Battle drone, completely yours. We teach gaming AI method busting strategies
In continuation of the article “ Search in the space of strategies. AI driver . " I made a mini-game of the “fighting” genre, where a student of AI fights with other handwritten bots and develops a strategy for winning by trial and error.
In this game, two guys are fighting like this:

They are located on the coordinate axis, have a certain amount of health, and they also have the parameter "cooldown". Cooldown - this is how many tacts the fighter will miss due to the fact that he performed this action. For example, the action “go” causes cooldown 2, and the action “stabbing” causes cooldown 4. You can act only when the cooldown has dropped to zero (it decreases every turn by one if it is not yet zero).
So, there are two fighters. Everyone has a coordinate, health and cooldown:
')
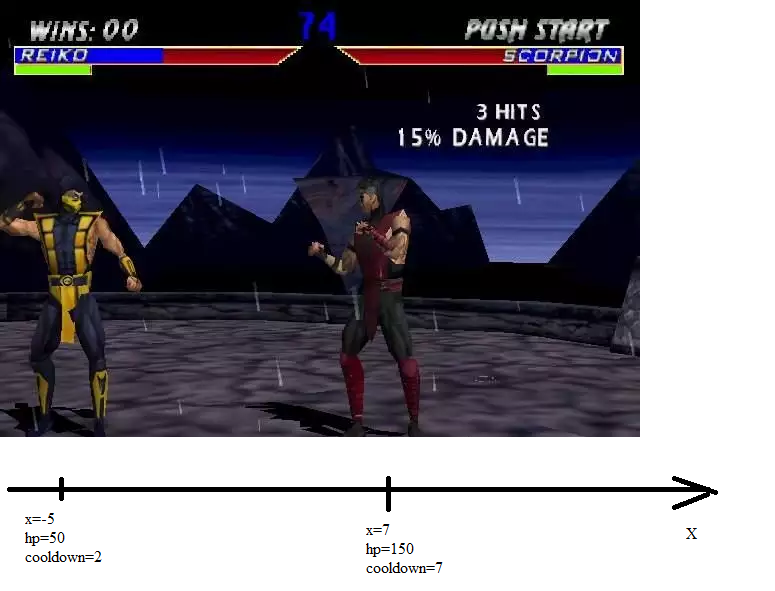
Each of the fighters in his turn can perform one of 6 actions:
1) Go right at 1 (causes cooldown 2)
2) Go left at 1 (causes cooldown 2)
3) Wait (calls cooldown 1)
4) Strike with a knife (causes cooldown 4, deals 20 damage if the distance to the enemy is no more than 1)
5) Shot from crossbow (causes cooldown 10; at a distance of 5 cells deals 10 damage; up to 12 cells deals 4 damage)
6) Poisoning (causes cooldown 10; at a distance of up to 8 cells, deals 2 damage and poisons. A poisoned enemy loses 1 hp each turn. Poisoning continues until the end of the battle, it cannot be poisoned twice)
At the entrance, each fighter receives information: x, hp and the state is poisoned / not poisoned about himself and his opponent. In addition, the value comes cooldown opponent. At the exit of each strategy gives a number from 1 to 6.
In the case when the strategy is implemented by a neural network, it produces 6 numbers, each of which means “as far as I want this option to be realized”. For example, if the neural network issued 0 0 1 0 -1 0, this means that it selects action 3, since the 3rd element of the sequence has the highest value.
One fight lasts 70 bars (or until one soldier kills another, if it happens earlier). 70 measures is 7 shots or 35 steps.
We will determine the quality metric for the AI fighter. We assume that the quality of the neural network game in one battle = -100 - (how much health we have lost) + (how much the enemy has lost health). Minus hundred is needed because my optimizer maximizes well only negative values.
q = -100- (input (3) -units (1) .hp) + (input (4) -units (2) .hp);
The parameters of this strategy will be the weights and shifts in the neural network - the test of our AI looks like this: a set of weights is loaded into a neural network, this neural network is fought for a while by the enemy, then it receives a quality assessment. The optimizer analyzes the resulting quality, generates a new set of scales (presumably, giving the best quality), and the cycle repeats.
An important element of this game is the stepwise dependence of the quality metric on the neural network coefficients.

Why is that? Because, let's say, the neural network produced the following output vector: 0 0 1 0 0 0. And then we slightly changed one of any parameters. And we got such an output vector: 0 0 0.9 0 0 0. Or 0.1-0.1 0.9 0 0 -0.1. At the same time, the neural network, as it voted for the third option, continues to vote for it.
That is, optimization methods based on small changes (gradient descent, for example) will not work here.
The quality of AI according to the result of a series of battles will be considered as the average quality for all battles plus the worst quality divided by two.
Why take the worst? Then, so that the neural network did not learn how to play perfectly in one rare case, playing poorly in all the others, and did not get a bunch of points for it “on average”. Why take an average? Then, the more choices a neural network participates in evaluating, the more it is:
It looks like this:

And the second option is much easier to optimize using small changes than the first.
We carry out a series of tests. The quality metric is stuck at around -100. That is, AI did not fight. So what? Learning to run is much easier than learning to win.
We introduce a restriction. Whenever our fighter goes beyond the arena (from -20 to 20 to x), he dies. The order "not one step back" in action.
Yes, and discuss the strategy of handwritten bots, of which there are several.
Handwritten bot "Gladiator". Goes to rapprochement. If it reaches the enemy with a knife, it hits. It shoots only if it sees that it will kill the enemy with one shot (which almost never happens).
AI began to win more often than lose, after 15 minutes of training (metric: -95.6). A minute later, he improved his skill (metric: -88). In another minute, the metric was -77.4. In a minute -76.2.
Check how he wins. We start the fight.
Gladiator has a coordinate of 10, hp = 80, and a neural network has a coordinate of -9, hp = 80.
The gladiator advances, and the neural network stands still and makes knife strikes into the void. As soon as the Gladiator reached the firing line with poison, the neural network shoots. Then, when the cooldown passes, the neural network continues to uselessly wave the knife ... Poison shoots at 8 cells. To pass 8 squares, you need to spend 16 turns. A knife strike is 4 moves. 16 is completely divisible by 4. This means that when a gladiator approaches the neural network at close range, she strikes with a knife earlier than the Gladiator. In fact, AI used the knife strike cooldown as a timer. Now the ratio of health - 80:34 is not in favor of the Gladiator. If a neuronet fired a crossbow (which would seem more reasonable than stabbing in the air), it would have missed the chance of a first strike.
The time expired when the score was 45: 5 in favor of the neural network.
Create a few new handwritten bots.
Handwritten bot "Sturmovik." Goes to rapprochement. If it hits with poison, and the enemy is not poisoned yet, applies poison. If you shoot from a crossbow at a short distance (5 units), it shoots. If the opponent has approached the stop, apply the knife.
Handwritten bot "Shooter". Goes to rapprochement. If he shoots something out of a crossbow, he shoots. If you shoot poison and the enemy is not poisoned, use poison. If finishes with a knife, applies a knife.
Handwritten bot "Tower". Do not go to rapprochement. If he shoots something out of a crossbow, he shoots. If you shoot poison and the enemy is not poisoned, use poison. If finishes with a knife, applies a knife.
And leave the neural network to fight them at night. For more smoothing of the utility function, I will set more tests (13 pieces) and more ticks in one test (85 instead of 70).
Accordingly, it will now be slower to work, but I think there are more chances to find a good optimum.
10:30 AM I check the quality of network training. -90.96. In the worst case, the metric is equal to -100 (that is, AI and his opponent did equal damage to each other). On average, -81.9231, that is, AI inflicted on 18 damage more.
Let's see how a neural network fights with different types of bots.
1) Gladiator. The initial coordinates are: -9 at the neural network and 10 at the Gladiator. Gladiator goes to a rapprochement, and in the meantime the neural network shoots at emptiness. Accordingly, the neural network is almost all the time with large cooldowns. And ... When the gladiator was at a distance of 9 from the neural network, the cooldown ended, and the neural network is waiting. Do not shoot. The gladiator makes his move, and the neural network immediately poisons him. By the time Gladiator got close to distance 4 to the neural network, her cooldown passed after poisoning. The neural network strikes with a knife into the void ... And the cooldown ends exactly when the gladiator approached the strike distance. Neural network hits the first, and then begins the exchange of blows. 85 cycles do not have time to expire - the neural network killed Gladiator. Gladiator has -18 hp, neural network has 40. The difference is 58 units.
2) Stormtrooper. The initial coordinates are: for neural network 5, for Sturmovik -10. The attack aircraft goes on the attack, and the neural network stands still and waves a knife. As soon as the Stormtrooper was in the area of the poison, the neural network uses poison. And then I notice an error in the attacker code, and all other bots too. Because of this error, they cannot use poison.
However, I see what AI is doing with the Tower bot. Nothing interesting - he just does not fight with him. Apparently, the game from defense is so good that the neural network does not try to oppose this strategy, but simply does not get involved. And the game ends in a draw.
So, at 11:02 am, I refined the strategy of “Sturmovik”, “Shooter” and “Tower” so that they could use the poison, and launched the neural network for training. The quality metric immediately dropped to -107.
At 11:04 there was a first improvement: the metric reached -97.31.
And that's all. The worst result is worse than -100, so at 11:59 I restart the search from scratch.
After the multi-start and primary evolution, the metric was about -133. At the time of 12:06 the metric was already -105.4.
But then the metric grew somehow slowly. I decided to find out what was wrong. Well, of course! The neural network learned to run away even in the interval from -20 to 20. And most of the fights ended in a draw. In several battles, AI could not retreat for any reason, and there its effectiveness ranged from -53 (breaks the enemy's enemy) to -108 (moderate defeat).
Reduce the size of the battlefield. Let it be a segment from -10 to +10. And we will also give a reward to anyone who can hold the center - 1 point in one move of retention. The number of points per center for the neural network is added to the metric for the battle, and the number of center points for the enemy is subtracted.
And I start training from scratch at 16:06. After a multi-start and primary evolution, I get the quality -126.
At 9:44 the next day I get the quality -100.81. That is, the bot wins on average, but sometimes loses. We look at how much he scored in various tests.
-45 -98 -108 -99 -100 -76 -104 -100 -105 -99 -96
3 losses, 2 draws and 6 wins. Let's see what these situations are, where the neural network loses.
Battle number 3, the most losing. The initial coordinates of the neural network and the enemy are -9 and 9. Health is 80 each, the enemy's strategy is Sturmovik.
At first, the neural network shoots at emptiness, then it waits for the Stormtrooper to reach the poisoning distance, the fighters exchange poisonings (the neural network shoots earlier, therefore it is 5 hp ahead of the enemy. I did not understand why 5, not 2), then the neural network starts already in the usual manner of waving a knife in anticipation of the enemy, as a result, the Sturmovik is the first to reach the near line of firing from a crossbow and shoots a neural network. This shot was fatal. Total, at Sturmovik 5 hp, at a neural network 0. Plus the Sturmovik received 3 points for passing the center.
-104 points net knocked out in the 7th battle. The coordinates of the neural network and the enemy were -6 and 9, respectively, each has 400 hp, the enemy's strategy is the shooter.
The shooter is on the offensive, and in the meantime the neural network is waving a knife. As a result, the neural network misses the optimal moment for the shot, and the enemy intercepts the initiative. A long skirmish follows, and the Shooter manages to make one shot more than a neural network. A shot from a crossbow at a far distance shoots just 4 HP.
-105 points network knocked out in the 9th battle. The coordinates of the neural network and the enemy were -1 and 9, respectively, the neural network had 140 hp, the enemy had 40, the enemy's strategy was Stormtrooper. A neural network waits with a knife while waiting and skips the optimal moment for applying poison. Stormtrooper first lets poison. As a result, he inflicted 5 damage more than a neural network.
First, the neural network does not attack, but sits on the defensive, and secondly, it expects in a non-optimal way, instead of pressing the “wait” button, presses the “hit” button.
With the strategy of "tower" neural network fights only if they are already at a distance of a shot. The “gladiator” strategy of a neural network is breaking apart: -45 and -76 are stuffed exactly on it. The “attack” and “shooter” strategies of the neuronet win due to the fact that it shoots first and gains an advantage either in poison or in the number of shots.
Well, even this AI is studying for a long time. And the rest ... Actually, this is an AI that makes discrete decisions, and it works rather than not.
When I told this AI to a friend who had just returned from the army, he was very surprised at my quality metric. Shooting retreating, he said - a bad decision. It is better to have AI consider damage to the enemy to be more important than saving your hp.
Make it bloodthirsty!
That is, fix it:
On this:
Then the metric penalizes us for 1 for taking a unit of damage and awards for 2 for causing one unit.
We start training from scratch. During the time that passed before the idea to create a berserker, I managed to change the processor to a more powerful one and write a faster implementation of neural networks, so all the training took only 20 minutes. 20 minutes - and the quality metric is -65 ... Just how to understand from this metric How realistic is AI?
Return a non-berserker metric
And we are terrified. The “cautious” metric is -117, in many battles AI removed less hp than it lost. AI turned out to be too bloodthirsty - I completely forgot about my HP.
Change the metric to
And we continue training.
Five minutes later we see the result: q = -75.75.
Results for individual trials:
0 -91.2000 -76.3000 -49.300 -49.500 -29.5000 -87.200 -73.600 -64.00 -57.00 -82.0000
Again we change the metric to “cautious” and look at the result.
Q = -114.98. Of the 11 battles AI loses.
We select such a value of the coefficient of aggressiveness, so that AI sees one defeat in itself, that is, that one of the 11 fights ends with a score of less than -100. I want to do this, on the one hand, to continue to encourage AI to play from attack, and on the other, that AI has about the same understanding of victories and defeats as I have. Biologically speaking, I am now setting up an AI evolutionary trajectory.
So, with the coefficient of aggressiveness 1.18, the AI already understands that he sometimes loses, but still does not understand how often.
We continue training.
Half an hour later we reach q = -96.
Returning the “cautious” metric, we get q = -106.23
We look at how many points the AI got in which fight.
-44 -94 -119 -99 -110 -75 -104 -96 -95 -93 -96
Lost: 3 fights. Won: 8 fights. Draws: 0. This is better than 3 losses, 2 draws and 6 wins, which turned out to be in the test without aggressiveness.
Let's see how our AI won in the 3rd since the end of the battle - then he lost without aggression.
The type of enemy in this battle - Stormtrooper. Initially, the fighters approach each other, ignoring the opportunity to shoot from a crossbow at a long distance. Then they poison each other as soon as possible (AI does it earlier, and wins the unit x by this). The AI then fires a crossbow (long range, with a penalty), and the Stormtrooper attacks melee. By the time the Stormtrooper was at a distance of the aimed shot (5 steps), the AI had already reloaded and was shooting again. The attack aircraft did not survive this.
Let's see how our AI loses. We start the fight number 3. The enemy - again Sturmovik.
Like last time, the enemies converge at a distance of a poison shot, but this time the Attackman was able to shoot first and gain an advantage of 1 hp (error number 1). Further fighters continue to converge and firefight on crossbows begins. AI hurried, and the first projectile fired before the enemy was in the target fire zone (error number 2). He inflicted damage a little earlier, but the Stormtrooper took a step forward and inflicted 10 damage instead of 4. During the further exchange of fire, the Stormtrooper successfully killed the AI.
From this experiment, I draw the following conclusions:
1) The way to create an AI, which is suitable for creating an autopilot, is also suitable for creating a combat robot.
2) Sometimes, in order for AI to achieve a given goal, he needs to name a more achievable goal, and then gradually substitute the goal for the one we want to achieve.
3) Optimize step function is much harder than smooth.
4) 3 layers of 11 neurons - this is enough to control the robot, which has 7 sensors and 6 outputs. Usually 33 neurons are not enough for tasks of a similar dimension.
Neural network configuration file . Unfortunately, I lost that file with a well-winning AI, but this one plays just as well.
If you wish, you can play against AI - in this case you need to uncomment the line in Test Seria:
input = [- 3., 9., 80.80.0];% Player 2 is a human
In this game, two guys are fighting like this:
They are located on the coordinate axis, have a certain amount of health, and they also have the parameter "cooldown". Cooldown - this is how many tacts the fighter will miss due to the fact that he performed this action. For example, the action “go” causes cooldown 2, and the action “stabbing” causes cooldown 4. You can act only when the cooldown has dropped to zero (it decreases every turn by one if it is not yet zero).
So, there are two fighters. Everyone has a coordinate, health and cooldown:
')
Each of the fighters in his turn can perform one of 6 actions:
1) Go right at 1 (causes cooldown 2)
2) Go left at 1 (causes cooldown 2)
3) Wait (calls cooldown 1)
4) Strike with a knife (causes cooldown 4, deals 20 damage if the distance to the enemy is no more than 1)
5) Shot from crossbow (causes cooldown 10; at a distance of 5 cells deals 10 damage; up to 12 cells deals 4 damage)
6) Poisoning (causes cooldown 10; at a distance of up to 8 cells, deals 2 damage and poisons. A poisoned enemy loses 1 hp each turn. Poisoning continues until the end of the battle, it cannot be poisoned twice)
At the entrance, each fighter receives information: x, hp and the state is poisoned / not poisoned about himself and his opponent. In addition, the value comes cooldown opponent. At the exit of each strategy gives a number from 1 to 6.
In the case when the strategy is implemented by a neural network, it produces 6 numbers, each of which means “as far as I want this option to be realized”. For example, if the neural network issued 0 0 1 0 -1 0, this means that it selects action 3, since the 3rd element of the sequence has the highest value.
One fight lasts 70 bars (or until one soldier kills another, if it happens earlier). 70 measures is 7 shots or 35 steps.
We will determine the quality metric for the AI fighter. We assume that the quality of the neural network game in one battle = -100 - (how much health we have lost) + (how much the enemy has lost health). Minus hundred is needed because my optimizer maximizes well only negative values.
q = -100- (input (3) -units (1) .hp) + (input (4) -units (2) .hp);
The parameters of this strategy will be the weights and shifts in the neural network - the test of our AI looks like this: a set of weights is loaded into a neural network, this neural network is fought for a while by the enemy, then it receives a quality assessment. The optimizer analyzes the resulting quality, generates a new set of scales (presumably, giving the best quality), and the cycle repeats.
An important element of this game is the stepwise dependence of the quality metric on the neural network coefficients.
Why is that? Because, let's say, the neural network produced the following output vector: 0 0 1 0 0 0. And then we slightly changed one of any parameters. And we got such an output vector: 0 0 0.9 0 0 0. Or 0.1-0.1 0.9 0 0 -0.1. At the same time, the neural network, as it voted for the third option, continues to vote for it.
That is, optimization methods based on small changes (gradient descent, for example) will not work here.
The quality of AI according to the result of a series of battles will be considered as the average quality for all battles plus the worst quality divided by two.
q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.00001;%sum(abs(k)) – . , – . Why take the worst? Then, so that the neural network did not learn how to play perfectly in one rare case, playing poorly in all the others, and did not get a bunch of points for it “on average”. Why take an average? Then, the more choices a neural network participates in evaluating, the more it is:
It looks like this:
And the second option is much easier to optimize using small changes than the first.
We carry out a series of tests. The quality metric is stuck at around -100. That is, AI did not fight. So what? Learning to run is much easier than learning to win.
We introduce a restriction. Whenever our fighter goes beyond the arena (from -20 to 20 to x), he dies. The order "not one step back" in action.
Yes, and discuss the strategy of handwritten bots, of which there are several.
Handwritten bot "Gladiator". Goes to rapprochement. If it reaches the enemy with a knife, it hits. It shoots only if it sees that it will kill the enemy with one shot (which almost never happens).
AI began to win more often than lose, after 15 minutes of training (metric: -95.6). A minute later, he improved his skill (metric: -88). In another minute, the metric was -77.4. In a minute -76.2.
Check how he wins. We start the fight.
Gladiator has a coordinate of 10, hp = 80, and a neural network has a coordinate of -9, hp = 80.
The gladiator advances, and the neural network stands still and makes knife strikes into the void. As soon as the Gladiator reached the firing line with poison, the neural network shoots. Then, when the cooldown passes, the neural network continues to uselessly wave the knife ... Poison shoots at 8 cells. To pass 8 squares, you need to spend 16 turns. A knife strike is 4 moves. 16 is completely divisible by 4. This means that when a gladiator approaches the neural network at close range, she strikes with a knife earlier than the Gladiator. In fact, AI used the knife strike cooldown as a timer. Now the ratio of health - 80:34 is not in favor of the Gladiator. If a neuronet fired a crossbow (which would seem more reasonable than stabbing in the air), it would have missed the chance of a first strike.
The time expired when the score was 45: 5 in favor of the neural network.
Create a few new handwritten bots.
Handwritten bot "Sturmovik." Goes to rapprochement. If it hits with poison, and the enemy is not poisoned yet, applies poison. If you shoot from a crossbow at a short distance (5 units), it shoots. If the opponent has approached the stop, apply the knife.
Handwritten bot "Shooter". Goes to rapprochement. If he shoots something out of a crossbow, he shoots. If you shoot poison and the enemy is not poisoned, use poison. If finishes with a knife, applies a knife.
Handwritten bot "Tower". Do not go to rapprochement. If he shoots something out of a crossbow, he shoots. If you shoot poison and the enemy is not poisoned, use poison. If finishes with a knife, applies a knife.
And leave the neural network to fight them at night. For more smoothing of the utility function, I will set more tests (13 pieces) and more ticks in one test (85 instead of 70).
Accordingly, it will now be slower to work, but I think there are more chances to find a good optimum.
10:30 AM I check the quality of network training. -90.96. In the worst case, the metric is equal to -100 (that is, AI and his opponent did equal damage to each other). On average, -81.9231, that is, AI inflicted on 18 damage more.
Let's see how a neural network fights with different types of bots.
1) Gladiator. The initial coordinates are: -9 at the neural network and 10 at the Gladiator. Gladiator goes to a rapprochement, and in the meantime the neural network shoots at emptiness. Accordingly, the neural network is almost all the time with large cooldowns. And ... When the gladiator was at a distance of 9 from the neural network, the cooldown ended, and the neural network is waiting. Do not shoot. The gladiator makes his move, and the neural network immediately poisons him. By the time Gladiator got close to distance 4 to the neural network, her cooldown passed after poisoning. The neural network strikes with a knife into the void ... And the cooldown ends exactly when the gladiator approached the strike distance. Neural network hits the first, and then begins the exchange of blows. 85 cycles do not have time to expire - the neural network killed Gladiator. Gladiator has -18 hp, neural network has 40. The difference is 58 units.
2) Stormtrooper. The initial coordinates are: for neural network 5, for Sturmovik -10. The attack aircraft goes on the attack, and the neural network stands still and waves a knife. As soon as the Stormtrooper was in the area of the poison, the neural network uses poison. And then I notice an error in the attacker code, and all other bots too. Because of this error, they cannot use poison.
However, I see what AI is doing with the Tower bot. Nothing interesting - he just does not fight with him. Apparently, the game from defense is so good that the neural network does not try to oppose this strategy, but simply does not get involved. And the game ends in a draw.
So, at 11:02 am, I refined the strategy of “Sturmovik”, “Shooter” and “Tower” so that they could use the poison, and launched the neural network for training. The quality metric immediately dropped to -107.
At 11:04 there was a first improvement: the metric reached -97.31.
And that's all. The worst result is worse than -100, so at 11:59 I restart the search from scratch.
After the multi-start and primary evolution, the metric was about -133. At the time of 12:06 the metric was already -105.4.
But then the metric grew somehow slowly. I decided to find out what was wrong. Well, of course! The neural network learned to run away even in the interval from -20 to 20. And most of the fights ended in a draw. In several battles, AI could not retreat for any reason, and there its effectiveness ranged from -53 (breaks the enemy's enemy) to -108 (moderate defeat).
Reduce the size of the battlefield. Let it be a segment from -10 to +10. And we will also give a reward to anyone who can hold the center - 1 point in one move of retention. The number of points per center for the neural network is added to the metric for the battle, and the number of center points for the enemy is subtracted.
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp)+(center.me-center.enemy); And I start training from scratch at 16:06. After a multi-start and primary evolution, I get the quality -126.
At 9:44 the next day I get the quality -100.81. That is, the bot wins on average, but sometimes loses. We look at how much he scored in various tests.
-45 -98 -108 -99 -100 -76 -104 -100 -105 -99 -96
3 losses, 2 draws and 6 wins. Let's see what these situations are, where the neural network loses.
Battle number 3, the most losing. The initial coordinates of the neural network and the enemy are -9 and 9. Health is 80 each, the enemy's strategy is Sturmovik.
At first, the neural network shoots at emptiness, then it waits for the Stormtrooper to reach the poisoning distance, the fighters exchange poisonings (the neural network shoots earlier, therefore it is 5 hp ahead of the enemy. I did not understand why 5, not 2), then the neural network starts already in the usual manner of waving a knife in anticipation of the enemy, as a result, the Sturmovik is the first to reach the near line of firing from a crossbow and shoots a neural network. This shot was fatal. Total, at Sturmovik 5 hp, at a neural network 0. Plus the Sturmovik received 3 points for passing the center.
-104 points net knocked out in the 7th battle. The coordinates of the neural network and the enemy were -6 and 9, respectively, each has 400 hp, the enemy's strategy is the shooter.
The shooter is on the offensive, and in the meantime the neural network is waving a knife. As a result, the neural network misses the optimal moment for the shot, and the enemy intercepts the initiative. A long skirmish follows, and the Shooter manages to make one shot more than a neural network. A shot from a crossbow at a far distance shoots just 4 HP.
-105 points network knocked out in the 9th battle. The coordinates of the neural network and the enemy were -1 and 9, respectively, the neural network had 140 hp, the enemy had 40, the enemy's strategy was Stormtrooper. A neural network waits with a knife while waiting and skips the optimal moment for applying poison. Stormtrooper first lets poison. As a result, he inflicted 5 damage more than a neural network.
Intermediate conclusions.
First, the neural network does not attack, but sits on the defensive, and secondly, it expects in a non-optimal way, instead of pressing the “wait” button, presses the “hit” button.
With the strategy of "tower" neural network fights only if they are already at a distance of a shot. The “gladiator” strategy of a neural network is breaking apart: -45 and -76 are stuffed exactly on it. The “attack” and “shooter” strategies of the neuronet win due to the fact that it shoots first and gains an advantage either in poison or in the number of shots.
Well, even this AI is studying for a long time. And the rest ... Actually, this is an AI that makes discrete decisions, and it works rather than not.
Neural network berserker
When I told this AI to a friend who had just returned from the army, he was very surprised at my quality metric. Shooting retreating, he said - a bad decision. It is better to have AI consider damage to the enemy to be more important than saving your hp.
Make it bloodthirsty!
That is, fix it:
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp); On this:
q=-100-(input(3)-units(1).hp)+2*(input(4)-units(2).hp); %2 – Then the metric penalizes us for 1 for taking a unit of damage and awards for 2 for causing one unit.
We start training from scratch. During the time that passed before the idea to create a berserker, I managed to change the processor to a more powerful one and write a faster implementation of neural networks, so all the training took only 20 minutes. 20 minutes - and the quality metric is -65 ... Just how to understand from this metric How realistic is AI?
Return a non-berserker metric
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp); And we are terrified. The “cautious” metric is -117, in many battles AI removed less hp than it lost. AI turned out to be too bloodthirsty - I completely forgot about my HP.
Change the metric to
q=-100-(input(3)-units(1).hp)+1.7*(input(4)-units(2).hp); %1.7 – And we continue training.
Five minutes later we see the result: q = -75.75.
Results for individual trials:
0 -91.2000 -76.3000 -49.300 -49.500 -29.5000 -87.200 -73.600 -64.00 -57.00 -82.0000
Again we change the metric to “cautious” and look at the result.
Q = -114.98. Of the 11 battles AI loses.
We select such a value of the coefficient of aggressiveness, so that AI sees one defeat in itself, that is, that one of the 11 fights ends with a score of less than -100. I want to do this, on the one hand, to continue to encourage AI to play from attack, and on the other, that AI has about the same understanding of victories and defeats as I have. Biologically speaking, I am now setting up an AI evolutionary trajectory.
So, with the coefficient of aggressiveness 1.18, the AI already understands that he sometimes loses, but still does not understand how often.
We continue training.
Half an hour later we reach q = -96.
Returning the “cautious” metric, we get q = -106.23
We look at how many points the AI got in which fight.
-44 -94 -119 -99 -110 -75 -104 -96 -95 -93 -96
Lost: 3 fights. Won: 8 fights. Draws: 0. This is better than 3 losses, 2 draws and 6 wins, which turned out to be in the test without aggressiveness.
Let's see how our AI won in the 3rd since the end of the battle - then he lost without aggression.
The type of enemy in this battle - Stormtrooper. Initially, the fighters approach each other, ignoring the opportunity to shoot from a crossbow at a long distance. Then they poison each other as soon as possible (AI does it earlier, and wins the unit x by this). The AI then fires a crossbow (long range, with a penalty), and the Stormtrooper attacks melee. By the time the Stormtrooper was at a distance of the aimed shot (5 steps), the AI had already reloaded and was shooting again. The attack aircraft did not survive this.
Let's see how our AI loses. We start the fight number 3. The enemy - again Sturmovik.
Like last time, the enemies converge at a distance of a poison shot, but this time the Attackman was able to shoot first and gain an advantage of 1 hp (error number 1). Further fighters continue to converge and firefight on crossbows begins. AI hurried, and the first projectile fired before the enemy was in the target fire zone (error number 2). He inflicted damage a little earlier, but the Stormtrooper took a step forward and inflicted 10 damage instead of 4. During the further exchange of fire, the Stormtrooper successfully killed the AI.
findings
From this experiment, I draw the following conclusions:
1) The way to create an AI, which is suitable for creating an autopilot, is also suitable for creating a combat robot.
2) Sometimes, in order for AI to achieve a given goal, he needs to name a more achievable goal, and then gradually substitute the goal for the one we want to achieve.
3) Optimize step function is much harder than smooth.
4) 3 layers of 11 neurons - this is enough to control the robot, which has 7 sensors and 6 outputs. Usually 33 neurons are not enough for tasks of a similar dimension.
Function codes
Function, simulating one fight:
function q = evaluateNN(input_,nn) units=[]; %input_: AI.x, enemy.x, AI.hp, enemy.hp, enemy.strategy units(1).x=input_(1); units(1).hp=input_(3); units(1).cooldown=0; units(1).poisoned=0; units(2).x=input_(2); units(2).hp=input_(4); units(2).cooldown=0; units(2).poisoned=0; me=1; enemy=2; center.me=0; center.enemy=0; for i=1:85 if(units(1).cooldown==0 || units(2).cooldown==0) cooldown=[units(1).cooldown;units(2).cooldown]; [ampl,turn]=min(cooldown); %choose if(turn==me) %me answArr=fastSim(nn,[units(me).x;units(me).hp;units(me).poisoned; units(enemy).x;units(enemy).hp; units(enemy).poisoned;units(enemy).cooldown]); [ampl, action] = max(answArr); else if(turn==enemy) %enemy action=3; if(input_(5)==0)%Human player units(1),units(2) 'Player2: 1: x++, 2: x--, 3: wait, 4: knife, 5: crossbow, 6: poison' action=input('Action number:') end; if(input_(5)==1)%gladiator if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=5 && units(enemy).hp<=10) action=5; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==2)%stormtrooper if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=5) action=5; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==3)%archer if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(abs(units(me).x-units(enemy).x)<=12) action=5; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==4)%tower if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(abs(units(me).x-units(enemy).x)<=12) action=5; else action=3; end; end; end; end; %actions %move if(action==1) if(turn==1) another=2; else another=1; end; if(units(turn).x+1~=units(another).x) units(turn).x=units(turn).x+1; end; units(turn).cooldown=units(turn).cooldown+2; end; if(action==2) if(turn==1) another=2; else another=1; end; if(units(turn).x-1~=units(another).x) units(turn).x=units(turn).x-1; end; units(turn).cooldown=units(turn).cooldown+2; end; if(action==3) %pause units(turn).cooldown=units(turn).cooldown+1; end; %knife if(action==4) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=1) units(another).hp=units(another).hp-20; end; units(turn).cooldown=units(turn).cooldown+4; end; %crossbow if(action==5) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=5) %meely units(another).hp=units(another).hp-10; elseif(abs(units(turn).x-units(another).x)<=12) %long-range units(another).hp=units(another).hp-4; end; units(turn).cooldown=units(turn).cooldown+10; end; %poison if(action==6) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=8) units(another).hp=units(another).hp-2; units(another).poisoned=1; end; units(turn).cooldown=units(turn).cooldown+10; end; else units(1).cooldown=units(1).cooldown-1; units(2).cooldown=units(2).cooldown-1; end; if(units(me).poisoned>0) units(me).hp=units(me).hp-1; end; if(units(enemy).poisoned>0) units(enemy).hp=units(enemy).hp-1; end; if(units(me).hp<=0) break; end; if(units(me).x==0) center.me=center.me+1; end; if(units(enemy).x==0) center.enemy=center.enemy+1; end; if(abs(units(me).x)>=10) units(me).hp=0; break; end; if(units(enemy).hp<=0) break; end; end; q=-100-(input_(3)-units(1).hp)+1.0*(input_(4)-units(2).hp); if(q>0) q=0; end; end The function of conducting a series of battles:
function q = testSeria(k) global nn sum_=0; countOfPoints=0; nnlocal=ktonn(nn,k); arr=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]; %% input=[[-3.,9.,80,80,1];[-2.,8.,10,10,2];[-4.,3.,60,60,4];[-4.,8.,20,20,3];[-2.,9.,15,15,2];[5.,-8.,100,100,4];[-5.,0.,50,50,1];[-5.,4.,80,80,2];[4.,7.,70,100,3];[7.,-6.,10,10,3];[-1.,9.,140,140,3]]; %input=[-3.,9.,80,80,0];%Player 2 is a human sz=size(input); for (i=1:sz(1)) val=evaluateNN(input(i,:),nnlocal); sum_=sum_+val; arr(i)=val; end; countOfPoints=sz(1); q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.001; end The function that executes the neural network:
function arr = fastSim(nn,input) %fast simulation for fast network sz=size(nn.LW); sum=cell([1,sz(1)]); LW=nn.LW; b=nn.b; sum{1}=nn.IW{1}*input; arr=sum{1}; for i=1:sz(1)-1 sum{i+1}=tansig(LW{i+1,i}*(sum{i}+b{i})); end; arr=sum{sz(1)}; end The function that translates a set of numbers into the neural network coefficients is needed to optimize the neural network:
function nn = ktonn(nn,k) %neuro net to array of koefficients ksize=size(k); if(ksize(2)==1) k=k'; end; bsz=size(nn.b); counter=1; for i=1:bsz(1)-1 sz=size(nn.b{i}); nn.b{i}=k(counter:counter+sz(1)-1)'; counter=counter+sz(1); end; lsz=size(nn.LW); for i1=1:(lsz(1)-1) x=i1+1; y=i1; szW=size(nn.LW{x,y}); nn.LW{x,y}=reshape(k(counter:counter+szW(1)*szW(2)-1),szW(1),szW(2)); counter=counter+szW(1)*szW(2); end; sz=size(nn.IW{1}); arr=k(counter:counter+sz(1)*sz(2)-1); arr=reshape(arr,sz(1),sz(2)); nn.IW{1}=arr; end Main.m:
clc; global nn X=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]]; Y=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]]; nnBase=newff(X,Y,[11,11,11],{'tansig' 'tansig' 'tansig'},'trainrp'); nn.b=nnBase.b; nn.IW=nnBase.IW; nn.LW=nnBase.LW; f=load('./conf.mat'); k=f.rtailor; q=testSeria(k) Neural network configuration file . Unfortunately, I lost that file with a well-winning AI, but this one plays just as well.
If you wish, you can play against AI - in this case you need to uncomment the line in Test Seria:
input = [- 3., 9., 80.80.0];% Player 2 is a human
Source: https://habr.com/ru/post/323648/
All Articles