CrateDB: outside as PostgreSQL, and inside Elasticsearch
About one year has passed since my last publication about distributed database CrateDB. The project is based on Elasticsearch and PrestoDB written in Java. During this time, it has been actively developing and acquiring new functionality in the github repository:

A pleasant surprise was to find in the github project that the CrateDB team has a Russian-speaking developer Ruslan . I quickly received a response from him to questions about the internal structure and dependencies of the project.
When last time on Habré I talked about the peculiarities of working with queries in the article "JOIN the dark side of the SQL" , I mentioned the shortcomings of the native jdbc driver for crate and incomplete support for join operations. These defects have been eliminated in recent versions (> 1.0)!
Now you can use the PostgreSQL jdbc driver, the pg command line utilities, and you do not need to pack a separate crate driver with the application. This was made possible by partially emulating wire PostgreSQL 9.5 protocol on the server. With an eye to the fact that transactions are not supported (therefore autocommit is set), authentication with any login / password is successful, SSL is not supported for connections and only UTF-8 character encoding is supported. The COPY subprotocol pg and stored functions call subprotocol is not yet supported. It should be remembered that the syntax of SQL queries and a subset of supported functions are specific to CrateDB.
')
Finally, the server has support for Left, Right and Full Outer Join . Although the special scheduler optimizations are not applied and the join is implemented as a nested loop, but the filters are applied distributed - on each shard of the tables from the query.
There was a strange syntax in SELECT, resembling PL / SQL CASE:
With subqueries in FROM until the miracle happened. Either sub-requests with aggregates are supported , or requests that the parser can easily rewrite. I hope that in a year the project will be surprised by the fact that complex subqueries will be available.
The functions distance, within, intersects, latitude / longitude are available for working with spatial data in queries. Work with geodata has long been in Elasticsearch , on the basis of which this distributed database was created.
There is a data access plugin for Grafana . You can draw graphs for monitoring data and telemetry stored in CrateDB.
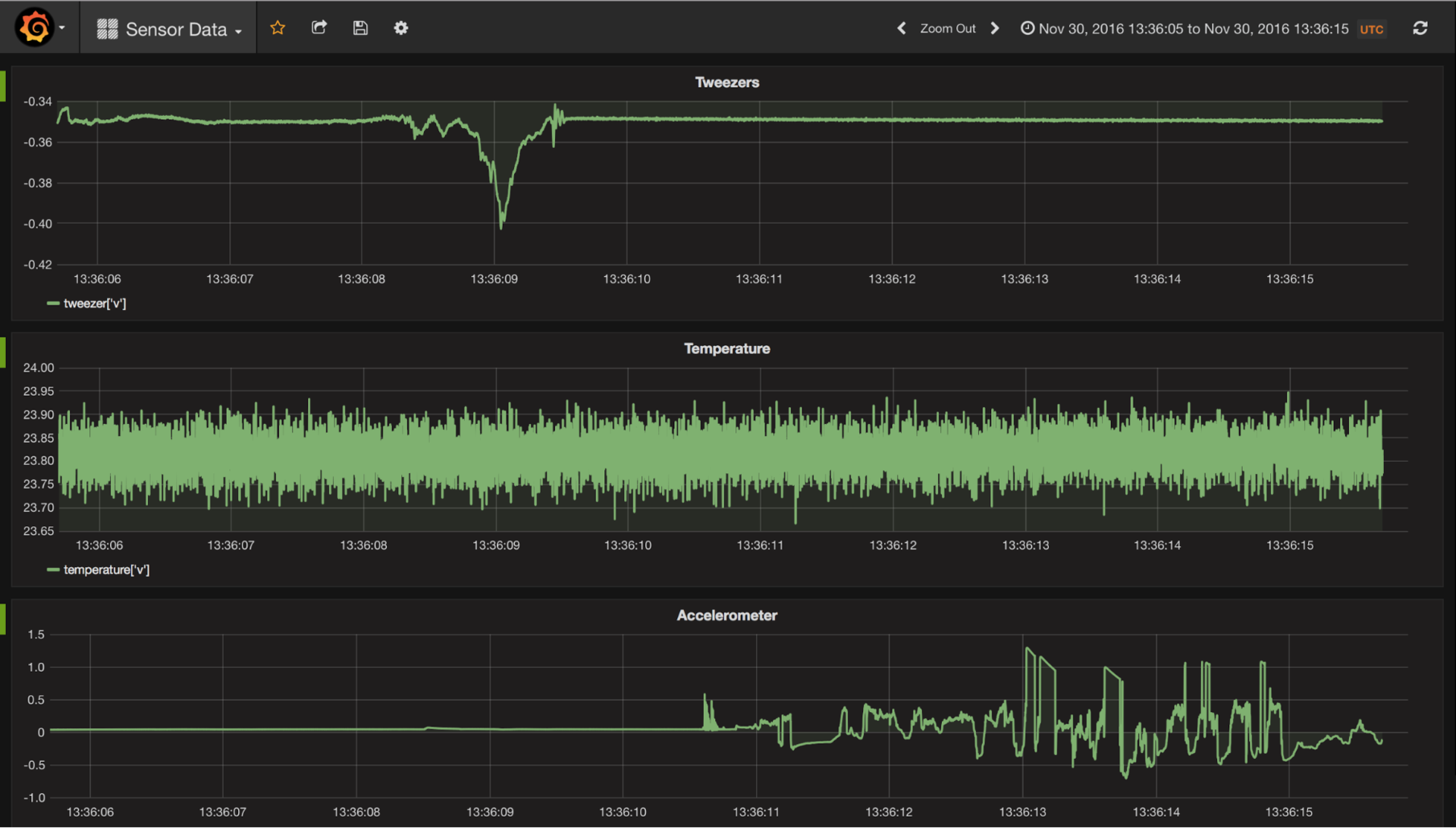
You need to configure the connection parameters and specify the requests for data selection.

Downloading and starting CrateDB for experiments can be done like this:
To run CrateDB 1.0.4, I used my Groovy script , which automatically installs the database in the user's home directory:
Either run the database in the Docker container or a dozen other ways .
When using CrateDB in your project, you need to remember that first of all it is a distributed database based on Elasticsearch, so there will be no full-fledged ACID . But if horizontal scalability is important, full-text search and the ability to execute SQL queries is an excellent candidate for storing project data. The good news is that the project is developing in leaps and bounds and is available for use under the Apache 2.0 license.
- support outer join;
- case when ... then ... end in requests;
- functions for working with spatial (Geospatial) data;
- it is possible to display time series data (Time Series) in Grafana;
- limited support for subqueries;
- cluster nodes operating in read-only mode;
- emulation of a PostgreSQL 9.5 protocol subset;
A pleasant surprise was to find in the github project that the CrateDB team has a Russian-speaking developer Ruslan . I quickly received a response from him to questions about the internal structure and dependencies of the project.
When last time on Habré I talked about the peculiarities of working with queries in the article "JOIN the dark side of the SQL" , I mentioned the shortcomings of the native jdbc driver for crate and incomplete support for join operations. These defects have been eliminated in recent versions (> 1.0)!
Now you can use the PostgreSQL jdbc driver, the pg command line utilities, and you do not need to pack a separate crate driver with the application. This was made possible by partially emulating wire PostgreSQL 9.5 protocol on the server. With an eye to the fact that transactions are not supported (therefore autocommit is set), authentication with any login / password is successful, SSL is not supported for connections and only UTF-8 character encoding is supported. The COPY subprotocol pg and stored functions call subprotocol is not yet supported. It should be remembered that the syntax of SQL queries and a subset of supported functions are specific to CrateDB.
')
Finally, the server has support for Left, Right and Full Outer Join . Although the special scheduler optimizations are not applied and the join is implemented as a nested loop, but the filters are applied distributed - on each shard of the tables from the query.
There was a strange syntax in SELECT, resembling PL / SQL CASE:
CASE WHEN condition THEN result [WHEN ...] [ELSE result] END With subqueries in FROM until the miracle happened. Either sub-requests with aggregates are supported , or requests that the parser can easily rewrite. I hope that in a year the project will be surprised by the fact that complex subqueries will be available.
The functions distance, within, intersects, latitude / longitude are available for working with spatial data in queries. Work with geodata has long been in Elasticsearch , on the basis of which this distributed database was created.
There is a data access plugin for Grafana . You can draw graphs for monitoring data and telemetry stored in CrateDB.
You need to configure the connection parameters and specify the requests for data selection.
Downloading and starting CrateDB for experiments can be done like this:
java -jar groovy-grape-aether-2.4.5.1.jar https://raw.githubusercontent.com/igor-suhorukov/crate-io-installer/master/crate-io.groovy
To run CrateDB 1.0.4, I used my Groovy script , which automatically installs the database in the user's home directory:
@Grab(group='org.codehaus.plexus', module='plexus-archiver', version='2.10.2') import org.codehaus.plexus.archiver.tar.TarGZipUnArchiver import com.github.igorsuhorukov.smreed.dropship.MavenClassLoader; @Grab(group='org.codehaus.plexus', module='plexus-container-default', version='1.6') import org.codehaus.plexus.logging.console.ConsoleLogger; def artifact = 'crate' def version = '1.0.4' def userHome= System.getProperty('user.home') def destDir = new File("$userHome/.crate-io") def crateIoDir= new File(destDir, "$artifact-$version"); if(!crateIoDir.exists()){ destDir.mkdirs() String sourceFile = MavenClassLoader.using("https://dl.bintray.com/crate/crate/").getArtifactUrlsCollection("io.crate:$artifact:tar.gz:$version", null).get(0).getFile() final TarGZipUnArchiver unArchiver = new TarGZipUnArchiver() unArchiver.setSourceFile(new File(sourceFile)) unArchiver.enableLogging(new ConsoleLogger(ConsoleLogger.LEVEL_DEBUG,"Logger")) unArchiver.setDestDirectory(destDir) unArchiver.extract() } def proc = "$crateIoDir.absolutePath/bin/crate".execute() proc.consumeProcessOutput(System.out, System.err) proc.waitFor() Either run the database in the Docker container or a dozen other ways .
Conclusion
When using CrateDB in your project, you need to remember that first of all it is a distributed database based on Elasticsearch, so there will be no full-fledged ACID . But if horizontal scalability is important, full-text search and the ability to execute SQL queries is an excellent candidate for storing project data. The good news is that the project is developing in leaps and bounds and is available for use under the Apache 2.0 license.
Source: https://habr.com/ru/post/323742/
All Articles