Are there stacking in Cisco Nexus switches?

When it comes to Cisco Nexus switches, one of the first questions I’m asking is whether stacking is supported on them? Hearing a negative answer, followed by the logical "Why?".
The answer is that the switch stack can serve as a single point of failure. In this case, Nexus is positioned as a switch in the data center, where fault tolerance is one of the first places.
“But you yourself wrote ( part 1 , part 2 , VSS / IRF ) that you can build a fault-tolerant infrastructure on the basis of the stack! It turns out, cheated? ". No way. Each technology is appropriate where its disadvantages are not so critical for the operation of the network, and the advantages provide tangible benefits. The situation with the stack is similar.
')
Stacking has two main advantages:
- single point of management of all switches (management plane),
- the ability to aggregate channels connected to different devices in a stack (Multi-Chassis Link Aggregation - MC-LAG).
Setup and maintenance of all switches in the stack occurs through one common interface.
MC-LAG support (in Cisco terms - Port channel) allows you to:
- minimize network usage of the Spanning Tree Protocols (STP) family of protocols;
- use aggregated bandwidth (all channels are active),
- provide fail-safe connection of devices (switches, servers, etc.).
On the stack, the MC-LAG operation is possible due to the general control plane . One of the switches becomes the master (master). It runs the control plane, which coordinates the work of all other devices. By the way, the management plane is activated on it. "Brain" in the stack is always one. The hardware resources of the switches are independent. If one of them breaks, the rest will continue to work.
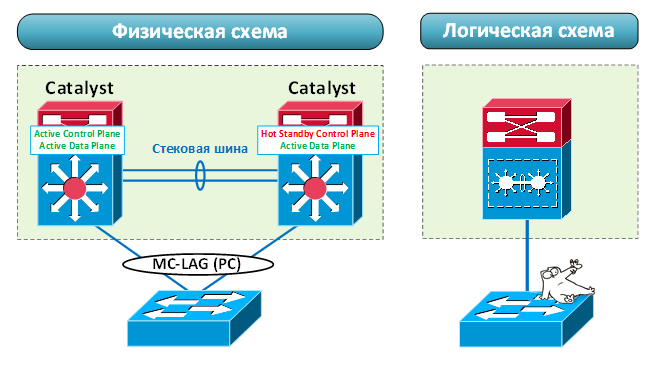
Thus, stacking involves the general control plane and management plane. Despite all the advantages, this is a possible point of failure. And although the hardware switches are independent, there are failures (not related to iron), in which the stack can no longer function correctly. For example, if the control plane on the main switch hangs due to a memory leak. The consequences can be different: loss of stack control, termination of various protocols (for example, LACP). In this case, the stack can continue to transmit traffic. After all, ASICs are filled with the necessary data and in fact do not depend on the work of the control plane. But all dynamic aggregations (MC-LAG) will “collapse”, since LACP packets will no longer be sent to the neighboring device.
Another possible problem is the situation when several switches decide that they are active (“split brain”). Since their configuration is identical, we have two devices on the network with the same addressing. This happens because of the rupture of the control channel. Of course, there are technologies aimed at combating such a phenomenon. In this case, the switches use additional neighbor state tracking mechanisms. And the control channel on some types of stack is difficult to break. But do not discount this situation.
Thus, the stack is a good solution for networks where its failure is not fatal. Yes, it cannot be called a fully fail-safe solution. But the likelihood of a critical situation is not so great. And with interest it can pay off the benefits it provides.
Nexus switches are positioned as a solution for environments (primarily for data centers), where fault tolerance is very important. Therefore, on these devices, stacking is completely absent. I note, the scope of Nexus is not limited to data centers. They can be used , including when building a corporate network.
But stacking has significant advantages. Therefore, Nexus support a number of technologies that allow them to be obtained without combining switches into a stack.
To implement the MC-LAG functions, the virtual Port-channel (vPC) technology is used. Each Nexus has its own independent control and management plane. In this case, we can aggregate the channels distributed between the two switches. Of course, we do not get complete independence of devices. During operation, the switches synchronize information necessary for the operation of aggregation (MAC addresses, ARP and IGMP entries, the state of ports). But in terms of fault tolerance, this is still better than a single control and management plane. This scheme is more reliable. Even if a vPC crashes, it will be less fatal for infrastructure.
However, vPC introduces special nuances of work. You can configure it only between two Nexus switches, and they both must have a set of identical settings. Some functions require small additional settings that are not needed when running a regular stack. For example, the correct routing of traffic between two vPC ports implies the presence of the “peer-gateway” command. Otherwise, you can stumble over the mechanism to prevent loops when passing traffic through vPC. Dynamic routing through vPC requires a “layer3 peer-router”. It would seem a trifle, and nerves can spoil. Not all technologies are compatible with vPC in their work. And it depends quite strongly on the model of Nexus'a. It is worth looking carefully at the configuration guide. In general, as usual, everything has its pros and cons.
vPC +, vPC to ACI
The vPC in FabricPath is called vPC +.
In the case of a classic vPC, synchronization occurs via a dedicated peer link. In the case of vPC work within the ACI factory, the peer link is not required. All synchronization takes place through the factory.
In the case of a classic vPC, synchronization occurs via a dedicated peer link. In the case of vPC work within the ACI factory, the peer link is not required. All synchronization takes place through the factory.

In terms of a single point of control for all switches, the lack of stacking is compensated by the following points:
- Using remote extenders Nexus (Fabric Extender - FEX). These are specialized switches, in which all functions of the control / management plane, as well as partly data plane, are transferred to the main (parent) switch.
Since all the FEX logic is implemented on the parent Nexus, the FEXs and the parent switch are a single point of failure. There is no local switching on FEXs. Packets between neighboring ports are transmitted through the parent device. So we have an increased load on the channel between them.
- Ability to synchronize configuration between two switches (Configuration Synchronization). In this case, the control / management plane remain independent.
Eventually. There is no stack in the Nexus. This is partially offset by other technologies. But they should be used deliberately, as they bring certain risks to the network design.
It is worth remembering that in order for the solution to be fault-tolerant it should not have dependent parts. Any technologies, protocols that provide fault tolerance, may also cause failures. Moreover, thanks to them, problems can pass from one device to another. Nothing is perfect. Therefore, if the issue of fault tolerance is decisive, you should try to build a network so that the influence of devices on each other is minimal.
But that's another story.
Useful links:
Source: https://habr.com/ru/post/324964/
All Articles