Infrastructure migration to the “cloud” in steps: what difficulties arise and where
We often help the customer's business to move to the "cloud" . This is a completely normal request, and most large companies somehow transfer their capacities. About 80% of cases occur in the transfer of an already virtualized infrastructure from the “home” server to the data center, the remaining 20% is the transfer directly from hardware (including users' workstations) to the virtual environment plus the removal of the computing node itself into the “cloud”.
Let's tell in steps how it happens with us . I will begin with the fact that rarely anyone moves at once with all services. Usually, non-criticals are taken away first, they look for a couple of months, and then everything else is translated.
Training
So, the first thing that is done is an assessment of capacity and infrastructure. About the choice of a hypervisor and technical details can be read here .
')
In fact, you need to have a list of services and know what capacities are needed for them and what needs. The task of a good administrator on the part of the customer is to make an accurate list of what is moving. That is, “splitting up” services to the level when it becomes clear what process is needed for what and how many resources it eats.
We allocate power with a small margin.
Then begins the assessment of the means of moving - as a rule, there are issues of data transfer and conversion of virtual machines into the format of the desired hypervisor.
Then, in fact, the relocation of some services: first, as I said, non-critical ones are taken away. Most often they start with virtual users or, in the case of development, with test environments. After a couple of months of running the test environments in the new "cloud" comes the turn of production. Although there were reverse examples - for example, we have one bank almost from scratch transferred a heavy database to our “cloud” (we gave IaaS and helped us adapt to our “cloud”). They really needed to move quickly - they did not have enough computing resources, and, after weighing all the risks, they decided that this was better.
But usually everything is easier. Depending on the migration tools, we plan the time when the services will be moved. The easiest and cheapest way is to do it with downtime at least in 4-6 hours, more difficult - if you need full availability of the service during the move. There are still cases when both the full availability of the service and the customer’s channels are slow at the same time, do not allow to transfer data quickly.
Moving
For offline travel, information is most often collected using the Clonezilla product. An even simpler method is to turn off the product, download to the file storage of the entire image (more on this here ), then convert. We support all types of virtualization.
If you need to move online, we most often work this way: we put Double-Take agents on both sides (from where we are going and where we are going, that is, to the customer’s server and the virtual machine in the cloud), plus to the control machine. It is cheaper to switch from idle in a few minutes, but Vizhn has a license for instant switching (it is an order of magnitude more expensive). We had a case with an oraklovy base, there was a simple 2 seconds.
You can move the means of applications - this is when we do not the image of the operating system as a whole, but directly the necessary part. Most often it is about MS SQL, it has an excellent "native" replication.
Further the image is dragged through a dedicated channel or VPN. Some customers simply send over the big Internet. As a rule, if we are talking about transferring the server node to the “cloud”, the customer has his own channel right up to the provider. If a “zoo” is transferred without virtualization, it is sometimes more difficult: you have to build a VPN tunnel or upload images to alienable media. In general, often the usual VPN with providers is limited to somewhere around 20 Mbit purely by the peculiarities of the technology. Therefore, you must have a provider L2VPN, or you have to carry it over the Internet at your own risk. Or you need a patchcord to the provider to do the exchange directly, but with encryption. Dedicated channels are not a problem, many get a “cloud” - physics connection: we calmly connect the iron servers in Vladivostok with the virtual ones in our country. VPN through the "cloud": nothing is specifically needed, is there as a basic service.
There are cases when there is really a lot of data, and even a gigabit channel on the customer’s side is not comfortable. Then you can download everything to your hard drive from the product, bring it to us, download it to the “cloud”. Once they even dragged a laptop with a huge hard drive. By the way, it is easy to call all providers, the main question of customers is how to leave if necessary. We have exactly the same problem: for example, once a customer moved away from us with their S3-like storage (more precisely, they dragged everything from their S3-compatible to their site due to the peculiarities of how they processed their personal data). Just asked to unload in S3 all virtualki in VMDK. Profits with 2 hard drives of 2 TB each, connected to the server, copied the images. We can safely give away in VMDK or other format.
Another method of natural relocation is through backup and recovery at a new site, if the customer has a good backup or disaster recovery scheme.
The customer is often surprised that there is the importance of the order of migration. It happens this way: when the move begins, it turns out that one of the services was needed for the work of another service. Therefore, dependency schemes are always compiled, a migration plan is worked out, so what.
Often, when migrating from iron platforms, you also need to upgrade the OS of the source servers - this is also no problem, but you need to plan.
Platform Features
It often happens that the customer has one virtualization platform in the server node, and the move is made to another for various reasons. Especially often migrating from VMware to KVM. The key point here is that for KVM there are two types of virtualization. The first and more productive is virtio, its work requires pre-installed drivers. In the second case, legacy is less productive when using an IDE disk and an Intel E1000 network adapter. However, sometimes this type of virtualization solves compatibility issues.
Then begins the quest with a different range of guest operating systems - 2003 and even 2008 (it also was). The hardest thing was since 2003, because not everything was getting smooth. In particular, drivers are usually installed on the device, which should be in the operating system, but in the case of migration, firewood is also installed on the machine that is being transferred to devices that are not actually present. So that when you deploy everything immediately fell as it should. This is important, because before running in the cloud, such a machine does not have a network adapter, the virtual machine has its own HDD and Ethernet. The car in the "cloud" has its own HDD driver and its own network. As a result, in the Legacy mode, the old IDE disk and adapter are thrown through it. But not in all cases it worked. As a result, we came to the conclusion that with the Windows 2003s that got us, they decided to unload the snapshots into the intermediate environment (Proxmoxy), and there you can start the virtual machine so that it will have the first disk its “old” IDE, and the second will be the virtual one Windows will see as an existing device. Initially, in the Proxmox virtualization environment, drivers were installed on the VM to work in the KVM leverage, and then the VM was downloaded to us in the “cloud”. Then the virtual machine loaded back into the “cloud” and took off. Ubuntu-8 was also shaggy, but even it is newer than the 2003 Windows. The most fun is that you cannot upgrade these operating systems on the customer side, for example, on some older systems, the Consultant Plus with a purchased license is spinning - this is a legacy that they are afraid to touch.
The next feature is the cluster. If the customer used his site, then when migrating to the “cloud” such architecture usually requires rework. More precisely, dragging a classic cluster into a “cloud” is not the most rational approach. There are always difficulties with this: how to drag? Cluster software itself will be an extra layer. But from the product it is often impossible to pull out. Here we attract experts on clusters and we think - most often the cluster is removed in advance on the side of the customer, because there is no sense in dragging him behind.
Compatibility issues arise, often - when moving Cisco to KVM or when migrating to MikroTik. In general, it starts: Mikrotik is not supported directly in KVM, but we have experience in setting it up. From our "cloud" came bundles to Ryazan, Kazan and Podolsk, where, in fact, stood Mikrotik, who built all the tunnels between the industries.
Often, customers have the expectation that the “cloud” itself presupposes DR (because it is located in two data centers). This is not out of the box, and we must immediately design the infrastructure so that it can move. We try to help: we estimate the possibility of moving, we give advice. Mature customers are ready for this, and they immediately rejoice at such opportunities (the benefit of their services are ready for this). And it is not at all necessary to do this by means of the hypervisor - you can configure replication from within the virtual machine.
In fact, we supply the customer with resources of one large “cloud”, where he can choose three different platforms: KVM leverage to accommodate one piece of infrastructure, cloud leverage on VMware (Cisco Powered platform) for another, and MS leverage based on Hyper-V for the third, respectively. For example, one large jar really wanted to start a test environment with us and cross it with its own iron, where docker was spinning. The docker in FIG did not drop our webcam, but the developers really liked the cloud API - they have their own custom-made web-environment for all test sites in different data centers. We hooked our API, then the merger of dockers went fine (thanks to the capabilities and flexibility of KVM, which allows you to tweak a lot). Another feature: the cloud shoulder on Hyper-V, we specifically designed to protect PD. This approach imposes a number of restrictions, and not any customer with arbitrary requirements can be “landed” on the Hyper-V cloud leg.
Workstations do not drag as separate machines - often either one image and file shareware is transferred, or the customer installs a Tsitriks farm. In theory, you can bring your own server with such a farm to the “cloud”, but this feature is rarely needed. Two buttons - and now you can copy the settings for your piece of iron. Plus, we can well combine the “clouds”, including the shoulders of various hypervisors inside the data center.
Often there are mistakes in performance. Channel, wheels - could underestimate the requirements for the car. For example, often on the “iron” crossings, those who are accustomed to working without virtualization, forget that you need to give a few percent of the performance to the work of the hypervisor. If someone on the servers had graphic cards - we do not have graphic cards in the "cloud". There was an embarrassment: the customer did not read the spec, and did virtualization for video editing, 32 cores, 200 gigs of operatives. But we had this machine as a “cloud” server, and it was assumed that it gives the desktop only for consoles (there was a limit of 1.5 FPS for this exchange). But the storage with a wild performance: you can choose the number of operations for certain needs, payment after the fact.
Some more customers do not know about the restrictions in licensing products placed in the "cloud". For example, Windows virtual machines are licensed exclusively by an IaaS service provider (as the owner of physical servers).
Often, when migrating, network errors appear that are many years old. For example, in one difficult move, it turned out that MSS was incorrectly configured - a crutch remained from 2007, and no one touched him as a result. The result was that the RDP sessions were torn.
There is also a feature of external addressing. It turns out that machines can enter the Internet through NAT, there is a static translation.
One of the customers wanted to have in the "cloud" a subnet of "white" IP addresses from a particular provider. In order to save money and time, we came up with the following scheme:
- A VPN tunnel was built from the customer’s router to the “cloud”, but without specifying AS CROC.
- Since the customer is a provider, he has allocated the necessary white subnet IP addresses.
- Traffic through VPN came to the equipment of the provider and was transmitted via its own AS via BGP to the Internet.
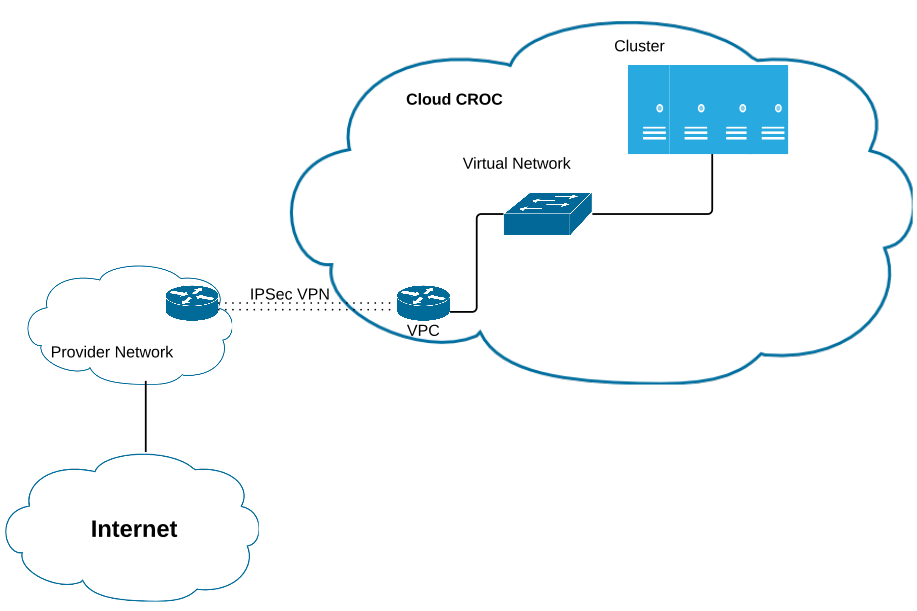
That is, they simply transmitted their Internet address through their external server, that is, they did not go through the “cloud” output, but through the router at the factory. They did not bother, because the channel allowed.
That's about it. Read more about the "clouds" here:
Source: https://habr.com/ru/post/324654/
All Articles