How Discord stores billions of messages

Discord continues to grow faster than we expected, just like custom content. The more users - the more messages in the chat. In July, we announced 40 million messages per day , in December we announced 100 million , and in mid-January we overcame 120 million. We immediately decided to keep the chat history forever, so users can return at any time and get access to their data from anyone devices. This is a lot of data, the flow and volume of which is growing, and all of them should be accessible. How do we do it? Cassandra!
What we did
The initial version of Discord was written in less than two months in early 2015. Perhaps one of the best DBMSs for fast iteration is MongoDB. Everything in Discord was specially stored in a single replica (replica set) of MongoDB, but we also prepared everything for simple migration to the new DBMS (we knew that we were not going to use MongoDB sharding because of its complexity and unknown stability). In fact, it is part of our corporate culture: develop quickly to experience a new product function, but always with a course for a more reliable solution.
Messages were stored in the MongoDB collection with a single composite index on
channel_id and created_at . Around November 2015, we reached the milestone of 100 million messages in the database, and then we began to understand the problems that await us: the data and the index are no longer placed in RAM, and the delays become unpredictable. It's time to migrate to a more suitable DBMS.')
Choosing the right DBMS
Before choosing a new DBMS, we needed to understand the existing read / write templates and why there were problems with the current solution.
- It quickly became clear that read operations are purely random, and read / write ratios are approximately 50/50.
- Heavy Discord voice chat servers almost did not send messages. That is, they sent one or two messages every few days. For a year, a server of this type is unlikely to reach the milestone of 1000 messages. The problem is that even with such a small number of messages, this data is more difficult to deliver to users. Simply returning 50 messages to the user can result in many random disk searches, which results in crowding out the disk cache.
- Heavy servers of private text chat Discord send a decent number of messages, easily falling into the range between 100 thousand and 1 million messages per year. They usually request only the most recent data. The problem is that there are usually less than 100 participants on these servers, so the data request rate is low and they are unlikely to be in the disk cache.
- Large public Discord servers send a lot of messages. There are thousands of contributors sending thousands of messages per day. Easily recruited millions of messages per year. They almost always request messages sent in the last hour, and this happens often. Therefore, the data is usually located in the disk cache.
- We knew that in the coming year, users will have even more ways to generate random readings: the ability to view their references in the last 30 days and then jump at that moment in history, view and navigate to the attached messages and full-text search. All this means even more random readings!
We then defined our requirements:
- Linear scalability - We do not want to revise the decision later or manually transfer the data to another shard.
- Automatic failover - We like to sleep at night and make the Discord as self-healing as possible.
- A little support - It should work as soon as we install it. All we have to do is add more nodes as data increases.
- Proven to work - We love to try new technologies, but not too new.
- Predictable performance - Messages are sent to us if the API response time in 95% of cases exceeds 80 ms. We also do not want to deal with the need to cache messages in Redis or Memcached.
- Non blob storage - Writing thousands of messages per second will not work fine if we have to continuously de-serialize blobs and attach data to them.
- Open source - We believe that we manage our own destiny, and do not want to depend on a third-party company.
Cassandra was the only DBMS that met all our requirements. We can simply add nodes when scaling, and it copes with the loss of nodes without any influence on the application. In big companies like Netflix and Apple, there are thousands of Cassandra nodes. Linked data is stored side by side on the disk, ensuring minimal search operations and easy distribution across the cluster. It is supported by DataStax, but is distributed open-source and community-based.
Having made a choice, it was necessary to prove that he was really justified.
Data modeling
The best way to describe a newcomer to Cassandra is abbreviation KKV. The two letters “K” contain the primary key. The first “K” is the partition key. It helps to determine in which node the data lives and where to find them on disk. There are many lines inside a section, and the second “K”, the clustering key, defines a specific line within a section. It works as a primary key inside a section and determines how to sort the rows. You can submit a section as an ordered dictionary. All these qualities combined allow for very powerful data modeling.
Remember that messages in MongoDB were indexed using
channel_id and created_at ? channel_id became the partition key, since all messages work on the channel, but created_at does not give a good clustering key, because two messages can be created at the same time. Fortunately, each ID in Discord is actually created in Snowflake , that is, chronologically sorted. So it was possible to use them. The primary key is turned into (channel_id, message_id) , where message_id is Snowflake. This means that when loading a channel, we can tell Cassandra the exact range where to look for messages.Here is a simplified diagram for our message table (it skips about 10 columns).
CREATE TABLE messages ( channel_id bigint, message_id bigint, author_id bigint, content text, PRIMARY KEY (channel_id, message_id) ) WITH CLUSTERING ORDER BY (message_id DESC); Although the schemas of Cassandra are similar to relational database schemas, they are easy to modify, which does not have any temporary effect on performance. We took the best from blob storage and relational storage.
As soon as the import of existing messages into Cassandra began, we immediately saw warnings in the logs that sections larger than 100 MB were found. Yah?! After all, Cassandra declares support for sections 2 GB! Apparently, the opportunity itself does not mean that it should be done. Large sections impose a heavy load on the garbage collector in Cassandra during compaction, cluster expansion, etc. The presence of a large partition also means that the data in it cannot be distributed across the cluster. It became clear that we will have to somehow limit the size of the sections, because some channels of Discord may exist for years and constantly increase in size.
We decided to distribute our messages in blocks (buckets) in time. We looked at the largest channels in the Discord and determined that if we store messages in blocks of about 10 days, we will comfortably invest in the 100 MB limit. Blocks must be received from
message_id or timestamps. DISCORD_EPOCH = 1420070400000 BUCKET_SIZE = 1000 * 60 * 60 * 24 * 10 def make_bucket(snowflake): if snowflake is None: timestamp = int(time.time() * 1000) - DISCORD_EPOCH else: # When a Snowflake is created it contains the number of # seconds since the DISCORD_EPOCH. timestamp = snowflake_id >> 22 return int(timestamp / BUCKET_SIZE) def make_buckets(start_id, end_id=None): return range(make_bucket(start_id), make_bucket(end_id) + 1) Cassandra partition keys can be composite, so our new primary key has become
((channel_id, bucket), message_id) . CREATE TABLE messages ( channel_id bigint, bucket int, message_id bigint, author_id bigint, content text, PRIMARY KEY ((channel_id, bucket), message_id) ) WITH CLUSTERING ORDER BY (message_id DESC); To request recent messages in the channel, we generated a range of blocks from the current time to
channel_id (it is also sorted chronologically as Snowflake and must be older than the first message). Then we sequentially query the sections until we collect enough messages. The downside of this method is that occasionally active instances of Discord will have to poll many different blocks in order to collect enough messages with time. In practice, it turned out that everything is in order, because for the active Discord instance there are usually enough messages in the first section, and such are the majority.Import messages in Cassandra passed without interference, and we were ready to try it in production.
Hard start
Bringing a new system into production is always scary, so a good idea would be to test it without affecting users. We configured the system to duplicate read / write operations in MongoDB and Cassandra.
Immediately after launching, errors appeared in the bug tracker, that
author_id is zero. How can it be zero? This is a required field!Coherence ultimately
Cassandra is an AP type system, that is, guaranteed integrity is sacrificed for accessibility, which we wanted in general. In Cassandra, reading before writing is contraindicated (read operations are more expensive) and therefore all that Cassandra does is update and insert (upsert), even if you provide only certain columns. You can also write to any node, and it will automatically resolve conflicts using the “last record wins” semantics for each column. So how did this affect us?

Sample race status edit / delete
If a user edited a message while another user deleted the same message, we had a line with completely missing data, except for the primary key and the text, because Cassandra only writes updates and inserts. There are two possible solutions for this problem:
- Write back the whole message while editing the message. Then there is the possibility of resurrecting deleted messages and added chances of conflicts for simultaneous entries in other columns.
- Identify the damaged message and delete it from the database.
We chose the second option by defining the required column (in this case
author_id ) and deleting the message if it is empty.Solving this problem, we noticed that we were very inefficient with write operations. Since Cassandra is ultimately agreed, she cannot take and immediately delete the data. She needs to replicate deletions to other nodes, and this should be done even if nodes are temporarily unavailable. Cassandra handles this by equating the deletion to a peculiar form of recording called “tombstone” (“gravestone”). During a reading operation, she simply slips through the “tombstones” that occur along the way. The tombstones' lifetime is set up (by default, 10 days), and they are permanently deleted during the compaction of the base, if the term is out.
Deleting a column and writing a zero to a column is absolutely the same thing. In both cases, a "gravestone" is created. Since all entries in Cassandra are updates and inserts, you create a “headstone” even if you initially write zero. In practice, our complete message layout consisted of 16 columns, but the average message had only 4 fixed values. We recorded 12 "gravestones" in Cassandra, usually for no reason. The solution to the problem was simple: write only non-zero values to the database.
Performance
Cassandra is known to perform write operations faster than reads, and we have seen exactly that. Write operations occurred in the interval of less than a millisecond, and read operations — less than 5 milliseconds. Such indicators were observed regardless of the type of data accessed. Performance remained unchanged during the week of testing. No wonder, we got exactly what we expected.
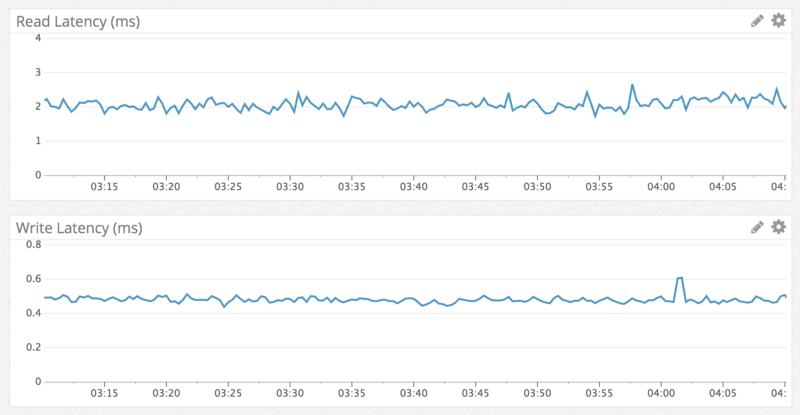
Delay read / write, according to data from the log
In accordance with fast, reliable reading performance, here is an example of a transition to a message a year ago in a channel with millions of messages:
Big surprise
Everything went smoothly, so we rolled out Cassandra as our main database and disabled MongoDB within a week. She continued to work flawlessly ... for about 6 months, until one day she stopped reacting.
We noticed that Cassandra continuously stops for 10 seconds during garbage collection, but could not understand why. They started digging and found the Discord channel, which took 20 seconds to load. The culprit was the public Discord-server of subddit Puzzles & Dragons . Since it is public, we are joined to watch. To our surprise, there was only one message on the channel. At that moment, it became obvious that they deleted millions of messages through our APIs, leaving only one message on the channel.
If you read carefully, remember how Cassandra handles deletions using “gravestones” (mentioned in the “Consistency in the Final Matter” chapter). When a user downloads this channel, even though there is one message, Cassandra has to efficiently scan millions of “gravestones” of messages. Then it generates garbage faster than the JVM can collect it.
We solved this problem as follows:
- We reduced the tombstone life from 10 days to 2 days, because every evening we run the Cassandra (anti-entropy process) repair on our message cluster.
- Modified request code to keep track of empty blocks on the channel and avoid them in the future. This means that if the user initiated this request again, then at worst Cassandra will scan only the most recent block.
Future
At the moment, we have a cluster of 12 nodes with a replication rate of 3, and we will continue to add new Cassandra nodes as needed. We believe that this approach is efficient in the long term, but as Discord grows, the distant future is seen, when you have to save billions of messages per day. Netflix and Apple have clusters with hundreds of nodes, so for now we have nothing to worry about. However, I want to have a couple of ideas in reserve.
Near future
- Update our message cluster from Cassandra 2 to Cassandra 3. The new storage format in Cassandra 3 can reduce storage by more than 50%.
- Newer versions of Cassandra do a better job of handling more data in each node. We now store approximately 1 TB of compressed data in each of them. We think that it is safe to reduce the number of nodes in a cluster by increasing this limit to 2 TB.
Distant future
- Explore Scylla is a Cassandra-compatible DBMS and written in C ++. In normal operation, our Cassandra nodes actually consume few CPU resources, but during off-peak hours during the Cassandra repair (anti-entropy process) they are quite dependent on the CPU, and the repair time increases depending on the amount of data recorded since the last repair. Scylla promises to significantly increase the repair speed.
- Create a system to archive unused channels in Google Cloud Storage and download them back on demand. We want to avoid this and do not think that this will have to do.
Conclusion
It has been more than a year since the transition to Cassandra, and despite the “big surprise” , it was a peaceful swim. We went from more than 100 million total messages to more than 120 million messages per day, while maintaining performance and stability.
Thanks to the success of this project, we have since transferred all our other data in production to Cassandra, and also successfully.
Over the course of this article, we explore how we perform full-text searches across billions of posts.
We still do not have specialized DevOps engineers (only four backend engineers), so it’s very cool to have a system that you don’t have to worry about. We are recruiting staff, so contact us if such tasks tickle your imagination.
Source: https://habr.com/ru/post/323694/
All Articles