Banal AB-test
On the Internet, someone is wrong
I accidentally found out that there is a misunderstanding of what an AB test is and how to conduct it. Therefore, a small article with basic principles and examples of how to do it may not be useful. The tips are designed for the reader who is just starting acquaintance with the AB-tests and a project with a small audience. If you have a large audience, then you already know how to conduct tests.
My experience in conducting AB tests is related to mobile applications, so some specifics can break through despite the intention to write only about basic things.
Definition
AB-test is a way to understand whether your product has become better when you change its part. Let's say you have a hypothesis that some kind of change will increase the key metric of the product by more than 10%. You take new users and give one half of the control version of the product, and the other with the realized hypothesis. Wait until the difference between the metric values becomes statistically significant, that is, it does not change if the test is continued with a probability of 90–95%. As soon as the results are reliable, we leave the winner and run the next test.
Why is it even needed?
“I know that my idea will make the product better.” Well, at least not worse. Well, in extreme cases, it will be used by those who really need it, but for the rest the product will remain the same!
So tells us our inner voice. Well, or at least told me. And sometimes he is right. And sometimes not.
- Let's release the change and see if the metrics will grow!
Let's grow up. But they could grow because of the correction of the crash in the same update, and not because of the innovation. This evaluation error is called “false positive”. Or metrics could not change, or even fall, and though change actually increased. It was just a parallel advertisement that led not only to the target, but also to many untargeted audiences, who quickly left without being interested in the product. This is an "false negative" error.
The cause of the error can be a large number of factors. And what is most frightening is the unpredictability of their appearance and the power of influence is not the result. Learning to predict and evaluate distorting factors is not possible. So the release of changes under the motto “I'm lucky!” Most likely will not lead to a steady increase in product metrics.
We need AB-tests in order to ensure the testable growth of product metrics, which is caused precisely by an improvement in the product, and not by external factors or a temporary change in the audience.
When to stop the test
If after two weeks the value of the test variation is greater than the value of the control, then this does not mean anything. We need to obtain reliable results, that is, results that are not likely to change with continued measurements. This can be done using a calculator :
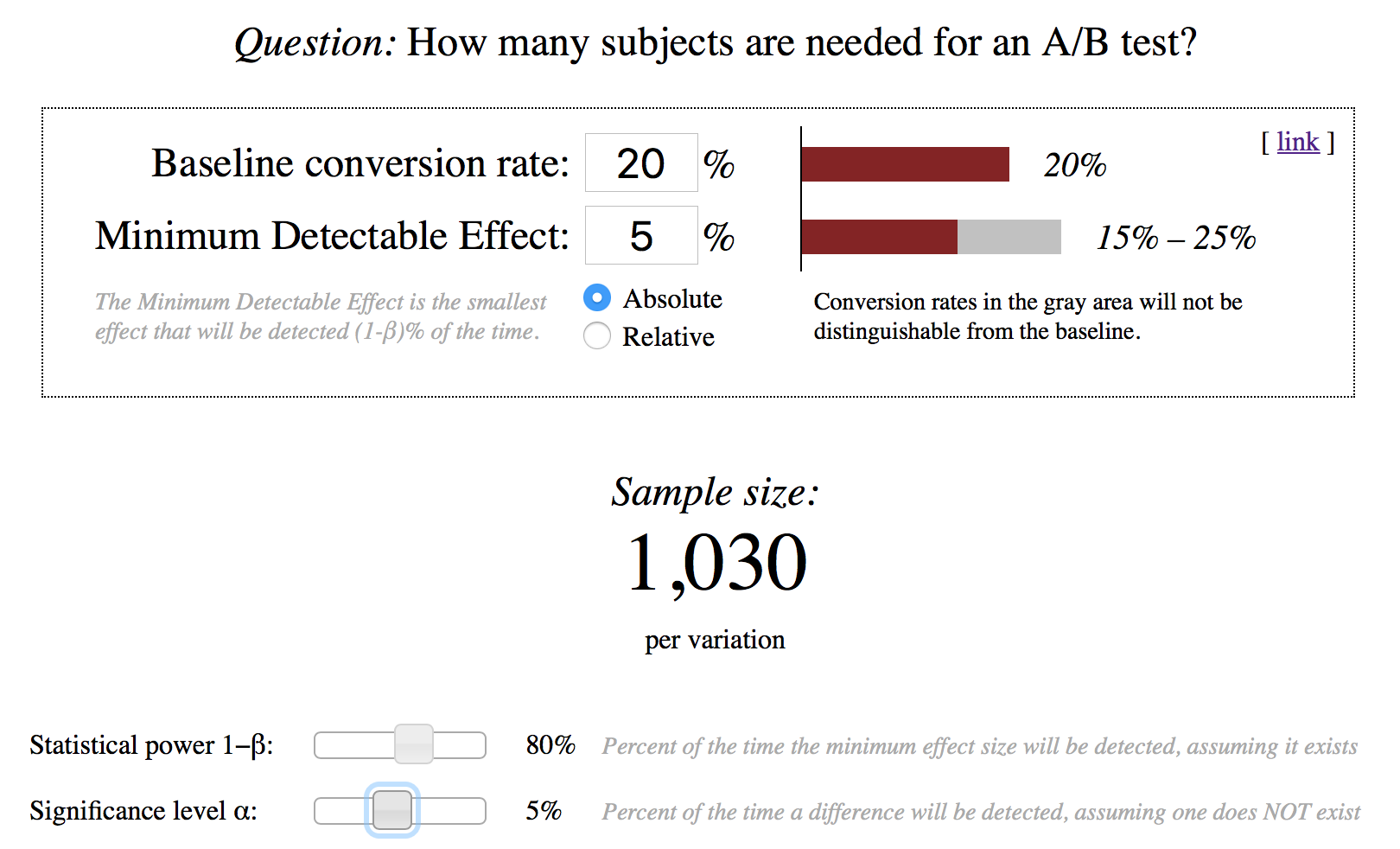
We enter data on the conversion in the baseline and test variations, and we get the sample size for each variation, which will allow us to say that the variations are statistically significantly different. The error probability is false negative 20%, the error is false positive 5%.
If the test took a sufficient number of participants and the test variation was significantly better than the control one, then the test can be considered complete, and the change is successful.
AB – color test buttons
This is an example that is commonly used to explain what an AB test is. This example is good for explanation, but in practice it usually does not give a meaningful increase in the metric. Because your product is more than a button. Unless, of course, your entire product being tested is a banner.
Like any other instrument, the AB – test can be used incorrectly, so the project’s metrics will not grow, and their efforts will be spent. Put an additional condition for the tests: the change should increase the important metric of the product by 15%. If the experiment scored enough sample to determine the difference of 15%, but the test result is lower than necessary, then go back to the control variation and look for a more daring hypothesis. So you can quickly check for really important changes, which is important at the initial stage of product development.
And finally a couple of tips:
- make as few variations as possible, this will reduce the time of the test;
- At first, try not to check conversions that are less than 10% - it will take a long time. Usually such metrics belong to such important as conversion to a paying user. For her, test the hypothesis if you are confident that it will bring a significant improvement.
Afterword
AB-test is a very useful tool that helps us not only when the hypothesis was confirmed. The beauty of the method is that even a non-positive result gives us new information about the product. Why did we think that this change would work, but it did not work? Perhaps our ideas about what users need are not entirely correct? Finding answers may lead you to new hypotheses and some of them will work.
')
Source: https://habr.com/ru/post/323836/
All Articles