and processed using its tools (when faced with a performance problem) can be processed faster using Spark.
The question is, does Spark need Hadoop to work?
Here is the definition of Spark:
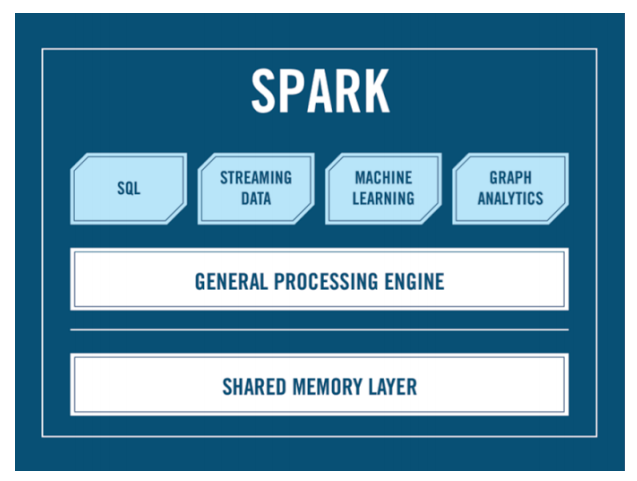
Is there the word Hadoop? There are Spark modules here:
But here there is no word Hadoop.
Let's just talk about Spark.
This idea originated at the University of Berkeley around 2009. The first release was released not so long ago - in 2012. Today we are on version 2.1.0 (it was released at the end of 2016). At the time of the dubbing of this report, version 1.6.1 was relevant, but they promised a speedy release of Spark 2.0, where they cleaned the API and added many new useful things (Spark 2.0 innovations are not taken into account here).
Spark itself is written on Scala, which explains the myth that using Spark is better with Scala, because it turns out the native API. But besides the Scala API exists for:
You can write Spark in InteliJ, which I will do today in the report. You can use Eclipse, and there are more special things for Spark - this is Spark-shell, which now comes with certain versions of Hadoop, where you can write Spark live commands and get instant results, and Notebooks very similar to it - there you can still save what you write for reuse.
You can run Spark in Spark-shell and Notebooks - there it is embedded; using the Spark-submit command, you can start the Spark application on the cluster, you can run it as a normal Java process (java -jaar and say what main is called and where your code is written). Today we will launch Spark in the report. For those tasks that we want to solve, the local machine is enough. But if we wanted to run it on a cluster, we would need a cluster manager. This is the only Spark need. Therefore, it is often the illusion that without Hadoop in any way, because Hadoop has Yarn, a cluster manager that can be used to distribute Spark tasks across the entire cluster. But there is an alternative option - Mesos - cluster manager, which has no relation to Hadoop. It has existed for a long time, and about a year ago they received $ 70 million, which indicates a good development of technology. In principle, who really dislikes Hadoop, can run Spark tasks on a cluster with absolutely no Yarn and Hadoop.
I will say literally two words about data locality. What is the idea of processing big data, which are not on the same machine, but on a large number of them?
When we write some code that works, for example, with jdbc or ORM, what actually happens? There is a machine that starts the Java process, and when the code that accesses the database runs in this process, all data is read from the database and transferred to where the Java process is running. When we talk about big data, it is impossible to do this, because there is too much data - it is inefficient and we have a bottle neck. In addition, data is already distributed and is initially located on a large number of machines, so it’s better not to pull data to this process, but to distribute the code to the machines on which we want to process this “date”. Accordingly, this happens in parallel on many machines, we use an unlimited amount of resources, and here we need a cluster manager who will coordinate these processes.
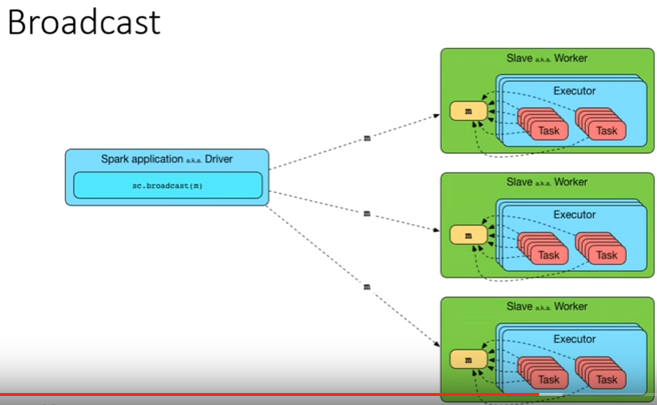
In this picture you see how it all works in the world of Spark.
We have a Driver - our main, which runs on a separate machine (not related to the cluster). When we submit our Spark application, we turn to Yarn, who is a resource manager. We tell him how many workers to use under our Java process (for example, 3). He chooses one machine from the cluster machines, which will be called the Application Master. Its task is to get the code and find three machines in the cluster for its execution. There are three machines, three separate Java-processes rise (three executor), where our code is launched. Then this is all returned by the Application Master, and eventually it returns it directly to the Driver if we want the result of the operation on big data to get back to where the code came from.
This is not directly related to what I will talk about today. Just in a nutshell, how Spark works with Cluster Manager (in this example with Yarn) and why we are not limited in resources (except in cash - how much we can afford machines, memory, etc.). It's all a bit like the classic MapReduce - the old API that was in Hadoop (in principle, it still exists now), with the only difference being that when this API was written, the machines were not strong enough, the intermediate results of the data could only be stored on disk because there was not enough space in the RAM. Therefore, it all worked slowly. As an example, I can say that we recently rewrote the code that was written in the old MapReduce and it ran around 2.5 hours. He now works 1.5 minutes on Spark, because Spark stores everything in RAM - it turns out much faster.
It is very important to understand when you write code that one part of it will be executed on the cluster, and the other part on the Driver. For people who do not understand this, very often OutOfMemory happens, etc. (we'll talk about it - I will show examples of these errors).
So, Spark ... let's go
RDD (resilient distributed dataset) is the main component that runs the entire Spark.
Let's start with the term dataset - it's just a repository of information (Collection). His API is very similar to Stream. In fact, like Stream, it is not a data warehouse, but a kind of abstraction on data (in this case also distributed) and allows you to run all sorts of functions on this data. Unlike Stream, RDD was initially Distributed — it was not on one RDD machine, but on the number of machines that we allowed to use when Spark was started.
Resilient says that you won’t kill him, because if some machine turned off during data processing (something happened there, for example, they turned out the lights), the cluster manager will be able to pick up another machine and transfer the java-process there, and RDD will recover. We will not even feel it.
Where can I get RDD?
Here are some examples of how we create RDD:
We will discuss what sc is a bit later (this is such a Spark starting object). Here we create an RDD:
What will this RDD be? It says here that it is RDD (there is a string in the text file). Moreover, it does not matter if I created RDD from a file (these are the lines of the given file) or from a directory (these are the lines of all the files in this directory).
This is how RDD is created from memory:
You have a parallelize method that takes a list and turns it into RDD.
Now we come to the question of what sc is, which we constantly used to get RDD. If we work with Scala, this object is called SparkContext. In the Java API world, it is called JavaSparkContext. This is the main point from which we start writing the code associated with Spark, because from there we get RDD.
Here is an example of how a Java Spark context object is configured:
The Spark-configuration object is created first, it is configured (you say what the application is called), then you specify whether we work locally or not (the asterisk says how many threads you will find, so much you can use; you can specify 1, 2, etc. d.). And then I create a JavaSparkContext and pass the configuration here.
Then the first question arises: how to divide everything? If I create SparkContext in this way and give it a configuration here, it will not work on a cluster. I need to separate it so that I don’t have anything written on the cluster here (because when the Spark process starts, I need to say how many machines to use, who is the master, who is the cluster manager, and so on). I do not want this configuration to be here; I want to leave only the application name.
And here Spring comes to the rescue: we make two beans. We have one under the production profile (it generally does not convey any information about who the master is, how many machines, etc.), the other under the local profile (and here I pass on this information; you can easily share it immediately). For tests, one bean will work from SparkContext, and for production - another.
Here is a list of the features that RDD has.
They are very similar to the Stream functions: also all Immutable, also return RDD (in the Stream world this was called intermediate operations, and here - transformations). We will not go into details now.
There are also Actions (in the Stream world, this was called terminal operations).
How to determine what is Action, and what is Transformation? As in streams, if the RDD method returns an RDD, this is a Transformation. If not, then this is Action.
Action exists of two types:
How does everything work?
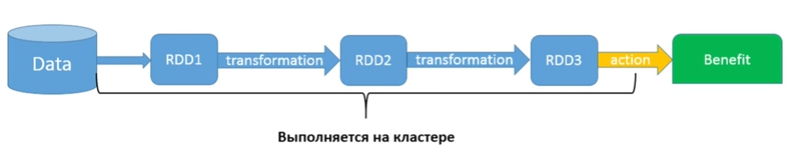
This scheme is similar to streams, but there is one small nuance. We have some kind of data, which is, for example, in s3 storage. Using SparkContext, I created my first RDD1. Then I do all sorts of different transformations, each of which returns me an RDD. In the end, I do Action and get some kind of benefit (saved, printed out or sent what I did). This piece, of course, runs on the cluster (all RDD methods run on the cluster). A small piece at the end will run on the Driver in the event that the result will be some kind of answer. Anything to the left of Data (that is, before I started using the Spark code) will also run on the Driver, and not on the cluster.
All this is Lazy - just like in a stream. Each RDD method, which is a transformation, does nothing, but waits for Action. When there is an Action, the whole chain will start. And here comes the classic question: what are we doing here in this case?
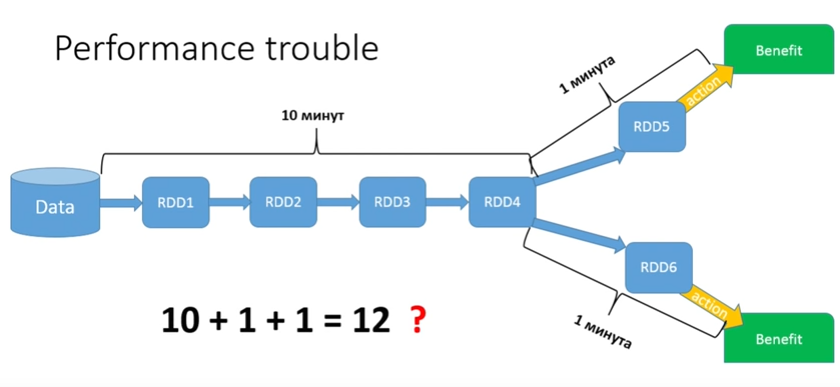
Imagine that my data is all monetary transactions for the last 5 years in some bank. And I need to conduct a fairly long treatment, and then it is divided: for all men, I want to make one Action, and for all women - another. Suppose my first part of the process takes 10 minutes. The second part of the process will require a minute. It would seem that we should have a total of 12 minutes?
No, we have 22 minutes, because Lazy - every time an Action is launched, the whole chain is run from beginning to end. In our case, the common piece runs only 2 times, but if we had 15 branches?
Naturally, it is very hard on performance. In the Spark world, it is very easy to write code, especially for people who are familiar with functional programming. But the nonsense is obtained. If you want to write effective code, you need to know many features.
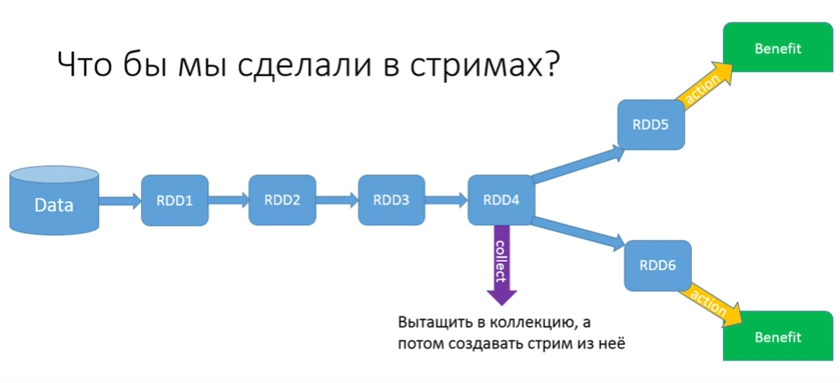
Let's try to solve the problem. What do we do in stream? They would make some kind of collect, collect it all in a collection, and then pull it out of it.
In GetTaxi tried, but it turned out like this:

Moreover, they were going to buy more machines per cluster, so that there were 40 of them and each with 20 gigabytes of RAM.
It is necessary to understand: if we are talking about big data, at the moment when you do collect, all the information from all RDDs is returned to you at the Driver. Therefore, jigabytes and machines do not help them at all: when they make a collect, all the information is merged into one place from which the application started. Naturally, it turns out out of memory.
How to solve this problem (you do not want to drive the chain twice, 15 - all the more, and you can't do collect)? For this, Spark has a persist method:
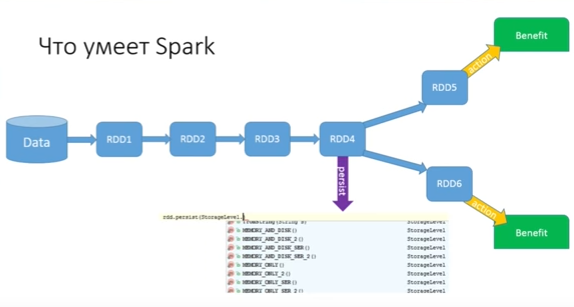
Persist allows you to save the state RDD, and you can choose where to save. There are many options for saving. The most optimal is in memory (there is memory only, but there is memory only 2 - with two backups). You can even write your custom storage and tell how to save it. You can save memory and disk - try to save to memory, but if this worker (the machine that runs this RDD) does not have enough RAM, some will be written into memory, and the remnants will be dumped to disk. You can save data as an object or do serialization. Each of the options has its pros and cons, but there is such an opportunity, and it is wonderful.
We beat this problem. Persist is not an action. If there is no action, persist will do nothing. When the first action starts, the whole chain is run and at the end of the first part of the RDD chain it persists on all machines where data is located. When we start the action RDD6, we start already with persist (if there were other branches, we would continue from the point that we have “remembered” or “marked” persist).
Spark is great, it can be used even for some local needs, not necessarily for big data. You can simply use its API for data processing (it is really convenient). The question arises: what to write? Python and R I dismissed immediately. We will find out: Scala or Java?
What does a regular Java developer think about Scala?

An advanced Java-developer sees a little more. He knows that there is some kind of play, some cool frameworks, lambdas and a lot of Chinese.
Remember the ass? Here she is. This is what Scala code looks like.
I will not go into the Scala API now, because my ultimate goal is to convince you that writing in Java is no worse, but this code considers the length of each line and summarizes the whole thing.
A very strong argument against Java is that the same Java code looks like this:
When I started the first project, the bosses asked if I was sure? After all, when we write, the code will be more and more. But this is all a lie. Today's code looks like this:
Do you see a strong difference between Scala and Java 8? It seems to me that for Java programmers this is more readable. But even despite Java 8, we come to the myth that Spark should be written on Scala. How do people who know that Java 8 is not so bad argue that you need to write on Scala?
For Scala:
For Java:
Why is Java still better? Because we, of course, love Scala, but the money in Java.

Listen to the podcast - Issue 104 - which discusses what happened.
I will tell you in a few words.
A year ago, Martin Odersky, who opened Typesafe in 2010, closed it. No more Typesafe company that supports Scala.
This does not mean that Scala died, because instead of Typesafe another company opened - Lightbend, but it has a completely different business model. They came to the conclusion that even thanks to the cool things written on Scala, like Play, Akka and Spark, and even thanks to the pope mentioned above, it is impossible to get the masses to go to work on Scala. A year ago, Scala was at the peak of its popularity, despite that it was not even included in the first 40 places in the ranking. For comparison - Groovy was on the twentieth, Java - on the first.
When they realized that even at the peak of popularity they still didn’t force people to use Scala among the masses, they recognized their business model as wrong. The company, which today will cut Scala, has a different business model. They say that all products that will be made for the masses, like Spark, will have an excellent Java API. And when we get to the data frames, you will see that there is no longer any difference whether to write in Scala or in Java.
First, I have already shown you that I have a SparkContext, which is registered as a bean. Next we will see how, with a postprocessor bean, we can support some functionality for Spark.
Let's write the code.
We want to write a service (auxiliary) that accepts RDD lines and the number of top words. His task is to return top words. Let's see in the code what we are doing.
Firstly, since we do not know whether the words of the songs are in lowercase or uppercase, we need to translate everything into lowercase so that we do not count words from a capital letter and a small letter two times. Therefore, we use the map function. After that, you need to turn strings into words using the flatmap function.
Now we have an RDD with words in it. We map it against their number. But first you just need to assign each word to one. It will be a classic pattern: we will have the word - 1, the word - 1, then all units against the same words will have to be summed and sorted (everything works in memory, and no intermediate results are stored on the disk if there is enough memory).
We have a mapToPair function - now we will create pairs. The problem is that in Java there is no class Pair. In fact, this is a big omission, because very often we have some information that we want to combine in a specific context, but writing a class is stupid.
The Rock has ready-made classes (there are a lot of them) - Tuple. There are Tuple2, 3, 4, etc. to 22. Why to 22? No one knows. We need Tuple2, because we map 2.
Now all this must reduce-it. We have a reduceByKey method, which will leave all the same words as the key, and with all the values will do what I ask. We need to fold. We have made a pair: the word - the amount.
Now you need to sort. Here we have again a small problem with Java, since the only thing we have sort is sorkByKey. The Scala API is just sortby and there you take this Tuple and pull everything you want out of it. And here - only SortByKey.
As I said, we still feel in some places that the Java API is not rich enough. But you can get out. For example, you can turn our pair. To do this, we once again do mapToPair, and Tuple has a built-in swap function (it turned out a couple number - words). Now we can do sortByKey.
After that, you need to pull out not the first, but the second part. Therefore, we make a map. For pulling out the second part, Tuple has a ready-made function "_2". Now we do Take (x) (we only need x words - the method is called TopX), and this can all be returned.
I'll show you how the test is done. But before that, look at what's in my Java config on Spring (we work on Spring, and this is not just a class, but a service).
In Java config, I read some user.properties (I will explain later why; now I don’t use it anyway). I also scan all classes and prescribe two beans: PropertySourcePlceholderConfigurer - so that you can inject something from a property file, this is not yet relevant; and the only bean that interests us right now is the usual JavaSparkContext.
I created SparkConf, set it up (the program is called music analyst), told him that we have a master (we work locally). We created a JavaSparkContext - everything is great.
Now watch the test.
Since we are working with Spring, the runner is naturally spring. Our configuration is AppConfig (it would be correct to make different configurations for testing and for production). Next, we inject here a JavaSparkContext and the service we want to check. With SparkContext, I use the parallelize method and pass the string “java java java scala grovy grovy” there. Next, I run the method and check that Java is the most popular word.
The test fell. Because the most popular is scala.
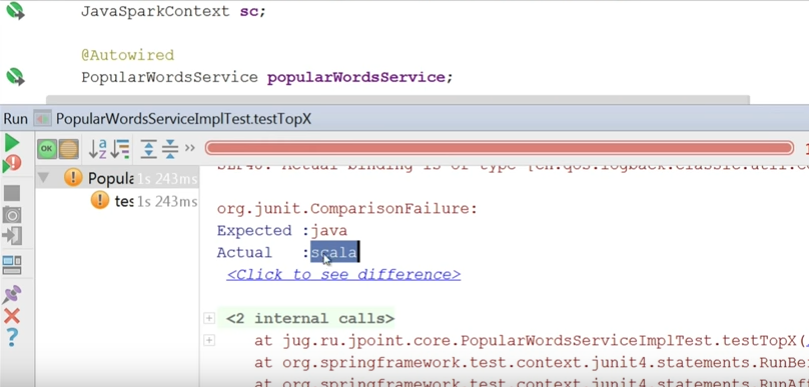
What did I forget to do? When I did Sort, I had to sort it the other way.
We fix in our service:
The test passed.
Now let's try to start main and see the result on a real song. I have a data directory, there is a folder called Beatles, which contains the text of a single song: yesterday. What do you think is the most popular word in yesterday?
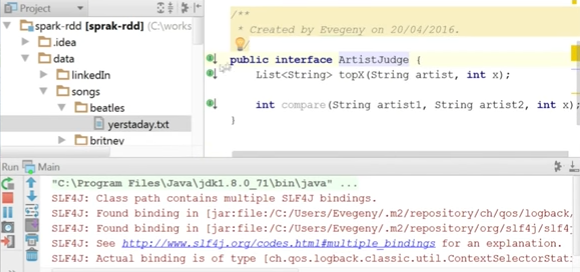
Here I have the service ArtistsJudge. We have implemented the TopX method - it takes the name of the artist, adds the directory in which the songs of this artist are located, and then uses the topX method of the service already written.
Main looks like this:
So, the most popular word is not yesterday, it is “i”:
Agree, this is not very good. We have junk words that do not carry a semantic load (in the end, we want to analyze how much the Pink Floyd songs are deeper and such words will hinder us very much).
Therefore, I had a userProperties file in which garbage words are defined:
It would be possible to immediately inject this garbage into our service, but I don’t like to do that. We have a UserConfig that will be transferred to different services. Everyone will pull out of him what he needs.
Pay attention, I use private for the setter and public for the property itself. But let's not dwell on it.
We go to our PopularWordsServiceImpl, autowired to this UserConfig and filter all words.
main.
, ( ):
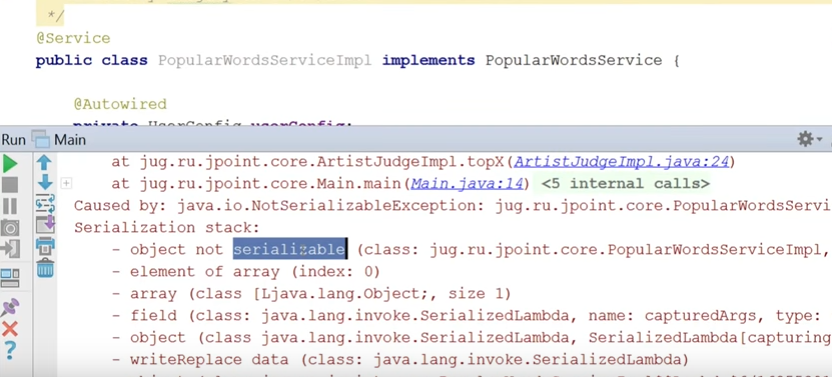
, not serializable. . , UserConfig — serializable.
serializable PopularWordsServiceImpl:
serializable:
map- ( , ) state- - , . Those. UserConfig , serializable. , UserConfig , . , serializable.
. yesterday. — oh, — believe. oh -, .
, , UserConfig worker? ? ? , Spark , , - .
, broadcast-.
, worker- data ( UserConfig ). , , broadcast, . ( ), broadcast .
2 , :
:
.
( ), . , . — - property- worker-. , , :
- Excel-, , 054 — Orange, 911 — . (10 ; 2 — big data) .
:
?
CommonConfig, , .
, :
- Spring, , , data.
! , ( broadcast).
? Driver Worker-, , , , 1 . . , . , , 1000 . Spark-, 10 Worker-.
Worker- - . 10, 1000, 100 . , , , .. - ( 1 , 2, .. 2 ). , worker- , broadcast.
:
context, , broadcast, , broadcast-. , worker- .
What is the problem? :
context (, , Spring). broadcast- , PostConstruct, wrapWithBroadcast. SparkContext , . PostConstruct.
( broadcast , ):
:

SparkContext, . . copy-paste, , broadcast, .

copy-past .
, Spark - ( broadcast — ). , SparkContext, .
:

SparkContext , serializable.
, , , . :
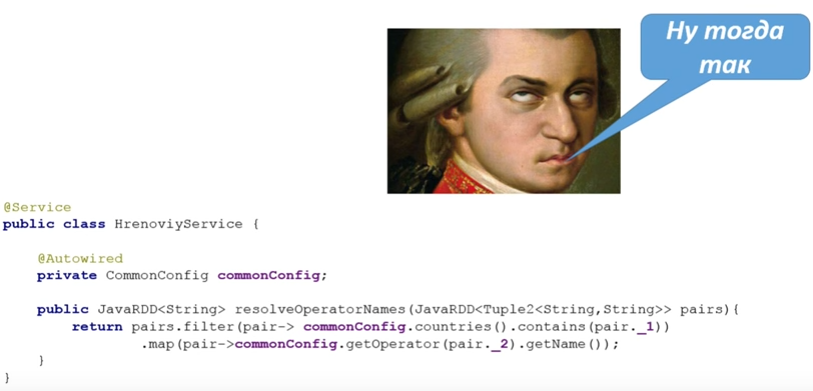
broadcast? , bean:
broadcast-, bean , broadcast.

, , broadcast? , , Service , , broadcast.
.
broadcast UserConfig AutowiredBroadcast. , ?
:
UserConfig.value, .
, bean-, .
.
, Java ( ..). — Scala. , Java 8, 2 . , :
Java GetWords, . Scala . Scala SortBy, Tuple, Scala ( ascending false, false).
? .
DataFrames — API, Spark 1.3. , ( Tuple). RDD, .. RDD , — . ( ), task- .
:
DSL SQLContext ( ).
, :
SQL :
, SQL sqlContext.
, :
:
, . :

keywords (, ).
main.
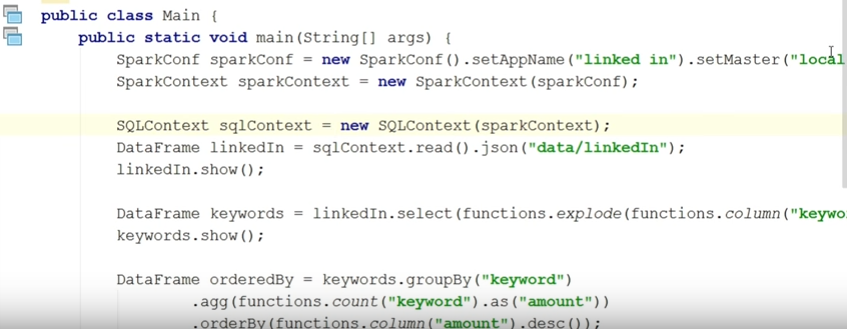
-, , . sqlContext.read.json ( , json, — ; json ). show. :

: , keywords, . . , 30 ( ), .
. linkedIn. select, keywords. , , explode ( keyword ).
. , :

sort .. .
. keyword:
, . keyword- amount. amount descended ( false). :

. :
first — , string ( resultset-). , :
30 . , functions.array_contains. show. Here is the result:

. : XML-, JSON-, . ( )? , Java Scala? , .
WordDataFrameCreator.
, :
. RDD map- . , RowFactory — RDD. RDD, RDD , , , , .. , — . SqlContext.
, SqlContext JavaSparkContext ( AppConfig, SqlContext ). , :
SqlContext , RDD, , , — ( , words, string — true).
API : , - .
:
, , RDD, . API .
lower case . withColumn — , . , , . , count , — descended-. - .
. , ? . , custom-, , .

ustom- ( udf) — , . . notGarbage. , udf1, string (), — boolean ( ).
, :
, , PostConstruct .
callUDF — . — , - . udf-.
UDF , , , @RegisterUDF BPP .
, ( Tomcat, ):
10 :
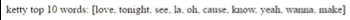
( ):
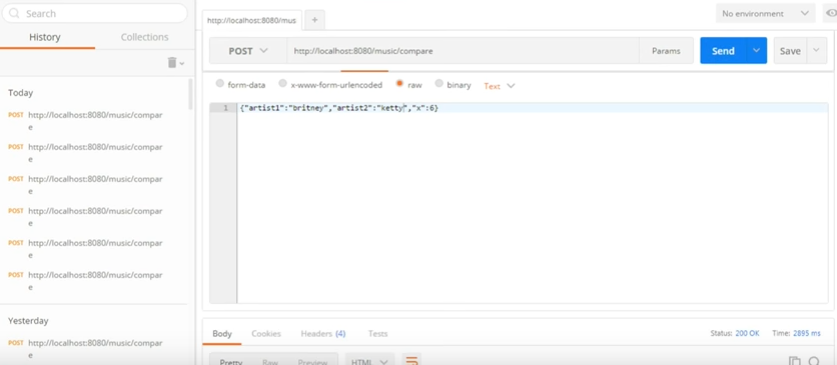
, . 6 4 .
:
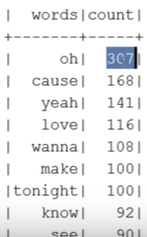
:

Pink Floyd 0 . , :

:

:
— 5 Spark-. , , , . Spark , - . , : , , , — « Spark!» .
— 7-8 JPoint 2017 . : «Spring – » « Spring Test» . , !
, JPoint Java — , .
So, Evgeny EvgenyBorisov Borisov about Spark, myths and a little about whether Pink Floyd's texts are more valid than Katy Perry’s.
')
This will be an unusual report on Spark.
Usually they talk a lot about Spark, how cool it is, they show Scala code. But I have a slightly different goal. First, I will talk about what Spark is and why it is needed. But the main goal is to show that you, as Java developers, can perfectly use it. In this report we will dispel a few myths about Spark.
Briefly about yourself
I have been a Java programmer since 2001.
By 2003, he started teaching in parallel.
Since 2008, began to engage in consultations.
Since 2009, engaged in the architecture of different projects.
Startup opened in 2014.
Since 2015, I have been the technical leader for Big data at Naya Technologies, which implements big data wherever it can. We have a huge number of clients who want us to help them. We are sorely lacking people who understand new technologies, so we are constantly looking for employees.
Myths about Spark
There are quite a few myths about Spark.
First, there are some conceptual myths about which we will talk in more detail:
- that Spark is some kind of lotion for Hadoop. Many have heard that Spark and Hadoop seem to be together. Talk about whether this is true;
- that Spark should be written on Scala. Everyone has probably heard that Spark can be written not only on Scala, but it is right to do it on Scala, because the native API, etc. We'll talk whether this is right;
- I love Spring and wherever possible, I use post-processors. Will post-processors really bring any benefits here?
- Let's talk about what's happening with Spark testing. Since Spark is big data, it is not very clear how to test it. There is a myth that it is impossible to write tests at all, and if you write, then everything will look completely different from what we are used to.
There are a number of technical myths (this is for people who work with Spark or more or less know it):
- about Broadcast - that in certain cases it must be used, otherwise everything will crash down. Let's talk about whether this is so.
- about data frames - They say that data frames can only be used for files that have a scheme, and we will talk about whether you can use them in other cases.
And the most important myth is about the Pink Floyd group. There is a myth that Pink Floyd wrote (wrote) clever texts, not at all like Britney Spears or Katie Perry. And today we will write a sentence on Spark, which will help analyze the lyrics of all these musicians and reveal similar words in them. Let's try to prove that Pink Floyd is writing the same rubbish as pop performers.
Let's see which of these myths will turn out to be refuted.
Myth 1. Spark and Hadoop
By and large, Hadoop is just a repository of information. This is a distributed file system. Plus, it offers a specific set of tools and an API, with which this information can be processed.
In the context of Spark, it is more correct to say that it is not Spark that needs Hadoop, but vice versa, because information that can be stored in Hadoop and processed using its tools (when faced with a performance problem) can be processed faster using Spark.
The question is, does Spark need Hadoop to work?
Here is the definition of Spark:
Is there the word Hadoop? There are Spark modules here:
- Spark Core is a specific API that allows you to process your data;
- Spark SQL, which makes it possible to write SQL-like syntax for people who are familiar with SQL (we’ll talk separately about whether this is good or bad);
- Machine Learning module;
- Streaming so that you can thrust information using Spark or listen to something.
But here there is no word Hadoop.
Let's just talk about Spark.
This idea originated at the University of Berkeley around 2009. The first release was released not so long ago - in 2012. Today we are on version 2.1.0 (it was released at the end of 2016). At the time of the dubbing of this report, version 1.6.1 was relevant, but they promised a speedy release of Spark 2.0, where they cleaned the API and added many new useful things (Spark 2.0 innovations are not taken into account here).
Spark itself is written on Scala, which explains the myth that using Spark is better with Scala, because it turns out the native API. But besides the Scala API exists for:
- Python
- Java,
- Java 8 (separately)
- and R (statistical tool).
You can write Spark in InteliJ, which I will do today in the report. You can use Eclipse, and there are more special things for Spark - this is Spark-shell, which now comes with certain versions of Hadoop, where you can write Spark live commands and get instant results, and Notebooks very similar to it - there you can still save what you write for reuse.
You can run Spark in Spark-shell and Notebooks - there it is embedded; using the Spark-submit command, you can start the Spark application on the cluster, you can run it as a normal Java process (java -jaar and say what main is called and where your code is written). Today we will launch Spark in the report. For those tasks that we want to solve, the local machine is enough. But if we wanted to run it on a cluster, we would need a cluster manager. This is the only Spark need. Therefore, it is often the illusion that without Hadoop in any way, because Hadoop has Yarn, a cluster manager that can be used to distribute Spark tasks across the entire cluster. But there is an alternative option - Mesos - cluster manager, which has no relation to Hadoop. It has existed for a long time, and about a year ago they received $ 70 million, which indicates a good development of technology. In principle, who really dislikes Hadoop, can run Spark tasks on a cluster with absolutely no Yarn and Hadoop.
I will say literally two words about data locality. What is the idea of processing big data, which are not on the same machine, but on a large number of them?
When we write some code that works, for example, with jdbc or ORM, what actually happens? There is a machine that starts the Java process, and when the code that accesses the database runs in this process, all data is read from the database and transferred to where the Java process is running. When we talk about big data, it is impossible to do this, because there is too much data - it is inefficient and we have a bottle neck. In addition, data is already distributed and is initially located on a large number of machines, so it’s better not to pull data to this process, but to distribute the code to the machines on which we want to process this “date”. Accordingly, this happens in parallel on many machines, we use an unlimited amount of resources, and here we need a cluster manager who will coordinate these processes.
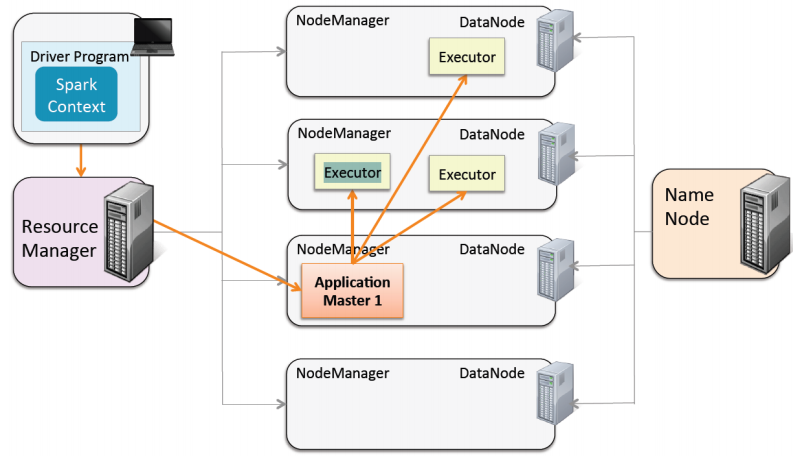
In this picture you see how it all works in the world of Spark.
We have a Driver - our main, which runs on a separate machine (not related to the cluster). When we submit our Spark application, we turn to Yarn, who is a resource manager. We tell him how many workers to use under our Java process (for example, 3). He chooses one machine from the cluster machines, which will be called the Application Master. Its task is to get the code and find three machines in the cluster for its execution. There are three machines, three separate Java-processes rise (three executor), where our code is launched. Then this is all returned by the Application Master, and eventually it returns it directly to the Driver if we want the result of the operation on big data to get back to where the code came from.
This is not directly related to what I will talk about today. Just in a nutshell, how Spark works with Cluster Manager (in this example with Yarn) and why we are not limited in resources (except in cash - how much we can afford machines, memory, etc.). It's all a bit like the classic MapReduce - the old API that was in Hadoop (in principle, it still exists now), with the only difference being that when this API was written, the machines were not strong enough, the intermediate results of the data could only be stored on disk because there was not enough space in the RAM. Therefore, it all worked slowly. As an example, I can say that we recently rewrote the code that was written in the old MapReduce and it ran around 2.5 hours. He now works 1.5 minutes on Spark, because Spark stores everything in RAM - it turns out much faster.
It is very important to understand when you write code that one part of it will be executed on the cluster, and the other part on the Driver. For people who do not understand this, very often OutOfMemory happens, etc. (we'll talk about it - I will show examples of these errors).
So, Spark ... let's go
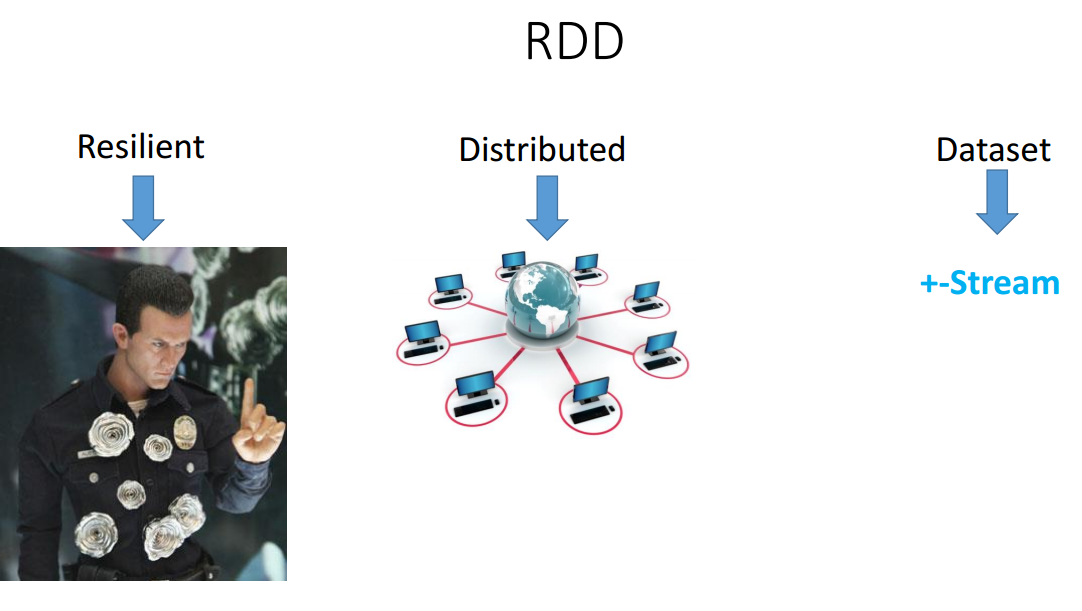
RDD (resilient distributed dataset) is the main component that runs the entire Spark.
Let's start with the term dataset - it's just a repository of information (Collection). His API is very similar to Stream. In fact, like Stream, it is not a data warehouse, but a kind of abstraction on data (in this case also distributed) and allows you to run all sorts of functions on this data. Unlike Stream, RDD was initially Distributed — it was not on one RDD machine, but on the number of machines that we allowed to use when Spark was started.
Resilient says that you won’t kill him, because if some machine turned off during data processing (something happened there, for example, they turned out the lights), the cluster manager will be able to pick up another machine and transfer the java-process there, and RDD will recover. We will not even feel it.
Where can I get RDD?
- the most common option is from a file or directory in which there are files of a certain type. I can create RDD from some file (just like Stream needs a data source);
- from memory - from some collection or list. It is most often used for tests. For example, I wrote some service that accepts RDD as input with some initial data and returns RDD with processed data as output. When I test it, I really don’t want to read data from a disk. I want to create a collection in the test. I have the opportunity to turn this collection into RDD and test my service;
- from another RDD in the same way as streams. Most stream methods return the stream back - everything is very similar.
Here are some examples of how we create RDD:
// from local file system JavaRDD<String> rdd = sc.textFile("file:/home/data/data.txt"); // from Hadoop using relative path of user, who run spark application rdd = sc.textFile("/data/data.txt") // from hadoop rdd = sc.textFile("hdfs://data/data.txt") // all files from directory rdd = sc.textFile("s3://data/*") // all txt files from directory rdd = sc.textFile("s3://data/*.txt") We will discuss what sc is a bit later (this is such a Spark starting object). Here we create an RDD:
- from a text file that is in the local directory (there is nothing to do with Hadoop);
- from file by relation path;
- with Hadoop - here I take the file that is in Hadoop. It is actually broken into pieces, but it will assemble into one RDD. Most likely the RDD will be located on the machines where this data is located;
- You can read it with s3 storage, you can use any wildcard or take only text files from the data directory.
What will this RDD be? It says here that it is RDD (there is a string in the text file). Moreover, it does not matter if I created RDD from a file (these are the lines of the given file) or from a directory (these are the lines of all the files in this directory).
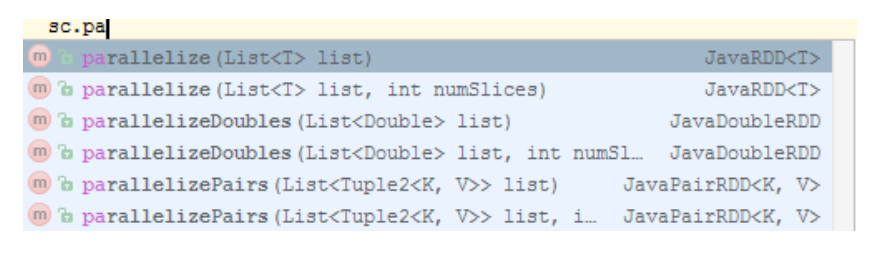
This is how RDD is created from memory:
You have a parallelize method that takes a list and turns it into RDD.
Now we come to the question of what sc is, which we constantly used to get RDD. If we work with Scala, this object is called SparkContext. In the Java API world, it is called JavaSparkContext. This is the main point from which we start writing the code associated with Spark, because from there we get RDD.
Here is an example of how a Java Spark context object is configured:
SparkConf conf = new SparkConf(); conf.setAppName("my spark application"); conf.setMaster("local[*]"); JavaSparkContext sc = new JavaSparkContext(conf); The Spark-configuration object is created first, it is configured (you say what the application is called), then you specify whether we work locally or not (the asterisk says how many threads you will find, so much you can use; you can specify 1, 2, etc. d.). And then I create a JavaSparkContext and pass the configuration here.
Then the first question arises: how to divide everything? If I create SparkContext in this way and give it a configuration here, it will not work on a cluster. I need to separate it so that I don’t have anything written on the cluster here (because when the Spark process starts, I need to say how many machines to use, who is the master, who is the cluster manager, and so on). I do not want this configuration to be here; I want to leave only the application name.
And here Spring comes to the rescue: we make two beans. We have one under the production profile (it generally does not convey any information about who the master is, how many machines, etc.), the other under the local profile (and here I pass on this information; you can easily share it immediately). For tests, one bean will work from SparkContext, and for production - another.
@Bean @Profile("LOCAL") public JavaSparkContext sc() { SparkConf conf = new SparkConf(); conf.setAppName("music analyst"); conf.setMaster("local[1]"); return new JavaSparkContext(conf); } @Bean @Profile("PROD") public JavaSparkContext sc() { SparkConf conf = new SparkConf(); conf.setAppName("music analyst"); return new JavaSparkContext(conf); } Here is a list of the features that RDD has.
map flatMap filter mapPartitions, mapPartitionsWithIndex sample union, intersection, join, cogroup, cartesian (otherDataset) distinct reduceByKey, aggregateByKey, sortByKey pipe coalesce, repartition, repartitionAndSortWithinPartitions They are very similar to the Stream functions: also all Immutable, also return RDD (in the Stream world this was called intermediate operations, and here - transformations). We will not go into details now.
There are also Actions (in the Stream world, this was called terminal operations).
reduce collect count, countByKey, countByValue first take, takeSample, takeOrdered saveAsTextFile, saveAsSequenceFile, saveAsObjectFile foreach How to determine what is Action, and what is Transformation? As in streams, if the RDD method returns an RDD, this is a Transformation. If not, then this is Action.
Action exists of two types:
- those that return something back to the Driver (it is important to emphasize that this will not be on the cluster; the answer will return to the Driver). For example, reduce takes the function of how to collect all the data, and eventually one answer will return (in general, it does not have to be one);
- those that do not return a response to the Driver. For example, you can save the data after processing to the same Hadoop or another storage (for this is the saveAsTextFile method).
How does everything work?
This scheme is similar to streams, but there is one small nuance. We have some kind of data, which is, for example, in s3 storage. Using SparkContext, I created my first RDD1. Then I do all sorts of different transformations, each of which returns me an RDD. In the end, I do Action and get some kind of benefit (saved, printed out or sent what I did). This piece, of course, runs on the cluster (all RDD methods run on the cluster). A small piece at the end will run on the Driver in the event that the result will be some kind of answer. Anything to the left of Data (that is, before I started using the Spark code) will also run on the Driver, and not on the cluster.
All this is Lazy - just like in a stream. Each RDD method, which is a transformation, does nothing, but waits for Action. When there is an Action, the whole chain will start. And here comes the classic question: what are we doing here in this case?
Imagine that my data is all monetary transactions for the last 5 years in some bank. And I need to conduct a fairly long treatment, and then it is divided: for all men, I want to make one Action, and for all women - another. Suppose my first part of the process takes 10 minutes. The second part of the process will require a minute. It would seem that we should have a total of 12 minutes?
No, we have 22 minutes, because Lazy - every time an Action is launched, the whole chain is run from beginning to end. In our case, the common piece runs only 2 times, but if we had 15 branches?
Naturally, it is very hard on performance. In the Spark world, it is very easy to write code, especially for people who are familiar with functional programming. But the nonsense is obtained. If you want to write effective code, you need to know many features.
Let's try to solve the problem. What do we do in stream? They would make some kind of collect, collect it all in a collection, and then pull it out of it.
In GetTaxi tried, but it turned out like this:
Moreover, they were going to buy more machines per cluster, so that there were 40 of them and each with 20 gigabytes of RAM.
It is necessary to understand: if we are talking about big data, at the moment when you do collect, all the information from all RDDs is returned to you at the Driver. Therefore, jigabytes and machines do not help them at all: when they make a collect, all the information is merged into one place from which the application started. Naturally, it turns out out of memory.
How to solve this problem (you do not want to drive the chain twice, 15 - all the more, and you can't do collect)? For this, Spark has a persist method:
Persist allows you to save the state RDD, and you can choose where to save. There are many options for saving. The most optimal is in memory (there is memory only, but there is memory only 2 - with two backups). You can even write your custom storage and tell how to save it. You can save memory and disk - try to save to memory, but if this worker (the machine that runs this RDD) does not have enough RAM, some will be written into memory, and the remnants will be dumped to disk. You can save data as an object or do serialization. Each of the options has its pros and cons, but there is such an opportunity, and it is wonderful.
We beat this problem. Persist is not an action. If there is no action, persist will do nothing. When the first action starts, the whole chain is run and at the end of the first part of the RDD chain it persists on all machines where data is located. When we start the action RDD6, we start already with persist (if there were other branches, we would continue from the point that we have “remembered” or “marked” persist).
Myth 2. Spark write only on Scala
Spark is great, it can be used even for some local needs, not necessarily for big data. You can simply use its API for data processing (it is really convenient). The question arises: what to write? Python and R I dismissed immediately. We will find out: Scala or Java?
What does a regular Java developer think about Scala?
An advanced Java-developer sees a little more. He knows that there is some kind of play, some cool frameworks, lambdas and a lot of Chinese.
Remember the ass? Here she is. This is what Scala code looks like.
val lines = sc.textFile("data.txt") val lineLengths = lines.map(_.length) val totalLength = lineLengths.reduce(_+_) I will not go into the Scala API now, because my ultimate goal is to convince you that writing in Java is no worse, but this code considers the length of each line and summarizes the whole thing.
A very strong argument against Java is that the same Java code looks like this:
JavaRDD<String> lines = sc.textFile("data.txt"); JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() { @Override public Integer call(String lines) throws Exception { return lines.length(); } }); Integer totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer a, Integer b) throws Exception { return a + b; } }); When I started the first project, the bosses asked if I was sure? After all, when we write, the code will be more and more. But this is all a lie. Today's code looks like this:
val lines = sc.textFile("data.txt") val lineLengths = lines.map(_.length) val totalLength = lineLengths.reduce(_+_) JavaRDD<String> lines = sc.textFile("data.txt"); JavaRDD<Integer> lineLengths = lines.map(String::length); int totalLength = lineLengths.reduce((a, b) -> a + b); Do you see a strong difference between Scala and Java 8? It seems to me that for Java programmers this is more readable. But even despite Java 8, we come to the myth that Spark should be written on Scala. How do people who know that Java 8 is not so bad argue that you need to write on Scala?
For Scala:
- Scala is cool, hipster, fashionable, right, you have to move forward. Nafig this Groovy, in Scala everything is definitely cooler;
- Scala - concise and convenient syntax. There is a butt;
- Spark API, because it is written in Scala, is primarily sharpened for Scala. This is a serious plus;
- Java API comes out a little later, because they have to file it, fake it. There is not always everything.
For Java:
- most java programmers know java. These people do not know Scala. In large companies, a bunch of Java programmers, who more or less understood Java. Giving them Scala to write Spark? Not;
- familiar world - there is Spring, familiar design patterns, Maven or even better - Gradle, singleton, etc. We used to work there. And Scala is not only a different syntax, it is a lot of other concepts. In Scala, control inversion is not needed, since everything is different there.
Why is Java still better? Because we, of course, love Scala, but the money in Java.
Listen to the podcast - Issue 104 - which discusses what happened.
I will tell you in a few words.
A year ago, Martin Odersky, who opened Typesafe in 2010, closed it. No more Typesafe company that supports Scala.
This does not mean that Scala died, because instead of Typesafe another company opened - Lightbend, but it has a completely different business model. They came to the conclusion that even thanks to the cool things written on Scala, like Play, Akka and Spark, and even thanks to the pope mentioned above, it is impossible to get the masses to go to work on Scala. A year ago, Scala was at the peak of its popularity, despite that it was not even included in the first 40 places in the ranking. For comparison - Groovy was on the twentieth, Java - on the first.
When they realized that even at the peak of popularity they still didn’t force people to use Scala among the masses, they recognized their business model as wrong. The company, which today will cut Scala, has a different business model. They say that all products that will be made for the masses, like Spark, will have an excellent Java API. And when we get to the data frames, you will see that there is no longer any difference whether to write in Scala or in Java.
Myth 3. Spark and Spring are incompatible.
First, I have already shown you that I have a SparkContext, which is registered as a bean. Next we will see how, with a postprocessor bean, we can support some functionality for Spark.
Let's write the code.
We want to write a service (auxiliary) that accepts RDD lines and the number of top words. His task is to return top words. Let's see in the code what we are doing.
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap) .sortByKey().map(Tuple2::_2).take(x); } } Firstly, since we do not know whether the words of the songs are in lowercase or uppercase, we need to translate everything into lowercase so that we do not count words from a capital letter and a small letter two times. Therefore, we use the map function. After that, you need to turn strings into words using the flatmap function.
Now we have an RDD with words in it. We map it against their number. But first you just need to assign each word to one. It will be a classic pattern: we will have the word - 1, the word - 1, then all units against the same words will have to be summed and sorted (everything works in memory, and no intermediate results are stored on the disk if there is enough memory).
We have a mapToPair function - now we will create pairs. The problem is that in Java there is no class Pair. In fact, this is a big omission, because very often we have some information that we want to combine in a specific context, but writing a class is stupid.
The Rock has ready-made classes (there are a lot of them) - Tuple. There are Tuple2, 3, 4, etc. to 22. Why to 22? No one knows. We need Tuple2, because we map 2.
Now all this must reduce-it. We have a reduceByKey method, which will leave all the same words as the key, and with all the values will do what I ask. We need to fold. We have made a pair: the word - the amount.
Now you need to sort. Here we have again a small problem with Java, since the only thing we have sort is sorkByKey. The Scala API is just sortby and there you take this Tuple and pull everything you want out of it. And here - only SortByKey.
As I said, we still feel in some places that the Java API is not rich enough. But you can get out. For example, you can turn our pair. To do this, we once again do mapToPair, and Tuple has a built-in swap function (it turned out a couple number - words). Now we can do sortByKey.
After that, you need to pull out not the first, but the second part. Therefore, we make a map. For pulling out the second part, Tuple has a ready-made function "_2". Now we do Take (x) (we only need x words - the method is called TopX), and this can all be returned.
I'll show you how the test is done. But before that, look at what's in my Java config on Spring (we work on Spring, and this is not just a class, but a service).
@Configuration @ComponentScan(basePackages = "ru.jug.jpoint.core") @PropertySource("classpath:user.properties") public class AppConfig { @Bean public JavaSparkContext sc() { SparkConf conf = new SparkConf().setAppName("music analytst").setMaster("local[*]"); return new JavaSparkContext(conf); } @Bean public static PropertySourcesPlaceholderConfigurer configurer(){ return new PropertySourcesPlaceholderConfigurer(); } } In Java config, I read some user.properties (I will explain later why; now I don’t use it anyway). I also scan all classes and prescribe two beans: PropertySourcePlceholderConfigurer - so that you can inject something from a property file, this is not yet relevant; and the only bean that interests us right now is the usual JavaSparkContext.
I created SparkConf, set it up (the program is called music analyst), told him that we have a master (we work locally). We created a JavaSparkContext - everything is great.
Now watch the test.
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = AppConfig.class) public class PopularWordsServiceImplTest { @Autowired JavaSparkContext sc; @Autowired PopularWordsService popularWordsService; @Test public void textTopX() throws Exception { JavaRDD<String> rdd = sc.parallelize(Arrays.asList(“java java java scala grovy grovy”); List<String> top1 = popularWordsService.topX(rdd, 1); Assert.assertEquals(“java”,top1.get(0)); } } Since we are working with Spring, the runner is naturally spring. Our configuration is AppConfig (it would be correct to make different configurations for testing and for production). Next, we inject here a JavaSparkContext and the service we want to check. With SparkContext, I use the parallelize method and pass the string “java java java scala grovy grovy” there. Next, I run the method and check that Java is the most popular word.
The test fell. Because the most popular is scala.
What did I forget to do? When I did Sort, I had to sort it the other way.
We fix in our service:
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } } The test passed.
Now let's try to start main and see the result on a real song. I have a data directory, there is a folder called Beatles, which contains the text of a single song: yesterday. What do you think is the most popular word in yesterday?
Here I have the service ArtistsJudge. We have implemented the TopX method - it takes the name of the artist, adds the directory in which the songs of this artist are located, and then uses the topX method of the service already written.
@Service public class ArtistJudgeImpl implements ArtistJudge { @Autowired private PopularDFWordsService popularDFWordsService; @Autowired private WordDataFrameCreator wordDataFrameCreator; @Value("${path2Dir}") private String path; @Override public List<String> topX(String artist, int x) { DataFrame dataFrame = wordDataFrameCreator.create(path + "data/songs/" + artist + "/*"); System.out.println(artist); return popularDFWordsService.topX(dataFrame, x); } @Override public int compare(String artist1, String artist2, int x) { List<String> artist1Words = topX(artist1, x); List<String> artist2Words = topX(artist2, x); int size = artist1Words.size(); artist1Words.removeAll(artist2Words); return size - artist1Words.size(); } public static void main(String[] args) { List<String> list = Arrays.asList("", null, ""); Comparator<String> cmp = Comparator.nullsLast(Comparator.naturalOrder()); System.out.println(Collections.max(list, cmp)); /* System.out.println(list.stream().collect(Collectors.maxBy(cmp)).get()); System.out.println(list.stream().max(cmp).get()); */ } } Main looks like this:
package ru.jug.jpoint; import org.springframework.context.annotation.AnnotationConfigApplicationContext; import ru.jug.jpoint.core.ArtistJudge; import java.util.List; import java.util.Set; /** * Created by Evegeny on 20/04/2016. */ public class Main { public static void main(String[] args) { AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); ArtistJudge judge = context.getBean(ArtistJudge.class); List<String> topX = judge.topX("beatles", 3); System.out.println(topX); } } So, the most popular word is not yesterday, it is “i”:
[i, yesterday, to] Agree, this is not very good. We have junk words that do not carry a semantic load (in the end, we want to analyze how much the Pink Floyd songs are deeper and such words will hinder us very much).
Therefore, I had a userProperties file in which garbage words are defined:
garbage = the,you,and,a,get,got,m,chorus,to,i,in,of,on,me,is,all,your,my,that,it,for It would be possible to immediately inject this garbage into our service, but I don’t like to do that. We have a UserConfig that will be transferred to different services. Everyone will pull out of him what he needs.
@Component public class UserConfig implements Serializable{ public List<String> garbage; @Value("${garbage}") private void setGarbage(String[] garbage) { this.garbage = Arrays.asList(garbage); } } Pay attention, I use private for the setter and public for the property itself. But let's not dwell on it.
We go to our PopularWordsServiceImpl, autowired to this UserConfig and filter all words.
@service public class PopularWordsServiceImpl implements PopularWordsService { @Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } } main.
, ( ):
, not serializable. . , UserConfig — serializable.
Component public class UserConfig implements Serializable{ public List<String> garbage; @Value("${garbage}") private void setGarbage(String[] garbage) { this.garbage = Arrays.asList(garbage); } } serializable PopularWordsServiceImpl:
@Service public class PopularWordsServiceImpl implements PopularWordsService { serializable:
public interface PopularWordsService extends Serializable { List<String> topX(JavaRDD<String> lines, int x); } map- ( , ) state- - , . Those. UserConfig , serializable. , UserConfig , . , serializable.
. yesterday. — oh, — believe. oh -, .
, , UserConfig worker? ? ? , Spark , , - .
, broadcast-.
4. , broadcast
, worker- data ( UserConfig ). , , broadcast, . ( ), broadcast .
2 , :
- . Spark ;
- , , , — . broadcast.
:
Israel, +9725423632 Israel, +9725454232 Israel, +9721454232 Israel, +9721454232 Spain, +34441323432 Spain, +34441323432 Israel, +9725423232 Israel, +9725423232 Spain, +34441323432 Russia, +78123343434 Russia, +78123343434 .
( ), . , . — - property- worker-. , , :
Israel, Orange Israel, Orange Israel, Pelephone Israel, Pelephone Israel, Hot Mobile Israel, Orange Russia, Megaphone Russia, MTC - Excel-, , 054 — Orange, 911 — . (10 ; 2 — big data) .
:
Orange Orange Pelephone Pelephone Hot Mobile Orange Megaphone MTC ?
public interface CommonConfig { Operator getOperator(String phone); List<String> countries(); } CommonConfig, , .
, :
@Service public class HrenoviyService { @Autowired private CommonConfig config; public JavaRDD<String> resolveOperatorNames(JavaRDD<Tuple2<String,String>> pairs){ return pairs.filter(pair-> config.countries().contains(pair._1)) .map(pair-> config.getOperator(pair._2).getName()); } } - Spring, , , data.
! , ( broadcast).
? Driver Worker-, , , , 1 . . , . , , 1000 . Spark-, 10 Worker-.
Worker- - . 10, 1000, 100 . , , , .. - ( 1 , 2, .. 2 ). , worker- , broadcast.
:
context, , broadcast, , broadcast-. , worker- .
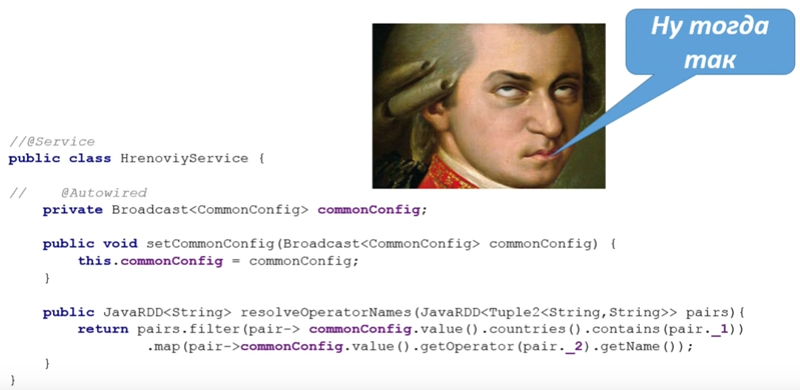
What is the problem? :
@Service public class HrenoviyService { @Autowired private JavaSparkContext sc; @Autowired private CommonConfig commonConfig; private Broadcast<CommonConfig> configBroadcast; @PostConstruct public void wrapWithBroadCast(){ configBroadcast = sc.broadcast(commonConfig); } public JavaRDD<String> resolveOperatorNames(JavaRDD<Tuple2<String,String>> pairs){ return pairs.filter(pair-> configBroadcast.value().countries().contains(pair._1)) .map(pair-> configBroadcast.value().getOperator(pair._2).getName()); } } context (, , Spring). broadcast- , PostConstruct, wrapWithBroadcast. SparkContext , . PostConstruct.
( broadcast , ):
return pairs.filter(pair-> configBroadcast.value().countries().contains(pair._1)) .map(pair-> configBroadcast.value().getOperator(pair._2).getName()); :
SparkContext, . . copy-paste, , broadcast, .
copy-past .
, Spark - ( broadcast — ). , SparkContext, .
:
SparkContext , serializable.
, , , . :
broadcast? , bean:
broadcast-, bean , broadcast.
, , broadcast? , , Service , , broadcast.
.
@Service public class PopularWordsServiceImpl implements PopularWordsService { @AutowiredBroadcast private Broadcast<UserConfig> userConfig; broadcast UserConfig AutowiredBroadcast. , ?
:
@Override public List<String> topX(JavaRDD<String> lines, int x) { return lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .filter(w -> !userConfig.value().garbage.contains(w)) .mapToPair(w -> new Tuple2<>(w, 1)) .reduceByKey((a, b) -> a + b) .mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x); } } UserConfig.value, .
, bean-, .
.
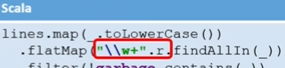
lines.map(String::toLowerCase) .flatMap(WordsUtil::getWords) .filter(word-> !Arrays.asList(garbage).contains(word)) .mapToPair(word-> new Tuple2<>(word, 1)) .reduceByKey((x, y)->x+y) .mapToPair(Tuple2::swap) .sortByKey(false) .map(Tuple2::_2) .take(amount); lines.map(_.toLowerCase()) .flatMap("\\w+".r.findAllIn(_)) .filter(!garbage.contains(_)) .map((_,1)).reduceByKey(_+_) .sortBy(_._2,ascending = false) .take(amount) , Java ( ..). — Scala. , Java 8, 2 . , :
Java GetWords, . Scala . Scala SortBy, Tuple, Scala ( ascending false, false).
? .
DataFrames — API, Spark 1.3. , ( Tuple). RDD, .. RDD , — . ( ), task- .
:
- hive-;
- json- ;
- RDD;
- ;
- .
DSL SQLContext ( ).
, :
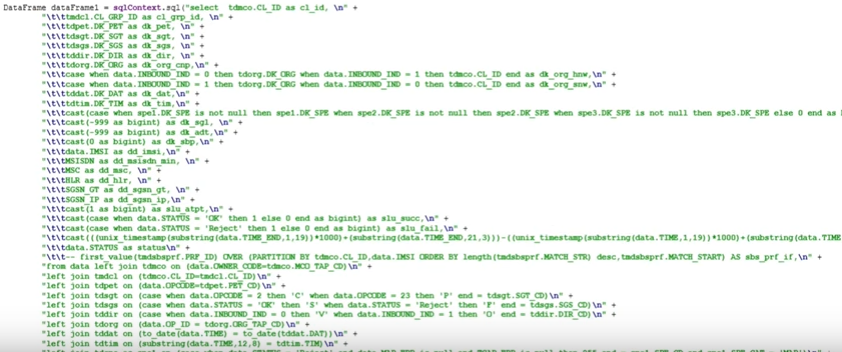
Agg, columns, count, distinct, drop, dropDuplicates, filter groupBy, orderBy, registerTable, schema, show, select, where, withColumn SQL :
dataFrame.registerTempTable("finalMap"); DataFrame frame = sqlContext.sql("select cl_id, cl_grp_id, dk_org_snw, dk_org_hnw, dk_org_cnp, dk_dir, dk_dat, DK_TIM_HR as dk_tim_hr, dk_spe, dk_sgt, dk_pet, dk_sgs, dk_sbp,\n" + "SUM(slu_atpt) slu_atpt, SUM(slu_succ) slu_succ, SUM(slu_fail) slu_fail, SUM(slu_dly) slu_dly\n" + "FROM finalMap f join tdtim t on f.dk_tim = t.DK_TIM\n" + "WHERE dk_pet IN (1, 4)\n" + "group by cl_id, cl_grp_id, dk_org_snw, dk_org_hnw, dk_org_cnp, dk_dir, dk_dat, DK_TIM_HR, dk_spe, dk_sgt, dk_pet, dk_sgs, dk_sbp").toDF(); , SQL sqlContext.
, :
:
abs, cos, asin, isnull, not, rand, sqrt, when, expr, bin, atan, ceil, floor, factorial, greatest, least, log, log10, pow, round, sin, toDegrees, toRadians, md5, ascii, base64, concat, length, lower, ltrim, unbase64, repeat, reverse, split, substring, trim, upper, datediff, year, month, hour, last_day, next_day, dayofmonth, explode, udf , . :
keywords (, ).
main.
-, , . sqlContext.read.json ( , json, — ; json ). show. :
: , keywords, . . , 30 ( ), .
. linkedIn. select, keywords. , , explode ( keyword ).
linkedIn.select(functions.explode(functions.column(“keywords”)).as(“keyword”)); . , :
sort .. .
. keyword:
DataFrame orderedBy = keywords.groupBy(“keyword”) .agg(functions.count(“keyword”).as(“amount”)) .orderBy(functions.column(“amount”).desc()); orderedBy.show(); , . keyword- amount. amount descended ( false). :
. :
String mostPopularWord = orderedBy.first().getString(0); System.out.println(“mostPopularWord = “ + mostPopularWord); first — , string ( resultset-). , :
linkedIn.where{ functions.column(“age”).leq(30).and(functions.array_contains(functions.column(“keywords”).mostPopularWord))) .select(“name”).show(); } 30 . , functions.array_contains. show. Here is the result:
. : XML-, JSON-, . ( )? , Java Scala? , .
WordDataFrameCreator.
, :
@Component public class WordDataFrameCreator { @Autowired private SQLContext sqlContext; @Autowired private JavaSparkContext sc; public DataFrame create(String pathToDir) { JavaRDD<Row> rdd = sc.textFile(pathToDir).flatMap(WordsUtil::getWords).map(RowFactory::create); return sqlContext.createDataFrame(rdd, DataTypes.createStructType(new StructField[]{ DataTypes.createStructField("words", DataTypes.StringType, true) })); } } . RDD map- . , RowFactory — RDD. RDD, RDD , , , , .. , — . SqlContext.
, SqlContext JavaSparkContext ( AppConfig, SqlContext ). , :
public SQLContext sqlContext(){ return new SQLContext(sc()); } SqlContext , RDD, , , — ( , words, string — true).
API : , - .
:
@Service public class PopularDFWordsServiceImpl implements PopularDFWordsService { @AutowiredBroadcast private Broadcast<UserConfig> userConfig; @Override public List<String> topX(DataFrame lines, int x) { DataFrame sorted = lines.withColumn("words", lower(column("words"))) .filter(not(column("words").isin(userConfig.value().garbage.toArray()))) .groupBy(column("words")).agg(count("words").as("count")) .sort(column("count").desc()); sorted.show(); Row[] rows = sorted.take(x); List<String> topX = new HashSet<>(); for (Row row : rows) { topX.add(row.getString(0)); } return topX; } } , , RDD, . API .
lower case . withColumn — , . , , . , count , — descended-. - .
. , ? . , custom-, , .
ustom- ( udf) — , . . notGarbage. , udf1, string (), — boolean ( ).
, :
@Service public class PopularWordsResolverWithUDF { @Autowired private GarbageFilter garbageFilter; @Autowired private SQLContext sqlContext; @PostConstruct public void registerUdf(){ sqlContext.udf().register(garbageFilter.udfName(),garbageFilter, DataTypes.BooleanType); } public List<String> mostUsedWords(DataFrame dataFrame, int amount) { DataFrame sorted = dataFrame.withColumn("words", lower(column("words"))) .filter(callUDF(garbageFilter.udfName(),column("words")))… , , PostConstruct .
callUDF — . — , - . udf-.
UDF , , , @RegisterUDF BPP .
, ( Tomcat, ):
10 :
( ):
, . 6 4 .
:
:
Pink Floyd 0 . , :
findings
- Hadoop Spark, Spark Hadoop. Yarn, , — ;
- Scala, . ;
- : , Spring, , , ..;
- . - , bean, , ;
- ( , ).
:
:
— 5 Spark-. , , , . Spark , - . , : , , , — « Spark!» .
— 7-8 JPoint 2017 . : «Spring – » « Spring Test» . , !
, JPoint Java — , .
Source: https://habr.com/ru/post/325070/
All Articles