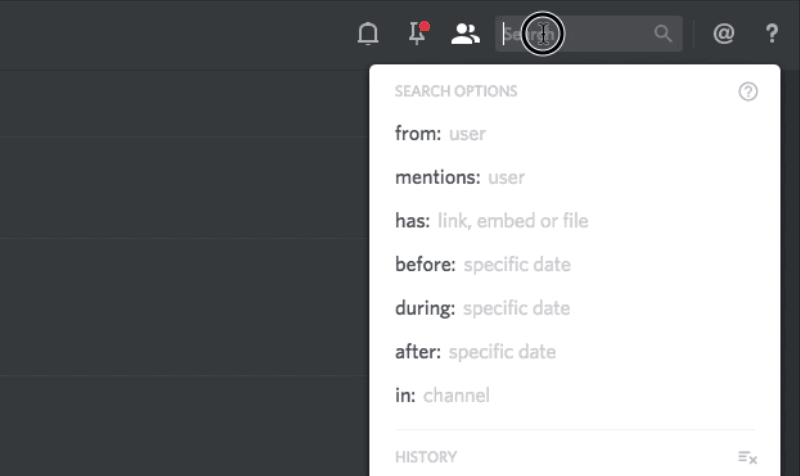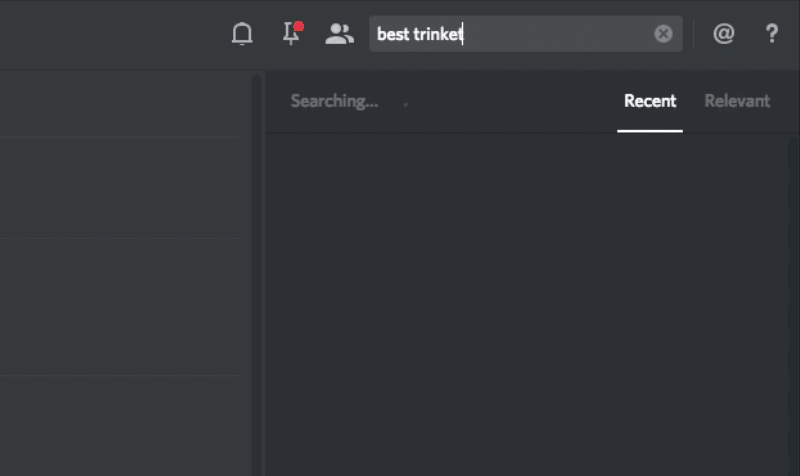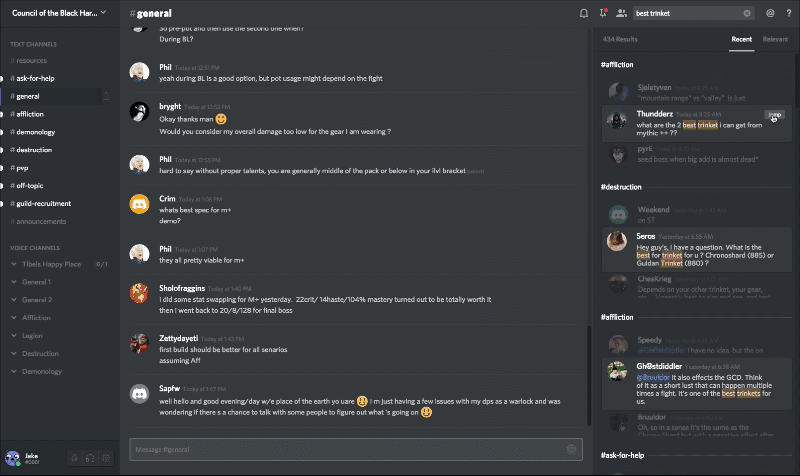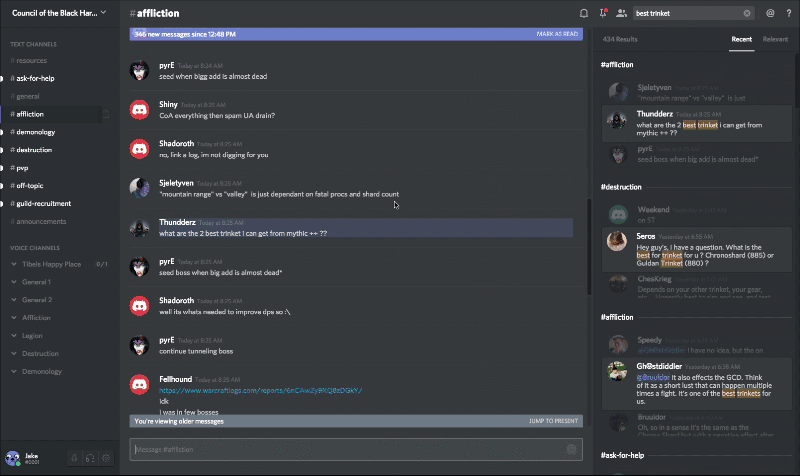
How Discord Indexes Billions of Posts

Millions of users send billions of messages to Discord every month . A search in these messages has become one of the most requested features we have done. Let there be a search!
Requirements
- Cost-effective: The main user interaction with Discord is our text and voice chat. Search is an auxiliary function, and the cost of the infrastructure should reflect this. Ideally, this means that the search should not be more expensive than the actual storage of messages.
- Fast and intuitive: All the functions we create must be fast and intuitive, including search. It should look and feel to a higher standard.
- Self-healing: We do not have a DevOps department (yet), so the search must withstand failures with minimal human intervention or without it at all.
- Linearly scalable: As with the storage of messages, increasing the capacity of the search infrastructure should include the addition of nodes .
- Lazy indexing: Not everyone uses the search - we do not have to index the messages until someone tries to find them at least once. In addition, after an index failure, there should be a possibility to re-index servers on the fly.
Looking at these requirements, we asked ourselves two key questions:
')
Q. Can I submit the search to a managed SaaS? (a simple solution)
A. No. All of the managed search solutions we reviewed go beyond our budget (an astronomical sum) for this feature. In addition, our guys do not like the idea of transferring messages outside our data center. Being aware of the risks, I want to keep control over the security of user messages, and not trusting it to a third party.
Q. Is there an open source search solution for us?
Oh yes! We studied everything and, after a brief discussion, quickly came to the choice of Elasticsearch vs Solr, since both systems may well be suitable for our case. Elasticsearch had the advantage:
- Detection of nodes in Solr requires ZooKeeper. Etcd works for us, and we did not want to multiply the infrastructure specifically for Solr. But Zen Discovery in Elasticsearch is self-sufficient.
- Elasticsearch supports automatic rebalancing of shards, which will allow adding new nodes to the cluster, thereby “out of the box” fulfilling our requirement for linear scalability.
- Elasticsearch has built-in structured DSL for requests, and Solr would otherwise have to programmatically create a query string using a third-party library.
- Our engineers have more experience with Elasticsearch.

Elasticsearch will work?
Elasticsearch seems to fit all our requirements, and our engineers have experience working with it. It allows you to replicate data between different nodes to withstand the failure of each of them, scales the cluster by adding new nodes and can swallow messages for indexing without getting tired. But while studying the topic, we found some scary stories about managing large Elasticsearch clusters, but in reality no one from our backend group had any experience with managing Elasticsearch clusters, not counting our log processing infrastructure.
We wanted to avoid problems with bulky large clusters, and then the idea came to delegate sharding and routing to the application layer in order to index messages in the pool of smaller Elasticsearch clusters. This also means that in the event of a single cluster being discontinued, only a portion of the Discord messages, those in the outgoing cluster, will become inaccessible. It also gives us a useful opportunity to drop the data of the whole cluster if it cannot be recovered (the system will lazily re-index the server data the next time the user tries to search for them).
Components
Elasticsearch likes to index documents in large quantities . This means that we can not index messages as they are published in real time. Instead, we designed a queue in which the worker captures message bursts and indexes them with single operations. We decided that the slight delay between posting the message and its accessibility to search is a reasonable limitation. After all, most users search for messages posted in the past, not just what they said.

On the side of receiving information, you had to do a couple of things:
- Message queue: It was necessary to make a queue where all messages arrive as they are posted online (for parsing by the pool of workers).
- Indexing Workers: Workers who do the actual routing and bulk insertion into the Elasticsearch from the queue.
We have previously made a system of setting tasks in a queue based on Celery , so we used it for history indexing workers as well.
- Workers indexing history: Workers whose task is to search the message history on a given server and insert it into the Elasticsearch index.
We still needed simple and fast mapping, which Elasticsearch cluster and index belong to the messages of each Discord server. We called this pair “cluster + index” Shard (not to be confused with Elasticsearch native shards in the index) . The mapping system created by us consists of two layers:
- Permanent mapping of shards: It was placed in Cassandra, our main persistent data store, as a reference.
- Shard mapping cache: When processing messages by workers, requests to Cassandra about Shard are a slow operation. We cache these cards in Redis, so we can perform mget operations to quickly figure out where to route the message.
If the server is being indexed for the first time, you also need to choose to which Shard to send messages to this Discord server. Since the Shards are an abstraction of the application layer, it becomes possible to distribute them more intelligently. Using the power of Redis, we applied a sorted set to create a load aware allocator for shards.
- Shard Dispenser: With the help of a sorted set in Redis, we store a set of Shards with ratings that correspond to their load. For the nearest distribution, a shard is selected that corresponds to the Shard with the lowest estimate. This score increases with each distribution, and each message, after being indexed in Elasticsearch, is also likely to increase its Shard score. The more data in Shard, the less chance that it will choose to distribute the new Discord server.
Of course, the entire search infrastructure would be incomplete without a cluster and host detection system from the application layer.
- etcd: In other parts of our system, etcd is used to locate services, so we applied it to Elasticsearch clusters. The nodes in the cluster are able to declare themselves in etcd for the rest of the system, so it is not necessary to firmly fix some Elasticsearch topologies.
In the end, it was necessary to enable customers to actually search for messages.
- Search API: Program interfaces through which requests from users come. It was necessary to implement all the permissions checks so that users could only search for messages to which they have access rights.

Indexing and data mapping
At a really high level in Elasticsearch, we have the concept of an “index” within which there are “shards”. In this case, the shard is a Lucene index . Elasticsearch is responsible for distributing the data in the index before the shard belonging to this index. If you want, you can control how the data is distributed among shards, using the "routing key". The index also stores the "replication factor", which means the number of nodes to which the index (and shards in it) should be replicated. If the node on which the index is located fails, then its replicated copy will take over the load. (By the way, these copies are also able to handle search queries, so you can scale the search bandwidth by adding more replicated copies).
Since we transferred all the logic of shards to the application level (our Shards), the sharding on the side of Elasticsearch in reality did not make sense. However, we could use it to replicate and balance indices between nodes in a cluster. In order for Elasticsearch to automatically create an index using the correct configuration, we used an index template that contains the index configuration and data mapping. Index configuration is quite simple:
- The index should contain only one shard (do not do any sharding for us)
- The index must replicate to one node (withstand the failure of the main node that carries the index)
- The index should be updated once every 60 minutes (why it had to be done, we will explain below)
- The index contains a single document type:
message
Storing the original message data in Elasticsearch did not make much sense, because in this format, the message data is difficult to search. Instead, we decided to take each message and convert it to a set of fields with metadata that can be indexed for searching:
INDEX_TEMPLATE = { 'template': 'm-*', 'settings': { 'number_of_shards': 1, 'number_of_replicas': 1, 'index.refresh_interval': '3600s' }, 'mappings': { 'message': { '_source': { 'includes': [ 'id', 'channel_id', 'guild_id' ] }, 'properties': { # This is the message_id, we index by this to allow for greater than/less than queries, so we can search # before, on, and after. 'id': { 'type': 'long' }, # Lets us search with the "in:#channel-name" modifier. 'channel_id': { 'type': 'long' }, # Lets us scope a search to a given server. 'guild_id': { 'type': 'long' }, # Lets us search "from:Someone#0001" 'author_id': { 'type': 'long' }, # Is the author a user, bot or webhook? Not yet exposed in client. 'author_type': { 'type': 'byte' }, # Regular chat message, system message... 'type': { 'type': 'short' }, # Who was mentioned, "mentions:Person#1234" 'mentions': { 'type': 'long' }, # Was "@everyone" mentioned (only true if the author had permission to @everyone at the time). # This accounts for the case where "@everyone" could be in a message, but it had no effect, # because the user doesn't have permissions to ping everyone. 'mention_everyone': { 'type': 'boolean' }, # Array of [message content, embed title, embed author, embed description, ...] # for full-text search. 'content': { 'type': 'text', 'fields': { 'lang_analyzed': { 'type': 'text', 'analyzer': 'english' } } }, # An array of shorts, specifying what type of media the message has. "has:link|image|video|embed|file". 'has': { 'type': 'short' }, # An array of normalized hostnames in the message, traverse up to the domain. Not yet exposed in client. # "http://foo.bar.com" gets turned into ["foo.bar.com", "bar.com"] 'link_hostnames': { 'type': 'keyword' }, # Embed providers as returned by oembed, ie "Youtube". Not yet exposed in client. 'embed_providers': { 'type': 'keyword' }, # Embed type as returned by oembed. Not yet exposed in client. 'embed_types': { 'type': 'keyword' }, # File extensions of attachments, ie "fileType:mp3" 'attachment_extensions': { 'type': 'keyword' }, # The filenames of the attachments. Not yet exposed in client. 'attachment_filenames': { 'type': 'text', 'analyzer': 'simple' } } } } } You may notice that we did not include a timestamp in the field set, and if you remember from our past post , our IDs are created in the Snowflake format, that is, they essentially contain a timestamp (which can be used to implement the function of selecting search results by time, choosing corresponding ID range).
However, these fields are not “stored” in this form in Elasticsearch; rather, they are stored only in an inverted index . The only actually stored and returned fields are the message, channel, and server ID on which the message was published. This means that the message data is not duplicated in Elasticsearch. The tradeoff is that we have to take data from Cassandra when returning search results, but this is absolutely normal, because in any case we would have to take the context of the message (two messages before and after) from Cassandra to display in the interface. Storing a real message object outside of Elasticsearch means that we don’t need to spend extra disk space on it. However, this also means that we cannot use Elasticsearch to highlight matches in the search results. We'll have to embed tokens and linguistic analyzers into the client program to highlight matches (which was really easy to do).
Implementation
We decided that microservice was probably not required for searching - instead, we put a library for Elasticsearch into which the logic of routing and queries was wrapped. It took only one additional service to start - these are indexers (who will use this library to do the actual work of indexing). The part of the program interfaces exposed for the rest of the team was also minimal, so if it were necessary to switch to our own service, it could be easily wrapped in an RPC layer. The library can be imported into our API workers, and it can actually perform search queries and return results to the user via HTTP.
For the rest of the command, the library shows the minimum part to search for messages:
results = router.search(SearchQuery( guild_id=112233445566778899, content="hey jake", channel_ids=[166705234528174080, 228695132507996160] )) results_with_context = gather_results(results, context_size=2) Queuing a message for indexing or deletion:
# When a message was created or updated: broker.enqueue_message(message) # When a message was deleted: broker.enqueue_delete(message) Bulk message indexing (almost) in real time by a worker:
def gather_messages(num_to_gather=100): messages = [] while len(messages) < num_to_gather: messages.append(broker.pop_message()) return messages while True: messages = gather_messages() router.index_messages(messages) To index old messages, a historical indexing task is created on the server, which performs a unit of work and creates a new task to continue indexing this server. Each task is a pointer to a place in the server message history and a fixed unit of the indexing volume (in this case, the default is set to 500 messages). The job returns a new pointer to the next batch of messages to be indexed or to None if there is nothing more to do. In order to quickly get results for a large server, we divided historical indexing into two phases: “initial” and “deep”. In the “initial” phase, messages for the last 7 days are indexed - and the index becomes available to users. After that, we begin the “deep” phase, which is performed with low priority. This article explains how this looks to the user. Tasks are performed in a pool of workers, which allows you to plan them among other tasks that workers perform. It looks like this:
@task() def job_task(current_job) # .process returns the next job to execute, or None if there are no more jobs to execute. next_job = current_job.process(router) if next_job: job_task.delay(next_job, priority=LOW if next_job.deep else NORMAL) initial_job = HistoricalIndexJob(guild_id=112233445566778899) job_task.delay(initial_job) Production Testing

After coding all of the above and testing in the development environment, we decided it was time to see how it works in production. We raised the only Elasticsearch cluster with three nodes, started indexing workers and assigned 1000 Discord servers for indexing. Everything seemed to work, but when we looked at the cluster indicators, we noticed two things:
- CPU usage turned out to be higher than we expected.
- Disk space consumption grew too fast for the volume of messages that was actually indexed.
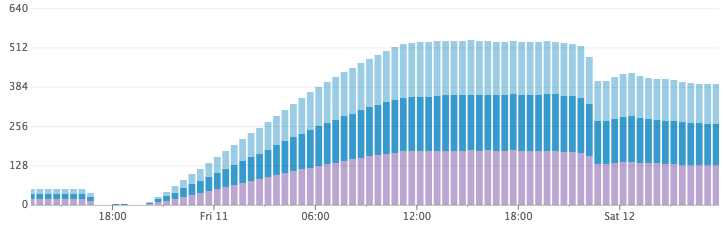
This surprised us quite a lot, and after continuing for some time using too much disk space, we canceled the indexing tasks and decided to sort it out the next day. Something was clearly wrong .
When we returned in the morning, we noticed a SIGNIFICANT disk space release. Has Elasticsearch discarded our data? We tried to run a search query on one of our servers, which was indexed and where one of our employees was registered. There is! The results returned well - and very quickly! What the heck?
Disk space usage grows rapidly and then decreases.
CPU load
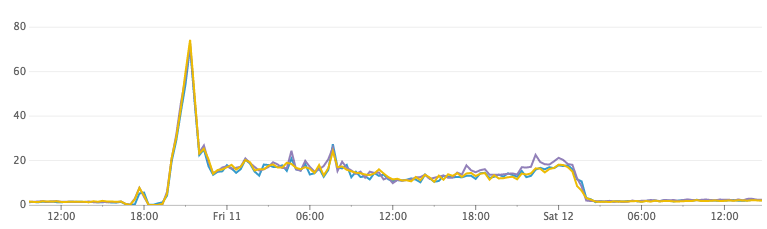
After a little investigation, we had a hypothesis! By default, Elasticsearch updates the index once per second. This is what provides the search "almost in real time." Every second (in each of the thousands of indexes), Elasticsearch filled the buffer in memory with the Lucene segment and opened it to make it searchable. During the night during idle time, Elasticsearch combined a large number of small fragments and generated much larger fragments (and much more efficient in disk space).
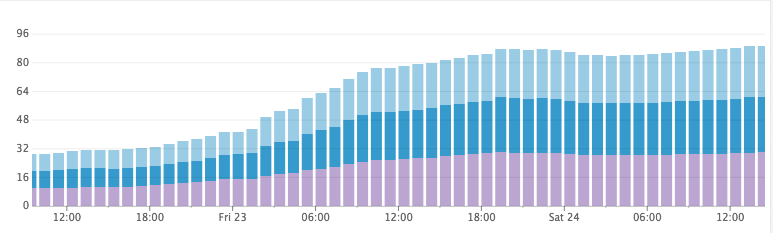
Testing the hypothesis was quite simple. We reset all indexes in the cluster, set the update interval to an arbitrarily large number, and then assigned the same servers for indexing. CPU utilization fell to insignificant values, while documents continued to be processed, and disk space consumption did not grow at an alarmingly high rate. Hooray!
Disk space usage after an increase in the refresh interval
CPU load
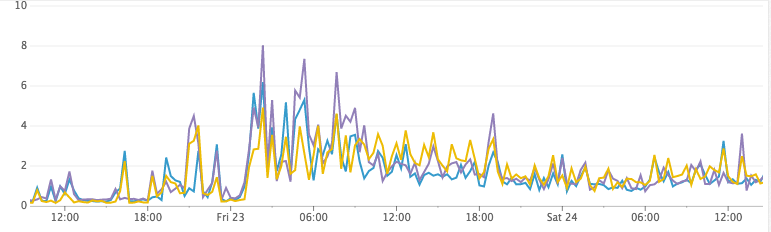
Unfortunately, however, the complete disabling of the update interval did not work in practice ...
Trouble with the update interval
It became obvious that the automatic indexing function in near real-time Elasticsearch does not satisfy our needs. It happens that the server works for hours without a single search query. We needed to find a way to control the update interval from the application layer. We did this with an obsolete Redis hash card. Since Discord servers are shared by shards on common indexes in Elasticsearch, we can build a quick map that changes with the index and keeps track of whether the index needs to be updated - depending on the server you are searching on. The data structure is simple: the Redis key storing the hash map,
prefix + shard_key , to the hash map of the guild_id values, to the signal value that indicates that the index needs to be updated. In retrospect, this could probably be a lot.The indexing cycle turns into:
- Take N messages from the queue.
- Figure out where to send these messages, by their
guild_id. - Perform a bulk insert operation in the corresponding clusters.
- Update the Redis map, indicating that the shard and the updated
guild_idon Shard have become dirty. This key should expire after 1 hour (Elasticsearch will have an automatic update by then).
And the search cycle turned into this:
- Find the shard on which you want to query
guild_id. - Check the Redis card for the fact that the shard, and also the
guild_id, are dirty. - If dirty, update the Elasticsearch index for Shard, and mark the whole Shard as clean.
- Run a search query and return results.
You may notice that although we are now clearly controlling the logic of the Elasticsearch update, we still have the main index updated every hour. If data is lost on Redis cards, the system will be automatically corrected within an hour.
Future
Since deploying in January, our Elasticsearch infrastructure has grown to 14 nodes in two clusters, using n1-standard-8 instance types on GCP with Provisioned SSD drives of 1 TB each. The total number of documents is almost 26 billion. The indexing rate reaches a peak of about 30,000 messages per second. Elasticsearch copes with this effortlessly, retaining the figure of 5-15% of the CPU throughout the deployment of our search.
So far, we have added nodes into clusters without difficulty. At some point, we will deploy new clusters, so that the new Discord servers being indexed will get there (thanks to our automatic distribution system for shards). In existing clusters, it will be necessary to limit the number of main select nodes as we add more nodes with data to the cluster.

We also stumbled upon four key indicators that we use to determine when to increase the cluster:
- heap_free: (aka heap_committed - heap_used). When we run out of space on the heap, the JVM is forced to stop so that the garbage collector can quickly free up space. If it cannot free enough space, then the node crashes. Before this, the JVM enters a state where it stops continuously, because the heap is full and too little memory is released during each pass of the garbage collector. We track this along with the statistics of the garbage collector to check how much time is spent on garbage collection.
- disk_free: Obviously, you need to add new nodes when disk space runs out or if more space is needed to index new documents. This is very easy to do on GCP, since we can simply increase the disk space without restarting the instance. The choice between adding a new node or changing the disk size depends on other parameters mentioned here. For example, if the disk space usage is high, but the other indicators are normal, then we will select the disk space expansion, rather than adding a new node.
- cpu_usage: If we have reached the CPU utilization threshold at peak hours.
- io_wait: If the I / O operations in the cluster have become too slow.
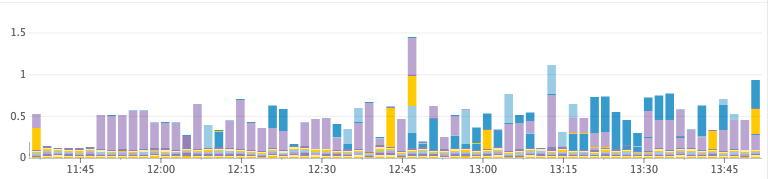
Unhealthy cluster (ends with a bunch)
Free Heap (MiB)
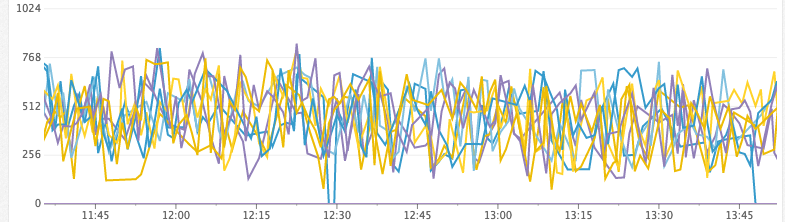
Time for garbage collection, GC per second
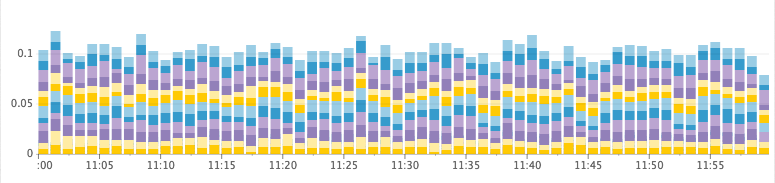
Healthy cluster
Free Heap (GiB)
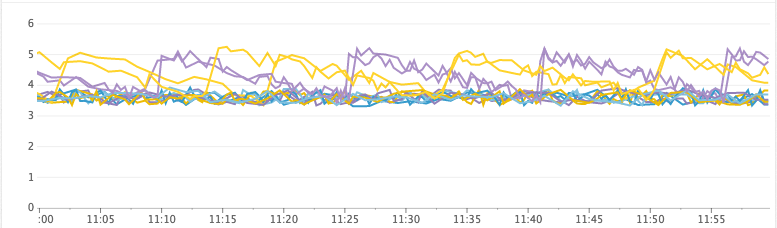
Time for garbage collection, GC per second
Conclusion
A little more than three months have passed since the moment when we launched the search function, and since then the system has been working with little or no problems.
Elasticsearch showed stable and confident performance from 0 to 26 billion documents on approximately 16,000 indexes and millions of Discord servers. We will continue scaling by adding new clusters or more nodes to existing clusters. At some point, we can think about writing code that will allow indexes to be transferred between clusters as a way to reduce the load on the cluster or to allocate our own index to the Discord server if it is an extremely talkative server (although our sharding system handles the distribution of weights, so that Discord servers and so usually get their own shards).
Source: https://habr.com/ru/post/324902/
All Articles