Cones stuffed with 15 years of using actors in C ++. Part I
This article is the first part of the text version of the report of the same name from the February C ++ CoreHard Winter 2017 conference. It so happened that for 15 years now I have been responsible for developing the SObjectizer framework. This is one of the few still alive and still developing OpenSource frameworks for C ++ that allow the use of the Actor Model. Accordingly, during this time, it has repeatedly been tried to try the Model Actors in the case, as a result of which some experience has been accumulated. Basically it was a positive experience, but there are some unobvious points about which it would be good to know in advance. About what rake it was possible to step on, what cones were stuffed, how to simplify your life and how it affected the development of SObjectizer, and will be discussed further.
I suspect that much of what I’m going to talk about is well known in the Erlang community. But the Erlang community weakly intersects with the C ++ community. In addition, there is a difference between what is available to the Erlang developer and what is available to the C ++ developer. Therefore, I hope that this article will be interesting and useful for C ++ nicknames.
SObjectizer itself appeared in the spring of 2002 in the company Intervale. SObjectizer was created exclusively as a working tool. Therefore, he immediately went "to the business" and was used inside several products both within the company and abroad:
- electronic and mobile commerce;
- mobile banking;
- SMS / USSD traffic aggregation;
- simulation modeling;
- test benches for checking software of railway transport automated control systems;
- prototyping of a distributed system for collecting measurement information.
Some of these products are still in operation.
A few words about the relevance of the Model Actors
We briefly refresh the main points of the Actors Model:
- an actor is an entity with behavior;
- actors respond to incoming messages;
- having received the message, the actor can:
- send some (finite) number of messages to other actors;
- create a certain (finite) number of new actors;
- define for yourself a new behavior for processing subsequent messages.
The Model of Actors implies that applied work in an application is performed by separate entities, actors who interact with each other only by means of asynchronous messages.
The actor sleeps waiting for an incoming message, then when an incoming message appears, it wakes up and processes the message, then falls asleep again until it receives the next message.
For historical reasons, we use the term agent in the SObjectizer, not the actor , so later in the text both terms will be used, they will be the same.
And a couple of words about the applicability of the Model Actors in C ++
In my personal opinion, using the Actor Model in C ++ gives us a number of bonuses:
- Each actor has its own state, which is accessible only to him. This greatly simplifies life in multi-threaded programming;
- transferring information through asynchronous messages is a convenient and natural way to solve some types of tasks. And the Model of Actors in such tasks reduces the semantic gap between the subject area and the implementation;
- when using the Actor Model, the connectivity of the components is very weak, which simplifies their composition and testing;
- interaction mechanism based on asynchronous messages is very good with timers. Using timers as deferred or periodic messages in the Actor Model is a pleasure;
- C ++ nicknames are new to multithreaded programming based on the Model Actors surprisingly fast. Yesterday's students in a short time begin to write reliable multi-threaded code.
Rake and stuffed cones
We receive the bonuses described above only if the task falls well on the Actor Model. A good bed is not always. So you need to be careful: if we take up the Actor Model, for example, in heavy computational problems, we can get more pain than pleasure.
If the Model of Actors is well suited for some subject area, then by using the right tools, you can greatly simplify your life.
But in this case, it is highly desirable to have an idea about some things that can be classified as “rake” or “pitfalls”. Next, I will talk about some of the rakes, which had a chance to trample personally. I hope this will help someone to fill fewer cones than I could.
Agent overload
One of the worst pitfalls is the problem of overloading actors.
Overload occurs when the agent does not have time to process their messages.
For example, someone loads the agent at a rate of 3 messages per second, and the agent can process only 2 messages per second. It turns out that in the agent's queue on each clock cycle there is another unprocessed message.
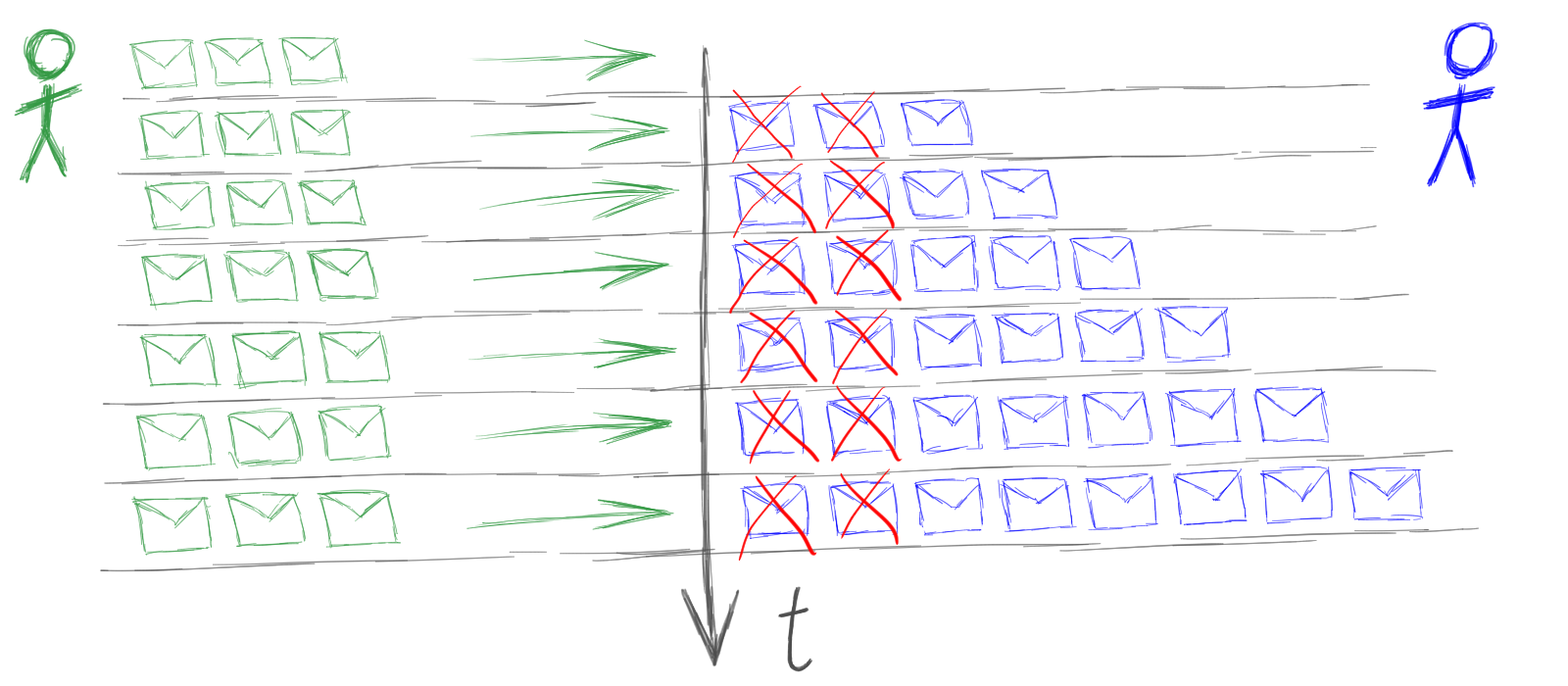
If the agent is not protected from overloads in any way, the consequences will be sad: the queue of incoming messages will swell, the memory will open, the memory consumption will slow down the speed of work, which will lead to more rapid growth of queues, etc. As a result, the application degrades to a complete loss of performance.
Why is overloading so terrible in Model Actors?
With asynchronous interaction based on sending messages, there is no simple way to implement feedback (it is also back pressure). Those. the sending agent simply does not know how full the receiving agent's queue is and cannot just pause until the receiving agent clears its turn. In particular, both the sending agent and the receiving agent can work on the same working thread, therefore if the sending agent “falls asleep”, it will block the common working thread together with the receiving agent.
The difficulty in dealing with congestion is that a good overload protection mechanism must be tailored to a specific task. Somewhere in the event of an overload, you can throw out the most recent messages. Somewhere you need to throw away the oldest. Somewhere for old messages you need to choose another processing strategy.
Where is the exit?
We learned from our experience that the campaign on the basis of two agents, the collector and performer, each of which works on different working threads, proved itself quite well. Agent-collector collects messages and provides overload protection. The perfomer agent periodically requests another batch of messages from the collector agent. When the next portion is processed, the agent-performer again requests the next portion, etc.
But the bad thing here is that all this needs to be done by the application programmer. It would be better to have a set of ready-made tools for this purpose. Therefore, we have built in SObjectizer a special mechanism called " message limits " that allows the programmer to use several ready-made simple policies to protect their agents from overload.
It may look like this in the code like this:
class collector : public so_5::agent_t { public : collector(context_t ctx, so_5::mbox_t quick_n_dirty) : so_5::agent_t(ctx // get_status . + limit_then_drop<get_status>(1) // , // , . + limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } ) // , // . + limit_then_abort<get_messages>(1)) ... }; Small explanation
By means of "limits for messages", you can specify, for example, that it is enough to have only one get_status message in the agent's message queue, and other messages of this type can be easily and painlessly thrown out:
limit_then_drop<get_status>(1) You can specify that the queue should have no more than 50 messages of the type request, and the remaining messages of this type should be sent to another agent who will perform processing in some other way (for example, if this is a request for resizing a picture, then you can do a resize more roughly but much faster):
limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } ) In some cases, exceeding the allowable number of messages in the queue is an indication that everything is very bad and it is better to interrupt the entire application. For example, if a second message like get_messages appears in the queue, the first one has not yet been processed,
then obviously something goes completely wrong, so you need to call std :: abort, restart and start all over again:
limit_then_abort<get_messages>(1) The message limits added to SObjectizer are not a complete overload protection mechanism (since such mechanisms should be sharpened for a specific task), but in simple cases and with rapid prototyping, message limits were quite successful.
Message Delivery Unreliable
For some, this may be a surprise, but the delivery of the sent message to the recipient is not guaranteed. Those. the message may just be lost somewhere along the way. There are several main reasons why a sent message may not reach the receiving agent:
- the recipient is simply not there. Those. it existed at the time of dispatch, but then managed to disappear;
- the recipient is, the message reached him, but the recipient simply ignored the message in its current state;
- the message does not reach the recipient, for example, due to the mechanism of "limits for messages".
In other words, when you asynchronously send a message to someone, you have no confidence that the message will reach the recipient.
Let's imagine that agent A sends a message x to agent B and expects to receive a message y in response. When message y reaches Agent A, Agent A is happy and continues his work.
However, if the message x to Agent B did not reach, but was lost somewhere along the road, then Agent A will wait in vain for a response message y .

If you forget about the unreliability of messages, you can easily find yourself in a situation where the application simply stopped working after losing several messages. As in this example: Agent A cannot continue to work until it receives message y.
Accordingly, the question arises: "If the messages are unreliable, then how to live with it?"
What to do?
You need to design the work of agents so that the loss of messages does not affect the performance. There are two easy ways to do this:
- Resending message after timeout. So, if Agent A did not receive message y from Agent B within 10 seconds, then Agent A can re-send message x . But! Here you need to understand that message forwarding is a direct way to agent overloading. Therefore, Agent B must be protected from overload by x .
- Roll back the operation if its result was not received within a reasonable time. So, if Agent A does not receive a message from Agent B within 10 seconds, Agent A can cancel previously performed actions on his side. Well, or set the status “result unknown” for your current operation and proceed to processing the next operation.
At first glance, it may seem that if the interaction through asynchronous messages is unreliable, then the application itself, which is developed on the basis of the Actors Model, will also be unreliable. In practice, it turns out to be more interesting: the reliability of the application just increases (in my opinion, at least). This is explained by the fact that the developer is immediately forced to put in his agents some mechanisms for overcoming abnormal situations. And these mechanisms work when abnormal situations do occur.
Error codes vs Exceptions
We attacked this rake exactly as the developers of SObjectizer. Although the consequences affect the users. The fact is that when we made the first version of SObjectizer in 2002, we did not use exceptions to report errors. Return codes were used instead.
Over time, it turned out that error codes are not reliable. Here the rule worked: if something can be forgotten, it will be forgotten. It is enough to skip error handling somewhere or reduce error handling only to its logging, then this will eventually come out sideways. For example, the application will stop processing any user requests. Traces of the problem can then be found somewhere in the log. But this is post factum, when the problem has already appeared on users.
Therefore, when in 2010 we started making a new version of SObjectizer, breaking compatibility with the previous one, we switched to using exceptions to report bugs.
In my opinion, this has a positive effect on the reliability and quality of applications. Problems are no longer “swallowed” and any deviation from the norm immediately becomes noticeable.
Question almost a million
Let's imagine a situation where agent B processes a message from agent A. And during the processing of this message, an error occurs, agent B throws an exception from its handler. What to do with it?
This problem has two components:
- Agent B runs on a context that is owned by SObjectizer. And SObjectizer has no idea what to do with the exception that flew out of agent B. Maybe this exception means that everything is completely bad and there is no point in continuing to work further. Or maybe it's some kind of nonsense that you can ignore.
- Even if you catch the exception that flew out from Agent B, and try to deliver it to Agent A, you may find that:
- Agent A is simply not there, he has already ceased to exist.
- Even if Agent A is, he may simply not be interested in receiving information about the problems of Agent B.
- Even if agent A is and even if he is interested in receiving information about problems of agent B, then we may simply not deliver this information to agent A for some reason (for example, because of the protection of agent A against overloads).
What to do with it?
In SObjectizer, we made a special flag that determines what to do if an exception is thrown from the agent. For example, kill the entire application at once, deregister the problem agent, or ignore the exception.
The fact that the agent is deregistered when an exception is issued outside allows the supervisor mechanisms to be organized, as in Erlang. That is, if some agent “falls” due to an exception, then the agent-supervisor will be able to react and restart the “fallen” agent to such a fall.
Here you are not Erlang, here the climate is different
Only here, our practice shows that in the case of C ++, this is not all that rosy, as in Erlang or some other safe language. In Erlang, the principle of let it crash is elevated to absolute. Roughly speaking, it is not customary to pay attention even to division by zero. Well, try to divide the Erlang process by zero, well, it will fall, the Erlang virtual machine will clear the garbage, the supervisor will create the crashed process again and that's it. But in C ++, the attempt to divide by zero is likely to kill the entire application, and not just the agent in which the error occurred.
Another important point: the agent is a C ++ object. If we decide to withdraw it from the application, we still need to carefully remove it, like any other object, whose lifetime has expired. Those. a destructor will be called for the agent object, and this destructor should work fine.
This means that the agent object must provide at least a basic guarantee of the security of exceptions. That is, if the agent object has issued an exception, no resource leaks or damage to anything in the program should arise.
Which automatically leads to the fact that in C ++ the principle of “let it crash” looks much different than in Erlang. And if we are already starting to take care that the agent provides any imputed guarantees with respect to the exceptions, then it quickly turns out that we have no reason to shift our concerns about overcoming the consequences of errors on the framework. This can be done by the agent himself.
What leads to the fact that agents naturally begin to support nothrow warranty. Those. Do not let out any exceptions at all. Roughly speaking, message handlers in agents, in which something serious is done, contain try-catch blocks inside. And if, at the same time, an exception from the agent flies out (which means something unexpected in the catch block), then something is wrong with the whole application. And in this case, you need to kill not one problem agent, but the entire application. Since we can not guarantee its further correct operation.
Hence the moral: C ++ is not Erlang and it is not worthwhile in C ++ to migrate error handling approaches suitable for Erlang or some other programming language.
On this for the first part of all, continued here .
')
Source: https://habr.com/ru/post/324420/
All Articles