Memory models underlying programming languages
We offer you a translation of an article devoted to the consideration of memory models used in programming.
Today, six main memory models dominate programming (not to be confused with Intel 8086 memory models ). Three of them stem from the three historically most important programming languages of the 1950s — COBOL, LISP, and FORTRAN, and the rest are connected with three historically important data storage systems: tape, hierarchical file system in Unix-style, and a relational database.
These models, at a much deeper level than syntax or even a type system, define what our programming languages can or cannot do. Let's take a closer look at these models, and then discuss some possible alternatives and reasons why they might be interesting.
Each modern programming environment, to one degree or another, uses all six memory models, and this is one of the reasons why our systems are so complex and difficult to understand.
')
Here we will analyze how each of these memory models:
Let's start with a simple programming language that lacks the ability to structure data, since it has no closures and does not contain any other data types except boolean and finite precision numbers. Here is his BNF description with the usual semantics and the usual priority of operations:
An example of converting Fahrenheit to Celsius in this language:
Let's agree that in our programming language recursion is prohibited, and the greedy (eager) computation strategy with call-by-value is used. We also agree that all variables are implicitly local and initialized with zeros when calling subroutines. Thus, no subroutine can have any side effects. In this form, our programming language is applicable only to the programming of finite automata. If you compile such a program under a real processor with registers, then each variable encountered in the program text can be assigned one register. Each subroutine can also be assigned a register for the return address. In addition, you will need another register for the team counter. Running the program in this language on a machine with gigabytes of RAM will not give any benefit. She can never use more variables than she did at the beginning.
It does not make such a language useless. There are many useful calculations that can be done in tight spaces. But it really does not allow to fully use its abstract power, even for such calculations.
To access additional memory, you can use the peek () and poke () functions to read or write one byte to the specified address. Thus, one would really use memory effectively:
However, many programming languages do not even provide peek () and poke (). Instead, they provide a certain structure on top of an ascetic uniform byte array.
For example, even when programming finite automata, nested records, arrays, and unions already provide tremendous benefits.
In COBOL, a data object is either something indivisible:
(Here we have significantly deviated from the terminology and taxonomy of COBOL, in order to simplify the understanding of what this language offers).
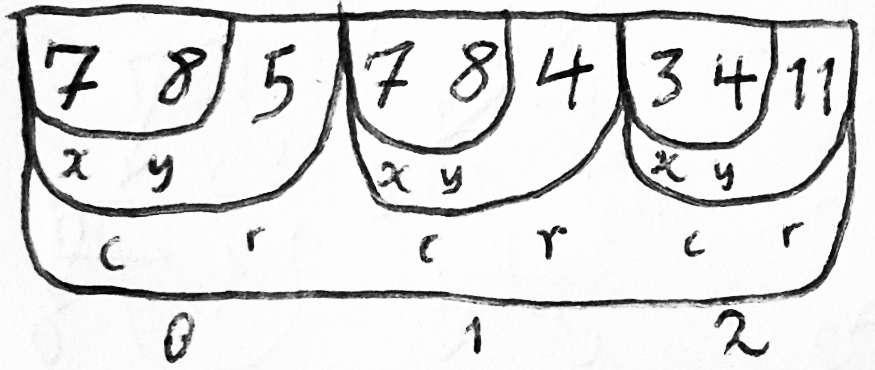
In such a memory model, if you have several similar entities, then each of them will have a record of the same type (both in size and in subfields) intended for storing information. Thus, all information about this entity will be located in memory sequentially. You can very easily download and store these pieces of related data on a disk, tape, punch cards or any other storage media. If several of these entries are in memory at the same time, they can be put into an array.
Any attribute of an entity is defined by two bytes representing the beginning and end offset of this attribute relative to the base address of the record storing the data of this entity. For example, the Account object may have the Owner field, which occupies bytes from 10 to 35, within which from 18 to 26 bytes the account holder’s middle name will be stored.
About this approach, you can make some interesting comments.
There are no pointers at all. This means that there is no way to make a dynamic allocation of memory, you can’t dereference a null pointer, don’t overwrite a memory area using a dangling pointer (although if two variables are declared as REDEFINES, then of course they can wipe each other and avoid Tagged unions can help with this problem, no memory shortage, no overlap, and no memory consumption on pointers.
On the other hand, it also means that every data structure in your program has a strict limit, and the only way to use the same memory for different things at different times is to risk using them at the same time.
Nested records are very economical with memory. You need to keep in memory only the data of those entities with which you are working at the moment. This means that you can successfully process megabytes of data on a machine with kilobytes of memory, as COBOL programmers did in the 1950s.
Each piece of data (fields, subfields, etc.) has one unique parent (with the exception of the highest level), which immediately contains all the child data.
In this memory model, if one part of the program has its own memory (for example, a stack frame or a static private variable), it can make some entities private by storing their data in this own memory. This is useful if you need to create a local temporary variable and be sure that it will not affect the execution of the rest of the program. However, such a memory model does not allow any part of the program to make the attribute private.
ALGOL (and ALGOL-58 and ALGOL-60) borrowed a record from COBOL as the main, in addition to arrays, data structuring mechanism. And it is from Algol that almost all other programming languages inherited it in one form or another.
The C language has almost the entire set of tools for structuring data: primitive types (char, int, etc.), structures, unions, and arrays. However, C also has pointers and subroutines that not only take arguments, but are recursive, requiring something like a stack allocation. Both of these extensions to the COBOL model come from LISP.
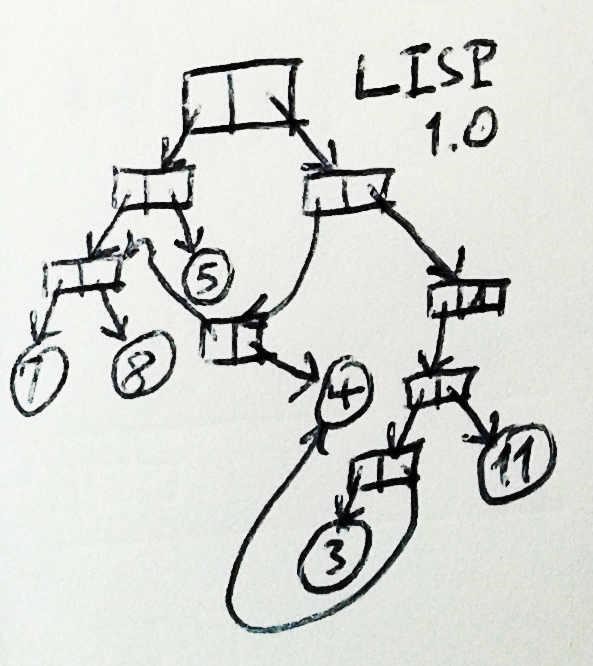
LISP (it is now Lisp, and in 1959 was LISP) could hardly be even more different from COBOL. Not only are there pointers in it, so besides them there is almost nothing left in the LISP. The only mechanism for structuring data in a LISP is something called cons, which consists of two pointers, one of which is called "car" and the other is "cdr". The value of any variable is a pointer. It can be a pointer to cons, or a pointer to a character, or a pointer to a number, or sometimes even a pointer to a subroutine, but this is a pointer.
In addition, there are recursive subroutines with arguments, and because of this, as well as tail recursion optimization, you can write programs that do something without ever changing the value of a variable.
Any object can be referenced by any number of pointers, by means of any of which an object can be modified. Thus, the object does not have a unique parent.
This model is extremely flexible in the sense that it makes it quite easy to write programs for processing natural languages, program interpretation and compilation, brute-force and symbolic computations . It also makes it easy to create a data structure (for example, a red-black tree ) once, and then apply it to many different types of objects. In contrast, COBOL-derived languages such as C have considerable difficulty with this kind of generalization, with the result that programmers have to write a huge amount of repetitive code again and again to implement the same well-known data structures and algorithms for new data types.
At the same time, however, this model does not cope well with memory limitations, is error prone and requires a lot of ingenuity to effectively implement. Since each object is identified only by a pointer, each object can have aliases. Each variable can be a null pointer. Since a pointer can indicate anything, type errors (when a pointer to an object of one type is stored in a variable that is expected to point to some other type) are ubiquitous, and object-graph languages traditionally use checks to shorten the debugging time. types at runtime.
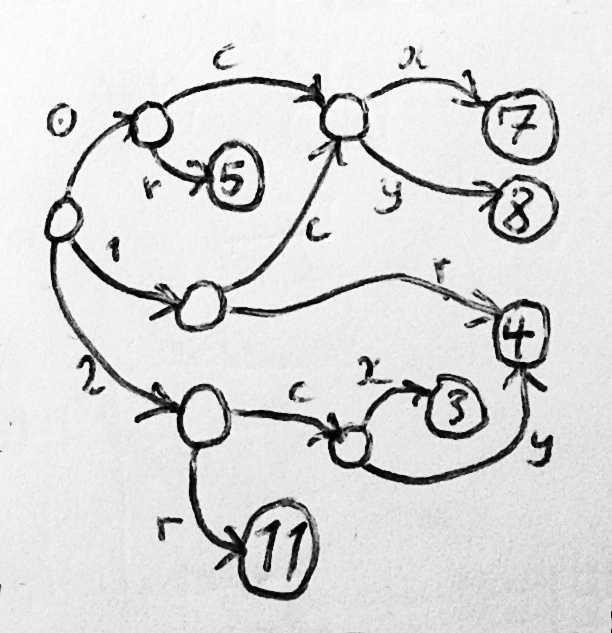
In this object-graph memory model, if you have several objects of the same type, each of them will be identified by a pointer, and finding a specific attribute of an object includes navigating through the object graph, starting with this pointer. For example, if you have an Account object, then you can present it as an associative list. Then, to find its owner (an object that can be shared with other objects of accounts), you go through the list until you find a cons, whose car will be ACCOUNT-HOLDER, and take its cdr. Then, in order to find the middle name of the account holder, you may be looking for the attributes of the account holder in the vector, you get a pointer to the corresponding name, which can be either a string or a character, as in old Lisp, which has no lines. Updating the second name may include changing this line, updating the vector to point to a new line, or building a new associative list with a new account holder object, depending on whether this owner object is used with other account objects, and whether it is desirable other accounts to update the middle name too.
Garbage collection is almost a necessity in these languages. Beginning in 1959, when McCarthy created Lisp, and until 1980, when Lieberman and Hewitt came up with the use of generations for garbage collection, programs using this memory model spent between a third and a half of their work on garbage collection. Some computers were even specially created with several processors so that the garbage collector could be run on a separate processor.
Object-graph languages made high demands on garbage collectors, not only because they prefer to create new objects rather than modify existing ones, but also because they usually have many pointers. In COBOL-derived languages, such as C and Golang, it is easier for garbage collectors to work because less large memory operations are performed there; these languages tend to modify objects instead of re-allocating memory for modified versions. And programmers, as a rule, try to use nested records where possible, rather than linking them with pointers, so pointers are found only where polymorphism is desirable, the validity of null pointers (which can be considered as a special case of polymorphism) or overlay.
Serialization of an object graph is a bit more complicated because it may contain circular references, and also because the part you want to serialize may contain links to parts that you do not want to serialize, and you should consider both cases as specific cases. For example, on some systems, an instance of a class contains a reference to its class, and a class contains references not only to the current versions of all methods, but also to the parent class. And you may not want to serialize the entire bytecode of the class with each object serialization. In addition, when you deserialize two objects that previously had common links (two accounts for the same account holder), then you probably want to keep sharing them. In general, the specific policy on this issue may vary depending on the purpose for which you are serializing data.
Like a memory model with nested entries, an object graph model allows you to make all attributes of a particular entity local to a specific part of your program — you simply do not give any references to its data structure for the rest of the program — but it does not allow you to make a particular attribute private. all entities. However, unlike the memory model with nested records, the object graph model reduces the dependence on the memory size of any node, which opens the door to object-oriented inheritance and allows you to make attributes private, despite some serious problems.
This model is used by the most popular programming languages today. Not only the current Lisps, but also Haskell, ML, Python, Ruby, PHP5, Lua, JavaScript, Erlang and Smalltalk. They all expanded the set of object types that exist in memory outside of a simple pair; as a rule, they include arrays of pointers and hash tables of strings, or pointers to other pointers. Some of them also include Tagged unions and unchangeable entries. Hash tables, in particular, offer a kind of way to add new properties of existing objects, in most cases without affecting other code that uses these objects.

In general, in these languages you can only follow the edges of the graph in the direction that they indicate, and the edge labels must be unique within the source node (cons has only one car, not two and not ten), but not node- destination. Ted Nelson's ZigZag data structure is a study of the situation where you require them to be unique in both source and destination. UnQL is, in a sense, a study that completely eliminates uniqueness.
Java (and C #) use a slightly modified version of this memory model: in Java, for example, there are things like “primitive types” that are not pointers.
Fortran was developed for the numerical simulation of physical phenomena, the so-called “scientific calculations”, which was one of the earliest applications of computers. At that time, scientific computers differed from "business computers" in COBOL with a number of features: they used binary numbers instead of decimals; they had no data type byte - just a word; they supported floating point math operations; and they had faster computation and slower I / O.

As a rule, such modeling implied a lot of linear algebra with large arrays of numbers that should be processed as soon as possible. And FORTRAN was optimized just for this - for the effective use of multidimensional arrays. In FORTRAN not only there were no recursive subroutines, pointers and records, at first there were no subroutines in it at all!
When subroutines appeared in it, they had parameters that could be arrays. In Algol 60, it was never really implemented. Since arrays were the only non-primitive types, the only possible element types for arrays were primitive types, such as integers or floating-point numbers.

In the memory model of parallel arrays that has evolved in the FORTRAN environment, if you have several objects of the same type, then each of them will be identified by a numerical offset, which is valid for several arrays. And the search for the private attribute of a particular object includes the indexing of the array for this attribute with the index of such an object. If you move a little bit away from the 1950s and allow yourself a primitive type of symbol from which you can form arrays, sticking to parallel arrays for structuring data, you can determine the second name of the account holder from the previous example as follows:
In this memory model, the subroutine can access any index in the array that was passed as an argument or is available to it in some other way, read or write it any number of times in a random order.
This is exactly what the phrase “FORTRAN can write in any language” means: there are arrays of primitive types in almost any programming language. Even in assembler or Forth, it is easy to make arrays. Awk, Perl4, and Tcl also provide dictionaries that are not first-class objects, since these are not object-graph languages, although they work well instead of arrays to store object attributes, allowing you to identify objects by strings instead of integers.
Interestingly, at the machine level, in the simple case, parallel arrays generate almost the same code as the structural elements that reference via pointers, as in the nested model. For example, here
In both cases, we add an immediate constant representing the attribute we need to a variable in the register that indicates which object we are considering. In the second case, the difference is that we multiply the index by the size of the element, and the immediate constant is slightly larger.
( , , , , ).
. . , , , .
, cache-friendly, , , , ( — , ). , , , : sum covariance, .
: , .
, . , , , . , (type error) — , — . (, ). , , , , ( ), , (nested-record model).
, , , , .
FORTRAN — , . Octave, Matlab, APL, J, K, PV-WAVE IDL, Lush, S, S-Plus R . Numpy, Pandas OpenGL — «» , Perl4, awk, Tcl, , - . , . Pandas, K - (parallel-dictionary variant) , .
: CPU , GPU SIMT-, CPU SIMD- ALU . , «, » (data-oriented design) ( ) « » (entity systems). , «» .
: (record), . , , :
Lua Erlang - . Forth . , , - -- , . -- Linda, .
.
Unix — ( ). , — (, , ), , , ( ). ( , ). , .
, . MapReduce , lex, , .
Python, (forward iterators) C++ STL, (forward ranges) D, Golang — , .
, ? (, ) . . empty, get, ``put, , , Python - :
, , . , . , . in1, out .. - , . ( Unix- Unix-: ). , , .
(multithreaded) (control flow system), (threads), , (empty streams block), . ; , . , , .
- (π-calculus) — , . , (concurrent) - (channel-oriented) λ-. :
-:
«» , incr , , +1 . , «». 17 incr, , , y.
-, , , , . , (labeled graphs)! , .
« », NSA, Apache NiFi, Unix---.
Unix ( Windows, MacOS, Multics) — , , shell-. - , — , «» - , « », ( ). , « », — .
() , ! , , , , . , () «» «». Unix , , , , .
— . , , , , , . , , .
.
, . - MUMPS, ( «» 4096 , «», « »). IBM IMS, , , «». . (Mark Lentczner) , - , Wheat. - PHP. Wheat «» «» ( , ). « » , . . Wheat , , - .
, .
« » «» «». cos — : θ cos(θ) . Cos-1 — : cos⁻¹(0.5) , , - . cos , : (0, 1), (π/2, 0), (π, -1), (3π/2, 0) . — : (1, 0), (0, π/2), (-1, π), (0, 3π/2) .
, , , , : n- n. , : (0, 1, 0), (π/2, 0, 1), (π, -1, 0) ..
cos, .
, , , permissions.sqlite Firefox:
, , id ; host(1) addons.mozilla.org, host(2) getpersonas.com, type(5) sts/use. -.
. , host(9), host⁻¹('news.ycombinator.com'), :
, :
, SQL, («» «»), , , id . - . :
, , , - .
SQL — , . .
Lisp, FORTRAN C, SQL , . , . SQL-, , , , (, - PL/SQL).
. , , .
SQL - : , ( , , ); ( , , COBOL). .
SQL, , :
, SQL : / (unmanageable) . SQL:
- :
iota :
sort_by_int_column :
SQL- , , , . , .
, SQL — , , , . , , — , , , , . , , .
Prolog miniKANREN, . miniKANREN , , .
(constraint programming), («», ), . , , , SAT SMT.
Today, six main memory models dominate programming (not to be confused with Intel 8086 memory models ). Three of them stem from the three historically most important programming languages of the 1950s — COBOL, LISP, and FORTRAN, and the rest are connected with three historically important data storage systems: tape, hierarchical file system in Unix-style, and a relational database.
These models, at a much deeper level than syntax or even a type system, define what our programming languages can or cannot do. Let's take a closer look at these models, and then discuss some possible alternatives and reasons why they might be interesting.
Introduction
Each modern programming environment, to one degree or another, uses all six memory models, and this is one of the reasons why our systems are so complex and difficult to understand.
')
Here we will analyze how each of these memory models:
- represents entity attributes,
- interacts with serialization,
- implements and maintains the modularity of programs, limiting access to certain aspects, making them local or private.
Prolog: programs with atomic variables only
Let's start with a simple programming language that lacks the ability to structure data, since it has no closures and does not contain any other data types except boolean and finite precision numbers. Here is his BNF description with the usual semantics and the usual priority of operations:
program ::= def* def ::= "def" name "(" args ")" block args ::= "" | name "," args block ::= "{" statement* "}" statement ::= "return" exp ";" | name ":=" exp ";" | exp ";" | nest nest ::= "if" exp block | "if" exp block "else" block | "while" exp block exp ::= name | num | exp op exp | exp "(" exps ")" | "(" exp ")" | unop exp exps ::= "" | exp "," exps unop ::= "!" | "-" | "~" op ::= logical | comparison | "+" | "*" | "-" | "/" | "%" logical ::= "||" | "&&" | "&" | "|" | "^" | "<<" | ">>" comparison ::= "==" | "<" | ">" | "<=" | ">=" | "!=" An example of converting Fahrenheit to Celsius in this language:
def f2c(f) { return (f — 32) * 5 / 9; } def main() { say(f2c(-40)); say(f2c(32)); say(f2c(98.6)); say(f2c(212)); } Let's agree that in our programming language recursion is prohibited, and the greedy (eager) computation strategy with call-by-value is used. We also agree that all variables are implicitly local and initialized with zeros when calling subroutines. Thus, no subroutine can have any side effects. In this form, our programming language is applicable only to the programming of finite automata. If you compile such a program under a real processor with registers, then each variable encountered in the program text can be assigned one register. Each subroutine can also be assigned a register for the return address. In addition, you will need another register for the team counter. Running the program in this language on a machine with gigabytes of RAM will not give any benefit. She can never use more variables than she did at the beginning.
It does not make such a language useless. There are many useful calculations that can be done in tight spaces. But it really does not allow to fully use its abstract power, even for such calculations.
To access additional memory, you can use the peek () and poke () functions to read or write one byte to the specified address. Thus, one would really use memory effectively:
def strcpy(d, s, n) { while n > 0 { poke(d + n, peek(s + n)); n := n — 1; } } However, many programming languages do not even provide peek () and poke (). Instead, they provide a certain structure on top of an ascetic uniform byte array.
For example, even when programming finite automata, nested records, arrays, and unions already provide tremendous benefits.
COBOL Nesting Entries and Memory Model: Memory as Income Declaration
In COBOL, a data object is either something indivisible:
- foundational object of the type of string or number of a certain size,
- or a collection of objects, such as:
- recording (objects of various types, stored side by side one after another);
- association (alternative objects that are stored, occupying the same place);
- or an array (a certain number of objects of the same type, stored side by side one after another).
(Here we have significantly deviated from the terminology and taxonomy of COBOL, in order to simplify the understanding of what this language offers).
In such a memory model, if you have several similar entities, then each of them will have a record of the same type (both in size and in subfields) intended for storing information. Thus, all information about this entity will be located in memory sequentially. You can very easily download and store these pieces of related data on a disk, tape, punch cards or any other storage media. If several of these entries are in memory at the same time, they can be put into an array.
Any attribute of an entity is defined by two bytes representing the beginning and end offset of this attribute relative to the base address of the record storing the data of this entity. For example, the Account object may have the Owner field, which occupies bytes from 10 to 35, within which from 18 to 26 bytes the account holder’s middle name will be stored.
About this approach, you can make some interesting comments.
There are no pointers at all. This means that there is no way to make a dynamic allocation of memory, you can’t dereference a null pointer, don’t overwrite a memory area using a dangling pointer (although if two variables are declared as REDEFINES, then of course they can wipe each other and avoid Tagged unions can help with this problem, no memory shortage, no overlap, and no memory consumption on pointers.
On the other hand, it also means that every data structure in your program has a strict limit, and the only way to use the same memory for different things at different times is to risk using them at the same time.
Nested records are very economical with memory. You need to keep in memory only the data of those entities with which you are working at the moment. This means that you can successfully process megabytes of data on a machine with kilobytes of memory, as COBOL programmers did in the 1950s.
Each piece of data (fields, subfields, etc.) has one unique parent (with the exception of the highest level), which immediately contains all the child data.
In this memory model, if one part of the program has its own memory (for example, a stack frame or a static private variable), it can make some entities private by storing their data in this own memory. This is useful if you need to create a local temporary variable and be sure that it will not affect the execution of the rest of the program. However, such a memory model does not allow any part of the program to make the attribute private.
ALGOL (and ALGOL-58 and ALGOL-60) borrowed a record from COBOL as the main, in addition to arrays, data structuring mechanism. And it is from Algol that almost all other programming languages inherited it in one form or another.
The C language has almost the entire set of tools for structuring data: primitive types (char, int, etc.), structures, unions, and arrays. However, C also has pointers and subroutines that not only take arguments, but are recursive, requiring something like a stack allocation. Both of these extensions to the COBOL model come from LISP.
Object Graphs and LISP Memory Model: Memory as a Marked Oriented Graph
LISP (it is now Lisp, and in 1959 was LISP) could hardly be even more different from COBOL. Not only are there pointers in it, so besides them there is almost nothing left in the LISP. The only mechanism for structuring data in a LISP is something called cons, which consists of two pointers, one of which is called "car" and the other is "cdr". The value of any variable is a pointer. It can be a pointer to cons, or a pointer to a character, or a pointer to a number, or sometimes even a pointer to a subroutine, but this is a pointer.
In addition, there are recursive subroutines with arguments, and because of this, as well as tail recursion optimization, you can write programs that do something without ever changing the value of a variable.
Any object can be referenced by any number of pointers, by means of any of which an object can be modified. Thus, the object does not have a unique parent.
This model is extremely flexible in the sense that it makes it quite easy to write programs for processing natural languages, program interpretation and compilation, brute-force and symbolic computations . It also makes it easy to create a data structure (for example, a red-black tree ) once, and then apply it to many different types of objects. In contrast, COBOL-derived languages such as C have considerable difficulty with this kind of generalization, with the result that programmers have to write a huge amount of repetitive code again and again to implement the same well-known data structures and algorithms for new data types.
At the same time, however, this model does not cope well with memory limitations, is error prone and requires a lot of ingenuity to effectively implement. Since each object is identified only by a pointer, each object can have aliases. Each variable can be a null pointer. Since a pointer can indicate anything, type errors (when a pointer to an object of one type is stored in a variable that is expected to point to some other type) are ubiquitous, and object-graph languages traditionally use checks to shorten the debugging time. types at runtime.
In this object-graph memory model, if you have several objects of the same type, each of them will be identified by a pointer, and finding a specific attribute of an object includes navigating through the object graph, starting with this pointer. For example, if you have an Account object, then you can present it as an associative list. Then, to find its owner (an object that can be shared with other objects of accounts), you go through the list until you find a cons, whose car will be ACCOUNT-HOLDER, and take its cdr. Then, in order to find the middle name of the account holder, you may be looking for the attributes of the account holder in the vector, you get a pointer to the corresponding name, which can be either a string or a character, as in old Lisp, which has no lines. Updating the second name may include changing this line, updating the vector to point to a new line, or building a new associative list with a new account holder object, depending on whether this owner object is used with other account objects, and whether it is desirable other accounts to update the middle name too.
Garbage collection is almost a necessity in these languages. Beginning in 1959, when McCarthy created Lisp, and until 1980, when Lieberman and Hewitt came up with the use of generations for garbage collection, programs using this memory model spent between a third and a half of their work on garbage collection. Some computers were even specially created with several processors so that the garbage collector could be run on a separate processor.
Object-graph languages made high demands on garbage collectors, not only because they prefer to create new objects rather than modify existing ones, but also because they usually have many pointers. In COBOL-derived languages, such as C and Golang, it is easier for garbage collectors to work because less large memory operations are performed there; these languages tend to modify objects instead of re-allocating memory for modified versions. And programmers, as a rule, try to use nested records where possible, rather than linking them with pointers, so pointers are found only where polymorphism is desirable, the validity of null pointers (which can be considered as a special case of polymorphism) or overlay.
Serialization of an object graph is a bit more complicated because it may contain circular references, and also because the part you want to serialize may contain links to parts that you do not want to serialize, and you should consider both cases as specific cases. For example, on some systems, an instance of a class contains a reference to its class, and a class contains references not only to the current versions of all methods, but also to the parent class. And you may not want to serialize the entire bytecode of the class with each object serialization. In addition, when you deserialize two objects that previously had common links (two accounts for the same account holder), then you probably want to keep sharing them. In general, the specific policy on this issue may vary depending on the purpose for which you are serializing data.
Like a memory model with nested entries, an object graph model allows you to make all attributes of a particular entity local to a specific part of your program — you simply do not give any references to its data structure for the rest of the program — but it does not allow you to make a particular attribute private. all entities. However, unlike the memory model with nested records, the object graph model reduces the dependence on the memory size of any node, which opens the door to object-oriented inheritance and allows you to make attributes private, despite some serious problems.
This model is used by the most popular programming languages today. Not only the current Lisps, but also Haskell, ML, Python, Ruby, PHP5, Lua, JavaScript, Erlang and Smalltalk. They all expanded the set of object types that exist in memory outside of a simple pair; as a rule, they include arrays of pointers and hash tables of strings, or pointers to other pointers. Some of them also include Tagged unions and unchangeable entries. Hash tables, in particular, offer a kind of way to add new properties of existing objects, in most cases without affecting other code that uses these objects.
In general, in these languages you can only follow the edges of the graph in the direction that they indicate, and the edge labels must be unique within the source node (cons has only one car, not two and not ten), but not node- destination. Ted Nelson's ZigZag data structure is a study of the situation where you require them to be unique in both source and destination. UnQL is, in a sense, a study that completely eliminates uniqueness.
Java (and C #) use a slightly modified version of this memory model: in Java, for example, there are things like “primitive types” that are not pointers.
FORTRAN parallel arrays and memory model: memory as a group of arrays
Fortran was developed for the numerical simulation of physical phenomena, the so-called “scientific calculations”, which was one of the earliest applications of computers. At that time, scientific computers differed from "business computers" in COBOL with a number of features: they used binary numbers instead of decimals; they had no data type byte - just a word; they supported floating point math operations; and they had faster computation and slower I / O.
As a rule, such modeling implied a lot of linear algebra with large arrays of numbers that should be processed as soon as possible. And FORTRAN was optimized just for this - for the effective use of multidimensional arrays. In FORTRAN not only there were no recursive subroutines, pointers and records, at first there were no subroutines in it at all!
When subroutines appeared in it, they had parameters that could be arrays. In Algol 60, it was never really implemented. Since arrays were the only non-primitive types, the only possible element types for arrays were primitive types, such as integers or floating-point numbers.
In the memory model of parallel arrays that has evolved in the FORTRAN environment, if you have several objects of the same type, then each of them will be identified by a numerical offset, which is valid for several arrays. And the search for the private attribute of a particular object includes the indexing of the array for this attribute with the index of such an object. If you move a little bit away from the 1950s and allow yourself a primitive type of symbol from which you can form arrays, sticking to parallel arrays for structuring data, you can determine the second name of the account holder from the previous example as follows:
- IM = IMDNAM (ICCHLD (IACCTN))
IA = ISTR (IM)
IE = ISTR (IM + 1)
After these four array indexing operations, the account holder’s second name is in the [IA, IE) characters of the CCHARS array. - IM = IMDNAM (IACCTN), then proceed as in the previous version, if you do not have a separate character set for the account holder attributes.
- Instead of IMDNAM, use CMDNAM, N * 12 character array, with one 12-character column for the second name of each account holder.
In this memory model, the subroutine can access any index in the array that was passed as an argument or is available to it in some other way, read or write it any number of times in a random order.
This is exactly what the phrase “FORTRAN can write in any language” means: there are arrays of primitive types in almost any programming language. Even in assembler or Forth, it is easy to make arrays. Awk, Perl4, and Tcl also provide dictionaries that are not first-class objects, since these are not object-graph languages, although they work well instead of arrays to store object attributes, allowing you to identify objects by strings instead of integers.
Interestingly, at the machine level, in the simple case, parallel arrays generate almost the same code as the structural elements that reference via pointers, as in the nested model. For example, here
b->foo , where b is a pointer to a struct with a 32-bit member foo: 40050c: 8b 47 08 mov 0x8(%rdi),%eax</code> <code>foos[b]</code>, b — foos, 32- : <source>400513: 8b 04 bd e0 d8 60 00 mov 0x60d8e0(,%rdi,4),%eax In both cases, we add an immediate constant representing the attribute we need to a variable in the register that indicates which object we are considering. In the second case, the difference is that we multiply the index by the size of the element, and the immediate constant is slightly larger.
( , , , , ).
. . , , , .
, cache-friendly, , , , ( — , ). , , , : sum covariance, .
: , .
, . , , , . , (type error) — , — . (, ). , , , , ( ), , (nested-record model).
, , , , .
FORTRAN — , . Octave, Matlab, APL, J, K, PV-WAVE IDL, Lush, S, S-Plus R . Numpy, Pandas OpenGL — «» , Perl4, awk, Tcl, , - . , . Pandas, K - (parallel-dictionary variant) , .
: CPU , GPU SIMT-, CPU SIMD- ALU . , «, » (data-oriented design) ( ) « » (entity systems). , «» .
: Lua, Erlang Forth?
: (record), . , , :
- Lua (finite maps) (, «»),
- Erlang , ( , (Hewitt) (Agha)),
- Forth .
Lua Erlang - . Forth . , , - -- , . -- Linda, .
.
Unix — ( ). , — (, , ), , , ( ). ( , ). , .
, . MapReduce , lex, , .
Python, (forward iterators) C++ STL, (forward ranges) D, Golang — , .
, ? (, ) . . empty, get, ``put, , , Python - :
def merge(in1, in2, out) { have1 := 0; have2 := 0; while !empty(in1) || !empty(in2) { if 0 == have1 && !empty(in1) { val1 := get(in1); have1 := 1; } if 0 == have2 && !empty(in2) { val2 := get(in2); have2 := 1; } if 0 == have1 { put(out, val2); have2 := 0; } else { if 0 == have2 || val1 < val2 { put(out, val1); have1 := 0; } else { put(out, val2); have2 := 0; } } } } , , . , . , . in1, out .. - , . ( Unix- Unix-: ). , , .
(multithreaded) (control flow system), (threads), , (empty streams block), . ; , . , , .
- (π-calculus) — , . , (concurrent) - (channel-oriented) λ-. :
Q . :
- P|Q , P Q, ;
- a(x).P , , , , ;
- ā〈x〉.P , , , - , .
- (νa)P , — ;
- ! , ;
- P + Q , P Q;
- 0 , .
-:
!incr(a, x).ā〈x+1〉 | (νa)( i̅n̅c̅r̅〈a, 17〉 | a(y) )«» , incr , , +1 . , «». 17 incr, , , y.
-, , , , . , (labeled graphs)! , .
« », NSA, Apache NiFi, Unix---.
Multics: (string-labeled tree) blob-
Unix ( Windows, MacOS, Multics) — , , shell-. - , — , «» - , « », ( ). , « », — .
() , ! , , , , . , () «» «». Unix , , , , .
— . , , , , , . , , .
.
, . - MUMPS, ( «» 4096 , «», « »). IBM IMS, , , «». . (Mark Lentczner) , - , Wheat. - PHP. Wheat «» «» ( , ). « » , . . Wheat , , - .
SQL: —
, .
« » «» «». cos — : θ cos(θ) . Cos-1 — : cos⁻¹(0.5) , , - . cos , : (0, 1), (π/2, 0), (π, -1), (3π/2, 0) . — : (1, 0), (0, π/2), (-1, π), (0, 3π/2) .
, , , , : n- n. , : (0, 1, 0), (π/2, 0, 1), (π, -1, 0) ..
cos, .
, , , permissions.sqlite Firefox:
sqlite> .mode column sqlite> .width 3 20 10 5 5 15 1 1 sqlite> select * from moz_hosts limit 5; id host type permi expir expireTime ai --- -------------------- ---------- ----- ----- --------------- — - 1 addons.mozilla.org install 1 0 0 2 getpersonas.com install 1 0 0 5 github.com sts/use 1 2 1475110629178 9 news.ycombinator.com sts/use 1 2 1475236009514 10 news.ycombinator.com sts/subd 1 2 1475236009514 , , id ; host(1) addons.mozilla.org, host(2) getpersonas.com, type(5) sts/use. -.
. , host(9), host⁻¹('news.ycombinator.com'), :
sqlite> select id from moz_hosts where host = 'news.ycombinator.com'; id --- 9 10 , :
sqlite> .width 0 sqlite> select min(expireTime) from moz_hosts where host = 'news.ycombinator.com'; min(expireTime) --------------- 1475236009514 , SQL, («» «»), , , id . - . :
select accountholder.middlename from accountholder, account where accountholder.id = account.accountholderid and account.id = 3201 , , , - .
SQL — , . .
Lisp, FORTRAN C, SQL , . , . SQL-, , , , (, - PL/SQL).
. , , .
SQL - : , ( , , ); ( , , COBOL). .
SQL, , :
for (int i = 0; i < moz_hosts_len; i++) { if (0 == strcmp(moz_hosts_host[i], "news.ycombinator.com")) { results[results_len++] = moz_hosts_id[i]; } } , SQL : / (unmanageable) . SQL:
select accountholder.middlename from accountholder, account where accountholder.id = account.accountholderid - :
int *fksort = iota(account_len); sort_by_int_column(account_accountholderid, fksort, account_len); int *pksort = iota(accountholder_len); sort_by_int_column(accountholder_id, pksort, accountholder_len); int i = 0, j = 0, k = 0; while (i < account_len && j < accountholder_len) { int fk = account_accountholderid[fksort[i]]; int pk = accountholder_id[pksort[j]]; if (fk == pk) { result_id[k] = fk; result_middle_name[k] = accountholder_middlename[pksort[j]]; k++; i++; // Supposing accountholder_id is unique. } else if (fk < pk) { i++; } else { j++; } } free(fksort); free(pksort); iota :
int *iota(int size) { int *results = calloc(size, sizeof(*results)); if (!results) abort(); for (int i = 0; i < size; i++) results[i] = i; return results; } sort_by_int_column :
void sort_by_int_column(int *values, int *indices, int indices_len) { qsort_r(indices, indices_len, sizeof(*indices), indirect_int_comparator, values); } int indirect_int_comparator(const void *a, const void *b, void *arg) { int *values = arg; return values[*(int*)a] — values[*(int*)b]; } SQL- , , , . , .
, SQL — , , , . , , — , , , , . , , .
Prolog miniKANREN, . miniKANREN , , .
(constraint programming), («», ), . , , , SAT SMT.
Source: https://habr.com/ru/post/323624/
All Articles