How to collect statistics from the website and not to fill yourself cones

Hi, Habr! My name is Slava Volkov, and I'm a frontend developer at Badoo. Today I would like to tell you a little about collecting statistics from the frontend.
We know that analytics allows you to evaluate the effectiveness of any web site, improve its work, and thus increase sales and improve user interaction with the site. Simply put, analytics is a way to control the processes occurring on a website. In most cases, for ordinary websites it is enough to install Google Analytics or Yandex.Metrica - their capabilities are enough.
But what about when standard monitoring tools are not enough? Or when the collected statistics should be integrated into your own analytics system to display a complete picture of what is happening between different components? In this case, most likely, you will have to develop your system. But how best to send statistics from your websites, what problems may arise and how to avoid them, I will tell in this article. Interested? Welcome under cat.
For such services as Badoo, any statistics is a very important way to assess the current situation on the resource, whether it is the user's clicks, the blocks that he saw, the actions that he committed, or errors while working with the site. Based on this information, we monitor the operation of the site and make decisions that affect the appearance of new features, changing the position of blocks on the page and other changes. Therefore, we work with a huge number of diverse statistics. What difficulties can be encountered with such a flow of messages?
The first problem that may arise is browser restrictions on the number of simultaneous connections to a single domain. For example, when loading a page, we perform four Ajax requests to retrieve data (font downloads, SVG graphics), and dynamically load styles. As a result, we get six requests that the browser performs at the same time ( example number 1 ) (in all the examples I set a delay of two seconds, and it is better to look at them on my machine to avoid network delays).
function sendAjax(url, data) { return new Promise(function(resolve, reject) { var req = new XMLHttpRequest(); req.open('POST', url); req.onload = function() { if (req.readyState != 4) return; if (req.status == 200) { resolve(req.response); } else { reject(Error(req.statusText)); } }; req.onerror = function() { reject(Error("Network Error")); }; req.send(data); }); } function logIt(startDate, requestId, $appendContainer) { var endDate = new Date(); var text = 'Request #' + requestId + '. Execution time: ' + ((endDate - startDate) / 1000) + 's'; var $li = document.createElement('li'); $li.textContent = text; $appendContainer.appendChild($li); } document.querySelector('.js-ajax-requests').addEventListener('click', function(e) { e.preventDefault(); var $appendContainer = e.currentTarget.nextElementSibling; for (var i = 1; i <= 8; i++) { (function(i) { var startDate = new Date(); sendAjax(REQUEST_URL + '?t=' + Math.random()).then(function() { logIt(startDate, i, $appendContainer); }); })(i); } }); But what will happen if we start sending some more statistics about the logged in user? We get the following result ( example number 2 ):
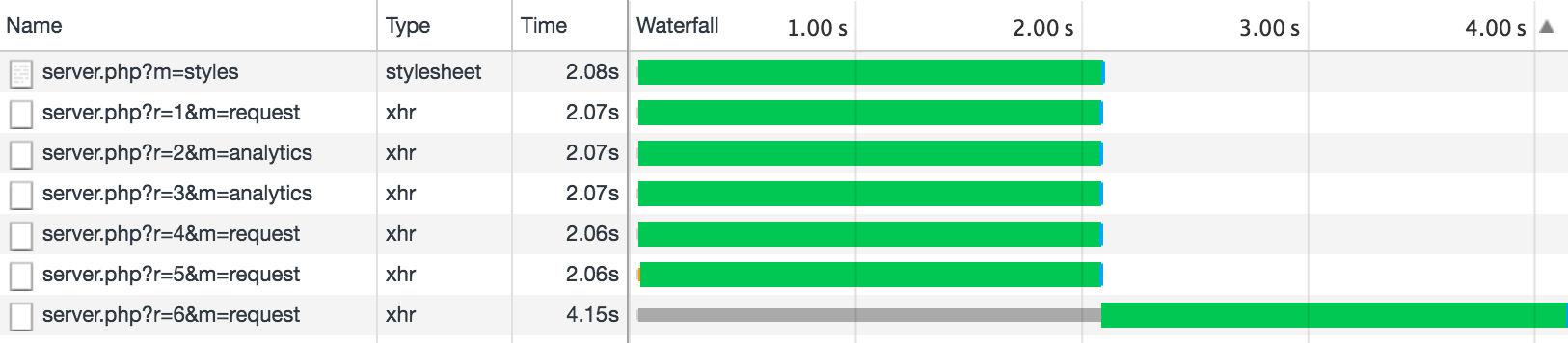
As you can see, two requests for sending statistics have affected the overall load of the site, and if this data is needed to render the page, the user will face a delay equal to the execution time of the fastest of the previous requests.
In most cases, waiting for a response from the statistics does not make sense, but these requests still affect the overall flow of execution. How to avoid such a situation?
Sending data
If you are already using HTTP / 2 or transferring data via a WebSocket connection, then this problem should not affect you at all. But if not yet, perhaps you will be helped simply by switching to HTTP / 2 (and you will forget everything like a bad dream). Fortunately, all modern browsers support this, and support for this protocol has already appeared in the most popular web servers. The only problem you may encounter is the need to remove all the hacks that you did for HTTP / 1.1, for example, domain sharding (creating an extra TCP connection and preventing prioritization), JS and CSS concatenation and embedded dataURI. In addition, when switching to HTTP / 2, you have to transfer the entire site to HTTPS, which can be expensive, especially if you have a lot of data from third-party resources downloaded via HTTP.
When using WebSocket connections, you also get a permanent connection to the server and no limit on the number of requests. There is nothing wrong with this decision, except that you have to raise your socket server and connect it with your system - additional work for developers. But in the end, it will be possible to transmit not only statistics through the socket, but also regular requests. And most importantly - it will allow to receive notifications from the server and save traffic.
Method number 1
If you are not yet ready to switch to HTTP / 2 or use a WebSocket connection, the simplest solution is to make requests with statistics for a separate domain, in fact, like making all the static data. Then the problem will disappear ( example number 3 ):
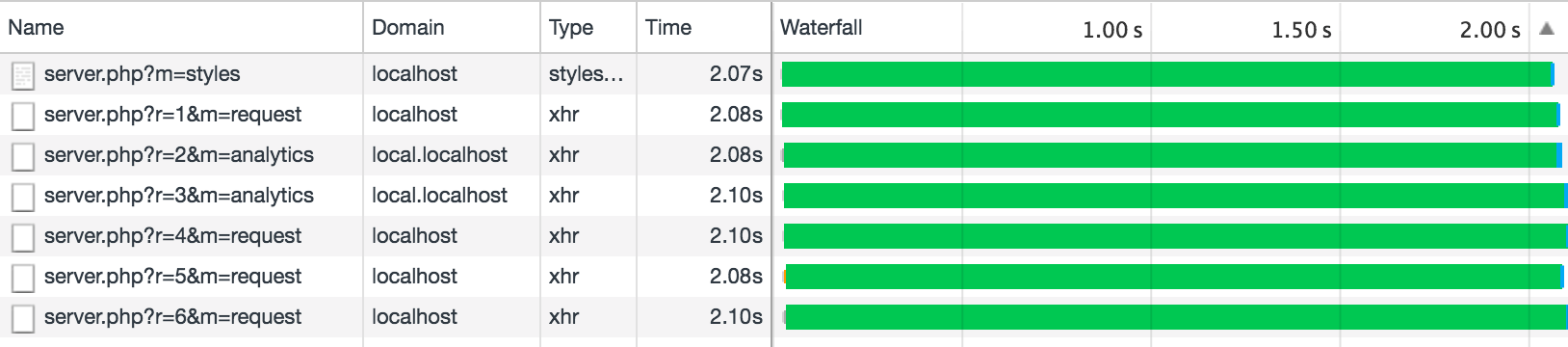
Of course, do not forget about the CORS configuration, otherwise such requests will be blocked by the browser.
Method number 2
Using the capabilities of the Fetch API , we can make six additional requests without passing a cookie ( example number 4 ). But this will only help if the cookie will not be used for authorization when making requests. By default, Fetch does not transmit them. It seems that it looks like an implementation bug, but this behavior is observed in both Chrome and Firefox. Bug feature? In order for cookies to go away, you need to set an additional parameter:
fetch(REQUEST_URL + '?t=' + Math.random(), { method: 'POST', credentials: 'include' }).then(function () { // ... }); So, we decided how we will transfer data to the server. But we will not send a request for each user action. Of course, it is better to buffer the events and then send the group to the server. But in this case, if the user leaves the page, there is a risk of losing the accumulated buffer. How to avoid such a situation?
Buffering
Message buffering can be organized using the debounce function, which will allow us to arrange a delay between sending messages. A small example of this work can be found here (if necessary, it can be supplemented taking into account the size of the transmitted data or the maximum lifetime of the queue).
In addition to using debounce delay, there are examples of using the window.requestIdleCallback method, but unfortunately, it is not supported by all browsers. The requestIdleCallback method queues a function that will be executed when the browser is idle. It is not bad to use this opportunity to perform background tasks, for example, sending statistics or loading any lazy load-elements on the page. My opinion is that it is better suited for the aggregation of synchronous calls. For example, see this example .
In addition, it would be nice to determine when your system is ready for use, and then call the ready () method, after which the statistics will be sent to the server without blocking the rest of the work. And before that, it may just fall into the buffer.
Event delivery guarantee
Unfortunately, when using buffering, this situation may arise: the user has closed the tab - and the statistics you collected are not sent and lost. This can be avoided. The first thing that comes to mind is to create a force () method on your statistics sending object, which will be executed during beforeunload . But if you use XHR requests for sending statistics, then when you close a tab or browser, the request will also not be executed:
window.addEventListener('beforeunload', sendData, false); function sendData() { var client = new XMLHttpRequest(); client.open("POST", "/server.php", false); client.send(data); } This can be corrected by sending a synchronous request, as in the example above (but this will block the user's actions with the browser), or by using the special sendBeacon method, which allows you to asynchronously send small amounts of data to the server and guarantees their delivery even after the page is closed. This method works in all modern browsers except Safari and Internet Explorer (there is support in Edge), so they will have to leave the old synchronous XHR for them. But the main thing is that the method looks quite compact and simple:
window.addEventListener('beforeunload', sendData, false); function sendData() { var navigator = window.navigator; var url = "/server.php"; if (!navigator.sendBeacon || !navigator.sendBeacon(url, data)) { var t = new XMLHttpRequest(); t.open('POST', url, false); t.setRequestHeader('Content-Type', 'text/plain'); t.send(data); } } In order to make sure that your requests go away, just open the Network tab in Chrome DevTools and filter on requests of the Other type. All your sendBeacon requests will be here.
Unfortunately, sendBeacon has flaws, due to which it is impossible to transfer all requests sent to it. First, the method falls under the restriction on the number of connections per domain ( example number 5 ), so theoretically a situation may arise when a request to send statistics blocks an important request for receiving data (but there is an exception: if you use instead of XHR) requests to the new Fetch API without passing a cookie, then sendBeacon no longer falls under the restriction of connections ( example number 9 )). Secondly, sendBeacon may have a size limit for the request. For example, earlier for Firefox and Edge the maximum request size was 64 Kb, but now there is no limit on the size of the data for Firefox ( Example 8 ). When I tried to find the maximum data size for Chrome (currently version 57 is relevant), I found a very interesting bug , due to which the use of sendBeacon becomes problematic and which caused us to fall in sending statistics. Try running example 7 , reload the page and see the result of example 8 :

In Chrome, until the buffer reaches 64 Kb, other requests simply cannot be sent. Now the bug is already fixed, and I hope that his fix will fall into the next version. After that, the limit for one query will also be 64 Kb of data.
So, if through this method you get a lot of statistics from different components, then, most likely, you will encounter a limit. If you step over this limit, the navigator.sendBeacon() method returns false , and in this case it is better to use the usual XHR request, and leave navigator.sendBeacon() only for those cases when the user leaves the page. Also, this method does not guarantee the receipt of data by the server if the Internet connection is lost, so when sending data it is better to use the navigator.onLine property, which returns the browser’s network status before sending requests.
In principle, the latter solution seems sufficient for most cases. If we take out sending statistics to a separate domain ( example number 6 ), then in general the solution is almost universal, especially if we consider desktop web applications. If we consider the mobile web, in which there are frequent cases of connection loss and cases when it is necessary to guarantee the delivery of messages to the server, then this solution is no longer suitable, and it is better to use the usual XHR request and check the result of its execution.
But is there a universal solution that will suit both desktop and mobile web? If you look into the future and turn to new experimental technologies, then this possibility does exist.
Service Worker and Background Sync
Background synchronization in the Service Worker is represented by the Background Sync API or, with another implementation, as periodic synchronization . Take the already considered example and try to rewrite it using the capabilities of the service worker.
The finished test case can be viewed at this link . And then - the source code .
Statistic.prototype._sendMessageToServiceWorker = function(message) { return new Promise(function(resolve, reject) { var messageChannel = new MessageChannel(); messageChannel.port1.onmessage = function(event) { if (event.data.error) { reject(event.data.error); } else { resolve(event.data); } }; navigator.serviceWorker.controller.postMessage(message, [messageChannel.port2]); }); }; Statistic.prototype._syncData = function() { return navigator.serviceWorker.ready.then(function(registration) { return registration.sync.register('oneTimeStatisticSync'); }); }; Service Worker:
self.addEventListener('sync', function(event) { console.info('Sync event executed'); if (event.tag == "oneTimeStatisticSync") { event.waitUntil(sendStatistic()); } }); As you can see, this time we send the data directly to the service worker, interacting with it via PostMessage, and we only delay the synchronization. The big plus of a service worker is that if an Internet connection suddenly disappears, it automatically sends data only after it appears. Watch the video below. Or try to do it yourself. Just turn off the Internet and click on the links in the example above. You will see that requests are sent only after the connection is established.
In order not to bother with manual synchronization and to simplify the code a little, you can use periodic synchronization, which is available in the service worker. Unfortunately, even in Chrome Canary it does not work yet and one can only guess how it will function. But now someone even wrote a polifil for this:
navigator.serviceWorker.register('service-worker.js') .then(function() { return navigator.serviceWorker.ready; }) .then(function(registration) { this.ready(); return registration; }.bind(this)) .then(function(registration) { if (registration.periodicSync) { registration.periodicSync.register({ tag: 'periodicStatisticSync', minPeriod: 1000 * 30, // 30sec powerState: 'auto', networkState: 'online' }); } }); Through the use of periodic synchronization, you can not only send statistics, but also download new data when the application is inactive. This is very convenient, for example, for news sites - to download new data every hour. But since at the moment this possibility is not yet available, we have to use the usual synchronization and our own timers.
The disadvantages of using Service Worker include, probably, the fact that this method is not supported by all browsers. In addition, its implementation requires the use of only the HTTPS protocol: the Service Worker must be connected via HTTPS and all fetch requests inside it must also be using this protocol (the exception is localhost ).
Conclusion
In conclusion, I would like to note that there are more and more opportunities for monitoring and sending data from web applications - the web is developing well in this direction. Therefore, the use of existing capabilities of browsers allows you to efficiently collect statistics from web resources. And do not forget that the statistics that you collect, with proper collection and analysis will allow you to better understand the work of your site and the interaction with users.
I wish you all success in collecting data!
')
Source: https://habr.com/ru/post/325062/
All Articles