In-depth training on the features of the title and content of the article to overcome clickbate

Click cloud word cloud
TL; DR: I achieved a clickbate recognition accuracy of 99.2% on the test data for features of the header and content. The code is available in the GitHub repository .
Sometime in the past, I wrote an article on clickbate detection. That article received good feedback as well as a lot of criticism. Some said that they needed to take into account the contents of the site, others asked for more examples from different sources, and some suggested trying in-depth training methods.
')
In this article I will try to resolve these issues and bring the clickback to a new level.
There is no free food information.
Looking through my own Facebook feed, I found that clickbate cannot be categorized simply by title. It also depends on the content. If the content of the site is well matched to the title, it should not be classified as clickback. However, it is very difficult to determine what a real clickback is.
See some real-life examples on Facebook.
| one. |  |
| 2 |  |
| 3 |  |
| four. |  |
What do you think now? Which of them would you classify as clickbate and which ones not? Has it become more difficult after deleting source information?
My previous models based on TF-IDF and Word2Vec classify the first three as clickbacks, and maybe the fourth too. However, among these examples there are only two clickbates: the second and the third. The first example is the article that CNN distributes, and the fourth from The New York Times. These are two reputable news sources, no matter what Trump says! :)
If Facebook / Google takes into account only the headlines, they will block all the above examples in the news feed or search results.
So I decided to classify not only by the title, but also by the content of the site, which is opened by reference, and by some of the main features that are noticeable on this site.
Let's start with the data collection.
Data collection
This time, I retrieved data from publicly accessible Facebook pages. Max Woolf wrote an excellent article on how to do it. Python scripts are available here . This scraper allows you to extract data from public Facebook pages that are available for viewing without authorization on the site.
I extracted data from the following pages:
- Buzzfeed
- CNN
- The new york times
- Clickhole
- StopClickBaitOfficial
- Upworthy
- Wikinews
Let's see what data Max Wolfe's scraper has learned from the Clickhole page.
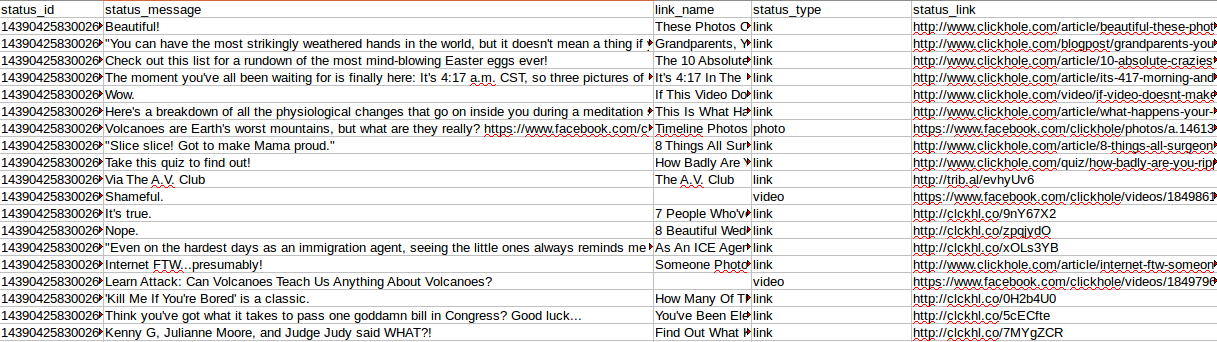
The following fields are interesting here:
- link_name (title of the published URL)
- status_type (is there a link, photo or video)
- status_link (real URL)
I filtered status_type == link because I’m interested only in published URLs with some textual content.
Then combined the collected data into two CSV files: Buzzfeed, Clickhole, Upworthy, and Stopclickbaitofficial fell into clickbaits.csv, and the rest into non_clickbaits.csv.
Data processing and feature generation
When data is collected and saved in two different files, it's time to collect html documents for all links and save all data as pickle files. To do this, I created a very simple Python script:

I approached html extraction very strictly, and in the case of any failure, the answer was “no html”. To save my time and speed up data collection I used Parallel in Joblib . Please note that you need to enable cookie support for cracking sites like The New York Times.
Since on my computer 64 GB of RAM, I did everything in memory. You can easily modify the code to save the results line by line in CSV and free up a lot of memory.
The next step was to generate the tags from this HTML data.
I used BeautifulSoup4 and goose-extractor to generate features.
The generated signs included:
- HTML size (in bytes)
- HTML length
- Total number of links
- Total number of buttons
- Total number of input fields
- Total number of unordered lists
- Total number of numbered lists
- Total number of H1 tags
- Total number of tags H2
- Text length in all found H1 tags
- Text length in all found H2 tags
- Total number of images
- Total number of html tags
- The number of unique tags html
Let's look at some of these signs:
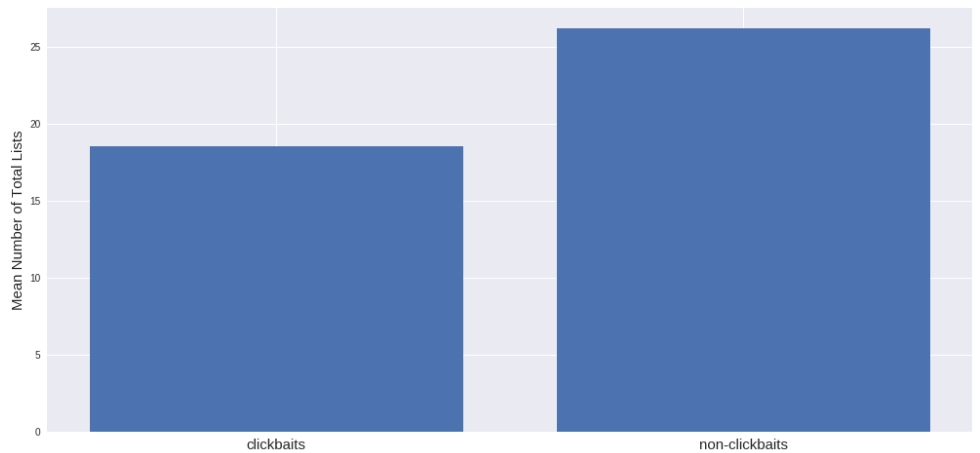
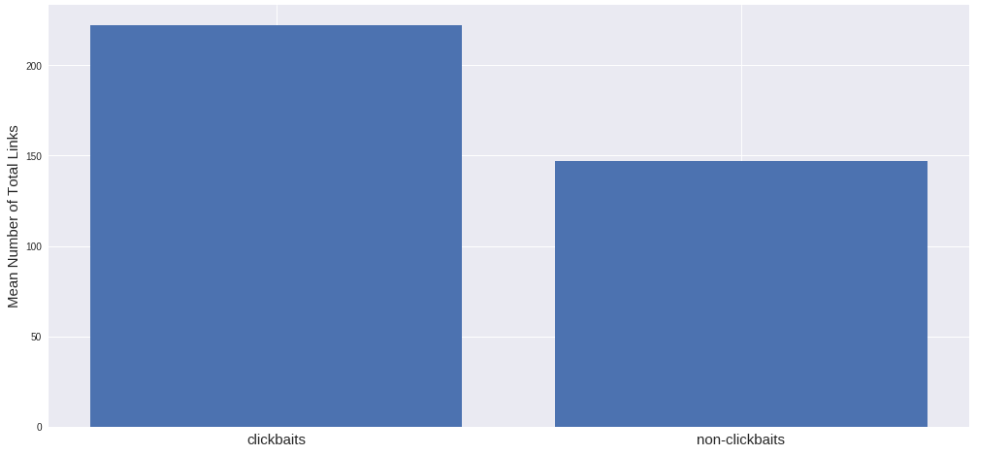
It seems that the average number of lists is more on sites without clickbate than on sites with clickbate. I thought it would be the opposite, but the data convince otherwise. It also turns out that clickable sites have more links:
At first, I suggested that there would be more images on clickbate sites. And yes, I was right:
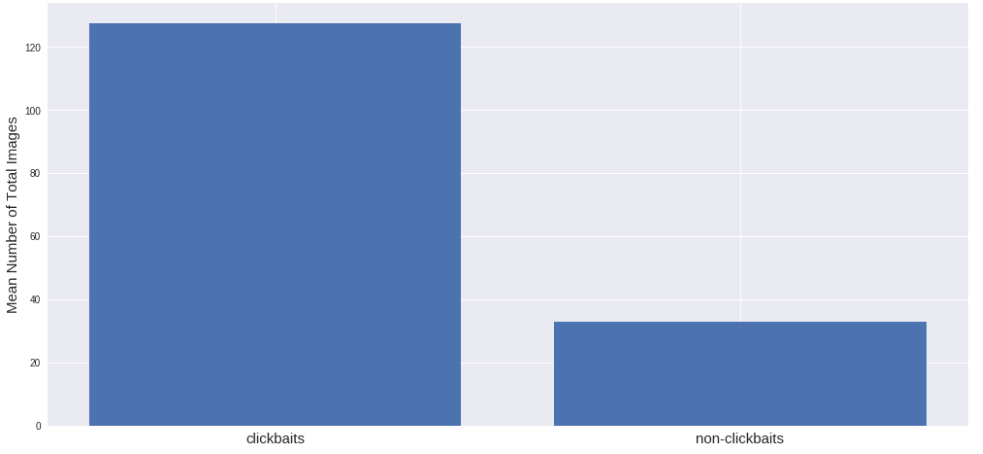
That's how they attract people. Pictures in articles are like worms for fish :)
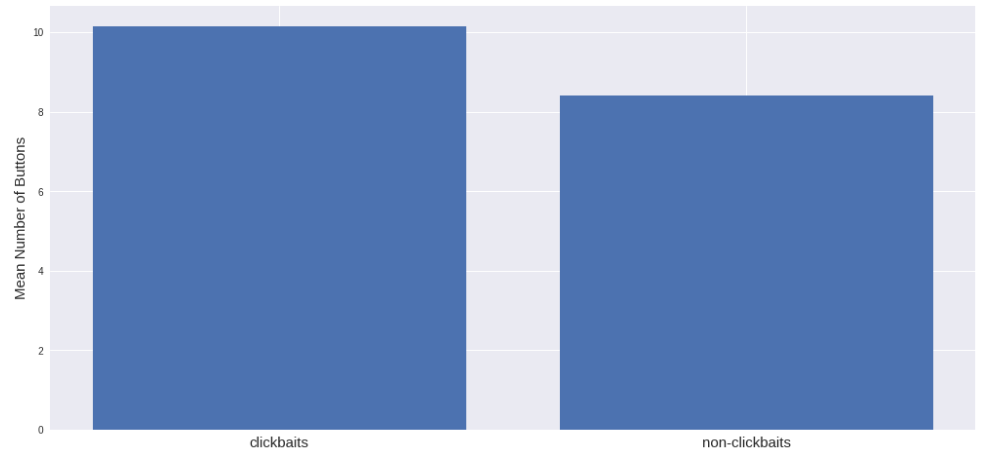
The number of interactive elements, for example, buttons, is almost the same:
When working with text data, it is customary to compose word clouds :), so here they are.
| Word cloud headlines for clickbate |  |
| Word cloud headlines without clickbate |  |
In the end, textual signs include:
- Full text H1
- Full text H2
- Meta description
Of course, you can extract more text and non-text features from web pages, but I limited myself to the list above. At this stage of extracting text data from web pages, I also deleted domain names from the text data of the corresponding web pages to avoid any retraining.
I noticed that the text with Buzzfeed often contains the words "Report a problem, thanks," so I deleted them too. Also created a special list of stop words for web pages:

At a certain moment, the data began to satisfy me and there appeared a confidence that the model would not retrain on this data. Then I began to construct some cool models of deep learning. But first, look at the final data:

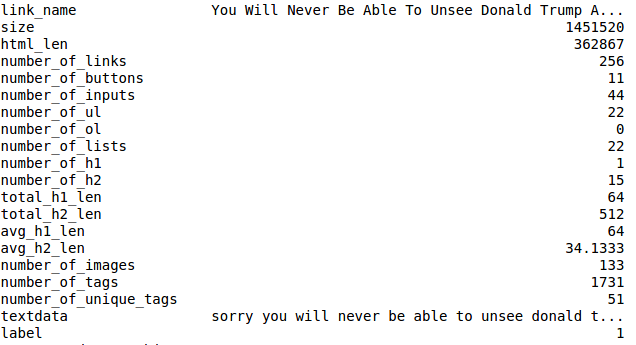
I ended up with about 50,000 samples. Approximately 25,000 for clickback sites, about the same for the rest.
Let's start building models!
Depth learning models
Before starting the construction of depth learning models, I divided the data into two parts, using a bundle on the label (1 = clickbate, 0 = not_clickbate). Let's call this test data, they consist of about 2500 examples from each sample. Test data were left intact, they were used only to evaluate the model. This model was built and tested on the remaining 90% of the data - data for training.
First, I tried a simple LSTM model with an embedded layer that converts positive indices into fixed-size density vectors. It was followed by two dense layers (Dense) with dropout and packet normalization (Batch Normalization):

A simple network shows an accuracy of 0.904 on a validation set after several periods, as well as an accuracy of 0.884 on a test set. I regarded it as a benchmark and tried to improve performance. We still have signs of content to add! Perhaps this will improve accuracy both on the validation set and on the test set.
In the following model, without changing the dense layers, followed by the LSTM layers, I added features of textual content and merged them before going through the dense layers:
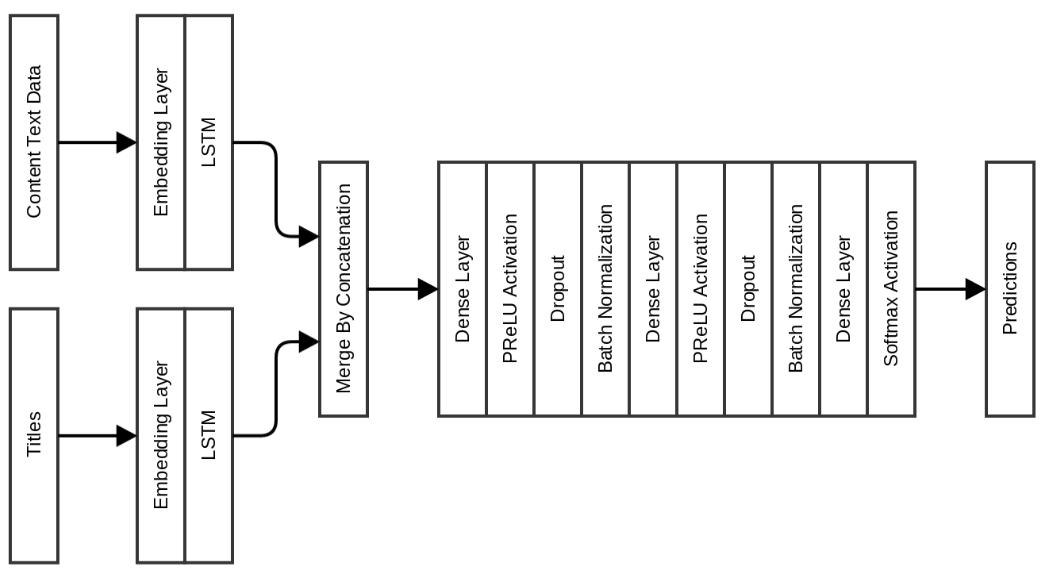
This model immediately improved the performance by 7% on benchmarks! The validation accuracy has increased to 0.975, and the accuracy on the test set to 0.963. The disadvantage of these models is that it takes a lot of time to learn, because you need to learn how to embed it. To overcome this, I made the following models with GloVe embedding as initialization for embedded layers. 840 billion GloVe 300-dimensional inserts were used, trained on Common Crawl data. These inserts can be downloaded here .
Previous timed dense models, as described in my article about duplicate posts in Quora. Inserts were initialized by GloVe:
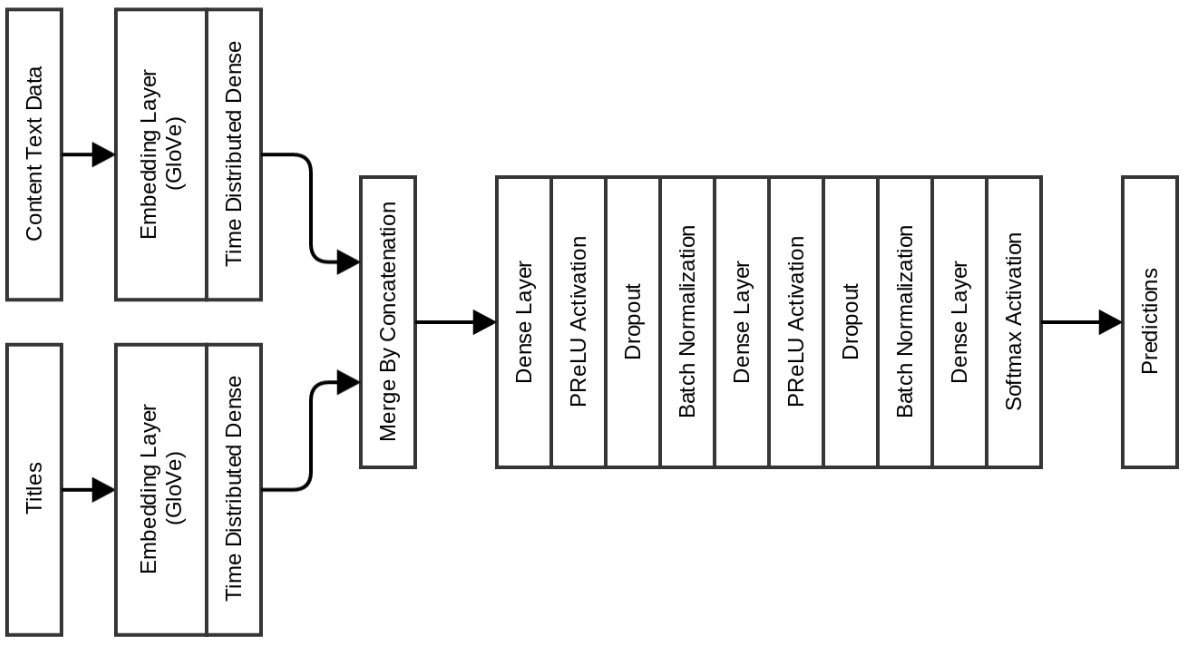
The model shows the accuracy of validation 0.977, and the accuracy on the test set - 0.971. The advantage of using this model is that the learning time per period is less than 10 seconds, while the previous model required 120-150 seconds per period.
So if you need a fast trained neural network model for determining clickbate, choose one of the above. If you need a more accurate model, see below :)
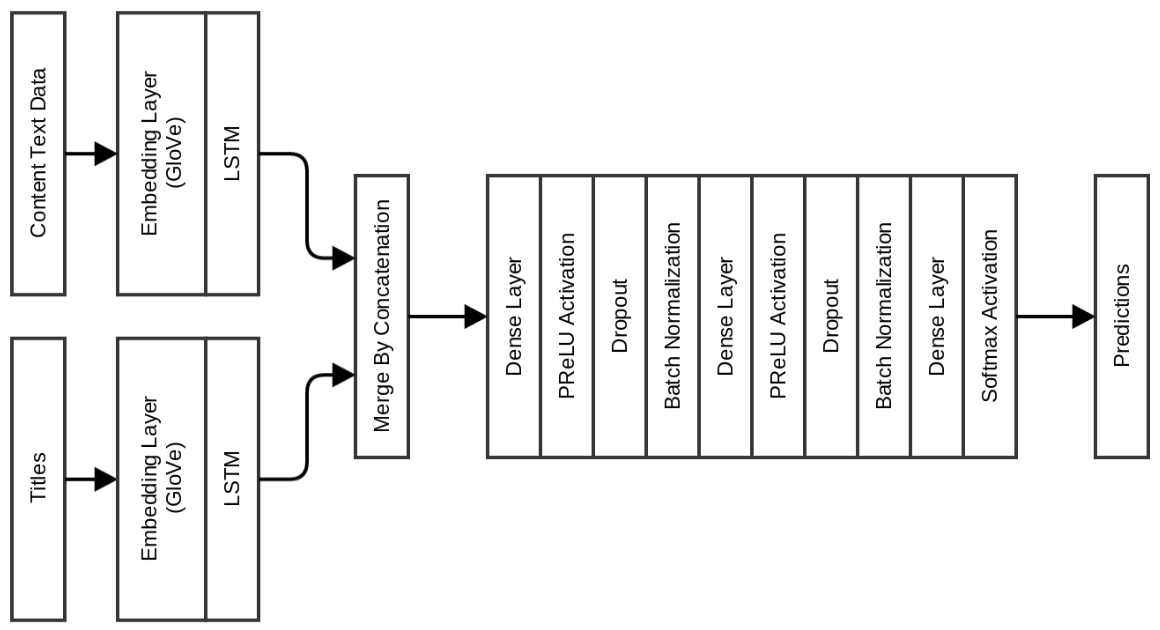
This network gives a good increase in validation accuracy: 0.983, but test accuracy increased very slightly to 0.975.
If you remember, I also created some numerical attributes based on what we do not see when we go by the URL. My next and final model includes these attributes too, along with LSTM for the header and text data content:
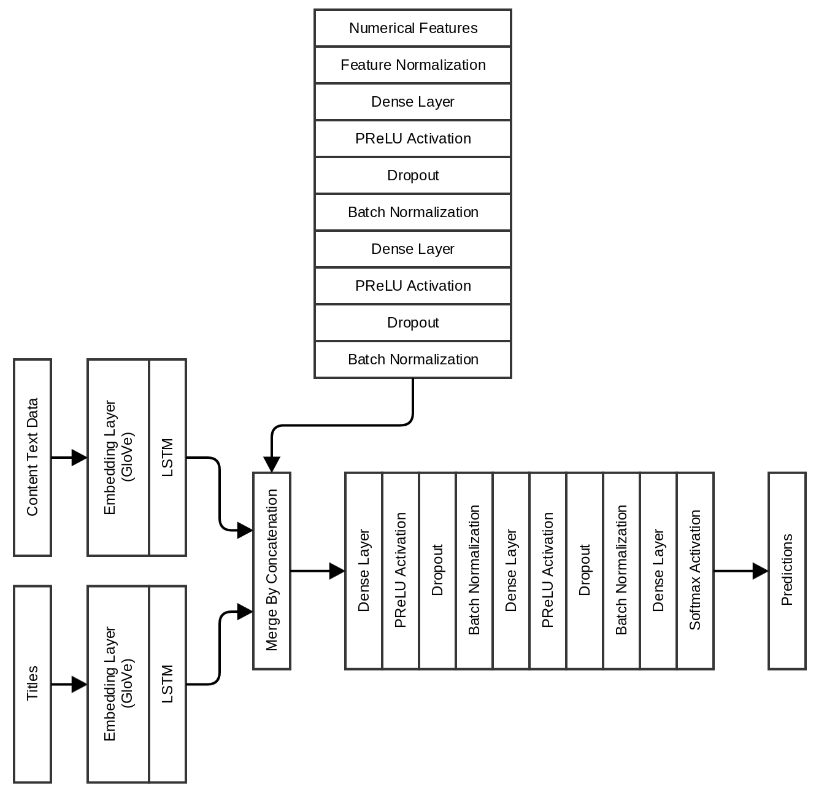
As it turned out, this is the best model with a validation accuracy of 0.996 and 0.991 on the test set. Each period takes approximately 60 seconds on this particular model.
The table summarizes the accuracy indicators obtained by different models:

Summarizing, I was able to build a model for determining clickback, which takes into account the title, text content and some functions of the website and demonstrates accuracy above 99% both during validation and on the test set.
The code for everything I’m talking about is available on GitHub .
All models were trained on NVIDIA TitanX, Ubuntu 16.04 system with 64 GB of memory.
Join forces and stop clickbate #StopClickBaits!
Feel free to comment or email at abhishek4 [at] gmail [dot] com if you have any questions.
Source: https://habr.com/ru/post/324960/
All Articles