Quadstor - performance and reliability
In the continuation of the article "Quadstor - a virtual SAN for state employees" as promised, the comparative speed tests of VSAN Quadstor HA and VSAN Starwind HA. As well as the Quadstor HA reliability test with simulated shutdown of one of the HA nodes.
To test the speed benchmarks of VSAN Quadstor and Starwind, 5 virtual machines were created based on a single iron host with VMware ESXi 6.5. Virtual machines for those. characteristics are exactly the same (twin brothers) (2xCPU, RAM-3Gb, 2x1Gb LAN,).

As can be seen in the figure (above): two VMs (virtual machines) under Windows Server 2008 R2 with StarWind 6 (which was), two VMs under Linux CentOS 7.3 with Quadstor 3.2.11, and one VM under Windows Server 2008 R2 for tests. Then, the Quadstor VM pairs allocated 50GB of disk each (not counting the disk for the OS) and combined them into the Quadstor ON, and StarWind allocated 50GB of disks each of the VM pairs (not counting the disk for the OS) and combined them into Starwind HA.
')
Next, the created pools of disks with Quadstor ON and Starwind HA via iSCSI connected to the VMware ESXi host (figure below).
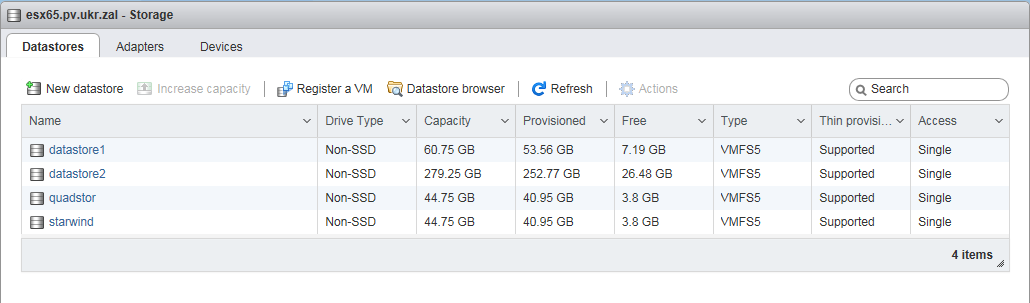
datastore1 and datastore2 are local VMware ESXi host disks, and quadstor and starwind are iSCSI disks. It turns out that the local disk datastore2 of the VMware ESXi host via virtual machines is again allocated via iSCSI to the host (of itself).
Such a solution is convenient when, for example, there are only two powerful servers and nothing else, and you need to create a fault-tolerant cluster such as VMware HA or Hyper-V HA or Windows Server Claster, etc. Then we allocate all servers on the two servers by virtual machine, issue all server disk space ( except for the disk with the OS), these VMs are merged into HA and from virtual machines we give two servers via iSCSI. Servers understand this disk as separate disk storage by iSCSI, and based on this, you can build a HA cluster using two servers.
Returning to our "sheep". I connect 4 disks to VM “VM_TEST” (figure below).
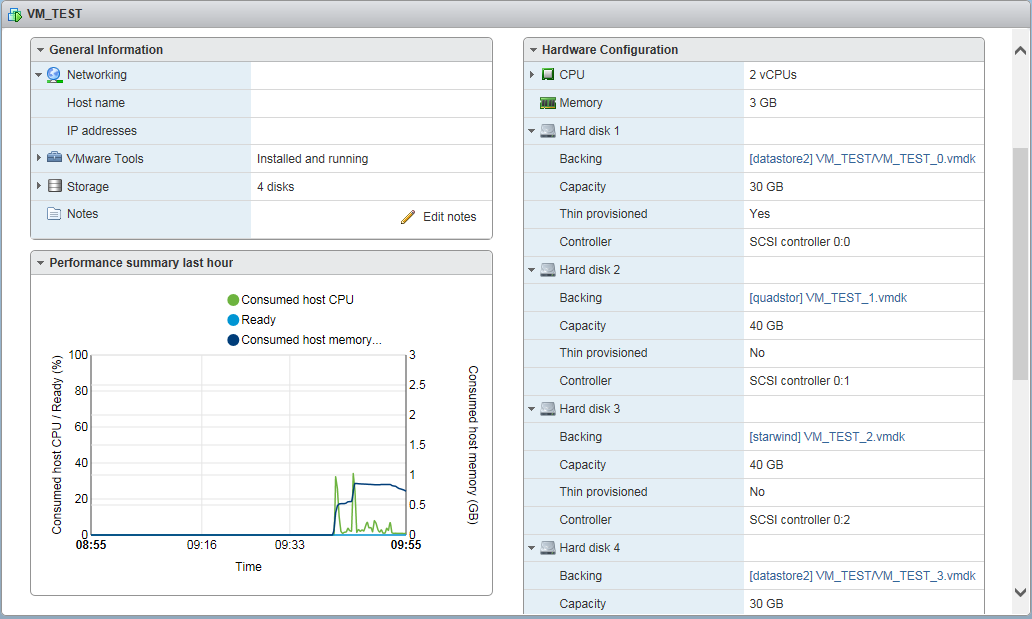
Hard disk 1 and Hard disk 4 is a local host disk (datastore2), Hard disk 2 is a Quadstor AT disk, Hard disk 3 is a Starwind HA disk.
The tests took place in two stages:
Synthetic test.
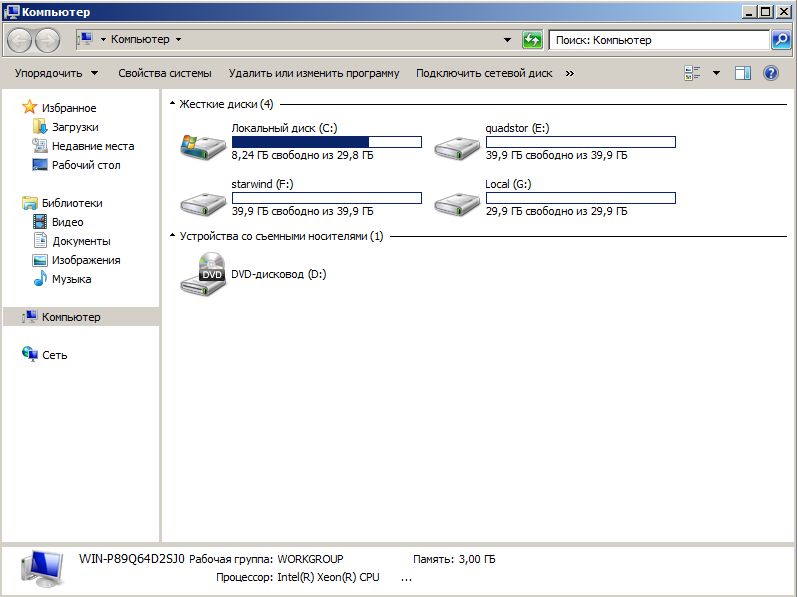
As mentioned above, there are 4 disks connected to the VM_TEST VM (image below).
Tests on the Crystal Disk Mark were launched to each disk in two modes, with 100MB of data and 2GB of data.
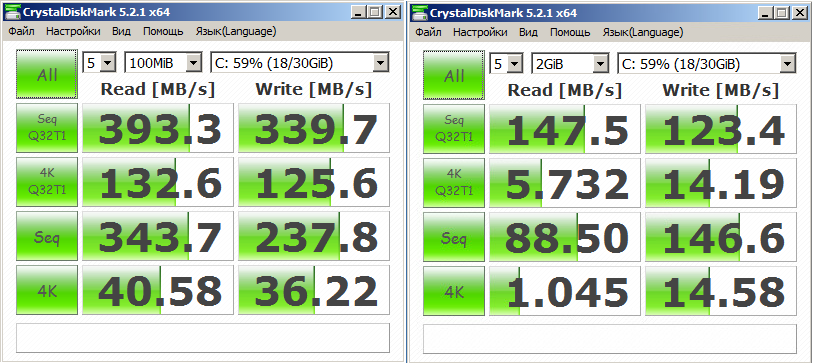
Test drive C: (Local, system drive) (figure below)
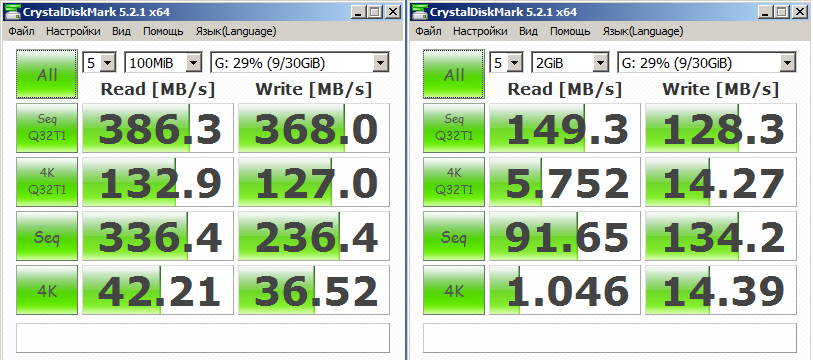
Drive Test E: (Quadstor Drive) (Figure below)

Disk test F: (Starwind disk) (see figure below)
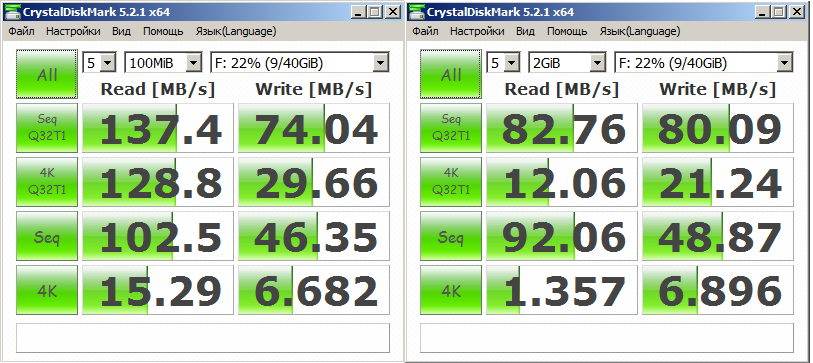
Disk Test G: (Local Disk) (Figure below)
These are the tests, comments unnecessarily, who knows he will understand everything. The only thing I will add is that it is strange that the C: drive and the G: drive are different, although this is the same local drive.
Test the usual copy.
This test will be a little more interesting. I wrote a small bat file that copies one large file of 7.71GB in size and many small files (about 10,000 files) with a total size of 1.94GB.
Sample bat file:
As you can see, the bat file is simple, using the usual commands, the iso file and the entire C: \ Windows \ System32 folder are copied and written to the log file (below).
==================================
"Test disk check" "QuadStor"
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017- 8: 26: 24,32
End 03/22 / 2017- 8: 31: 43,79
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017 - 8: 31: 43,79
End 03/22/2012 - 8:32: 55.69
-
==================================
“Starwind Disc Test”
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017: 8:32: 55.72
End 03/22 / 2017- 8: 37: 32.90
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017- 8: 37: 32.92
End 03/22 / 2017-8: 38: 36.80
-
==================================
“Disk check test” “Local”
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017: 8: 38: 36.82
End 03/22 / 2017- 8: 42: 37.31
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017: 8: 42: 37.31
End 03/22 / 2017-8: 43: 32.50
-
Now a little analyze this log file.
QuadStor Disk Test (E :)
Copying a large file size 7.71GB, took - 5m. 22c. - this is about 25 MB / s
Copying small files with a total size of 1.94GB took 1m. 12c. - this is about 27 MB / s
Starwind Disk Test (F :)
Copying a large file size 7.71GB, took - 4m. 27c. - this is about 29 MB / s
Copying small files with a total size of 1.94GB took 1m. 4c. - this is about 31 MB / s
Local Disk Test (G :)
Copying a large file size 7.71GB, took - 4m. 01s. - this is about 33 MB / s
Copying small files with a total size of 1.94GB, took 55s. - this is about 36 MB / s
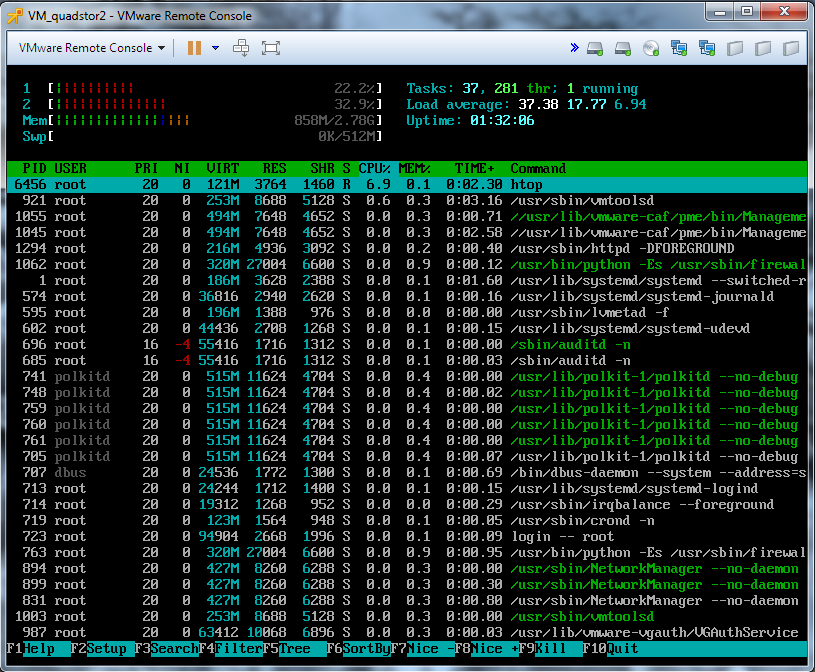
Below are screenshots of the load on Linux OS (QuadStor) and Windows OC (Starwind) while copying files.
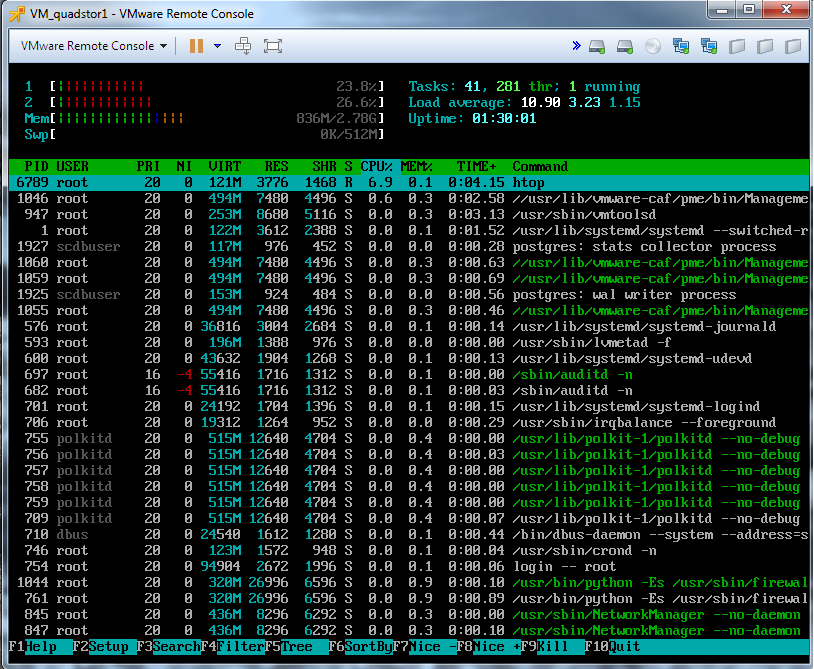
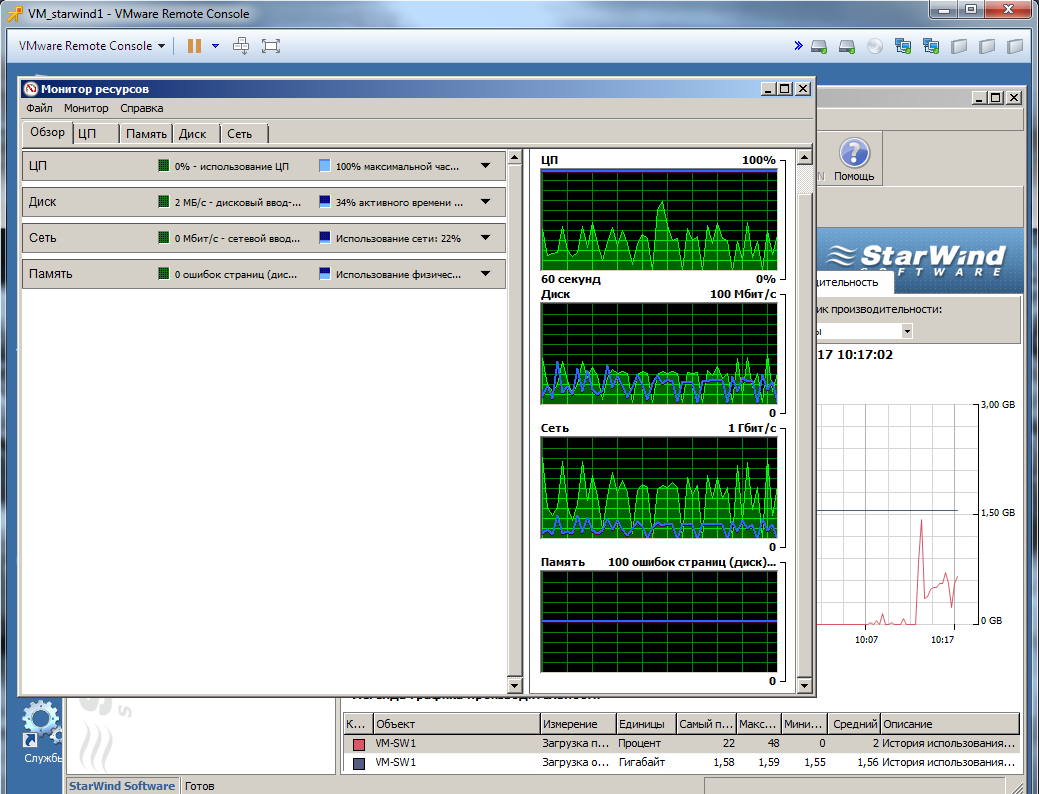
In general, the conclusions you can do yourself.
I just want to give some examples:
Standard desktop, home or work PC, the speed of copying files, an average of 20-25 MB / s. HP Proliant 380 G8 server, 2 disks (HDD SAS 300Gb 10k) RAID1 - the speed of copying files, an average of 80-100 MB / s.
The reliability check consisted in the emergency shutdown of one of the Quadstor ON nodes while recording files. Turn on copying.
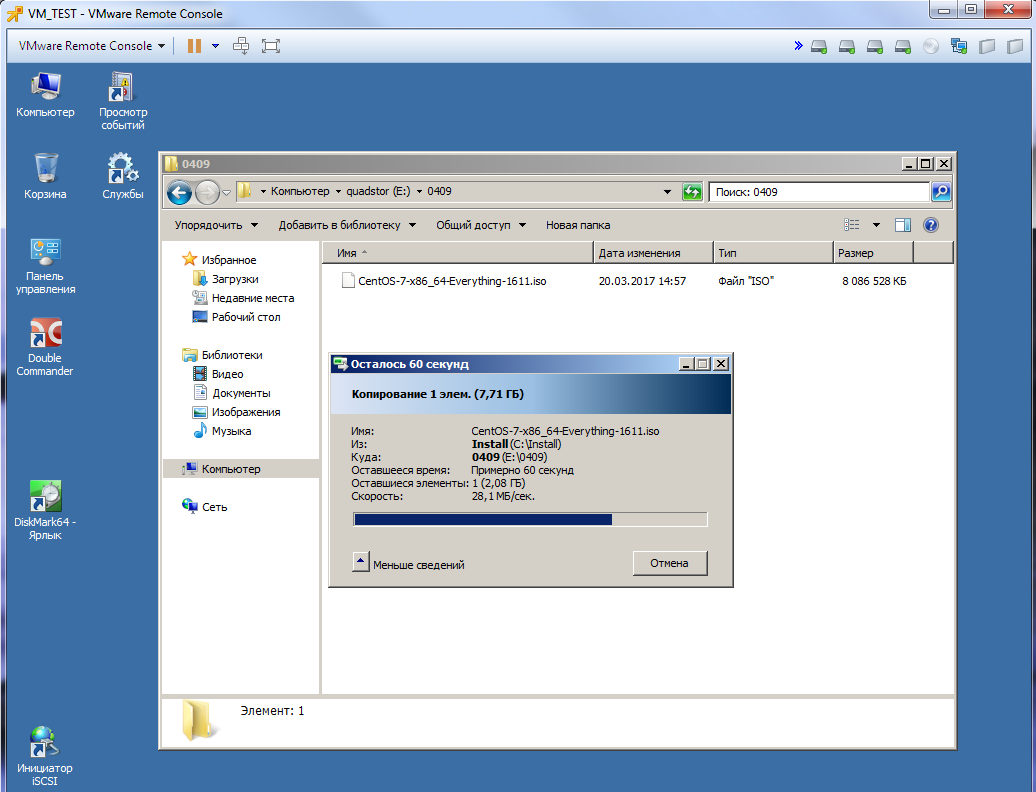
And turn off one of the nodes.

And in fact, almost nothing changes. When copying a file, when you turn off one of the nodes, copying “freezes” for 1-2 seconds. and continues on. And the load on the work node increases slightly.
When the disabled node resumes, synchronization occurs.
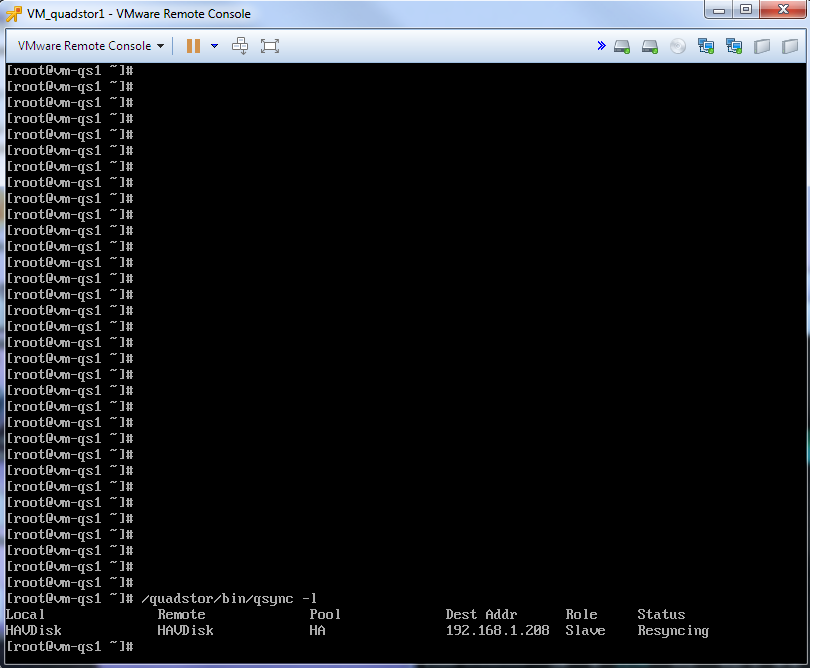
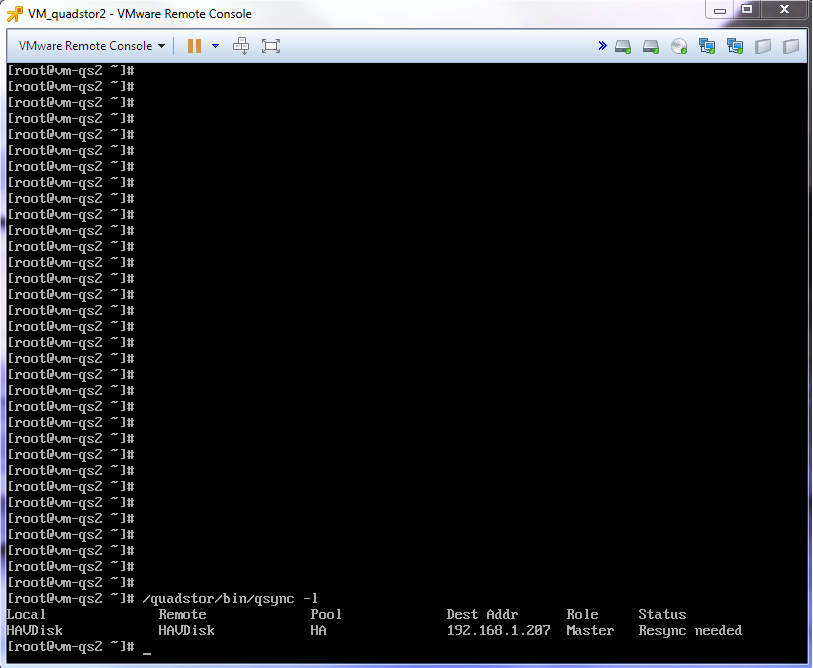
Synchronization lasted 1-2min.
Then I decided to check if you disable the synchronization network. It's a little more complicated here. Since the two nodes of each other do not see each other, they became both Master. But this situation was solved simply. I disconnected the node that was once “Slave”, connected the network and started the node. Nod understood that the “Master” already exists and becomes “Slave” and synchronization occurs.
That's all.
Performance
To test the speed benchmarks of VSAN Quadstor and Starwind, 5 virtual machines were created based on a single iron host with VMware ESXi 6.5. Virtual machines for those. characteristics are exactly the same (twin brothers) (2xCPU, RAM-3Gb, 2x1Gb LAN,).
As can be seen in the figure (above): two VMs (virtual machines) under Windows Server 2008 R2 with StarWind 6 (which was), two VMs under Linux CentOS 7.3 with Quadstor 3.2.11, and one VM under Windows Server 2008 R2 for tests. Then, the Quadstor VM pairs allocated 50GB of disk each (not counting the disk for the OS) and combined them into the Quadstor ON, and StarWind allocated 50GB of disks each of the VM pairs (not counting the disk for the OS) and combined them into Starwind HA.
')
Next, the created pools of disks with Quadstor ON and Starwind HA via iSCSI connected to the VMware ESXi host (figure below).
datastore1 and datastore2 are local VMware ESXi host disks, and quadstor and starwind are iSCSI disks. It turns out that the local disk datastore2 of the VMware ESXi host via virtual machines is again allocated via iSCSI to the host (of itself).
Such a solution is convenient when, for example, there are only two powerful servers and nothing else, and you need to create a fault-tolerant cluster such as VMware HA or Hyper-V HA or Windows Server Claster, etc. Then we allocate all servers on the two servers by virtual machine, issue all server disk space ( except for the disk with the OS), these VMs are merged into HA and from virtual machines we give two servers via iSCSI. Servers understand this disk as separate disk storage by iSCSI, and based on this, you can build a HA cluster using two servers.
Returning to our "sheep". I connect 4 disks to VM “VM_TEST” (figure below).
Hard disk 1 and Hard disk 4 is a local host disk (datastore2), Hard disk 2 is a Quadstor AT disk, Hard disk 3 is a Starwind HA disk.
The tests took place in two stages:
- Synthetic test using Crystal Disk Mark v5.2
- Test the usual copying of large and small files.
Synthetic test.
As mentioned above, there are 4 disks connected to the VM_TEST VM (image below).
Tests on the Crystal Disk Mark were launched to each disk in two modes, with 100MB of data and 2GB of data.
Test drive C: (Local, system drive) (figure below)
Drive Test E: (Quadstor Drive) (Figure below)
Disk test F: (Starwind disk) (see figure below)
Disk Test G: (Local Disk) (Figure below)
These are the tests, comments unnecessarily, who knows he will understand everything. The only thing I will add is that it is strange that the C: drive and the G: drive are different, although this is the same local drive.
Test the usual copy.
This test will be a little more interesting. I wrote a small bat file that copies one large file of 7.71GB in size and many small files (about 10,000 files) with a total size of 1.94GB.
Sample bat file:
@echo off set NAME=%1 set DISK=%2 set LOG=log_%date%.txt echo ================================== >>%LOG% echo " " %NAME% >>%LOG% echo ================================== >>%LOG% echo " ( - 7,71Gb)" >>%LOG% echo ---------------------------------- >>%LOG% echo Start %date%-%time% >>%LOG% copy /Y CentOS-7-x86_64-Everything-1611.iso %DISK%\CentOS-7-x86_64-Everything-1611.iso echo End %date%-%time% >>%LOG% echo ---------------------------------- >>%LOG% echo " ( - 1,94Gb)" >>%LOG% echo ---------------------------------- >>%LOG% echo Start %date%-%time% >>%LOG% xcopy /Y /EC:\Windows\System32 %DISK%\ echo End %date%-%time% >>%LOG% echo ---------------------------------- >>%LOG% As you can see, the bat file is simple, using the usual commands, the iso file and the entire C: \ Windows \ System32 folder are copied and written to the log file (below).
==================================
"Test disk check" "QuadStor"
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017- 8: 26: 24,32
End 03/22 / 2017- 8: 31: 43,79
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017 - 8: 31: 43,79
End 03/22/2012 - 8:32: 55.69
-
==================================
“Starwind Disc Test”
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017: 8:32: 55.72
End 03/22 / 2017- 8: 37: 32.90
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017- 8: 37: 32.92
End 03/22 / 2017-8: 38: 36.80
-
==================================
“Disk check test” “Local”
==================================
"Copying a large file (size - 7.71Gb)"
-
Start 03/22/2017: 8: 38: 36.82
End 03/22 / 2017- 8: 42: 37.31
-
"Copying many small files (size - 1.94Gb)"
-
Start 03/22/2017: 8: 42: 37.31
End 03/22 / 2017-8: 43: 32.50
-
Now a little analyze this log file.
QuadStor Disk Test (E :)
Copying a large file size 7.71GB, took - 5m. 22c. - this is about 25 MB / s
Copying small files with a total size of 1.94GB took 1m. 12c. - this is about 27 MB / s
Starwind Disk Test (F :)
Copying a large file size 7.71GB, took - 4m. 27c. - this is about 29 MB / s
Copying small files with a total size of 1.94GB took 1m. 4c. - this is about 31 MB / s
Local Disk Test (G :)
Copying a large file size 7.71GB, took - 4m. 01s. - this is about 33 MB / s
Copying small files with a total size of 1.94GB, took 55s. - this is about 36 MB / s
Below are screenshots of the load on Linux OS (QuadStor) and Windows OC (Starwind) while copying files.
In general, the conclusions you can do yourself.
I just want to give some examples:
Standard desktop, home or work PC, the speed of copying files, an average of 20-25 MB / s. HP Proliant 380 G8 server, 2 disks (HDD SAS 300Gb 10k) RAID1 - the speed of copying files, an average of 80-100 MB / s.
Reliability.
The reliability check consisted in the emergency shutdown of one of the Quadstor ON nodes while recording files. Turn on copying.
And turn off one of the nodes.
And in fact, almost nothing changes. When copying a file, when you turn off one of the nodes, copying “freezes” for 1-2 seconds. and continues on. And the load on the work node increases slightly.
When the disabled node resumes, synchronization occurs.
Synchronization lasted 1-2min.
Then I decided to check if you disable the synchronization network. It's a little more complicated here. Since the two nodes of each other do not see each other, they became both Master. But this situation was solved simply. I disconnected the node that was once “Slave”, connected the network and started the node. Nod understood that the “Master” already exists and becomes “Slave” and synchronization occurs.
That's all.
Source: https://habr.com/ru/post/324598/
All Articles