CEPH for pumping

Something like this is the first installation of CEPH on real hardware.
You installed cef, but it slows down and falls why it is not clear? Then you came to the right place! I'll pump your ceph.
You listened to your friends and put the first disks on your car, and then you are surprised that she does not make a lap record at the local cartadrome, and you dreamed of the Nurburgring? Right! It does not happen, you cannot get away from physics anywhere, so before building a cluster you should calculate IOPS (at least approximately), the required volume and select disks for this. If you are thinking of scoring a cluster of 8TB disks, then you should not expect hundreds of thousands of IOPS from it. What are IOPS-s and their approximate value for different types of disks given here .
Another thing worth paying attention to is the magazines.
')
For those who do not know: ceph first writes the data to the log, and after some time transfers it to a slow OSD. Immediately there are fans to save money, take one or two SSDs faster and make them a magazine for 20-25 OSD. First, your IOPS will squeeze a little. Secondly, it works until the first death of the SSD. Then you have all the OSD that were on this SSD. By setting the logs should be approached very carefully. The recommendations on ceph.com indicate that no more than 5-6 OSD is needed per SSD, but it does not indicate what log size to specify and which filestore max sync interval parameter to select. Unfortunately, these parameters are individual for each cluster, so you will need to select them yourself through numerous tests.
The second thing that catches the eye, in our carriage, are two large sofas instead of seats. You won't put two sofas instead of seats in your car in 2017?

In relation to CEPH, we are now talking about pools.
Usually they make one big pool and stop at this, but this is wrong. One large pool leads to problems with ease of management and upgrade. How is the upgrade related to pool size? And here it is: it is very dangerous to upgrade a live cluster on the fly, so it makes sense to deploy a new small row, otrepletirovat data to a new pool and switch. From this comes the recommendation: to divide the data into logical entities. If you have an openstack, then it makes sense to start from the openstack zones. With a large number of servers, spread them on racks and rule with crushmap rules.
Now crawled under the hood.

If we are not designing a system for tens of thousands of IOPS, then the processor can be supplied with an entry level. However, keep in mind: the more disks per server and the more they can give out IOPS, the greater the load. Therefore, if you have an extrabudgetary configuration of 2-3 JBODs per server (which is a bad idea in and of itself), then the processor will be heavily loaded. We, with one JBOD and 30 disks, have not yet driven the processor into the regiment. But the "wiring" change. No, of course, it will start on 1 gbit / s, but when the OSD drops, the rebalance begins and here the channel is loaded to the full. Therefore, interconnect between CEPH 10 Gbit / s nodes is mandatory. The good tone rule is to do LACP.
"Suspension" is better strengthened. We put the memory on the basis of the recommended 1 gigabyte RAM for 1 TB of data. It is possible and more. In memory CEPH quite voracious.

Now about the fast ride on what was built.
CEPH has data integrity checks - the so-called scrub and deep scrub. Their launch greatly affects IOPS, so it’s better to run them with a script at night, limiting the number of PGs to be checked.
Limit the rebalance rate with the parameters osd_recovery_op_priority and osd_client_op_priority. It is quite possible to survive during the day a slow rebalance, and at night, at the moments of minimum load, run it to the full.
Do not fill the cluster out of place: the 85% limit is not just created. If there is no possibility to increase space in the cluster with new servers, then use reweight-by-utilization. Note that this utility has a default setting of 120%, and also when it starts, rebalance starts.
The weight parameter also affects the filling, but indirectly. Yes, CEPH has weight and reweight. Usually weight is made equal to the volume of the disk.

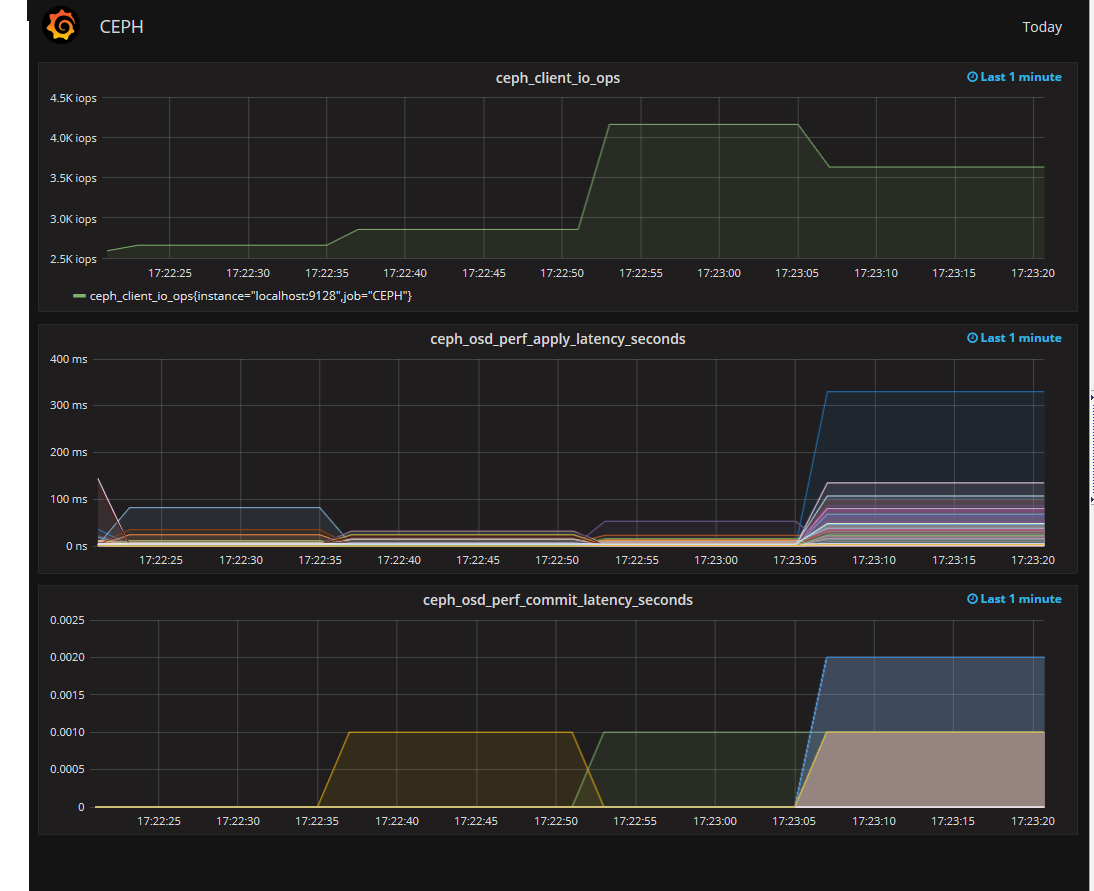
So, our CEPH is almost pumped up, it remains only to attach the monitor. You can monitor anything, but monitoring of the output of ceph osd perf is particularly interesting. Most interesting is fs_apply_latency. It is he who shows us which OSD takes a long time to respond and decreases cluster performance. Moreover, the SMART on these OSD can be quite a good one.
It looks like this.

So filming the transformations of the old carriage is over. It's time to show the backstage and disprove the myths that I heard:
- Do normally - it will be normal. With proper design CEPH does not need a large team of administrators to support it.
- There are bugs. Saw OOM on OSD. Just came OOM, killed OSD, then another. This stopped. CEPH was updated, OOM came a couple of times, but then it stopped just as suddenly. Otdebazhit failed.
- Mostly CEPH is very hungry for swap. Perhaps you need to edit the swappiness settings.
- The transition from double to triple replication is sad and long, so think hard though.
- Use single-type servers, one OS in a cluster and one version of CEPH, down to the minor. Theoretically, CEPH will start everything, but then why individually debug each piece of hardware?
- CEPH has fewer bugs than it looks. If you think you have found a bug, then first read the documentation carefully.
- Get one test bench on the physical hardware. Not everything can be checked in virtual machines.
Separately, I want to say that you should not do:
- Do not remove disks from different nodes of a flat cluster with the words “this is cef, what will it be?”. Health error will be. Depending on the amount of data in the cluster and the level of replication.
- Double replication - the path of extremes. First, there are more chances to lose data, and second, a slower rebalance.
- Dev releases let developers test, especially any new ones with bluestore. Of course, it can work, but when it crashes down, how will you get the data from the incomprehensible file system?
- FIO with the parameter engine = rbd can lie. Do not rely on it for tests.
- Do not immediately pull into the prod all the new things that you found in the documentation. First check on the physical stand.
Thanks for attention.
Source: https://habr.com/ru/post/324374/
All Articles