Can Python chew a million requests per second?

Is it possible with Python to process a million requests per second? Until recently, this was unthinkable.
Many companies migrate from Python to other programming languages to improve performance and, consequently, save on the cost of computing resources. In fact, this is not necessary. Goals can be achieved using Python.
The Python community has recently paid a lot of attention to performance. With the help of CPython 3.6, due to the new implementation of dictionaries, it was possible to increase the speed of the interpreter. And thanks to the new calling convention and the CPython 3.7 dictionary cache should be even faster.
For a certain class of tasks, PyPy is well suited for its JIT compilation. You can also use NumPy, which has improved support for C extensions. This year, PyPy is expected to achieve compatibility with Python 3.5.
These wonderful solutions inspired me to create a new one in the area where Python is used very actively: in the development of web and microservices.
Meet Japronto!
Japronto is a new microframe designed for microservices. It is designed to be fast , scalable and easy . Thanks to asyncio , synchronous and asynchronous modes are implemented. Japronto is amazingly fast - even faster NodeJS and Go.
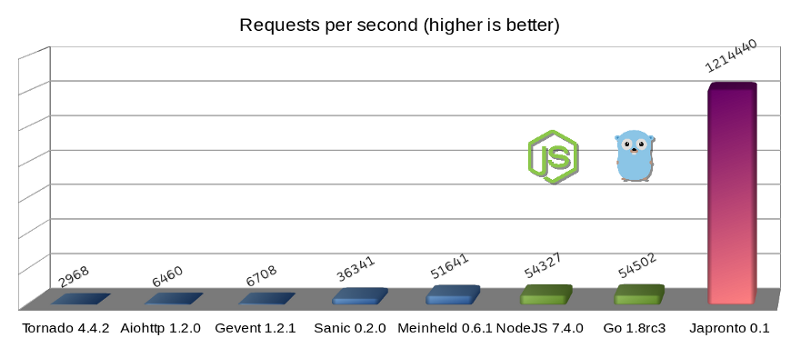
Python microframes (blue), Dark side of force (green) and Japronto (purple)
Update: The @heppu user suggested that a well-optimized, written on Go using the stdlib HTTP server can be 12% faster . There is also a wonderful fasthttp server (also Go), which in this particular benchmark is only 18% slower than Japronto. Wonderful! Details can be found here: https://github.com/squeaky-pl/japronto/pull/12 and https://github.com/squeaky-pl/japronto/pull/14 .
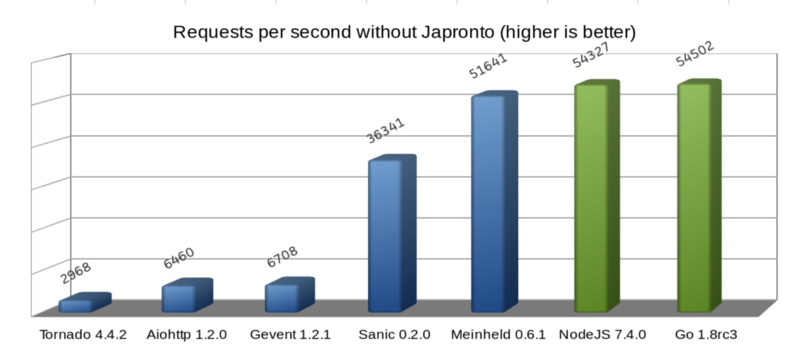
The diagram shows that the Meinheld WSGI server goes almost nostril to the nostril with NodeJS and Go. Despite the fact that this server is blocking in its nature, compared to the previous four asynchronous solutions, it works just fine in Python. Therefore, do not believe that asynchronous systems are always faster. In most cases, they are much better parallelized, but the performance depends on many other parameters.
For testing, I used a simple “Hello world!” Application. Despite its uncomplicated nature, this solution makes it easy to determine the contribution of the program / framework to the loss of performance.
The results were obtained on an unselected AWS c4.2xlarge instance with 8 VCPUs, HVM virtualization, and a magnetic repository running in the São Paulo region. The machine was installed Ubuntu 16.04.1 LTS (Xenial Xerus) with a Linux kernel 4.4.0–53-generic x86_64. The processor was identified by the operating system as the Xeon CPU E5-2666 v3 @ 2.90GHz CPU. Freshly compiled Python 3.6 source code was used.
Each of the tested servers (including options for Go) used only one workflow. Load testing was performed using wrk with one thread, hundreds of connections and twenty-four simultaneous (pipelined) connection requests (a total of 2,400 parallel requests).
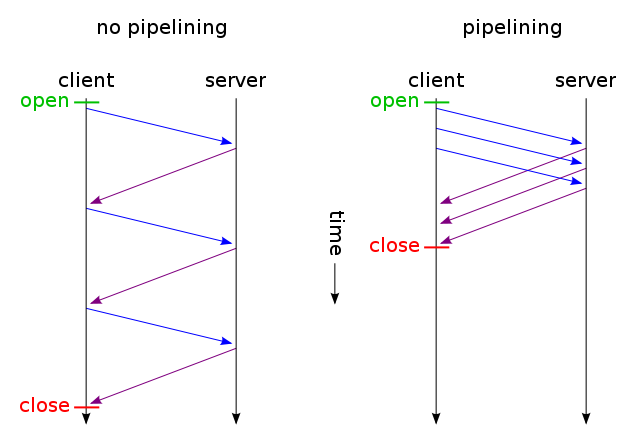
HTTP pipelining (image taken from Wikipedia )
HTTP pipelining (HTTP pipelining) in this case is the most important element of the system, since it is one of the optimizations that Japronto uses when serving requests.
Most servers do not take advantage of HTTP pipelining and process requests from pipelining clients in the usual way (Sanic and Meinheld went even further: they silently discard such requests, which is a violation of the HTTP 1.1 specification).
When using HTTP pipelining, the client sends the next request within one TCP connection, without waiting for a response to the previous one. To correctly match requests and responses, the server sends responses in the same order in which it received requests.
An uncompromising struggle for optimization
When a client sends a lot of small GET requests in the form of pipeline chains, it is highly likely that they will arrive at the server in one TCP packet (thanks to the Nagle algorithm ) and will be read there by a single system call .
Making a system call and moving data from kernel space to user space is a very expensive operation (say, compared to moving memory in a single process). Therefore, it is important to perform only the required minimum of system calls (but not less).
After receiving and successfully parsing the data, Japronto tries to execute all requests as quickly as possible, build the answers in the correct order and write (write) them all with one system call . You can use the scatter / gather IO system calls for “gluing together” requests, but this is not yet implemented in Japronto.
It should be remembered that such a scheme does not always work. Some requests may take too long, and waiting for them will lead to an unreasonable increase in network latency.
Be careful when setting up the heuristics, and also do not forget about the cost of system calls and the expected time of completion of query processing.
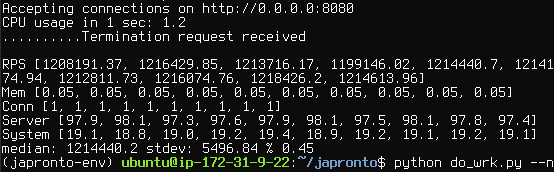
Japronto provides 1,214,440 RPS on grouped continuous data (median, calculated as the 50th percentile, using interpolation).
In addition to recording latency for pipelining clients, several other techniques are used.
Japronto is almost entirely written in C. The parser, protocol, connection reaper, router, request and response objects are implemented as C extensions.
Japronto to the last tries to delay the creation of analogues of its internal structures in Python. For example, a heading dictionary is not created until it is requested in the view. All the boundaries of tokens have already been noted in advance, but the normalization of header keys and the creation of several objects of type str are performed only at the time of their first access.
When analyzing the status line, headers, and chunks of the HTTP message body, Japronto relies on the wonderful C library picohttpparser. To quickly find the boundaries of HTTP tokens, picohttpparser directly uses SSE4.2 text processing instructions built into modern processors (they have been present in almost all x86_64 compatible processors for 10 years). I / O is assigned to uvloop, which is a wrapper around libuv. At the lowest level, the epoll system call is used, which provides asynchronous read-write notifications.

Picohttpparser parsing using SSE4.2 and CMPESTRI x86_64
When designing high-performance systems in Python, special attention must be paid to not unnecessarily increasing the load on the garbage collector. Japronto tries to avoid creating reference cycles and perform as few selection / deallocation operations as possible. This is achieved by placing some objects in advance in the so-called arenas. Japronto is also trying to reuse Python objects, instead of getting rid of them and creating new ones.
Memory is allocated in multiples of 4 Kb. Internal structures are organized in such a way that the data that are often used together are located in the memory not far from each other. This minimizes cache misses.
Japronto also tries to avoid unreasonable copying between buffers, performing many on-site operations. For example, URL-decoding of a path occurs even before the mapping in the process-router.
Open source developers, I need your help
I worked on Japronto for the past three months. Often on weekends, as well as on weekdays. This was only possible because I decided to take a break from work as a hired programmer and directed all my efforts to Japronto.
I think that the time has come to share the fruits of my work with the community.
The following features are currently implemented in Japronto :
- HTTP 1.x with cunked transfer support;
- full HTTP pipelining support;
- Keep-alive connections with a custom connection reaper;
- support synchronous and asynchronous modes;
- Master-multiworker model with master and multiple workflows;
- reload code with changes;
- simple routing
Next, I would like to do web sockets and streaming HTTP responses (streaming HTTP responses) in asynchronous mode.
There is still a lot of work involved in documenting and testing. If you want to help, contact me directly on Twitter . Here is the Japronto repository on github .
Also, if your company is looking for a Python developer who is obsessed with performance and versed in DevOps, I am ready to discuss this. Considering offers from all over the world.
Finally
The above techniques do not have to be Python specific. Maybe they can be applied in languages like Ruby, JavaScript, or even PHP. I would be interested in doing this, but unfortunately this is impossible without funding.
I would like to thank the Python community for their continuous work on improving performance. Namely: Victor Stinner @VictorStinner, INADA Naoki @methane and Yury Selivanov 1st1 , as well as the entire PyPy team.
In the name of love for Python.
')
Source: https://habr.com/ru/post/323556/
All Articles