LIFT: Learned Invariant Feature Transform

Introduction
In recent years, ubiquitous neural networks are finding more and more applications in various fields of knowledge, crowding out the classical algorithms used for many years. The area of computer vision, where year after year more and more problems are solved with the help of modern neural networks, is no exception. It is time to write about another traditional fighter in the war, "Traditional Vision vs. Deep Training." For many years, the SIFT (Scale-invariant Feature Transform) algorithm, proposed back in 1999, reigned supreme in the task of finding local features of images (the so-called key points), many folded their heads in trying to surpass it, but only Deep Learning succeeded. So, meet, a new algorithm for finding local features - LIFT (Learned Invariant Feature Transform).
Need for Data

For deep learning to work, you need a lot of data, otherwise the magic will not work. And we need not all kinds of data, but those that would be a representative representation of the task that we want to solve. So, let's look at what man-made detectors / descriptors of special points can do:
- Invariance to the location in the picture.
- Invariance to the angle of rotation.
- Invariance to scale.
Okay, so we need a dataset containing a bunch of points where for each particular point there will be a lot of samples obtained from different angles. You can, of course, take arbitrary images, cut points from them, and then use synthetically generated affine transformations to get datasets of arbitrarily large size. But synthetics are bad because there are always some limitations on the accuracy of modeling.
real cases. Real data sets that meet our requirements arise when solving some applied problems of computer vision. For example, when 3D reconstructing scenes shot from multiple angles, we do something like the following:
- For each image of the scene we find special points.
- We find correspondences between special points from different images.
- But based on this information, we calculate the spatial arrangement of each frame (parameterized through those. rotation and translation relative to the origin).
- Using the triangulation procedure, we find the 3D positions of all singular points.
- Using the spreading optimization aki Bundle Adjustment (most often the algorithm, derived from the Levenberg-Marquardt method), we obtain more accurate information about the location of points in space.
- Any different postprocessing. For example, you can stretch a polygonal model on a cloud of points to get smooth surfaces.
As a by-product of the operation of such an algorithm, we get a cloud of points, where each 3D point corresponds to several of its 2D positions (projections) on the scene frames. Here is a cloud - this is exactly the dataset we need. Without taking much interest in the intricacies of Structure From Motion, the authors took a couple of publicly available datasets for 3D reconstruction, drove them through a publicly available tool for building a cloud of points (VisualSFM), and then used the resulting data set in their experiments. As stated, the mesh trained on such a set is also generalized to other types of scenes.
Grids, nets, nets
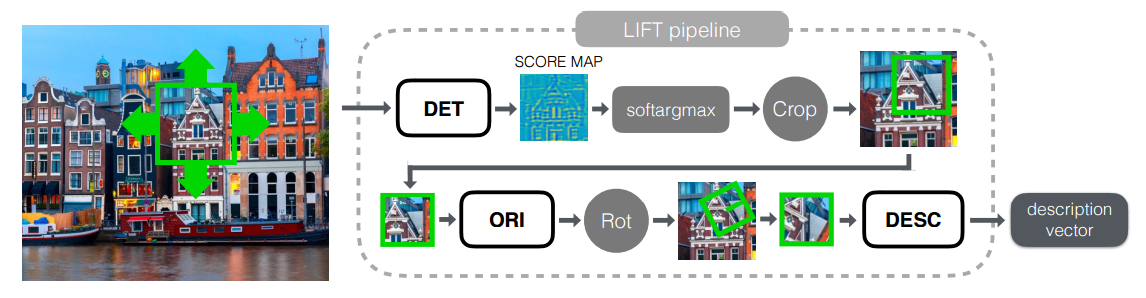
We have dealt with dataset, so it's time to move on to the most interesting, namely, the study of grids. The whole grid can be divided into 3 logical blocks:
- Detector - is responsible for finding special points on the entire image as a whole.
- Rotation Estimator - determines the orientation of the point and turns the patch around it so that the rotation angle is equal to zero.
- Descriptor - takes as input a patch, by which it builds a unique (here how it will turn out) vector describing this patch. These vectors can already be used, for example, in order to calculate the Euclidean distance between a pair of points and understand whether they are similar or not.
First, we consider the inference for this model as a whole, and then all the blocks separately and exactly how they train.
Inference
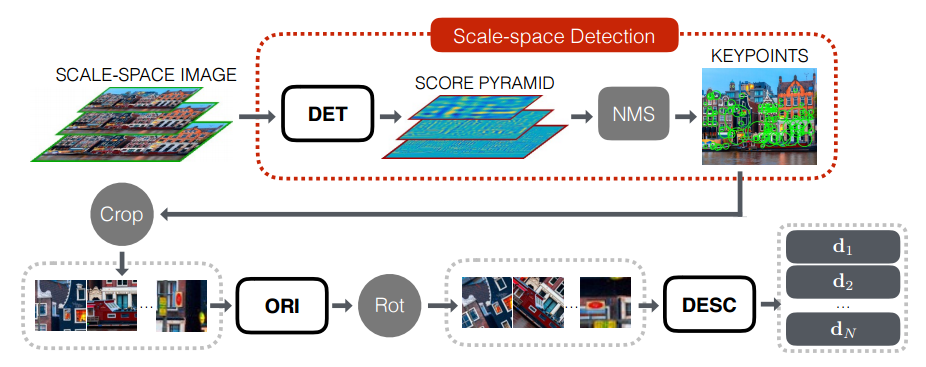
The search for special points and the calculation of their descriptors occurs in several stages:
- To begin with, we build a pyramid of images (i.e., we bring the original image to several scales to obtain scale-invariant features) for the original image.
- Each layer of the pyramid is run through the network-detector and the Score Map pyramid is calculated.
- Using the Non-Maximum Suppression procedure, we find the strongest candidates for particular points.
- For each singular point, cut a patch that includes the singular point and some of its neighborhoods.
- Align the orientation of each patch with the Orientation Estimator.
- We calculate the handle for each aligned patch.
- We use the obtained descriptors for the standard feature matching procedure.
Descriptor
Since the time of the SIFT feature, it is known that even if we are not very good at finding truly unique points, but we can build a cool descriptor for each of them, then we can most likely solve the problem. Therefore, we will begin the review from the end, namely with the construction of a descriptor for the singular point already found. Generally speaking, any convolutional mesh, taking a picture (patch) as input, yields some description of this picture, which can already be used as a descriptor. But, as practice shows, there is no need to take a huge network, such as, for example, VGG16, ResNet-152, Inception etc., a small network is enough for us: 2-3 convolutional layers with activations in the form of hyperbolic tangents
and other small things like batch normalization, etc.
For definiteness, let's denote our network descriptor. where - descriptor convolution network, - its parameters - Patch with zero angle (obtained from the Rotation Estimator).
For each singular point we make two pairs:
- - a pair of patches corresponding to the projections of the same particular point.
- - a couple of patches where the first one belongs to a particular point and the second (negative sample) does not. At the same time, the “negative” patch is selected from a certain neighborhood, not too far from positive. In the process of training the neighborhood decreases, so that negative samples become more and more difficult.
In the process of learning we will minimize the loss-function of the following form:
Those. in essence, we want the Euclidean distance between similar points to be small, and between points that are not similar to each other to be far away.
Rotation estimator
Since we can observe the same point not only from different points of space, but also from different angles of inclination, we must be able to build the same descriptor for the same particular point, no matter from what angle we observe it. But instead of teaching Descriptor to memorize all possible angles of inclination for the same point, it is proposed to use an intermediate computational block that will determine the orientation of the patch in space (Rotation Estimator) and “turn” the patch to some state invariant to rotation (Spatial Transform). Of course, it would be possible to use the block for calculating the orientation of the patch in space, taken from the algorithm for constructing SIFT features, but outside the 21st century it is now accepted to reduce any computer vision problem to machine learning. So we will use another convolutional neural network to solve this problem.
So, we denote our neural network as: where - network settings, and - source patch.
Let's take a couple of patches as a sample. , belonging to one singular point, but having different angles of inclination, as well as their spatial coordinates , .
In the process of learning we will minimize the following loss-function:
Where - patch obtained after the procedure for correcting its orientation, .
Those. when training a network, we turn patches, with different angles of inclination, so that the Euclidean distance between their descriptors becomes minimal.
Detector
It remains to consider the last step, namely the direct detection of specific points on the original image. The essence of this network is that the entire image is driven through it, and some feature map is expected at the output, for which special points on the source image correspond to strong responses.
In spite of the fact that when the model is inference, the detector is triggered on the entire image at once, in the course of the training we will chase it only for individual patches.
The calculation of the detector consists of two steps: first we must calculate the Score Map for the patch, which will then determine the position of the singular point:
and then, calculate the position of the singular point:
Where Is a function that calculates a weighted center of mass with weights that are the result of a calculation :
where y is the position within Score Map, - hyperparameter responsible for the coefficient of "blurring" softmax-function.
When training the detector, we will take four patches. where - projections of the same singular point, - projection of another singular point, - A patch not belonging to a particular point. For the collection of such patches we will minimize the following loss-function:
Where - balancing parameter for two members of the loss function.
Member of the loss, responsible for the correct classification of positives and negatives:
Loss member, responsible for the exact localization of singular points:
Training
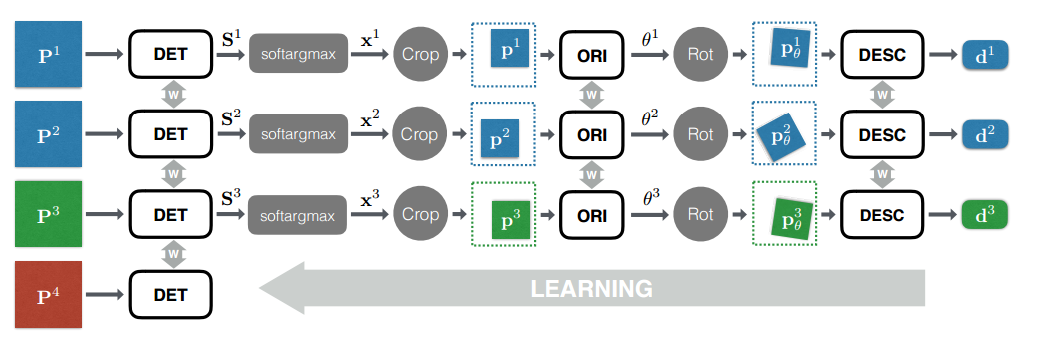
The whole network trains in the fashionable fashion now End-To-End, i.e. Immediately learn all parts of the network in parallel as Siamese networks. At the same time, for each of the 4 used in training, the patches create a separate network brunch with sharring weights between them.
Experiments
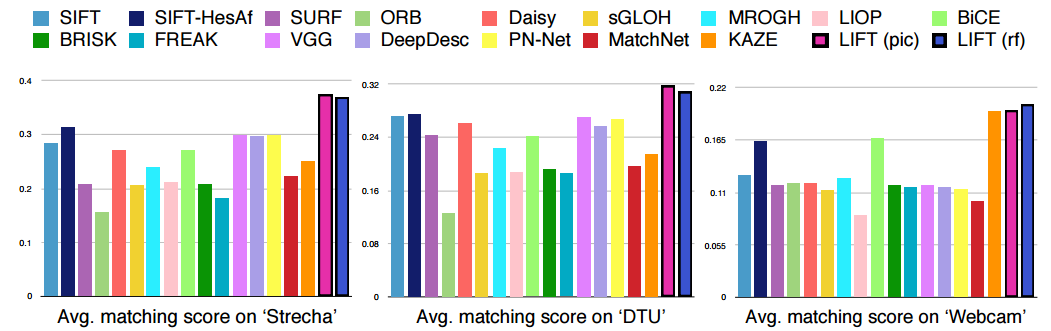
Comparing with the existing methods for finding particular points, the authors concluded that their approach is state of the art.
And the results of their network can be viewed in the following video:
Conclusion
The presented work is another confirmation of the fact that the time of traditional methods of computer vision is taking place, and it is being replaced by the era of Sainz. And once again coming up with an ingenious heuristics, solving some complex problem, you should think: is it possible to formulate a task so that the computer could independently iterate over millions of heuristics and choose the one that solves the problem in the best way.
Links
- The original article can be found at arxiv: LIFT: Learned Invariant Feature Transform
- Enough friendly code on Theano is on github: https://github.com/cvlab-epfl/LIFT
- You can read about the training of Siamese networks and similar pipeline calculation of descriptors of special points, but with reference to the stereomatching task, from our father Jan LeKun here: Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches
Thanks for attention.
PS The post is the result of one discussion on the circles , in connection with which the author's syllable may not be enough literary.
')
Source: https://habr.com/ru/post/323688/
All Articles