Explain the effect of the last line
Microclones are duplicated, very small pieces of code — just a few instructions or lines. In this article, we will look at the “last line effect” - a phenomenon in which the last line or instruction in a microclone is much more likely to contain an error than previous lines or instructions. To this end, we studied 219 open source projects and 263 warnings about defective microclones, and also surveyed six authors of real applications who made such errors in their code. In our interdisciplinary work, we also study the psychological mechanisms that cause relatively trivial errors of this type. Based on the results of surveys and further technical analysis, we assume that the existence of the effect of the last line is played by so-called “sequence of actions” errors: when copying code, the attention of developers switches to other tasks due to distracting factors and the monotonous nature of this procedure. Moreover, all the microclones, whose origin we were able to establish, were found in unusually large commits. Knowledge of this effect has two useful consequences for programmers:
1) it will be easier for them to recognize situations in which the probability to make a mistake in microclones is especially great;
2) they will be able to use the automatic microclone detector / PVS-Studio, which will simplify the detection of errors of this type.
Microclones, code clones, detection of code clones, last line effect, psychology, interdisciplinary research.
')
Software developers often have to duplicate one line of code several times in a row with minor changes, as in the following example from the TrinityCore project:
Example 1
Trinitycore
The spatial coordinates of the other object are added to the fields corresponding to the x, y, z coordinates, but the last line of this fragment of three lines of the same type contains an error: the y-coordinate is added to the z-coordinate. In fact, the last line should look like this:
The following example is taken from the popular Chromium web browser and demonstrates the manifestation of the effect in question in the same type of instructions within a single line:
Example 2
Chromium
Instead of double checking the host for an empty string, the second check should be performed for port_str:
Lines 1-3 of example 1 are similar to each other, as well as the conditions of the if-operator in line 3 of example 2. We call such extremely short code blocks consisting of almost identical repeated lines or instructions microclones. Our own experience in developing and advising on software quality issues prompted us on an intuitive level that the last line or instruction in the microclone is much more likely to contain an error than the previous lines or instructions. The purpose of this work is to verify the truth of our sensations, and it is precisely this goal that are responsible for two questions posed in the framework of this study:
Since copying blocks of code when writing programs is used in most programming languages, practically every developer can be affected by the effect of the last line. If we are able to prove that the last of several consecutive instructions of the same type is more prone to error, the authors and code inspectors will know which areas should be given special attention, which will help improve the quality of the program by reducing the number of errors.
Copying and pasting is one of the natural ways of creating code like examples 1 and 2. After working to determine the origin of the code among the duplicates in the examples we selected, we came to the conclusion that developers use a number of mechanical techniques to create them, of which the most important are line-by-line copy-paste and "cloning" sections of code. These methods are one of the most common programming idioms (Kim et al. 2004), they require minimal physical and time costs, and therefore are cheap; besides, it is known that such code is efficient. Although copying small sections of code is often seen as a harmful technique (Kapser and Godfrey 2008), sometimes this is the only way to implement the desired program behavior, as in the examples discussed above. Several tools have been developed to detect and, if possible, eliminate microclones (Bellon et al. 2007; Roy et al. 2009). Despite the fact that these tools have shown impressive results down to the level of methods, they are poorly adapted to recognize microclones in practice due to too many false positives.
After we published an article about the effect of the last line in a popular science blog, it quickly and with great enthusiasm began to be quoted in other forums. Many programmers agreed with our observations and suggested that there were psychological reasons behind the effect under discussion. This is the source of our third and final question in the framework of this study:
Based on the results of surveys of developers, a thorough technical analysis of examples and cooperation with a psychologist, we will try to find out whether psychological aspects - and if so, which ones - affect the effect of the last line. Having studied the phenomena that have been observed by cognitive psychology for a long time, we will find out whether it is possible to explain with their help the effect of the last line in microclones of the code.
Based on our previous study of the effect of the last line (Beller and others. 2015), we made the following additions to it:
Our observations show that the last line or instruction in microclones, such as those presented in examples 1 and 2, are much more likely to contain an error than any of the preceding lines or instructions. It seems to us that the existence of this phenomenon is not due to the technical complexity of microclones, but to psychological causes, which, in turn, are mainly reduced to an overload of the short-term memory of programmers. A preliminary study based on five projects revealed that all microclones with errors were written in abnormally large commits during non-standard working hours. Knowledge of these features and the help of our automated static analyzer PVS-Studio can help reduce the number of trivial errors associated with the effect of the last line, by automatically detecting them.
Our work consists of two parts: empirical studies of C1 and C2. In this section, we describe the order of research and their objects.
In the C1 study, consisting of five easily reproducible stages, we conducted a statistical analysis of the prevalence of the effect of the last line in microclones. Moreover, in an attempt to shed light on the process of creating microclones, we did additional work on identifying the original sections of the code and their copies.
Having established the existence of the effect of the last line in the C1 study, we must now try to identify the reasons behind it (RQ 3). To this end, we developed an initial hypothesis based on the results of research in the field of cognitive psychology, in which Rolf Zwaan, a professor of cognitive psychology, helped us. To confirm our hypothesis, as well as to collect evidence from the practice of developers, we interviewed the programmers responsible for creating microclones found in the course of the C1 study. Their observations and observations will help us develop a preliminary version explaining the existence of the effect of the last line. Narrowing the circle of respondents exclusively to those whose authorship regarding defective microclones is precisely established allows us to: (1) focus on specific examples to which respondents are directly related; (2) to obtain the most useful answers, since we know for sure that it was these developers who were responsible for writing the microclones under discussion.
In fig. 1 shows the general outline of our study. The main task is to establish contact with the authors of microclones (in many cases the defective code is not in the latest version of the project). The plan includes four main stages:
Fig. 1 - Study Plan C2
To facilitate the replication of our work by other researchers, we have preferred well-known open source projects. Among the 219 projects studied by us in the C1 study, erroneous microclones were found in such famous projects as audio editor Audacity (1 example), web browsers Chromium (9) and Firefox (9), XML-library libxml (1), MySQL database (1) and MongoDB (1), C compiler clang (14), Quake III FPS-shooters (3) and Unreal 4 (25), Blender (4) computer graphics creation package, VTK three-dimensional modeling and visualization software ( 8), Samba (4) and OpenSSL (2) network protocols, VirtualDub (3) video editor, as well as the programming language PHP (1). For the C2 study, we selected 10 microclones from the Chromium, libjingle, Mesa 3D and LibreOffice projects.
To facilitate the work of other researchers, we have prepared a special package, which includes all the initial data and diagnostics. It includes all unfiltered PVS-Studio messages grouped in two directories: findings_old / , which contains the old data used in our article for the International Conference on Visibility of Programs (ICPC) (Beller et al. 2015), and findings_new / with more recent data used in this article. In addition, the package includes microclones analyzed by us and sorted according to projects ( analyzed_data.csv ), a spreadsheet with data evaluation ( evaluation.ods ), and the results of the analysis of repositories from studies C1 and C2. We also added scripts in the R language to reproduce the results and diagrams from this article. Finally, the package contains a questionnaire template with questions for respondents.
In this section, we will look at traditional methods for detecting duplicate code fragments, explain why they are not suitable for searching microclones, and show how we were able to get around this problem using our own diagnostics of static analysis. In addition, we will show how the original sections and copies were determined in microclones and how the dimensions of commits were taken into account.
As examples 1 and 2 show, the code fragments considered in the framework of this article either completely coincide in the text or contain “clones with the same syntactic structure, differing only in identifiers of variables, types or functions” (Koschke 2007). For this reason, they are clones of 1 or 2 types of extremely small size (usually less than 5 lines / instructions) - we call them microclones .
Traditional methods for detecting duplicate code are comparing tokens, lines of code, abstract syntax tree (ASD) nodes, or graphs (Koschke 2007). However, in practice, in any of these approaches, it is required to determine the minimum clone size in conventional units of measurement (be it tokens, instructions, lines or ASD nodes) in order to reduce the percentage of false positives. As a rule, this value is taken in the region of 5-10 units (Bellon et al. 2007; Juergens et al. 2009), which is much larger than the microclones we are considering (2-5 units) and makes it impossible to search for them.
Thus, in example 1, lines 1-3 represent a class of microclones. Since there are three rows, this class is presented in this example in triplicate. In turn, each instance consists of a variable, an assignment operation, an assignable object and its field, and thus has a length of 4 units.
Since in practice traditional search methods are unable to reliably detect microclones, we used our own approach. Our task is not to detect any microclones, but only those that contain errors. Given this additional limitation, we were able to develop a whole set of powerful diagnostics that detect microclones on the basis of the usual character-by-character match. These diagnostics are able to find defective parts of the code that most likely appeared as a result of copying small fragments. In tab. 1 lists and describes all twelve diagnostics, which allowed to detect errors in microclones in the framework of this study. The last column shows the ratio of single and multi-line clones to the total number of warnings of this type. For example, the V501 diagnostic only determines whether the operands of some logical operators are identical. If the answer is yes, then at best it’s just an extra code that can make it difficult to support the program in the future, at worst - a real mistake. Other diagnostics are not as narrowly specialized with microclones as V501. We studied each of the 526 warnings and selected only 272 cases of real microclones for our study. From tab. 1, it can also be seen that 78% of microclones were detected by a single diagnosis (V501) with a very low percentage of false positives - 3%. Other diagnostics are more likely to work on non-microclone sections of code.
Table 1 - Types of errors detected by PVS-Studio and their distribution among 219 open projects
To competently talk about the reasons for the existence of the last line effect, answering the question RQ 3, we also found in each class of microclones an original copy of the code and an instance that was supposedly copied from it. Although such an empirical analysis does not give one hundred percent certainty that the copying procedure went in that direction, we have sufficient evidence that at least some developers mechanically clone the code in this way (see RQ 3). In most cases, you can immediately determine which of the two copies of the microclone is the original, and which is the copy. Thus, in example 1, line 3, containing an error, includes traces of the code from line 2, which implies the influence of line 2 (original) on line 3 (copy). A similar natural order of the original lines and copies is observed in most microclones - be it a lexicographic order, as, for example, in the sequence of variables x, y, z in example 1, or numerical:
Example 3
Cmake
Even in cases where the natural order of the original instance and the copy is not explicitly expressed, as in Examples 1 and 3, it can be restored to the context, as in Example 2: placing port_str in the first place and host on the second in line 3 contradicts the order in which these variables were defined earlier, it means that the first host! = buzz :: STR_EMPTY is the original, and the second is a copy.
In the process of establishing the origin of a copy in the examples under consideration, we face two problems, namely: 1) the size of the copied section may vary; 2) microclones longer than 4 duplicates are represented by a smaller number of examples. In order, nevertheless, to be able to generalize the data for different sizes of microclones, for each microclone i we calculate that gives us the degree of distance
that gives us the degree of distance  .
.
The distance 1 is about copying from the immediately preceding line / instruction, as in example 4. Meaning 0: an error occurred in the same line of the microclone. A value of -1 indicates the reverse copying order: from the second Edinet to the first:
Example 4
UnrealEngine4
In this example, in line 1 it is natural to expect cx (). IsRelative instead of cy (). IsRelative , which suggests a possible copy from the second line. The logic of using variables with similar names, as well as the sequence of lines 3 and 4, indicate that the copy must begin with return cx (). IsRelative () in the first line.
From here we get the degree of distance or
or  , which indicates the immediate proximity of two duplicates either on one line or on two adjacent ones, regardless of the total size of the cloned section.
, which indicates the immediate proximity of two duplicates either on one line or on two adjacent ones, regardless of the total size of the cloned section.
To calculate and present the ratio of the sizes of each of the commits containing defective microclones to the rest of the commits, we first calculate the variability for each commit in the repository. To do this, we use the git log tool, which allows us to build ordered graphs of all commits (excluding merges) in the repository, thus revealing the number of added and the number of deleted lines of code in each commit. The sum of these numbers gives the total number of rows changed, i.e. variability for each commit. Then we compare the variability of commits containing defective microclones with the distribution of this parameter in other commits, and in particular with its median. Although our sample (ten examples) is too small for reliable statistical analysis, this approach still allows us to draw valid conclusions about the possible difference in the commit size. We use the median (and not the mean, for example), because we are dealing with the wrong distributions; the median is an independent, real value with which we compare other similar values.
In this section, we examine the defective microclones in more detail by examining examples and performing a statistical evaluation.
In tab. 2 basic statistics on the results of the study C2. During the period from mid-2011 to July 2015, we applied the full set of diagnostics of PVS-Studio on the 219 open source projects we selected. Andrei Karpov, who specializes in consulting on software development, carried out an analysis of all these projects, using the latest versions of PVS-Studio, available at the time of checking each specific project. He filtered out false positives, leaving 1,891 warnings left, indicating potential defects in the code. These warnings were grouped by 162 diagnostics. Then we studied each message and found that 272 of them were issued by twelve diagnostics and are related to microclones. In nine cases, the messages were duplicated, so as a result, 263 microclones remained. Statistical analysis at the project level shows that our diagnostics were able to recognize clones with defects in half of the selected projects. Almost all of these cases (92%) contain at least one example of the effect of the last line.
Table 2 - Statistics on the results of the study
Tab. 3 contains a summary of the errors found in 263 microclones. In total, 74% of multi-line clones contain an error in the last line and 90% of single-line clones in the last instruction.
Table 3 - Summary of the results of the study
For a more complete understanding of the principles of operation of the diagnostics that we used to detect microclones, below we will look at some of the most illustrative examples of 263 PVS-Studio warnings related to microclones and identifying the most frequent errors from the table. one.
As can be seen from the table. 1, most microclone warnings were issued by the V501 diagnostic. The following is a typical example of such an error from the Chromium browser:
Example 5
Chromium
This is a single-line microclone, in which the second and third subexpressions coincide completely, but at the same time are joined by the logical operator OR ( || ), which makes the expression redundant. , ( NAME_LAST ) — .
V517 if-.
6
linux-3.18.1
else if 9 , . , slot 0, .
(, , , , ), , . MTASA m_ucRed , m_ucBlue .
7
MTASA
V519 «» , , 8:
8
linux-3.18.10
f->fmt.vbi.samples_per_line , . , , 1 . , , (, , ) - . Release: , , .
if- , , Haiku :
9
Haiku
, , else mpa_size - . , 3 , « », .
. 10 5 PerPtrBottomUp.clear() . , .
.
10
Clang
V537, , Quake III. PVS-Studio rectf.X :
11
Quake III
(.. ) y- rectf.X .
V656 , . , . , , , , . , V656, LibreOffice.
12
LibreOffice
maSelection.Max() aSelection , .
12, . Chromium — 12 , (. . 4):
13
Chromium
2 data_[M02] , :
4 — ?? 2
. 4 158 , . 5 — 105 . . , 2 . , , .
5 —
. 4 5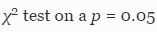 p = 0,05, , . p-, , . 2-6 . 4 2-4 . five.
p = 0,05, , . p-, , . 2-6 . 4 2-4 . five.
RQ1 RQ2, p- 2, 3, 4, 5 6 2, 3 4 (p < 0,05). , / . . , , , . . 4 5.
: « /» « /» (. . 3). , , 1, , . . 4, 2, 4 5 ( ) . , 2, : 9,5 , . 72 , .
, , /, RQ 1 RQ 2.
, , , . RQ 3 :
, .
. 6 . , . , 263 245.
6 — ( ) ( )
In fig. 2 . , 165 245 (67%) . — 18 %, (9%) (3%). 4% . , , , . , : , . 117 /, , 33 (28%). 4,9 , , 20% , . 28% , , . , , .
Fig. 2 — () ()
In fig. 2 , (. 3.3). , 84% (220 245), ..
(. 3.3). , 84% (220 245), .. 
89% (195 220)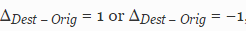 or . , . , ..
or . , . , ..  (3 220). , , , 81% (66 81). , :
(3 220). , , , 81% (66 81). , :
C2 , . . , :
. 7 , . Skype. , , , , . I1-I7 ID- . , , - . . I1, I2, I4, I6 I7 . , .
7 — 6.10.2016
, . , , , . 7b37fbb I1 , ( . 7 ), , ( 6b7fcb4 ).
I1 :
14
I1
, -, , !has_mic !has_audio . , , . , « - », , « , ». , - , , , !a && !a .
I4 , , , , :
15
I4
, field.type == trans(«string») ||, , :
16
I4
He said that "he does not count the exact number of repetitions, but he does it by eye." At the last stage of editing, the respondent deletes all unnecessary lines, but in this case he apparently forgot to do it or was distracted by something. Determining the source line in this code (see Section 3.3), we also found that it was refactored twice, but the error was not corrected. This happened because the developers relied on automatic edits and did not read the code with due care. In conclusion, I4 reported that he often uses these techniques to create microclones, "but rarely forgets to delete extra lines." Like the respondent I1, he concluded that such places should be identified by a code review or tests.
Respondent I6 responded that “a lot of time has passed since writing, but [...] this code looks like a copy and paste error, which is not uncommon”. He also said that "every now and then he encounters this technique and uses it himself." To speed up the development process and once again not to write code manually, I6 creates microclones using copy-paste, and then makes the appropriate edits to each of the copied lines. "I missed the last line." The respondent explained that he forgot to change the last duplicate in the microclone because “I began to think about less automatic tasks, and as a result, the quality of the automatic task was affected”. Although respondent I6 was unable to recall the circumstances of that day, he argues that in their company, the developers "always try to write code quickly so that program improvements appear immediately." He also said that he was confronted with microclones "constantly", at least a dozen times a day. “Of these ten cases, about nine are caught in the process of self-review of the code or using the compiler. The tenth is mostly detected by other programmers or unit tests. But sometimes, about once a month [...], errors of this kind penetrate release versions and manifest themselves among end users. ”
Respondent I7 is the author of the following microclone:
Example 17
Anonymous respondent I7
According to his recollections, he “just typed this line, without using copying and pasting,” and missed the error because, “apparently, he was in a hurry and inattentively read the code”. Although the respondent could not recall the exact date of the creation of this commit, he noted that “there is almost always a lot of work”.
From the survey results, it can be concluded that the size of commits is one of the factors due to which a defective microclone is more likely to avoid detection by various means and defense mechanisms mentioned by respondents. If this assumption is true, then the commits that carry such microclones must be abnormally large. The definition of “abnormally large” indicates a relative value and makes sense only when comparing commits within the repository. Taking this into account, we compared the sizes of commits with defective microclones with the median size of the commit for each project, which is reflected in Fig. 3. The data obtained show that in all cases the size of commits with defective microclones is several orders of magnitude higher than the median.
Fig. 3 - The median of the commit size for the entire repository history (blue dashed line) and the size (expressed by the variability on a logarithmic scale) of commits with defective microclones (orange dashed line)
Having discovered a lot of potential errors in open source projects, we wanted to help the open source development community and verify that the authors find the errors we find significant enough to correct them. To do this, we posted our comments in the project tracker bug. As a result, many of our messages were taken into account and led to an increase in the quality of the project code. So, the verification error in Example 2 (Chromium project) was fixed. Search query pvs-studio bug | issue issues reports of numerous edits in Firefox, libxml, MySQL, Clang, samba and many other projects, aided by the results of our research. As an example, we can take the case when, on October 11, 2016, at the caff670 commit, we fixed a defective microclone that had existed in the samba code since 2005.
In this section, we will combine the information we collected about error patterns and data on the psychological mechanisms underlying them. In conclusion, we consider possible factors that threaten the validity of our findings.
As a possible technical reason for the effect of the last line, one might suspect a higher technical complexity of the last line as compared to the other lines and, as a result, a greater susceptibility to errors. For example, the compiler may skip the last line when checking or fail to check it in time when the code is written in the IDE window and the last line of the microclone is also the last line in the current code editor window. However, these considerations are wrong for the following reasons:
On the other hand, including IDEs and diagnostic compilers for detecting microclones could make it easier to find errors before they get into a commit.
Another technical reason could be related to the fact that in the sequence of several instructions the last of them is more difficult to formulate than the others. However, as examples 1, 2, 5, 7 and 11 show, the opposite is true: since all duplicates are built according to one pattern, only the very first of them can be the most complex, i.e. the original, while all subsequent ones are just copies of it.
Since it is doubtful that the existence of the last line effect is due to technical reasons, it is necessary to consider the psychological mechanisms that may underlie it. For consultation, we turned to a professor of cognitive psychology (the fourth author of this article) and presented our observations to him. At this stage, our conclusions are preliminary, since a more thorough study would require a psychological experiment, where we could directly observe the process of making mistakes, which cannot be reconstructed from the results of the analysis of the origin of defective duplicates (see section 3.3) and the respondents' memories (see section 4.5).
In cognitive psychology, errors in the sequence of actions are those errors that occur when performing routine operations. This type of error has been extensively studied by experts (Anderson 1990). A typical example of such an error is when you add milk to coffee twice, instead of pouring milk once and then putting sugar. As shown by the results of analysis of the origin of microclones, developers use a whole arsenal of various mechanical methods and algorithms when copying code. One of these algorithms is: "[write original fragment], [copy original], [copy original], ..., [edit copy], [edit copy], ..." (see polls I4, I6). Along with it, an algorithm is applied: "[write original fragment], [copy original, edit copy], [copy original, edit copy], ..." In some limiting cases, in our data set, this algorithm seems to be repeated up to 34 times . Despite the fact that when writing microclones different methods are used, they all boil down to a sequence of actions with a different ratio of automatic and conscious operations. Thus, from the point of view of cognitive psychology, errors made by developers in microclones are typical errors in the sequence of actions.
Despite differences in the details, all patterns of sequence control agree that cognitive noise seems to be the main cause of errors of this kind (Botvinick and Plaut 2004; Cooper and Shallice 2006; Trafton et al. 2011). Noise in this case means any events that are not related to the current task and distract the attention of the programmer. Noise can be generated by stress caused by external causes, for example, restrictions on the timing of the task, or internal, for example, large commit. Sequence control models provide a useful theoretical framework that allows you to speculate about the possible psychological mechanisms underlying the last line effect. At this stage, we have only specific examples of microclones and information about their location in the code, but do not know the details of their occurrence. Nevertheless, as shown in section 4.4, the answers of the interviewed developers and the results of the analysis of the origin of microclones allow us to draw reasonable conclusions about how they appear. Copying and editing are basic operations performed by the programmer when writing code. Let us look again at example 1. The editing operation here consists of two smaller steps: editing the variable name and editing the value.
Example 1
Trinitycore
The error is in line 3. Apparently, this line was created by copying line 2. The first replacement was successful (the variable name was changed from y to z ), but the second step - editing the value - was skipped, which led to an error. Theoretically, this code could have been created by double-copying line 1 and then editing the duplicates received. However, the name of the variable y instead of x in line 3 gives us reason to believe that the second line was copied. As shown in section 4.4, in most microclones longer than two lines, usually the preceding line is copied. It follows that in such cases the algorithm was applied: "[copy, edit, edit], [copy, edit, edit], ..."
According to the sequence control models, errors of this type are due to cognitive noise, which is most likely to occur near the end of a series of similar operations, because the programmer's attention switches to the next task prematurely, for example, writing new code (see survey I6). As already mentioned, there are several slightly different versions explaining the causes of cognitive noise. As an example, we present a version (Cooper and Shallice 2006) explaining the effect of the last line by choosing the wrong action plan (for example, the developer has already mentally moved on to the next lines, instead of focusing on the completion of the current fragment).
Although none of the programmers interviewed complained about the excessively high level of stress while writing microclones, the testimonies of respondents I6 and I7 differ from the rest: they noted a high workload in general and a desire to move faster in writing code. Analysis of the local creation time of commits with defective microclones according to the table. 7 shows that only two of them were created during the required working hours, while the rest of the programmers worked on the code at an inopportune time, although they did it on duty. As you know, fatigue reduces the efficiency of the brain and affects the short-term memory (Kane et al. 2007). Perhaps it is fatigue and haste that play a significant role in the appearance of defective microclones.
In addition, we found that all commits (including refactoring) with defective microclones are extremely large in size, by orders of magnitude larger than the standard commit sizes in their repositories. This gives us the idea that the size of a commit is an important, if not the key factor that provokes cognitive noise, due to which errors go unnoticed. This conclusion is in good agreement with the version of short-term memory overload, as well as with the respondent I1's remark that the final code is very difficult to control due to the large volume.
Surveys show that short-lived defective microclones are a widespread phenomenon in software development, but they usually come to light at the early stages or, at least, during the code review process, conducted independently or with the help of colleagues (Beller et al. 2014). Thus, the cognitive error observed in the remaining, uncorrected microclones is not only a programming error, but also a review error (Healy 1980) and is that during the review of the code, the developer does not notice the defect in the last and other lines. In fact, our polls show that, in all likelihood, in microclones caught in commits, such an error was made twice: once when the code was reviewed by the author and at least once again when the colleague was reading. The appearance of an error in the last line is more likely than in previous ones, probably due, among other things, to the fact that it is an error in the sequence of actions. The person mentally switches to the next task (for example, writing the next part of the code), without having finished the current one (review). Another explanation suggests that the error is less noticeable due to the following instructions of the same type: the reviewer reads the last of them faster and therefore less carefully. Moreover, the visual similarity of the original copy and the copy may make it difficult to perceive individual lines. The study of code review problems shows that the similarity of fragments (manifested in the frequency of repetition of words) leads to the fact that the reviewer spends less time reading, and this negatively affects his ability to recognize errors in the text (Moravcsik and Healy 1995).
All potential factors for the manifestation of the effect of the last line are associated with an increased probability of making mistakes of this kind in situations where the programmer’s attention is reduced due to cognitive noise. The probable causes of its occurrence may, first of all, be associated with large commits, high workload, stress, distractions and fatigue (O'Malley and Gallas 1977). Conversely, our observations show that the ability of developers to control their reaction to extraneous noise (Fukuda and Vogel 2009), i.e. the ability to focus on a task greatly affects the probability of a microclone to appear with an error in the sequence of actions.
In this section, we will consider the internal and external threats to the validity of our results, and also show how we have reduced their influence to a minimum.
One of the main internal factors is to correctly determine which line contains the error. So, in example 2, any of the two instructions can be taken as a copy. However, reading and writing code usually occurs from top to bottom and from left to right (Siegmund et al. 2014). Therefore, it is natural and only correct to assume that the arrangement of errors in lines and instructions follows the same order: in Example 2, we can understand that the second instruction is a copy of the first one only after reading it, therefore we mark the second instruction as defective. Further, in many cases, as in this example, the closest context of the microclone (in example 2, the host variable is declared first and then port_str is declared) sets the natural order for the rest of the program text (check host first, then port_str in line 3) . To minimize the potential impact of researchers bias, the data were distributed for independent processing between the first two authors, and the controversial cases were discussed together. If it was not possible to agree on any result, it was discarded. In the course of the work, we also re-classified all 202 results of the earlier study (Beller et al. 2015) and found that they are almost entirely consistent with previous findings. Since the procedure for marking the defective lines in these circumstances is regulated in detail, we are sure of a high degree of mutual correspondence between the assessments of each expert, which guarantees the reproducibility of our research.
It is possible that our diagnostics do not detect all defective microclones. This factor is only a minor threat, since we do not claim to detect all errors of this type. We believe that we were able to find most of the microclones by expanding the number of diagnostics to 12 (see Table 1). This is confirmed by the fact that most of the errors were found by just a few key diagnostics: V501, V517, V519 and V537; and also the fact that van Tonder and Le Gu found more than 24,000 erroneous microclones using the abbreviated set of our diagnostics (van Tonder and Le Goues 2016).
, , . , — . , «» , (Busjahn . 2015; Siegmund . 2014). , , , , .. . , : 1) «ctrl+c, ctrl+v»? 2) ? 3) ? , , « », , WatchDog (Beller . 2015, 2015, 2016). CloneBoard, , Eclipse (de Wit . 2009).
. , . , - . , , , , , , . , , , (Adair 1984), , . , , , , .
, PVS-Studio C C++. C — (Meyerovich and Rabkin 2013), , , , C C++ . , , : , if-, (. 1, 2, 5, 7 11). , C: Java, JavaScript, C#, PHP, Ruby Python. , ?1,2 , (. . 2). , PVS-Studio, , , , , . : , .
« », (Roy . 2014). : « — , - » (Baxter . (1998)) « — [...] , » (Basit and Jarzabek (2007)). , , . , (Koschke 2007). 1 , 2 ( ). 3 , 4 (Roy . 2014). , . (Koschke 2007; Balazinska . 1999; Kapser and Godfrey 2003). : , , « », . .
. 2007 . C Java (Bellon . 2007). 25 . 2014 , (Svajlenko and Roy 2014). 50 , 15 15 (Svajlenko and Roy 2014). . , , . .
(Beller . 2015) 380 125 Java (van Tonder and Le Goues 2016) 24 304 , , . 43 , . , .
, , , 9% 17% (Zibran . 2011), 1, 2 3 (Koschke 2007). « » 5% (Roy and Cordy 2007) 50% (Rieger . 2004; Roy . 2014). , , , . , — , « ». , , , . (Chatterji . 2011; Gode and Koschke 2011; Inoue . 2012; Xie . 2013).
, .
, , . , , . . , , . IDE: .
, , , , , . .
219 , 263 . , — . . , , — , .
, , , - , . , - . , , - . , -, , .
, , , , . , , , , . , ; , - , , . PVS-Studio , , , .
ICSE'15 «Mercato Centrale», , .
The team of authors, 2016
Open access
This article is subject to the Creative Commons Attribution 4.0 International license , which permits unrestricted use, distribution and reproduction on any medium, provided that the licensee specifies the authorship and location of the original text, and also provides a link to the Creative Commons license and indicates changes, if any. were made.
1) it will be easier for them to recognize situations in which the probability to make a mistake in microclones is especially great;
2) they will be able to use the automatic microclone detector / PVS-Studio, which will simplify the detection of errors of this type.
Keywords
Microclones, code clones, detection of code clones, last line effect, psychology, interdisciplinary research.
')
1. Introduction
Software developers often have to duplicate one line of code several times in a row with minor changes, as in the following example from the TrinityCore project:
Example 1
Trinitycore

The spatial coordinates of the other object are added to the fields corresponding to the x, y, z coordinates, but the last line of this fragment of three lines of the same type contains an error: the y-coordinate is added to the z-coordinate. In fact, the last line should look like this:

The following example is taken from the popular Chromium web browser and demonstrates the manifestation of the effect in question in the same type of instructions within a single line:
Example 2
Chromium
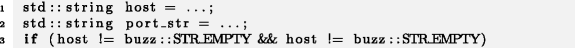
Instead of double checking the host for an empty string, the second check should be performed for port_str:
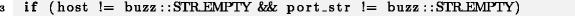
Lines 1-3 of example 1 are similar to each other, as well as the conditions of the if-operator in line 3 of example 2. We call such extremely short code blocks consisting of almost identical repeated lines or instructions microclones. Our own experience in developing and advising on software quality issues prompted us on an intuitive level that the last line or instruction in the microclone is much more likely to contain an error than the previous lines or instructions. The purpose of this work is to verify the truth of our sensations, and it is precisely this goal that are responsible for two questions posed in the framework of this study:
- RQ 1 Is it true that the last line in a multi-line multi-line is more likely to contain an error?
- RQ 2 Is it true that the last instruction in a one-line microclone is more likely to contain an error?
Since copying blocks of code when writing programs is used in most programming languages, practically every developer can be affected by the effect of the last line. If we are able to prove that the last of several consecutive instructions of the same type is more prone to error, the authors and code inspectors will know which areas should be given special attention, which will help improve the quality of the program by reducing the number of errors.
Copying and pasting is one of the natural ways of creating code like examples 1 and 2. After working to determine the origin of the code among the duplicates in the examples we selected, we came to the conclusion that developers use a number of mechanical techniques to create them, of which the most important are line-by-line copy-paste and "cloning" sections of code. These methods are one of the most common programming idioms (Kim et al. 2004), they require minimal physical and time costs, and therefore are cheap; besides, it is known that such code is efficient. Although copying small sections of code is often seen as a harmful technique (Kapser and Godfrey 2008), sometimes this is the only way to implement the desired program behavior, as in the examples discussed above. Several tools have been developed to detect and, if possible, eliminate microclones (Bellon et al. 2007; Roy et al. 2009). Despite the fact that these tools have shown impressive results down to the level of methods, they are poorly adapted to recognize microclones in practice due to too many false positives.
After we published an article about the effect of the last line in a popular science blog, it quickly and with great enthusiasm began to be quoted in other forums. Many programmers agreed with our observations and suggested that there were psychological reasons behind the effect under discussion. This is the source of our third and final question in the framework of this study:
- RQ 3 What are the reasons for the existence of defective microclones in general and the effect of the last row in particular?
Based on the results of surveys of developers, a thorough technical analysis of examples and cooperation with a psychologist, we will try to find out whether psychological aspects - and if so, which ones - affect the effect of the last line. Having studied the phenomena that have been observed by cognitive psychology for a long time, we will find out whether it is possible to explain with their help the effect of the last line in microclones of the code.
Based on our previous study of the effect of the last line (Beller and others. 2015), we made the following additions to it:
- They introduced the term "microclone" and defined it.
- Introduced the PVS-Studio diagnostic tools used by the automatic static analysis tool (Beller 2016) to detect defective microclones that cannot be detected by traditional methods.
- We studied each mistake separately in all 263 microclones selected from 219 popular open source projects based on 1,891 warning analyzers.
- Conducted a preliminary analysis of the psychological mechanisms underlying the effect of the last line.
- We surveyed six developers of real projects that made mistakes in microclones.
- We studied the repositories of four popular open source projects based on the results of surveys, which indicated a connection between errors and anomalously large commit sizes.
Our observations show that the last line or instruction in microclones, such as those presented in examples 1 and 2, are much more likely to contain an error than any of the preceding lines or instructions. It seems to us that the existence of this phenomenon is not due to the technical complexity of microclones, but to psychological causes, which, in turn, are mainly reduced to an overload of the short-term memory of programmers. A preliminary study based on five projects revealed that all microclones with errors were written in abnormally large commits during non-standard working hours. Knowledge of these features and the help of our automated static analyzer PVS-Studio can help reduce the number of trivial errors associated with the effect of the last line, by automatically detecting them.
2 Study Plan
Our work consists of two parts: empirical studies of C1 and C2. In this section, we describe the order of research and their objects.
2.1 Plan of the study C1: the prevalence and predominance of the effect of the last line in the microclones
In the C1 study, consisting of five easily reproducible stages, we conducted a statistical analysis of the prevalence of the effect of the last line in microclones. Moreover, in an attempt to shed light on the process of creating microclones, we did additional work on identifying the original sections of the code and their copies.
- Conduct a static analysis of the objects of study using the PVS-Studio tool with all included diagnostics. PVS-Studio is a commercial static analyzer developed by the Russian company OOO Program Verification Systems and includes dozens of diagnostic rules ranging from detecting cloned code blocks to anti-patterns of programming using specific C library functions. Those who want to reproduce our research can use the open access with free demo version of PVS-Studio.
- Examine the PVS-Studio report and remove false positives, as well as messages not related to microclones.
- For each defective microclone, count the total number of lines of code (RQ 1) or instructions (RQ 2) and indicate in which lines or instructions an error appears. If possible, determine the original section of the code and its copy (for example, in example 6, the original is line 2 and the copy is line 3).
- Starting the study, we default on the assumption that in a defective microclone with a length of n lines, the error probability for each line is 1 / n regardless of its number inside the fragment under consideration (null hypothesis H0). For example, lines 1 and 2 in a block of 2 lines have the same probability of an error of 0.5. However, if at stage (3) it is possible to show that the distribution of errors in the lines is significantly different from the uniform distribution with a level of significance
 , we abandon the null hypothesis and assume that errors are unevenly distributed. For each length of n lines, Pearson's consent criterion is used.
, we abandon the null hypothesis and assume that errors are unevenly distributed. For each length of n lines, Pearson's consent criterion is used. 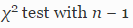 with a degree of freedom n - 1 to establish the correspondence between the observed data and the null hypothesis (distribution 1 / n).
with a degree of freedom n - 1 to establish the correspondence between the observed data and the null hypothesis (distribution 1 / n). - If in step (4) a significant discrepancy between the estimated and actual distributions is found, we calculate the odds ratio between them as an intuitive measure of the intensity of the last-line effect (Bland and Altman (2000)).
2.2 Plan C2 study: analysis of the last line effect
Having established the existence of the effect of the last line in the C1 study, we must now try to identify the reasons behind it (RQ 3). To this end, we developed an initial hypothesis based on the results of research in the field of cognitive psychology, in which Rolf Zwaan, a professor of cognitive psychology, helped us. To confirm our hypothesis, as well as to collect evidence from the practice of developers, we interviewed the programmers responsible for creating microclones found in the course of the C1 study. Their observations and observations will help us develop a preliminary version explaining the existence of the effect of the last line. Narrowing the circle of respondents exclusively to those whose authorship regarding defective microclones is precisely established allows us to: (1) focus on specific examples to which respondents are directly related; (2) to obtain the most useful answers, since we know for sure that it was these developers who were responsible for writing the microclones under discussion.
In fig. 1 shows the general outline of our study. The main task is to establish contact with the authors of microclones (in many cases the defective code is not in the latest version of the project). The plan includes four main stages:
- Projects and examples of microclones are selected at random, since the work on the C2 study is a laborious process, involving contacting the authors of the examples and conducting individual surveys. Given that the standard share of responding to “cold calls” is 30%, we can count on three successful surveys that should give us enough information to formulate an initial hypothesis explaining the existence of the effect of the last line in terms of cognitive psychology. When analyzing each of the microclones, you should familiarize yourself with the development rules adopted in this project and study the repository.
- Next, we determine the location of the microclone in the project's source tree. Since many of the errors were corrected after the publication of our earlier observations and are absent in the current thread, at this stage we are forced to apply different search strategies. First, we study the repository, dating from the day when the C1 study was conducted. In case of failure - for example, if the code adjacent to the microclone was refactored (or the change history was overwritten) - we use the search on the project's bug tracker to find the commit where the fix was made. If this step does not bring results, we resort to full-text search (using the ag tool) for all commits of the project.
- When the original microclone is detected, we trace its history with the git blame tool, in order to get information about the corrections made, as well as to establish the authorship of this code.
- Finally, we’ll find out the developer’s email address using the git blame -e command. To achieve a higher response rate, we collect additional information about respondents using Internet search: this will allow us to determine the relevance of the email address. In order to achieve the most honest answers, we guarantee the respondents that we will not disclose their personal data. Then we send each developer an e-mail with the text of the microclone of their authorship, a history of its change / correction, the context of the error, as well as an explanation of the reason for conducting the survey and attach the questionnaire.
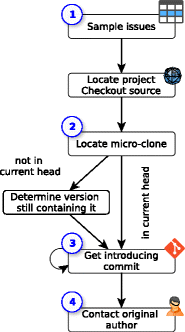
Fig. 1 - Study Plan C2
2.3 Objects of study
To facilitate the replication of our work by other researchers, we have preferred well-known open source projects. Among the 219 projects studied by us in the C1 study, erroneous microclones were found in such famous projects as audio editor Audacity (1 example), web browsers Chromium (9) and Firefox (9), XML-library libxml (1), MySQL database (1) and MongoDB (1), C compiler clang (14), Quake III FPS-shooters (3) and Unreal 4 (25), Blender (4) computer graphics creation package, VTK three-dimensional modeling and visualization software ( 8), Samba (4) and OpenSSL (2) network protocols, VirtualDub (3) video editor, as well as the programming language PHP (1). For the C2 study, we selected 10 microclones from the Chromium, libjingle, Mesa 3D and LibreOffice projects.
2.4 Notes on the reproduction of the study
To facilitate the work of other researchers, we have prepared a special package, which includes all the initial data and diagnostics. It includes all unfiltered PVS-Studio messages grouped in two directories: findings_old / , which contains the old data used in our article for the International Conference on Visibility of Programs (ICPC) (Beller et al. 2015), and findings_new / with more recent data used in this article. In addition, the package includes microclones analyzed by us and sorted according to projects ( analyzed_data.csv ), a spreadsheet with data evaluation ( evaluation.ods ), and the results of the analysis of repositories from studies C1 and C2. We also added scripts in the R language to reproduce the results and diagrams from this article. Finally, the package contains a questionnaire template with questions for respondents.
3 Methods for the detection of microclones
In this section, we will look at traditional methods for detecting duplicate code fragments, explain why they are not suitable for searching microclones, and show how we were able to get around this problem using our own diagnostics of static analysis. In addition, we will show how the original sections and copies were determined in microclones and how the dimensions of commits were taken into account.
3.1 Why modern code clone detection tools are not suitable for our task
As examples 1 and 2 show, the code fragments considered in the framework of this article either completely coincide in the text or contain “clones with the same syntactic structure, differing only in identifiers of variables, types or functions” (Koschke 2007). For this reason, they are clones of 1 or 2 types of extremely small size (usually less than 5 lines / instructions) - we call them microclones .
Traditional methods for detecting duplicate code are comparing tokens, lines of code, abstract syntax tree (ASD) nodes, or graphs (Koschke 2007). However, in practice, in any of these approaches, it is required to determine the minimum clone size in conventional units of measurement (be it tokens, instructions, lines or ASD nodes) in order to reduce the percentage of false positives. As a rule, this value is taken in the region of 5-10 units (Bellon et al. 2007; Juergens et al. 2009), which is much larger than the microclones we are considering (2-5 units) and makes it impossible to search for them.
Thus, in example 1, lines 1-3 represent a class of microclones. Since there are three rows, this class is presented in this example in triplicate. In turn, each instance consists of a variable, an assignment operation, an assignable object and its field, and thus has a length of 4 units.
3.2 Methods of detection of defective microclones used by us
Since in practice traditional search methods are unable to reliably detect microclones, we used our own approach. Our task is not to detect any microclones, but only those that contain errors. Given this additional limitation, we were able to develop a whole set of powerful diagnostics that detect microclones on the basis of the usual character-by-character match. These diagnostics are able to find defective parts of the code that most likely appeared as a result of copying small fragments. In tab. 1 lists and describes all twelve diagnostics, which allowed to detect errors in microclones in the framework of this study. The last column shows the ratio of single and multi-line clones to the total number of warnings of this type. For example, the V501 diagnostic only determines whether the operands of some logical operators are identical. If the answer is yes, then at best it’s just an extra code that can make it difficult to support the program in the future, at worst - a real mistake. Other diagnostics are not as narrowly specialized with microclones as V501. We studied each of the 526 warnings and selected only 272 cases of real microclones for our study. From tab. 1, it can also be seen that 78% of microclones were detected by a single diagnosis (V501) with a very low percentage of false positives - 3%. Other diagnostics are more likely to work on non-microclone sections of code.
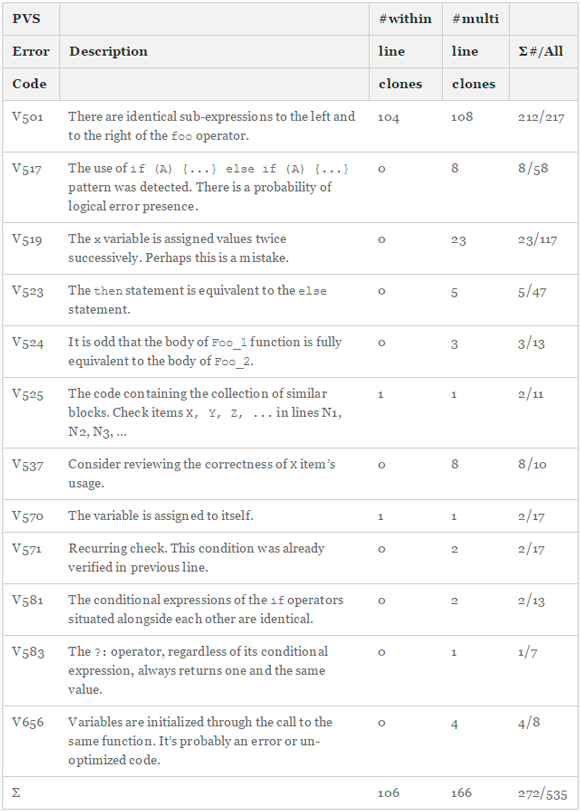
Table 1 - Types of errors detected by PVS-Studio and their distribution among 219 open projects
3.3 How the origin of the erroneous microclones was established
To competently talk about the reasons for the existence of the last line effect, answering the question RQ 3, we also found in each class of microclones an original copy of the code and an instance that was supposedly copied from it. Although such an empirical analysis does not give one hundred percent certainty that the copying procedure went in that direction, we have sufficient evidence that at least some developers mechanically clone the code in this way (see RQ 3). In most cases, you can immediately determine which of the two copies of the microclone is the original, and which is the copy. Thus, in example 1, line 3, containing an error, includes traces of the code from line 2, which implies the influence of line 2 (original) on line 3 (copy). A similar natural order of the original lines and copies is observed in most microclones - be it a lexicographic order, as, for example, in the sequence of variables x, y, z in example 1, or numerical:
Example 3
Cmake

Even in cases where the natural order of the original instance and the copy is not explicitly expressed, as in Examples 1 and 3, it can be restored to the context, as in Example 2: placing port_str in the first place and host on the second in line 3 contradicts the order in which these variables were defined earlier, it means that the first host! = buzz :: STR_EMPTY is the original, and the second is a copy.
In the process of establishing the origin of a copy in the examples under consideration, we face two problems, namely: 1) the size of the copied section may vary; 2) microclones longer than 4 duplicates are represented by a smaller number of examples. In order, nevertheless, to be able to generalize the data for different sizes of microclones, for each microclone i we calculate
that gives us the degree of distance .The distance 1 is about copying from the immediately preceding line / instruction, as in example 4. Meaning 0: an error occurred in the same line of the microclone. A value of -1 indicates the reverse copying order: from the second Edinet to the first:
Example 4
UnrealEngine4

In this example, in line 1 it is natural to expect cx (). IsRelative instead of cy (). IsRelative , which suggests a possible copy from the second line. The logic of using variables with similar names, as well as the sequence of lines 3 and 4, indicate that the copy must begin with return cx (). IsRelative () in the first line.
From here we get the degree of distance
or , which indicates the immediate proximity of two duplicates either on one line or on two adjacent ones, regardless of the total size of the cloned section.3.4 How commit sizes are taken into account
To calculate and present the ratio of the sizes of each of the commits containing defective microclones to the rest of the commits, we first calculate the variability for each commit in the repository. To do this, we use the git log tool, which allows us to build ordered graphs of all commits (excluding merges) in the repository, thus revealing the number of added and the number of deleted lines of code in each commit. The sum of these numbers gives the total number of rows changed, i.e. variability for each commit. Then we compare the variability of commits containing defective microclones with the distribution of this parameter in other commits, and in particular with its median. Although our sample (ten examples) is too small for reliable statistical analysis, this approach still allows us to draw valid conclusions about the possible difference in the commit size. We use the median (and not the mean, for example), because we are dealing with the wrong distributions; the median is an independent, real value with which we compare other similar values.
4 Results
In this section, we examine the defective microclones in more detail by examining examples and performing a statistical evaluation.
4.1 General Description of Results
In tab. 2 basic statistics on the results of the study C2. During the period from mid-2011 to July 2015, we applied the full set of diagnostics of PVS-Studio on the 219 open source projects we selected. Andrei Karpov, who specializes in consulting on software development, carried out an analysis of all these projects, using the latest versions of PVS-Studio, available at the time of checking each specific project. He filtered out false positives, leaving 1,891 warnings left, indicating potential defects in the code. These warnings were grouped by 162 diagnostics. Then we studied each message and found that 272 of them were issued by twelve diagnostics and are related to microclones. In nine cases, the messages were duplicated, so as a result, 263 microclones remained. Statistical analysis at the project level shows that our diagnostics were able to recognize clones with defects in half of the selected projects. Almost all of these cases (92%) contain at least one example of the effect of the last line.

Table 2 - Statistics on the results of the study
Tab. 3 contains a summary of the errors found in 263 microclones. In total, 74% of multi-line clones contain an error in the last line and 90% of single-line clones in the last instruction.
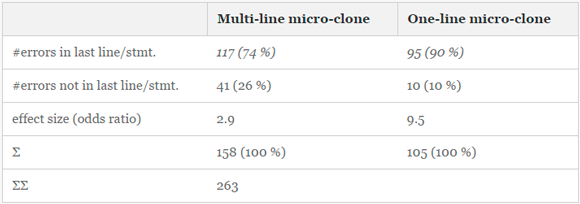
Table 3 - Summary of the results of the study
4.2 Detailed results analysis
For a more complete understanding of the principles of operation of the diagnostics that we used to detect microclones, below we will look at some of the most illustrative examples of 263 PVS-Studio warnings related to microclones and identifying the most frequent errors from the table. one.
4.2.1 V501 - Same Subexpressions
As can be seen from the table. 1, most microclone warnings were issued by the V501 diagnostic. The following is a typical example of such an error from the Chromium browser:
Example 5
Chromium

This is a single-line microclone, in which the second and third subexpressions coincide completely, but at the same time are joined by the logical operator OR ( || ), which makes the expression redundant. , ( NAME_LAST ) — .
4.2.2 V517 —
V517 if-.
6
linux-3.18.1

else if 9 , . , slot 0, .
4.2.3 V519 —
(, , , , ), , . MTASA m_ucRed , m_ucBlue .
7
MTASA

V519 «» , , 8:
8
linux-3.18.10
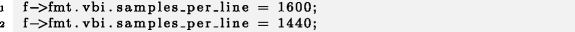
f->fmt.vbi.samples_per_line , . , , 1 . , , (, , ) - . Release: , , .
4.2.4 V523 —
if- , , Haiku :
9
Haiku
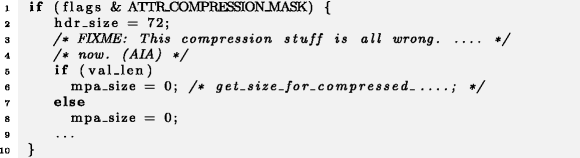
, , else mpa_size - . , 3 , « », .
4.2.5 V524 —
. 10 5 PerPtrBottomUp.clear() . ,
.10
Clang

4.2.6 V537 —
V537, , Quake III. PVS-Studio rectf.X :
11
Quake III

(.. ) y- rectf.X .
4.2.7 V656 —
V656 , . , . , , , , . , V656, LibreOffice.
12
LibreOffice

maSelection.Max() aSelection , .
4.2.8
12, . Chromium — 12 , (. . 4):
13
Chromium

2 data_[M02] , :
4 — ?? 2
4.3
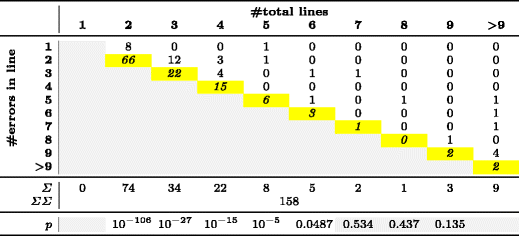
. 4 158 , . 5 — 105 . . , 2 . , , .
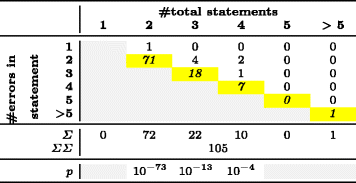
5 —
. 4 5
p = 0,05, , . p-, , . 2-6 . 4 2-4 . five.RQ1 RQ2, p- 2, 3, 4, 5 6 2, 3 4 (p < 0,05). , / . . , , , . . 4 5.
: « /» « /» (. . 3). , , 1, , . . 4, 2, 4 5 ( ) . , 2, : 9,5 , . 72 , .
, , /, RQ 1 RQ 2.
4.4
, , , . RQ 3 :
- RQ 3 ?
, .
. 6 . , . , 263 245.

6 — ( ) ( )
In fig. 2 . , 165 245 (67%) . — 18 %, (9%) (3%). 4% . , , , . , : , . 117 /, , 33 (28%). 4,9 , , 20% , . 28% , , . , , .
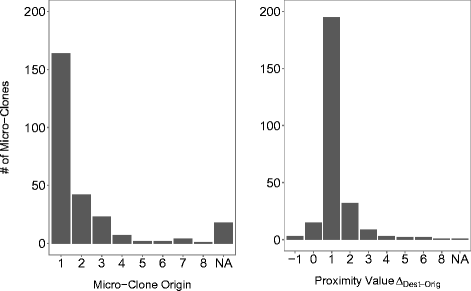
Fig. 2 — () ()
In fig. 2 ,
(. 3.3). , 84% (220 245), .. 89% (195 220)
or . , . , .. (3 220). , , , 81% (66 81). , :- . , .
- , . , .
4.5
C2 , . . , :
- (.. ).
- .
- , .
- .
. 7 , . Skype. , , , , . I1-I7 ID- . , , - . . I1, I2, I4, I6 I7 . , .
7 — 6.10.2016
, . , , , . 7b37fbb I1 , ( . 7 ), , ( 6b7fcb4 ).
I1 :
14
I1

, -, , !has_mic !has_audio . , , . , « - », , « , ». , - , , , !a && !a .
I4 , , , , :
15
I4

, field.type == trans(«string») ||, , :
16
I4

He said that "he does not count the exact number of repetitions, but he does it by eye." At the last stage of editing, the respondent deletes all unnecessary lines, but in this case he apparently forgot to do it or was distracted by something. Determining the source line in this code (see Section 3.3), we also found that it was refactored twice, but the error was not corrected. This happened because the developers relied on automatic edits and did not read the code with due care. In conclusion, I4 reported that he often uses these techniques to create microclones, "but rarely forgets to delete extra lines." Like the respondent I1, he concluded that such places should be identified by a code review or tests.
Respondent I6 responded that “a lot of time has passed since writing, but [...] this code looks like a copy and paste error, which is not uncommon”. He also said that "every now and then he encounters this technique and uses it himself." To speed up the development process and once again not to write code manually, I6 creates microclones using copy-paste, and then makes the appropriate edits to each of the copied lines. "I missed the last line." The respondent explained that he forgot to change the last duplicate in the microclone because “I began to think about less automatic tasks, and as a result, the quality of the automatic task was affected”. Although respondent I6 was unable to recall the circumstances of that day, he argues that in their company, the developers "always try to write code quickly so that program improvements appear immediately." He also said that he was confronted with microclones "constantly", at least a dozen times a day. “Of these ten cases, about nine are caught in the process of self-review of the code or using the compiler. The tenth is mostly detected by other programmers or unit tests. But sometimes, about once a month [...], errors of this kind penetrate release versions and manifest themselves among end users. ”
Respondent I7 is the author of the following microclone:
Example 17
Anonymous respondent I7
According to his recollections, he “just typed this line, without using copying and pasting,” and missed the error because, “apparently, he was in a hurry and inattentively read the code”. Although the respondent could not recall the exact date of the creation of this commit, he noted that “there is almost always a lot of work”.
From the survey results, it can be concluded that the size of commits is one of the factors due to which a defective microclone is more likely to avoid detection by various means and defense mechanisms mentioned by respondents. If this assumption is true, then the commits that carry such microclones must be abnormally large. The definition of “abnormally large” indicates a relative value and makes sense only when comparing commits within the repository. Taking this into account, we compared the sizes of commits with defective microclones with the median size of the commit for each project, which is reflected in Fig. 3. The data obtained show that in all cases the size of commits with defective microclones is several orders of magnitude higher than the median.
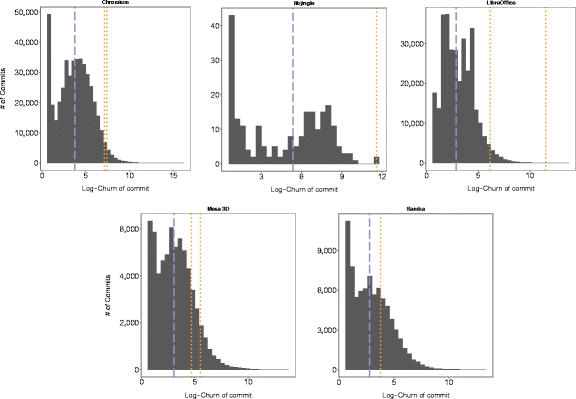
Fig. 3 - The median of the commit size for the entire repository history (blue dashed line) and the size (expressed by the variability on a logarithmic scale) of commits with defective microclones (orange dashed line)
4.6 Usefulness of results
Having discovered a lot of potential errors in open source projects, we wanted to help the open source development community and verify that the authors find the errors we find significant enough to correct them. To do this, we posted our comments in the project tracker bug. As a result, many of our messages were taken into account and led to an increase in the quality of the project code. So, the verification error in Example 2 (Chromium project) was fixed. Search query pvs-studio bug | issue issues reports of numerous edits in Firefox, libxml, MySQL, Clang, samba and many other projects, aided by the results of our research. As an example, we can take the case when, on October 11, 2016, at the caff670 commit, we fixed a defective microclone that had existed in the samba code since 2005.
5 Analysis of research results
In this section, we will combine the information we collected about error patterns and data on the psychological mechanisms underlying them. In conclusion, we consider possible factors that threaten the validity of our findings.
5.1 Technical complexity and other technical reasons for the effect of the last line
As a possible technical reason for the effect of the last line, one might suspect a higher technical complexity of the last line as compared to the other lines and, as a result, a greater susceptibility to errors. For example, the compiler may skip the last line when checking or fail to check it in time when the code is written in the IDE window and the last line of the microclone is also the last line in the current code editor window. However, these considerations are wrong for the following reasons:
- Modern IDEs, as a rule, are not subject to delays in syntax checking.
- The last line or instruction in the microclone is correct in terms of syntax, i.e. the compiler cannot issue a warning that would draw the programmer's attention to the problem.
On the other hand, including IDEs and diagnostic compilers for detecting microclones could make it easier to find errors before they get into a commit.
Another technical reason could be related to the fact that in the sequence of several instructions the last of them is more difficult to formulate than the others. However, as examples 1, 2, 5, 7 and 11 show, the opposite is true: since all duplicates are built according to one pattern, only the very first of them can be the most complex, i.e. the original, while all subsequent ones are just copies of it.
5.2 Psychological mechanisms and causes
Since it is doubtful that the existence of the last line effect is due to technical reasons, it is necessary to consider the psychological mechanisms that may underlie it. For consultation, we turned to a professor of cognitive psychology (the fourth author of this article) and presented our observations to him. At this stage, our conclusions are preliminary, since a more thorough study would require a psychological experiment, where we could directly observe the process of making mistakes, which cannot be reconstructed from the results of the analysis of the origin of defective duplicates (see section 3.3) and the respondents' memories (see section 4.5).
In cognitive psychology, errors in the sequence of actions are those errors that occur when performing routine operations. This type of error has been extensively studied by experts (Anderson 1990). A typical example of such an error is when you add milk to coffee twice, instead of pouring milk once and then putting sugar. As shown by the results of analysis of the origin of microclones, developers use a whole arsenal of various mechanical methods and algorithms when copying code. One of these algorithms is: "[write original fragment], [copy original], [copy original], ..., [edit copy], [edit copy], ..." (see polls I4, I6). Along with it, an algorithm is applied: "[write original fragment], [copy original, edit copy], [copy original, edit copy], ..." In some limiting cases, in our data set, this algorithm seems to be repeated up to 34 times . Despite the fact that when writing microclones different methods are used, they all boil down to a sequence of actions with a different ratio of automatic and conscious operations. Thus, from the point of view of cognitive psychology, errors made by developers in microclones are typical errors in the sequence of actions.
Despite differences in the details, all patterns of sequence control agree that cognitive noise seems to be the main cause of errors of this kind (Botvinick and Plaut 2004; Cooper and Shallice 2006; Trafton et al. 2011). Noise in this case means any events that are not related to the current task and distract the attention of the programmer. Noise can be generated by stress caused by external causes, for example, restrictions on the timing of the task, or internal, for example, large commit. Sequence control models provide a useful theoretical framework that allows you to speculate about the possible psychological mechanisms underlying the last line effect. At this stage, we have only specific examples of microclones and information about their location in the code, but do not know the details of their occurrence. Nevertheless, as shown in section 4.4, the answers of the interviewed developers and the results of the analysis of the origin of microclones allow us to draw reasonable conclusions about how they appear. Copying and editing are basic operations performed by the programmer when writing code. Let us look again at example 1. The editing operation here consists of two smaller steps: editing the variable name and editing the value.
Example 1
Trinitycore
The error is in line 3. Apparently, this line was created by copying line 2. The first replacement was successful (the variable name was changed from y to z ), but the second step - editing the value - was skipped, which led to an error. Theoretically, this code could have been created by double-copying line 1 and then editing the duplicates received. However, the name of the variable y instead of x in line 3 gives us reason to believe that the second line was copied. As shown in section 4.4, in most microclones longer than two lines, usually the preceding line is copied. It follows that in such cases the algorithm was applied: "[copy, edit, edit], [copy, edit, edit], ..."
According to the sequence control models, errors of this type are due to cognitive noise, which is most likely to occur near the end of a series of similar operations, because the programmer's attention switches to the next task prematurely, for example, writing new code (see survey I6). As already mentioned, there are several slightly different versions explaining the causes of cognitive noise. As an example, we present a version (Cooper and Shallice 2006) explaining the effect of the last line by choosing the wrong action plan (for example, the developer has already mentally moved on to the next lines, instead of focusing on the completion of the current fragment).
Although none of the programmers interviewed complained about the excessively high level of stress while writing microclones, the testimonies of respondents I6 and I7 differ from the rest: they noted a high workload in general and a desire to move faster in writing code. Analysis of the local creation time of commits with defective microclones according to the table. 7 shows that only two of them were created during the required working hours, while the rest of the programmers worked on the code at an inopportune time, although they did it on duty. As you know, fatigue reduces the efficiency of the brain and affects the short-term memory (Kane et al. 2007). Perhaps it is fatigue and haste that play a significant role in the appearance of defective microclones.
In addition, we found that all commits (including refactoring) with defective microclones are extremely large in size, by orders of magnitude larger than the standard commit sizes in their repositories. This gives us the idea that the size of a commit is an important, if not the key factor that provokes cognitive noise, due to which errors go unnoticed. This conclusion is in good agreement with the version of short-term memory overload, as well as with the respondent I1's remark that the final code is very difficult to control due to the large volume.
Surveys show that short-lived defective microclones are a widespread phenomenon in software development, but they usually come to light at the early stages or, at least, during the code review process, conducted independently or with the help of colleagues (Beller et al. 2014). Thus, the cognitive error observed in the remaining, uncorrected microclones is not only a programming error, but also a review error (Healy 1980) and is that during the review of the code, the developer does not notice the defect in the last and other lines. In fact, our polls show that, in all likelihood, in microclones caught in commits, such an error was made twice: once when the code was reviewed by the author and at least once again when the colleague was reading. The appearance of an error in the last line is more likely than in previous ones, probably due, among other things, to the fact that it is an error in the sequence of actions. The person mentally switches to the next task (for example, writing the next part of the code), without having finished the current one (review). Another explanation suggests that the error is less noticeable due to the following instructions of the same type: the reviewer reads the last of them faster and therefore less carefully. Moreover, the visual similarity of the original copy and the copy may make it difficult to perceive individual lines. The study of code review problems shows that the similarity of fragments (manifested in the frequency of repetition of words) leads to the fact that the reviewer spends less time reading, and this negatively affects his ability to recognize errors in the text (Moravcsik and Healy 1995).
All potential factors for the manifestation of the effect of the last line are associated with an increased probability of making mistakes of this kind in situations where the programmer’s attention is reduced due to cognitive noise. The probable causes of its occurrence may, first of all, be associated with large commits, high workload, stress, distractions and fatigue (O'Malley and Gallas 1977). Conversely, our observations show that the ability of developers to control their reaction to extraneous noise (Fukuda and Vogel 2009), i.e. the ability to focus on a task greatly affects the probability of a microclone to appear with an error in the sequence of actions.
5.3 Factors threatening the validity of the research results
In this section, we will consider the internal and external threats to the validity of our results, and also show how we have reduced their influence to a minimum.
5.3.1 Internal factors
One of the main internal factors is to correctly determine which line contains the error. So, in example 2, any of the two instructions can be taken as a copy. However, reading and writing code usually occurs from top to bottom and from left to right (Siegmund et al. 2014). Therefore, it is natural and only correct to assume that the arrangement of errors in lines and instructions follows the same order: in Example 2, we can understand that the second instruction is a copy of the first one only after reading it, therefore we mark the second instruction as defective. Further, in many cases, as in this example, the closest context of the microclone (in example 2, the host variable is declared first and then port_str is declared) sets the natural order for the rest of the program text (check host first, then port_str in line 3) . To minimize the potential impact of researchers bias, the data were distributed for independent processing between the first two authors, and the controversial cases were discussed together. If it was not possible to agree on any result, it was discarded. In the course of the work, we also re-classified all 202 results of the earlier study (Beller et al. 2015) and found that they are almost entirely consistent with previous findings. Since the procedure for marking the defective lines in these circumstances is regulated in detail, we are sure of a high degree of mutual correspondence between the assessments of each expert, which guarantees the reproducibility of our research.
It is possible that our diagnostics do not detect all defective microclones. This factor is only a minor threat, since we do not claim to detect all errors of this type. We believe that we were able to find most of the microclones by expanding the number of diagnostics to 12 (see Table 1). This is confirmed by the fact that most of the errors were found by just a few key diagnostics: V501, V517, V519 and V537; and also the fact that van Tonder and Le Gu found more than 24,000 erroneous microclones using the abbreviated set of our diagnostics (van Tonder and Le Goues 2016).
, , . , — . , «» , (Busjahn . 2015; Siegmund . 2014). , , , , .. . , : 1) «ctrl+c, ctrl+v»? 2) ? 3) ? , , « », , WatchDog (Beller . 2015, 2015, 2016). CloneBoard, , Eclipse (de Wit . 2009).
. , . , - . , , , , , , . , , , (Adair 1984), , . , , , , .
5.3.2
, PVS-Studio C C++. C — (Meyerovich and Rabkin 2013), , , , C C++ . , , : , if-, (. 1, 2, 5, 7 11). , C: Java, JavaScript, C#, PHP, Ruby Python. , ?1,2 , (. . 2). , PVS-Studio, , , , , . : , .
6
« », (Roy . 2014). : « — , - » (Baxter . (1998)) « — [...] , » (Basit and Jarzabek (2007)). , , . , (Koschke 2007). 1 , 2 ( ). 3 , 4 (Roy . 2014). , . (Koschke 2007; Balazinska . 1999; Kapser and Godfrey 2003). : , , « », . .
. 2007 . C Java (Bellon . 2007). 25 . 2014 , (Svajlenko and Roy 2014). 50 , 15 15 (Svajlenko and Roy 2014). . , , . .
(Beller . 2015) 380 125 Java (van Tonder and Le Goues 2016) 24 304 , , . 43 , . , .
, , , 9% 17% (Zibran . 2011), 1, 2 3 (Koschke 2007). « » 5% (Roy and Cordy 2007) 50% (Rieger . 2004; Roy . 2014). , , , . , — , « ». , , , . (Chatterji . 2011; Gode and Koschke 2011; Inoue . 2012; Xie . 2013).
7
, .
, , . , , . . , , . IDE: .
, , , , , . .
219 , 263 . , — . . , , — , .
, , , - , . , - . , , - . , -, , .
, , , , . , , , , . , ; , - , , . PVS-Studio , , , .
Notes
- TrinityCore — - (MMOG), www . trinitycore . org .
- Chromium — Google Chrome, www.chromium.org .
- http://www.viva64.com/ru/b/0260
- www.reddit.com/r/programming/comments/270orx/the_last_line_effect
- http://www.viva64.com/ru/pvs-studio-download
- 10.6084/m9.figshare.1313697
- . , .
- : http://viva64.com/ru/d/0368/ .
- https :// codereview . chromium . org /7031055
- www . google . com / search ? q = pvs - studio + bug +|+ issue
- https :// bugzilla . samba . org / show _ bug . cgi ? id =12373
- Clang . : https :// llvm . org / bugs / show _ bug . cgi ? id =9952 .
Thanks
ICSE'15 «Mercato Centrale», , .
Bibliography
Adair JG (1984) Reconsideration of the methodological artifact. J Appl Psychol 69 (2): 334-345 CrossRef Google Scholar
Anderson JR (1990) Cognitive psychology and its implications. WH Freeman / Times Books / Henry Holt & Co
Balazinska M, Merlo E, Dagenais M, Lague B, Kontogiannis K (1999) Measuring clone based reengineering opportunities. In: Proceedings of the international software metrics symposium (METRICS). IEEE, pp 292-303
Basit HA, Jarzabek S (2007) Efficient token based clone detection with flexible tokenization. In: Proceedings of the 6th joint meeting of the European Conference and the European Conference of the Commonwealth of Independent States on the foundations of software engineering (ESEC / FSE). ACM, pp 513-516
Baxter ID, Yahin A, de Moura LM, Sant'Anna M, Bier L (1998) Clone detection using abstract syntax trees. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 368-377
Beller M, Bacchelli A, Zaidman A, Juergens E (2014) Modern projects in open-source projects: Which problems do they fix? In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 202-211
Beller M, Bholanath R, McIntosh S, Zaidman A (2016) Analyze a large-scale evaluation of open source software. In: Proceedings of the 23rd IEEE international conference on software analysis, evolution, and reengineering. IEEE, pp 470-481
Beller M, Gousios G, Panichella A, Zaidman A (2015) (ID). In: Proceedings of the 10th joint meeting of the ACM SIGSOFT software on the foundations of software engineering (ESEC / FSE). ACM
Beller M, Gousios G, Zaidman A (2015) How (much) do developers test? In: 37th International conference on software engineering (ICSE). ACM, pp 559-562
Beller M, Levaja I, Panichella A, Gousios G, Zaidman A (2016) How to catch 'em all: watchdog In: 3rd International workshop on software engineering (SER & IP 2016). IEEE, pp. 53-56
Beller M, Zaidman A, Karpov A (2015) The last line effect. In: 23rd International conference on program comprehension (ICPC). ACM, pp 240-243
Bellon S, Koschke R, Antoniol G, Krinke J, Merlo E (2007) Comparison and Evaluation of Clone Detection Tools. IEEE Trans Softw Eng 33 (9): 577-591 CrossRef Google Scholar
Bland JM, Altman DG (2000) The odds ratio. Bmj 320 (7247): 1468 CrossRef Google Scholar
Botvinick M, Plaut DC (2004) Doing without schema hierarchies: a recurrent connectionist approach 111: 395-429
Busjahn T, Bednarik R, Begel A, Crosby M, Paterson JH, Schulte C, Sharif B, Tamm S (2015) Eye movements. In: Proceedings of International Conference on Program Comprehension (ICPC). ACM, pp 255-265
Chatterji D, Carver JC, Massengil B, Oslin J, Kraft N, et al. (2011). In: Proceedings of the international symposium on empirical software engineering and measurement (ESEM). IEEE, pp 20-29
Cooper R, Shallice T (2006) Hierarchical schemas and vol 113
de Wit M, Zaidman A, van Deursen A (2009) Managing code clones using dynamic change tracking and resolution. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 169-178
Fukuda K, Vogel EK (2009) Human variation in overriding attentional capture. J Neurosci 29 (27): 8726-8733 CrossRef Google Scholar
Gode N, Koschke R (2011) Frequency and clones. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 311-320
Healy AF (1980) Proofreading errors. J Exper Psychol Human Percep Perform 6 (1): 45 CrossRef Google Scholar
Inoue K, Higo Y, Yoshida N, Choi E, Kusumoto S, Kim K, Park W, Lee E (2012) Experience of finding inconsistently bugs in mobile phone software. In: Proceedings of the international workshop on software clones (IWSC). IEEE, pp 94-95
Juergens E, Deissenboeck F, Hummel B, Wagner S (2009) Do code clones matter? In: Proceedings of the international conference on software engineering (ICSE). IEEE, pp 485-495
Kane MJ, Brown LH, McVay JC, Silvia PJ, Myin-Germeys I, Kwapil TR (2007). Psychol Sci 18 (7): 614-621 CrossRef Google Scholar
Kapser C, Godfrey M (2003) A taxonomy of the clones in the most wanted list. In: 2nd International workshop on detection of software clones (IWDSC-03), vol 13
Kapser CJ, Godfrey MW (2008) Cloning considered harmful-patterns in software. Emp Softw Eng 13 (6): 645-692 CrossRef Google Scholar
Kim M, Bergman L, Lau T, Notkin D (2004) An ethnographic study of paste and paste programming practices in oopl. In: Proc. International symposium on empirical software engineering (ISESE). IEEE, pp 83-92
Koschke R (2007) Survey of research on software clones. In: Koschke R, Merlo E, Walenstein A (eds) Duplication, redundancy, and similarity in software, no. 06301 in Dagstuhl seminar meetings. Internationales Begegnungs- und Forschungszentrum fur Informatik (IBFI). https://web.archive.org/web/20161024110147/http://drops.dagstuhl.de/opus/volltexte/2007/962/ . Schloss Dagstuhl, Dagstuhl
Meyerovich L, Rabkin A (2013) Empirical analysis of programming language adoption. In: ACM SIGPLAN notices, vol 48. ACM, pp 1-18
Moravcsik JE, Healy AF (1995) Effect of meaning on letter detection. J Exper Psychol Learn Memory Cogn 21 (1): 82 CrossRef Google Scholar
O'Malley JJ, Gallas J (1977) Noise and attention span. Percep Motor Skills 44 (3): 919-922 CrossRef Google Scholar
Rieger M, Ducasse S, Lanza M (2004) Insights into system-wide code duplication. In: Proceedings of the conference on reverse engineering (WCRE). IEEE, pp 100-109
Roy C, Cordy J, Koschke R (2009): A qualitative approach. Sci Comput Program 74 (7): 470-495 MathSciNet CrossRef MATH Google Scholar
Roy CK, Cordy JR (2007) A survey on software clone detection research. Tech. Rep. TR 2007-541. Queens university
Roy CK, Zibran MF, Koschke R (2014) The clone management: past, present, and future (keynote paper). In: 2014 Software evolution week - IEEE conference on software maintenance, reengineering, and reverse engineering, (CSMR-WCRE). IEEE, pp 18-33
Siegmund J, Kastner C, Apel S, Parnin C, Bethmann A, Leich T, Saake G, Brechmann A (2014). In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 378-389
Svajlenko J, Roy CK (2014) Evaluating modern clone detection tools. In: The 30th IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, pp 321-330
van Tonder R, Le Goues C (2016) Defending against the micro clones. In: 2016 IEEE 24th International Conference on Program Comprehension (ICPC). IEEE, pp 1-4
Trafton JG, Altmann EM, Ratwani RM (2011) A memory for goals model of sequence errors. Cogn Syst Res 12: 134-143 CrossRef Google Scholar
Xie S, Khomh F, Zou Y (2013). In: Proceedings of the 10th working conference on mining software repositories (MSR). IEEE
Zibran MF, Saha RK, Asaduzzaman M, Roy CK (2011) Analyzing and forecasting software: an empirical study. In: Proceedings of ICCCS. IEEE, pp 295-304
Anderson JR (1990) Cognitive psychology and its implications. WH Freeman / Times Books / Henry Holt & Co
Balazinska M, Merlo E, Dagenais M, Lague B, Kontogiannis K (1999) Measuring clone based reengineering opportunities. In: Proceedings of the international software metrics symposium (METRICS). IEEE, pp 292-303
Basit HA, Jarzabek S (2007) Efficient token based clone detection with flexible tokenization. In: Proceedings of the 6th joint meeting of the European Conference and the European Conference of the Commonwealth of Independent States on the foundations of software engineering (ESEC / FSE). ACM, pp 513-516
Baxter ID, Yahin A, de Moura LM, Sant'Anna M, Bier L (1998) Clone detection using abstract syntax trees. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 368-377
Beller M, Bacchelli A, Zaidman A, Juergens E (2014) Modern projects in open-source projects: Which problems do they fix? In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 202-211
Beller M, Bholanath R, McIntosh S, Zaidman A (2016) Analyze a large-scale evaluation of open source software. In: Proceedings of the 23rd IEEE international conference on software analysis, evolution, and reengineering. IEEE, pp 470-481
Beller M, Gousios G, Panichella A, Zaidman A (2015) (ID). In: Proceedings of the 10th joint meeting of the ACM SIGSOFT software on the foundations of software engineering (ESEC / FSE). ACM
Beller M, Gousios G, Zaidman A (2015) How (much) do developers test? In: 37th International conference on software engineering (ICSE). ACM, pp 559-562
Beller M, Levaja I, Panichella A, Gousios G, Zaidman A (2016) How to catch 'em all: watchdog In: 3rd International workshop on software engineering (SER & IP 2016). IEEE, pp. 53-56
Beller M, Zaidman A, Karpov A (2015) The last line effect. In: 23rd International conference on program comprehension (ICPC). ACM, pp 240-243
Bellon S, Koschke R, Antoniol G, Krinke J, Merlo E (2007) Comparison and Evaluation of Clone Detection Tools. IEEE Trans Softw Eng 33 (9): 577-591 CrossRef Google Scholar
Bland JM, Altman DG (2000) The odds ratio. Bmj 320 (7247): 1468 CrossRef Google Scholar
Botvinick M, Plaut DC (2004) Doing without schema hierarchies: a recurrent connectionist approach 111: 395-429
Busjahn T, Bednarik R, Begel A, Crosby M, Paterson JH, Schulte C, Sharif B, Tamm S (2015) Eye movements. In: Proceedings of International Conference on Program Comprehension (ICPC). ACM, pp 255-265
Chatterji D, Carver JC, Massengil B, Oslin J, Kraft N, et al. (2011). In: Proceedings of the international symposium on empirical software engineering and measurement (ESEM). IEEE, pp 20-29
Cooper R, Shallice T (2006) Hierarchical schemas and vol 113
de Wit M, Zaidman A, van Deursen A (2009) Managing code clones using dynamic change tracking and resolution. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 169-178
Fukuda K, Vogel EK (2009) Human variation in overriding attentional capture. J Neurosci 29 (27): 8726-8733 CrossRef Google Scholar
Gode N, Koschke R (2011) Frequency and clones. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 311-320
Healy AF (1980) Proofreading errors. J Exper Psychol Human Percep Perform 6 (1): 45 CrossRef Google Scholar
Inoue K, Higo Y, Yoshida N, Choi E, Kusumoto S, Kim K, Park W, Lee E (2012) Experience of finding inconsistently bugs in mobile phone software. In: Proceedings of the international workshop on software clones (IWSC). IEEE, pp 94-95
Juergens E, Deissenboeck F, Hummel B, Wagner S (2009) Do code clones matter? In: Proceedings of the international conference on software engineering (ICSE). IEEE, pp 485-495
Kane MJ, Brown LH, McVay JC, Silvia PJ, Myin-Germeys I, Kwapil TR (2007). Psychol Sci 18 (7): 614-621 CrossRef Google Scholar
Kapser C, Godfrey M (2003) A taxonomy of the clones in the most wanted list. In: 2nd International workshop on detection of software clones (IWDSC-03), vol 13
Kapser CJ, Godfrey MW (2008) Cloning considered harmful-patterns in software. Emp Softw Eng 13 (6): 645-692 CrossRef Google Scholar
Kim M, Bergman L, Lau T, Notkin D (2004) An ethnographic study of paste and paste programming practices in oopl. In: Proc. International symposium on empirical software engineering (ISESE). IEEE, pp 83-92
Koschke R (2007) Survey of research on software clones. In: Koschke R, Merlo E, Walenstein A (eds) Duplication, redundancy, and similarity in software, no. 06301 in Dagstuhl seminar meetings. Internationales Begegnungs- und Forschungszentrum fur Informatik (IBFI). https://web.archive.org/web/20161024110147/http://drops.dagstuhl.de/opus/volltexte/2007/962/ . Schloss Dagstuhl, Dagstuhl
Meyerovich L, Rabkin A (2013) Empirical analysis of programming language adoption. In: ACM SIGPLAN notices, vol 48. ACM, pp 1-18
Moravcsik JE, Healy AF (1995) Effect of meaning on letter detection. J Exper Psychol Learn Memory Cogn 21 (1): 82 CrossRef Google Scholar
O'Malley JJ, Gallas J (1977) Noise and attention span. Percep Motor Skills 44 (3): 919-922 CrossRef Google Scholar
Rieger M, Ducasse S, Lanza M (2004) Insights into system-wide code duplication. In: Proceedings of the conference on reverse engineering (WCRE). IEEE, pp 100-109
Roy C, Cordy J, Koschke R (2009): A qualitative approach. Sci Comput Program 74 (7): 470-495 MathSciNet CrossRef MATH Google Scholar
Roy CK, Cordy JR (2007) A survey on software clone detection research. Tech. Rep. TR 2007-541. Queens university
Roy CK, Zibran MF, Koschke R (2014) The clone management: past, present, and future (keynote paper). In: 2014 Software evolution week - IEEE conference on software maintenance, reengineering, and reverse engineering, (CSMR-WCRE). IEEE, pp 18-33
Siegmund J, Kastner C, Apel S, Parnin C, Bethmann A, Leich T, Saake G, Brechmann A (2014). In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 378-389
Svajlenko J, Roy CK (2014) Evaluating modern clone detection tools. In: The 30th IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, pp 321-330
van Tonder R, Le Goues C (2016) Defending against the micro clones. In: 2016 IEEE 24th International Conference on Program Comprehension (ICPC). IEEE, pp 1-4
Trafton JG, Altmann EM, Ratwani RM (2011) A memory for goals model of sequence errors. Cogn Syst Res 12: 134-143 CrossRef Google Scholar
Xie S, Khomh F, Zou Y (2013). In: Proceedings of the 10th working conference on mining software repositories (MSR). IEEE
Zibran MF, Saha RK, Asaduzzaman M, Roy CK (2011) Analyzing and forecasting software: an empirical study. In: Proceedings of ICCCS. IEEE, pp 295-304
Copyright
The team of authors, 2016
Open access
This article is subject to the Creative Commons Attribution 4.0 International license , which permits unrestricted use, distribution and reproduction on any medium, provided that the licensee specifies the authorship and location of the original text, and also provides a link to the Creative Commons license and indicates changes, if any. were made.
Source: https://habr.com/ru/post/323914/
All Articles