Make changes to the code little by little

It was always curious to know what and how coders overseas think? It is logical to assume that technical thinking and basic processes should be similar to Russian developers. Under the cut the opportunity to compare our trips with the "local". If you are doing well with English, the original of the publication and the author himself can be found at the link. .

')
Web application development is a young and unexplored type of activity. Tools for generating and compiling code are widely available, have been used for a relatively long time and are always at hand with programmers. The idea is (such is the tendency) to take one or two tools, run from the command line, and building on their ability to do some part of the work.
Git provides solutions to any conceivable problems with merging code. There is also support for arbitrary complex branching and tagging schemes. Many reasonably believe that it is advisable to always use these functions.


It's a delusion. We should start with the procedures that will take effect in the process of the current work, and move in the opposite direction to what was done during the development. Even with the creation of paged MVP (minimum viable products) , in the end, in the existing business, the majority of software costs are operating costs, not development costs .
I will give an example that works very well in practice from the point of view of operating activities: the code needs to be deployed in production in small fragments (code units). I suppose the size of such fragments should be measured in dozens of lines, not in hundreds. You will see that, having taken this approach as a basis, all you have to do is perform only relatively simple change control.

Your last chance to avoid mistakes in the code being developed is just before you launch it, so many development teams consider it a good idea to do standard (as it were) code reviews (code review). This is not a mistake, but the effect of the effort expended is low.
Checking hundreds of lines of code is a serious task. It requires a lot of working time and immersion in the process. Viewing large changes usually ends with putting the tag “lgtm” (“I think this is not bad”), while at the same time, for the bustle of small fixes, you can ignore the problems of a more general nature. Even in teams with the strongest development culture, there are code checks that turn into a witch hunt.

Viewing hundreds of lines for errors is an efficient, easy process. It does not prevent all problems, and does not create new ones. This process represents a reasonable balance between the possible and the practical.

Rolling out large modified fragments terrifies even experienced developers. And the reason is the instinctive understanding of a simple relationship.

With every line of code with some probability there is an undetected error that will pop up during operation. The process of code execution may affect the value of this probability, but it cannot reduce it to zero. Large modified fragments contain many lines, and therefore there is a high probability of failure when using real data and real traffic. In online systems, the code must be passed to work to check its performance.

Unable to prevent all problems in production. They will still arise. And better let it happen when we push small changes.
Many serious bugs in production manifest themselves when rolling out . If there is no index in the new database query on your largest page, then most likely you will quickly receive a corresponding warning. It is reasonable to assume that the error is in the latest version of the code.
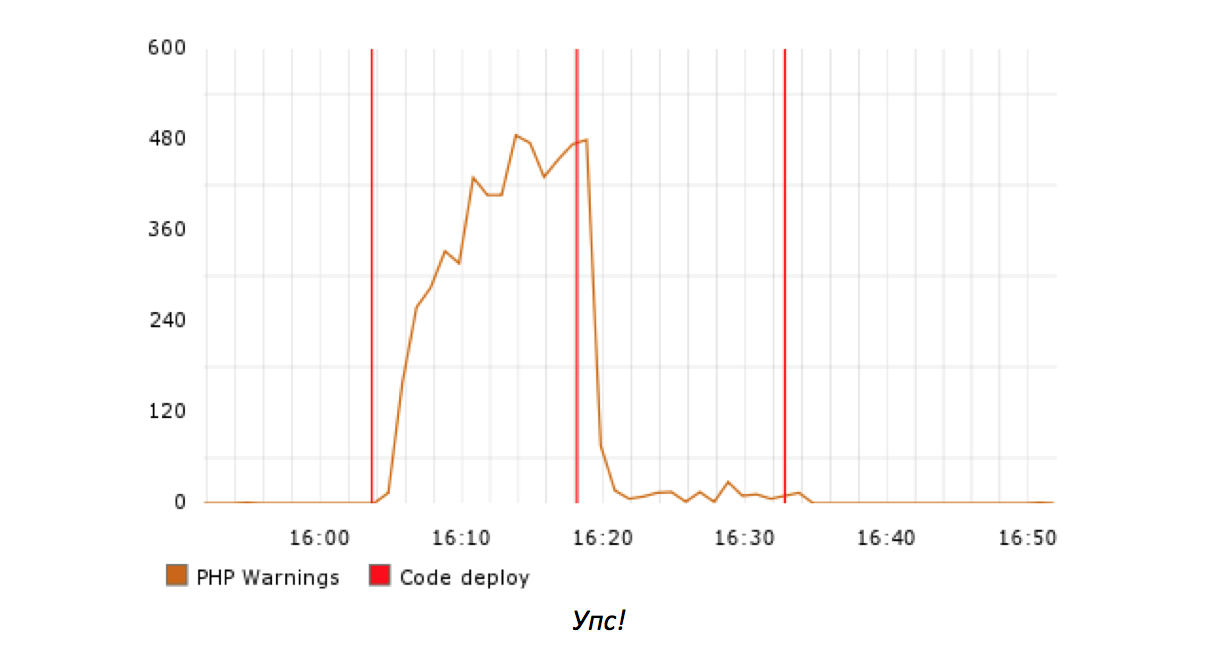
In another case, you will fix a small but harmful problem that has existed for some time. The key information needed to solve this problem can be obtained at its first occurrence, as well as in the analysis of the changes made since that moment.
In both scenarios, the debugger deals with altered code fragments. Detection of errors in such fragments is similar to the verification of the code, but only worse - this is a test performed under duress. Therefore, the duration of troubleshooting in production will tend to be proportional to the size of the variable fragments.

The effectiveness of code checking with a preventive purpose limits the human factor. Problems in releases are inevitable and proportional to the volume of the released code. The time required for debugging is a function (among other things) of the amount of code being debugged.
Below is a simple list of instructions. But if you take them seriously, you can draw some interesting conclusions.
• The code branches are inert and that is bad . I tell people that I don’t mind working in branches, if it helps them, and if I can’t even say with certainty that they do it. It’s easier to double the size of a branch than to merge and deploy all the code, and the developers constantly fall into this trap.
• Easy source code manipulation is normal . GitHub branches are great, but git diff | gist -optdiff also works well when it comes to dozens of lines of code.
• You do not need elaborate rituals of git releases . Ceremonies like tagging releases seem like a waste of time if you release releases many times a day.
• Your real problem is frequent releases . Limiting the amount of released code can slow down the progress, unless you can simultaneously increase the frequency of publications. This is not so easy to do, and at the same time your arsenal of tools will start to the means, sharpened by the solution of this problem .
This is not an exhaustive list. If you start with your day-to-day operating activities and move in the opposite direction, towards the development of code, this will allow you to critically reflect on your entire development process. And it will only benefit.
Source: https://habr.com/ru/post/323654/
All Articles