How and why static analyzers deal with false positives

In my previous article, I wrote that I didn’t like the approach in which static code analyzers are evaluated using synthetic tests. The article cited an example, perceived by the analyzer as a special case for which a warning is not consciously issued. To be honest, I did not expect such a surge of comments on the topic that the analyzer may very rarely, but did not issue an error warning due to the false-tripping mechanisms implemented in it. The fight against false positives is such a large component of any static analyzer that somehow it is not even clear what is there to actually discuss. This must be done and everything. Such mechanisms exist not only in our analyzer, but also in other analyzers / compilers. However, since this moment caused such a heated discussion, I think it is worth paying attention to it, therefore I wrote this explanatory article.
Introduction
It all started with the publication " Why I do not like synthetic tests ." We can say that this article was written in reserve. Sometimes in discussions I need to explain why I do not like certain synthetic tests. It’s hard to write long answers each time, so I’ve been planning to prepare an article for a long time, which I can link to. And when I looked at the itc-benchmarks , I realized that it was a good time to write the text, while my impressions were fresh and you could choose a couple of tests that I can include in the article.
I did not expect such rejection of this article by the community of programmers and comments at various sites and in the mail. The reason for this, probably, is that I have been developing static analyzers for 10 years now and some questions seem so obvious to me that I consider them too brief and categorical. I will try to eliminate misunderstandings and tell how and why the fight against false positives is conducted.
The text of the article can relate to any tool, PVS-Studio itself has nothing to do with it. A similar article could be written by someone from the GCC, Coverity or Cppcheck developers.
')
Hand work with false positives
Before proceeding to the main topic, I want to clarify the markup of false messages. I got the impression that many people began to write negative comments without understanding what was being said. I met comments in the spirit of:
You went the wrong way. Instead of providing mechanisms for suppressing false positives, you try to fix them yourself as much as possible and are most likely mistaken.
I will give explanations to no longer return to the discussion of this topic. PVS-Studio provides several mechanisms for eliminating false positives, which are inevitable in any case:
- Suppress warnings on a specific line using comments.
- Mass suppression of warnings that occur because of the macro. This is also done with special comments.
- Similarly for lines of code containing a specific sequence of characters.
- Complete shutdown of diagnostics irrelevant for this project using settings or special comments.
- Exclusion from the analysis of a part of the code using #ifndef PVS_STUDIO.
- Change the settings of some diagnostics using special comments. They are described in the description of specific diagnostics (see V719 : V719_COUNT_NAME as an example).
All of these features are described in detail in the “ Suppressing False Warnings ” documentation. You can also turn off warnings or suppress warnings in macros by using configuration files (see pvsconfig).
Separately, it is necessary to single out the system of mass marking of warnings using a special database. This allows you to quickly integrate the analyzer into the process of developing large projects. The ideology of this process is described in the article " Practice of using the PVS-Studio analyzer ".
All this refers to an explicit indication that it is not considered an error. However, this does not remove the task of minimizing warnings with the help of special exceptions. The value of the analyzer is not that he swears at everything, but how much he knows the situations when he does not have to swear.
Theoretical background
Now a little theory. Each diagnostic analyzer message is evaluated by two characteristics:
- Criticality of the error (how fatal it is for the program).
- The reliability of the error (what is the probability that a real defect was found, and not just a code that the analyzer did not understand).
These two criteria for each diagnosis can be combined in any proportions. Therefore, it is ideal to describe the types of diagnostics, placing them on a two-dimensional graph:
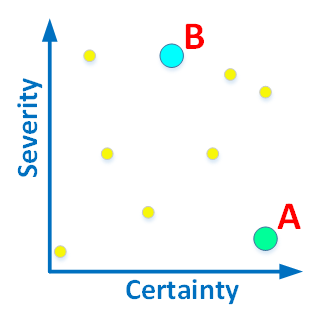
Figure 1. Diagnostics can be assessed by severity and reliability.
I will give a couple of explanatory examples. Diagnostics A , which determines that there is no header from comments in the * .cpp file, will be located in the lower right corner. A forgotten comment will not cause the program to crash, although it is an error in terms of the coding standard adopted by the team. In this case, you can very accurately determine whether there is a comment or not. Therefore, the accuracy of the error is high.
Diagnostics B , which says that some of the class members are not initialized in the constructor, will be placed in the middle of the upper part. The reliability of this error is not very high, since the analyzer could simply not understand how and where this member is initialized ( this is difficult ). The programmer can perform initialization after the constructor has completed its work. Thus, an uninitialized member in the constructor is not necessarily an error. But this diagnosis is at the top of the graph, since if it is really a mistake, then it will critically affect the performance of the program. Using an uninitialized variable is a serious defect.
I hope the idea is clear. However, I think the reader will agree that such a distribution of errors on a chart is difficult to understand. Therefore, some analyzers simplify this graph to a table of nine or four cells:

Figure 2. Simplified version of the classification. 4 cells are used.
So, for example, the authors of the Goanna analyzer did until they were bought by Coverity, which Synopsys later bought. They just classified the warnings issued by the analyzer, referring them to one of 9 cells:

Figure 3. Fragment from Goanna reference guide (Version 3.3). Used 9 cells.
However, this method is also unusual and inconvenient for use. Programmers want warnings to be located on a one-dimensional chart: it doesn’t matter -> important. This is customary, especially since compiler warnings are built on the same principle, divided into different levels.
To reduce the two-dimensional classification to one-dimensional is not easy. This is how we arrived at the PVS-Studio analyzer. We simply do not have the bottom of a two-dimensional graph:
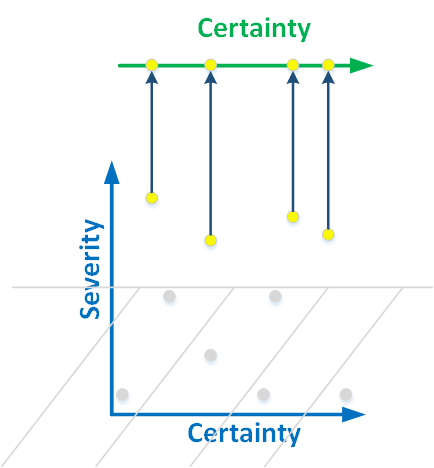
Figure 4. We project high-level warnings onto the line. Errors begin to be classified by authenticity.
We identify only those errors that may lead to a program malfunction. A forgotten comment at the beginning of the file can not lead to the fall of the program and is not interesting to us. But we are looking for an uninitialized member of the class, as this is a critical error.
Thus, we need to classify errors according to their level of reliability. This level of confidence is nothing other than the distribution of analyzer messages into three groups (High, Medium, Low).

Figure 5. Fragment of the PVS-Studio interface window. Enabled to view the general purpose diagnostics level High and Medium.
And the same warning can get at different levels, depending on how much the analyzer is sure that he found the error, and did not give a false positive.
In this case, I repeat that all warnings are looking for errors that may be critical for the program. Just sometimes the analyzer is sure more, and sometimes less, that I found an error.
Note. Of course, there is a certain relativity. For example, in PVS-Studio there is a warning, the V553 which the analyzer issues when it encounters a function with a length of more than 2000 lines of code. Such a function need not contain an error. But in practice, the probability is extremely high that this function is a source of errors. This feature cannot be tested by unit tests. You can consider the presence of such a function in the code as a defect. However, there are only a few such diagnostics and the main task of the analyzer is to search for exits beyond the array, unspecified behavior and other fatal errors (see table ).
False alarms and confidence levels
PVS-Studio warnings reveal code points, about which it can be said that they, to a greater or lesser degree, lead to serious program malfunctions. Therefore, the warning levels in PVS-Studio are not the criticality of errors, but their accuracy. However, sometimes criticality can also be taken into account for leveling, but we will not go into such small details, since the overall picture is important to us.
Briefly: Levels - this is the reliability of the identified error .
The criticism that was expressed in the previous article was that, fighting false warnings, we could lose useful warnings. In fact, warnings usually do not go anywhere, but only move according to confidence levels. And those rare variants of errors for which readers were experiencing, as a rule, simply accumulate at the Low level, which we do not recommend for viewing. Only completely meaningless warnings completely disappear, from viewing of which there will be no sense.

Figure 6. Leaving something in reserve is good. But at some point you need to be able to stop.
Readers apparently alerted my words that useful messages could disappear. I see no reason to deny it. Such a probability exists, but it is so insignificant that you should not worry about it. I will show with examples that there is no sense in taking these cases into account. But let's start with the topic of posting messages at different levels.
In some cases, it is immediately clear to what level of confidence a warning should be placed. As an example, consider a simple V518 diagnostic that identifies the following error pattern:
char *p = (char *)malloc(strlen(src + 1)); Most likely, incorrectly put a bracket. They wanted to add 1 so that it was where to place the terminal zero. But they were mistaken and, as a result, the memory is allocated 2 bytes less than it should.
Theoretically, you can imagine that the programmer wanted to write just such code, but the probability of this is extremely small. Therefore, the accuracy of this warning is very high, and it is always placed in messages of the High level.
By the way, this diagnostic does not even have a single exception. If you find such a pattern, it means an error.
In other cases, it is immediately clear that the accuracy of the error is low and the message is always sent to the Low level. We have very few such diagnostics, since this means that the diagnosis was unsuccessful. One such stupid diagnostic is V608 , which identifies repetitive sequences consisting of operators of explicit type conversions. Look for expressions like:
y = (A)(B)(A)(B)x; I do not remember why we did this diagnosis. While I have never seen that this diagnosis revealed a real error. She found redundant code (usually in complex macros), but not errors.
The majority of diagnostics “floats” through the levels, depending on the confidence of the analyzer that a real bug has been found.
We interpret the levels like this:
High (first level). Most likely, this is a mistake. Be sure to read this code! If this is not even an error, then most likely the code is poorly written and should be corrected anyway, so that it does not confuse the analyzers and other members of the development team. Let me explain with an example:
if (A == B) A = 1; B = 2; Perhaps there is no error and braces are not needed. There is a tiny chance that the programmer always wanted to assign the variable B the value 2. However, I think everyone will agree that such code should be rewritten, even if there is no error:
if (A == B) A = 1; B = 2; Medium (second level) . This code seems to contain an error, but the analyzer is not sure. If you have corrected all the warnings of the High level, it will be useful to work with the warnings of the Medium level.
Low (third level) . Low confidence warnings that we generally do not recommend for study. Please note that when we write articles about checking projects , we consider only the High and Medium levels and do not associate with the Low level.
We did the same when we worked on the Unreal Engine project. Our goal was to destroy all the warnings of the first and second levels of general purpose. We did not look at the third level.
As I said, most diagnostics can be assigned a different level, depending on the set of symptoms. Some signs may reduce, while others increase the reliability. They are selected empirically based on the diagnostics run on more than a hundred open source projects.
Consider how diagnostics can move through different levels. For example, take the V572 diagnostic, which warns about a suspicious explicit type conversion. Using the new operator, a class object is created, a pointer to which is then cast to another type:
T *p = (T *)(new A); This is a strange construction. If class A is inherited from T , then the type conversion is superfluous and you can simply remove it. If not inherited, then this is most likely an error. However, the analyzer is not completely sure that this is a mistake, and to begin with, it assigns the Medium confidence level. No matter how strange this construction may be, it sometimes corresponds to a correctly working code. I can’t give an example, because I don’t remember what those situations are.
If an array of elements is created, and then it is given to a pointer to the base class, this is much more dangerous:
Base *p = (Base *)(new Derived[10]); Here the analyzer will issue a high warning. The size of the base class may be less than the heir, and then, when accessing the p element [1], we “do not understand where” and will work with incorrect data. Even if as long as the size of the base class and the successor are the same, this code should be corrected anyway. While the programmer can carry, but it is very easy to break everything by adding a new member of the class to the heir class.
There is also a reverse situation when the casting to the same type occurs:
T *p = (T *)(new T); Such code can appear when someone has been working with C for too long and has forgotten that, unlike calling the malloc function, a mandatory type cast is not necessary. Or as a result of refactoring the old code, in which the C program turns into a C ++ program.
There is no error here and the message can not be issued at all. Just in case, it remains, but moves to the Low level. Watch this message and edit the code is not necessary, but if someone wants to bring beauty in the code, then we do not mind.
In the comments to the previous article, people were worried that warnings could accidentally disappear, which, although with a low probability, could indicate an error. As a rule, such messages do not disappear, but move to the Low level. We have just considered one such example: “T * p = (T *) (new T);”. There is no error here, but suddenly something is wrong ... Those who wish can learn the code.
Let's look at another example. Diagnostics V531 : suspiciously multiply one sizeof by another sizeof :
size_t s = sizeof(float) * sizeof(float); This is a meaningless expression and, most likely, there is some kind of mistake, for example, a typo. The analyzer will issue a High warning on this code.
However, there is a situation where the warning level is replaced with Low. This happens when sizeof (char) is one of the factors.
All the “sizeof (T) * sizeof (char)” expressions that we observed on more than a hundred projects were not errors. Almost always, these were some macros where such multiplication was obtained due to the substitution of one macro into another.
You can not look at these warnings, so they are hidden from the eyes of users in the section Low-warnings. However, those who wish can still study them.

Figure 7. Now the reader knows that he can always sail on the endless expanses of Low level warnings.
Exceptions in diagnostics
Exceptions can be made both for individual diagnostics and for diagnostic groups. Let's start with "mass destruction exceptions." Programs have code that is never executed. In fact, it is possible not to look for errors at all. Once the code is not executed, the error does not manifest itself. Therefore, many diagnostics do not apply to non-executable code. Let me explain this with an example:
int *p = NULL; if (p) { *p = 1; } When dereferencing a pointer, its only possible value is NULL. There is no other value here that could be stored in the 'p' variable. However, the exception is triggered that dereferencing is in code that is never executed. And if it is not executed, then there is no error. Dereferencing will be performed only when a value other than NULL is placed in the variable p .
Someone might say that a warning might be useful, as it will tell you that the condition is always false. But this is a concern of other diagnostics, for example, V547.
Would it be useful to someone if the analyzer starts warning that in the above code the null pointer is dereferenced? Not.
We now turn to the special exceptions in diagnostics. Let's return to the V572 diagnostics we have already reviewed:
T *p = (T *)(new A); There are exceptions when this message will not be issued. One such case is the cast to (void) . Example:
(void) new A(); The object is created and consciously left to live until the end of the program. This design could not appear by chance due to a typo. This is a conscious action to suppress warnings of compilers and analyzers on a record of the form:
new A(); Many tools will swear at this design. The compiler / analyzer suspects that the person forgot to write a pointer that the new operator returns. Therefore, the person consciously used the suppression of warnings, adding a cast to the void type.
Yes, this code is strange. But once a person asks to leave this code alone, this is the way to do it. The task of the analyzer is to look for errors, rather than forcing a person to write even more sophisticated constructions to confuse the compiler / analyzer and get rid of warnings.
Would it be useful for someone to issue a warning anyway? Not. The one who wrote this code, thanks will not tell.
Now, back to the V531 diagnostic:
sizeof(A) * sizeof(B) Are there any cases when you should not issue any messages at all, even at Low level? Yes there is.
Typical task: it is necessary to calculate the size of the buffer, the size of which is a multiple of the size of another buffer. Let's say there is an array of 125 elements of type int , and we need to create an array of 125 elements of type double . To do this, the number of elements in the array must be multiplied by the size of the object. That's just when counting the number of elements is easy to make a mistake. Therefore, programmers use special macros to safely calculate the number of elements. For more details, why and how to do this, I repeatedly wrote in my various articles (see the mention of the arraysize macro here ).
After the macro is opened, the following constructs are obtained:
template <typename T, size_t N> char (*RtlpNumberOf( __unaligned T (&)[N] ))[N]; .... size_t s = sizeof(*RtlpNumberOf(liA->Text)) * sizeof(wchar_t); The first sizeof is used to calculate the number of items. The second sizeof calculates the size of the object. As a result, everything is fine, and we correctly calculate the size of the array in bytes. Perhaps the reader does not understand what is actually being discussed. I apologize, but I do not want to deviate from the essence of the story and go into clarification.
In general, there is some magic when multiplying two sizeof operators is perfectly normal and expected. The analyzer is able to recognize such a buffer size calculation pattern and does not issue a warning.
Would it be useful for someone to issue a warning anyway? Not. This is perfectly correct and well-written code. So it is necessary to write.
Go ahead. The analyzer will issue a warning V559 on the construction of the form:
if (a = 5) To suppress a warning on similar code, the expression must be placed in double brackets:
if ((a = 5)) This is a hint to the analyzers and the compiler that there is no error, and the person consciously wants to assign a value inside the condition. I do not know who and when came up with this method of hints, but it is generally accepted and supported by many compilers and analyzers.
Naturally, the PVS-Studio analyzer will also keep silent about such code.
Perhaps, it was worthwhile to move the warning to the Low level, and not completely suppress it? Not.
Is it possible that a person accidentally puts extra parentheses around the wrong expression? Yes, there is, but extremely small. Do you often put extra brackets? I do not think. Rather, it happens 1 time for 1000 if statements . Or even less. Accordingly, the probability that due to the extra brackets an error is missed, less than 1/1000.
Perhaps it is better to issue a warning anyway? Not. Thus, we deprive a person of the “legal possibility” to avoid a warning on his code, but at the same time the probability of finding an additional error is extremely small.
I have already given similar arguments in the comments to the previous article, but they did not convince everyone. Therefore, I will try to approach this topic from another side.
I have a question for those who claim to want to see all warnings. Have you covered unit tests with 100% of the code? Not? How so, because there may be mistakes?
I will answer for my opponent. Covering 100% of the code with tests is extremely difficult and expensive. The price that will be paid for 100% coverage will not pay for the investment of time and effort.
That's the same with static analysis. There is a line at the intersection of which the time for analyzing warnings of the analyzer will exceed any reasonable limits. Therefore, there is no practical sense to issue as many warnings as possible.
Let's consider another case where the V559 warning is not issued:
if (ptr = (int *)malloc(sizeof(int) * 100)) This is a classic pattern of memory allocation and simultaneous verification that memory has been allocated. It is clear that there is no error here. The man clearly did not want to write:
if (ptr == (int *)malloc(sizeof(int) * 100)) Such an expression has no practical meaning and, in addition, leads to a memory leak. So assignment inside a condition is exactly what the programmer wanted to do.
Would it be good if the analyzer would issue warnings for such constructions? Not.
Let's finish the chapter with one more example of the exception, which will be harder for me to justify, but I will try to convey to the reader our philosophy.
Diagnostics V501 - one of the leaders in the number of exceptions. However, these exceptions do not interfere with the diagnosis to work efficiently ( proof ).
Diagnostics gives out warnings for expressions like:
if (A == A) int X = Q - Q; If the left and right operands are identical, then this is suspicious.
One of the exceptions is that you should not issue a warning if the operation '/' or '-' applies to numeric constants. Examples:
double w = 1./1.; R[3] = 100 - 100; The fact is that programmers often specifically write such expressions without simplifying them. This makes it easier to understand the meaning of the program. Most often, such situations are found in applications that perform many calculations.
An example of real code with similar expressions:
h261e_Clip(mRCqa, 1./31. , 1./1.); Can we miss any mistake due to such an exception? Yes we can. However, the benefits of reducing the number of false positives greatly exceed the potential benefits of losing useful warnings.
Such a division or subtraction is a standard common practice in programming. The risk of losing a trigger is justified.
Perhaps they wanted to write another expression there? Yes, it is not excluded. However, such reasoning is the path to nowhere. The phrase "suddenly wanted to write something else," can be applied to 1./31. And here we come to the idea of an ideal analyzer, which simply swears at all the lines in the program. Even on the empty. Suddenly it is wrong that it is empty. Suddenly there it was necessary to call the function foo () .

Figure 8. You need to be able to stop. Otherwise, a useful walk on diagnostics will turn into some kind of garbage.
It is better to lose 1 useful message than to show another 1,000 useless for the company. There is nothing terrible about it. The completeness of error detection is not the only criterion of the utility of the analyzer. Equally important is the balance between useful and useless messages. Attentiveness is quickly lost. Looking through a report with a large number of false positives, a person begins to be very inattentive to warnings and misses many errors, marking them out as not errors.
Once again briefly about exceptions
It seems to me that I explained everything in detail, but I foresee that I can once again hear a comment of this type:
I don’t understand why you should complain about misunderstanding instead of just making a function and the on / off button for it. You want - you use, you do not want, it is not necessary - do not use. Yes, this is work. But yes, this is your job.

Figure 9. The unicorn reaction to a wish to make a setting that disables all warning filtering.
It is proposed to make a button that will show all warnings without restrictions with exceptions turned off.
There is such a button already in the analyzer! There is! It is called “Low” and displays warnings with a minimum level of confidence.
Apparently, many simply misunderstand the term "exceptions." In the form of exceptions, a number of absolutely necessary conditions for adequate diagnostics of problems are drawn up.
Let me explain this, based on the diagnosis of V519 . She warns that the same object is assigned values twice in a row. Example:
x = 1; x = 2; But only in this form, the diagnosis is not applicable. Therefore, refinements begin, such as:
Exception N1. The object participates in the second expression as part of the right operand of the operation =.
If this exception is removed, the analyzer will start swearing at a completely normal code:
x = A(); x = x + B(); Does anyone want to devote their time and energy to view this type of code? Not. And convince us of the opposite will not work.
the main idea
I don’t have a goal in this article to prove or justify anything to anyone. Its purpose is to direct the thoughts of readers in the right direction. I try to explain that trying to get as many warnings from analyzers as possible is counterproductive. This does not help to make the developed project more reliable, but it takes time that could be spent on alternative methods of improving the quality of the program.
Static code analyzer is not able to detect all errors. And any other tool is also not capable. There is no silver bullet. The quality and reliability of the software is achieved by a reasonable combination of various tools, and not by trying to squeeze everything possible and impossible from any one tool.
I will give an analogy. They try to achieve safety at a construction site using a combination of various elements: training in safety measures, wearing a helmet, prohibition to start work while intoxicated, and so on. It is inefficient to choose only one component and hope that it will solve all the problems. You can make a wonderful armored helmet, and better a helmet, with a built-in Geiger counter and water supply for the day. But all this will not save from falling when performing high-altitude work. Here you need another device - a safety cable. You can start to think in the direction of the parachute built into the helmet. This, of course, is an interesting engineering problem, but such an approach is impractical. Very soon, the weight and size of the helmet will exceed reasonable limits.The helmet will begin to interfere with the builders, anger them, slow down the pace of work. It is likely that builders will begin to secretly remove the helmet and work without it.
If the user has won all the warnings of the analyzer, it is unreasonable to seek to see as many warnings as possible at an ever lower level of confidence. It will be more useful to do unit tests and bring the code coverage, say up to 80%. I do not call for striving for 100% coverage, since the time it takes to implement 100% coverage and maintain it will outweigh the benefits of this action. Then you can add one of the dynamic code analyzers to the testing process. Some types of defects found by dynamic analyzers cannot find static analyzers. And vice versa.Therefore, dynamic and static analysis perfectly complement each other. You can develop UI tests.
Such an integrated approach will have a much better effect on the quality and reliability of programs. Using several technologies, it is possible to achieve better quality than, say, 100% covering all code with tests. At the same time, 100% code coverage will be spent much more.
In fact, I think that everyone who writes that he wants more unfiltered messages from static code analyzers have never used these code analyzers. Or tried them on toy projects in which low density of errors. In any real project there is always a problem, how to deal with the existing false positives. This is a big complex task, on which both the developers of the analyzers and their users have to work. Where even more warnings ?!
We regularly receive letters from customers asking them to eliminate this or that false positive. But "give more messages" we have never heard.
Conclusion
From this article we learned:
- The PVS-Studio analyzer tries to look for not “smells”, but real errors that can lead to program malfunction.
- Diagnostic messages are divided into three confidence levels (High, Medium, Low).
- We recommend to study only the levels of High and Medium.
- For those who are worried that exceptions can remove a useful error: this is unlikely. Most likely, such an unreliable warning has been moved to the Low level. You can open the Low tab and examine such warnings.
- Exceptions in diagnostics are inevitable, otherwise the tool will begin to interfere more than help.
Thanks to everyone who took the time to read this great article. I myself did not expect it to turn out so long. This shows that the topic is more complicated than it seems at first glance.

The unicorn will continue to guard the quality of the program code. I wish everyone good luck and invite you to additionally get acquainted with the presentation of " PVS-Studio 2017 ".

If you want to share this article with an English-speaking audience, then please use the link to the translation: Andrey Karpov. The way static analyzers fight against false positives
Read the article and have a question?
. : PVS-Studio, 2015 . , .
Source: https://habr.com/ru/post/324372/
All Articles