Complete latent semantic analysis with Python tools
Known implementations of latent-semantic analysis (LSA) by means of the Python programming language [1,2] have a number of significant methodological shortcomings. There are no correlation matrices of words and documents. These matrices reveal hidden connections. There is no cluster analysis for the distribution of words and documents. There is no flexible graphical implementation for analyzing semantic space, which makes it extremely difficult to analyze the results. The user is not able to assess the effect of deleting words that occur once, the method of determining the semantic distance between words and documents. Moreover, there may be situations when, after deleting words that occur only once, the dimension of the frequency matrix is violated and its singular decomposition becomes impossible. The user receives an error message, not understanding their reasons, complaining about the shortcomings of the Python software tools.
At once I want to note that the article is intended for an audience not only familiar with the LSA method, but also with minimal experience in its practical application. Therefore, using the standard set of English-language short messages for testing, I will give a printout of the source data and the results of their processing and a graph of the semantic space.
Nom.dok-- 0 Text-Human machine interface for ABC computer applications
Nom.dok-- 1 Text-A user opinion of computer system response time
Nom.dok-- 2 Text-The EPS user interface
Nom.dok-- 3 Text-System and human system engineering testing of EPS
Nom.dok-- 4 Text-Relation of the user perceived response time to error measurement
Nom.dok-- 5 Text-The generation of random, binary, ordered trees
Nom.dok-- 6 Text-The intersection graph of paths in trees
Nom.dok-- 7 Text-Graph minors IV: Widths of trees and well-quasi- ordering
Nom.dok-- 8 Text-Graph minors: A survey
')
[[1. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1.]
[1. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[1. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1.]
[0. 1. 0. 0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 1.]
[0. 1. 1. 2. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 1. 1. 1.]
[0. 1. 1. 0. 1. 0. 0. 0. 0. 0.]]
comput {[1. 1. 0. 0. 0. 0. 0. 0. 0. 0.]}
ep {[0. 0. 1. 1. 0. 0. 0. 0. 0.]}}
graph {[0. 0. 0. 0. 0. 0. 1. 1. 1.]}
human {[1. 0. 0. 1. 0. 0. 0. 0. 0.]}}
interfac {[1. 0. 1. 0. 0. 0. 0. 0. 0. 0.]}
minor {[0. 0. 0. 0. 0. 0. 0. 1. 1.]}
respons {[0. 1. 0. 0. 1. 0. 0. 0. 0.]}}
survey {[0. 1. 0. 0. 0. 0. 0. 0. 1.]}
system {[0. 1. 1. 2. 0. 0. 0. 0. 0.]]}
time {[0. 1. 0. 0. 0. 0. 0. 0. 0.]]}
tree {[0. 0. 0. 0. 0. 1. 1. 1. 0.]}
user {[0. 1. 1. 0. 1. 0. 0. 0. 0.]]}
The matrix normalized by the TF-IDF method: rows-words -12 columns - documents - 9.
comput {[0.5 0.25 0. 0. 0. 0. 0. 0. 0.]}
ep {[0. 0. 0.38 0.38 0. 0. 0. 0. 0.]}
graph {[0. 0. 0. 0. 0. 0. 0.55 0.37 0.37]}
human {[0.5 0. 0. 0.38 0. 0. 0. 0. 0.]}
interfac {[0.5 0. 0.38 0. 0. 0. 0. 0. 0.]}}
minor {[0. 0. 0. 0. 0. 0. 0. 0.5 0.5]}
respons {[0. 0.25 0. 0. 0.5 0. 0. 0. 0.]}
survey {[0. 0.25 0. 0. 0. 0. 0. 0. 0.5]}
system {[0. 0.18 0.27 0.55 0. 0. 0. 0. 0.]}
time {[0. 0.25 0. 0. 0.5 0. 0. 0. 0.]}
tree {[0. 0. 0. 0. 0. 1.1 0.55 0.37 0.]}
user {[0. 0.18 0.27 0. 0.37 0. 0. 0. 0.]}
comput {[-0.0045 0.3471]}
ep {[-0.0014 0.3404]}
graph {[-0.3777 0.0363]}
human {[-0.0017 0.4486]}
interfac {[-0.0017 0.4309]}
minor {[-0.2351 0.0542]}
respons {[-0.0053 0.218]}
survey {[-0.0827 0.1223]}
system {[-0.0039 0.4297]}
time {[-0.0053 0.218]}
tree {[-0.8917 -0.0508]}
user {[-0.0043 0.2744]}
The coordinates x - 0.891700 and y - 0.050800 of the reference word --tree, from which all distances are calculated.
[[1.37269958 0. 0]
[0. 1.06667558]]
The first 2 rows of the orthogonal matrix Vt of the documents of the singular transformation of the normalized matrix are: columns of documents -9.
[[0.0029 0.0189 0.0025 0.0024 0.005 0.7145 0.5086 0.4278 0.2175]
[-0.5749 -0.331 -0.453 -0.5026 -0.2996 0.0524 0.0075 -0.0204 -0.0953]]
comput {[0.21 0.12 0.17 0.19 0.11 -0.01 0. 0.01 0.04]}
eps {[0.21 0.12 0.16 0.18 0.11 -0.02 0. 0.01 0.04]}
graph {[0.02 0.02 0.02 0.02 0.01 0.37 0.26 0.22 0.12]}
human {[0.28 0.16 0.22 0.24 0.14 -0.02 0. 0.01 0.05]}
interfac {[0.26 0.15 0.21 0.23 0.14 -0.02 0. 0.01 0.04]}
minor {[0.03 0.03 0.03 0.03 0.02 0.23 0.16 0.14 0.08]}
respons {[0.13 0.08 0.11 0.12 0.07 -0.01 0. 0.01 0.02]}
survey {[0.08 0.05 0.06 0.07 0.04 0.07 0.06 0.05 0.04]}
system {[0.26 0.15 0.21 0.23 0.14 -0.02 0. 0.01 0.04]}
time {[0.13 0.08 0.11 0.12 0.07 -0.01 0. 0.01 0.02]}
tree {[-0.03 0.01 -0.02 -0.02 -0.01 0.88 0.62 0.52 0.26]}
user {[0.17 0.1 0.13 0.15 0.09 -0.01 0. 0.01 0.03]}
[[1. 0.998649 1. 1. 0.999932 -0.06811 -0.009701
0.05267 0.405942]
[0.998649 1. 0.998673 0.998635 0.999186-0.016168 0.04228
0.104496 0.452889]
[1. 0.998673 1. 1. 0.999938 -0.067637 -0.009226
0.053143 0.406376]
[1. 0.998635 1. 1. 0.999929-0.068378-0.00997
0.052401 0.405696]
[0.999932 0.999186 0.999938 0.999929 1. -0.056489 0.001942
0.064293 0.416555]
[-0.06811 -0.016168 -0.067637 -0.068378 -0.056489 1. 0.998292
0.992706 0.884128]
[-0.009701 0.04228 -0.009226 -0.00997 0.001942 0.998292 1. 0.998054
0.909918]
[0.05267 0.104496 0.053143 0.052401 0.064293 0.992706 0.998054 1.
0.934011]
[0.405942 0.452889 0.406376 0.405696 0.416555 0.884128 0.909918
0.934011 1.]]
Clustering cosine distances between documents.
Cluster Tags:
[1 1 1 1 1 0 0 0 0]
Coordinates of cluster centroids:
[[0.09520025 0.14587425 0.095664 0.09493725 0.10657525 0.9687815
0.976566 0.98119275 0.93201425]
[0.9997162 0.9990286 0.9997222 0.9997128 0.999797 -0.0553564
0.003065 0.0654006 0.4174916]]
comput {[1. 0.999961 0.108563 0.999958 0.999959 0.237261 0.999936
0.835577 0.999992 0.999936 -0.04393 0.999996]}
ep {[0.999961 1. 0.09976 1. 1. 0.228653 0.999796
0.830682 0.999988 0.999796 -0.052771 0.999933]}
graph {[0.108563 0.09976 1. 0.099439 0.099594 0.991462 0.119832
0.636839 0.104697 0.119832 0.988361 0.111252]}
human {[0.999958 1. 0.099439 1. 1. 0.228339 0.99979
0.830502 0.999986 0.99979-0.053094 0.999929]}
interfac {[0.999959 1. 0.099594 1. 1. 0.22849 0.999793
0.830589 0.999987 0.999793 -0.052938 0.999931]}
minor {[0.237261 0.228653 0.991462 0.228339 0.22849 1. 0.248265
0.731936 0.233482 0.248265 0.960085 0.239888]}
respons {[0.999936 0.999796 0.119832 0.99979 0.999793 0.248265 1. 0.841755
0.999884 1. -0.032595 0.999963]}
survey {[0.835577 0.830682 0.636839 0.830502 0.830589 0.731936 0.841755 1.
0.833435 0.841755 0.512136 0.83706]}
system {[0.999992 0.999988 0.104697 0.999986 0.999987 0.233482 0.999884
0.833435 1. 0.999884 -0.047814 0.999978]}
time {[0.999936 0.999796 0.119832 0.99979 0.999793 0.248265 1. 0.841755
0.999884 1. -0.032595 0.999963]}
tree {[-0.04393 -0.052771 0.988361 -0.053094 -0.052938 0.960085 -0.032595
0.512136 -0.047814 -0.032595 1. -0.041227]}
user {[0.999996 0.999933 0.111252 0.999929 0.999931 0.239888 0.999963
0.83706 0.999978 0.999963-0.041227 1.]}
Clustering cosine distances between words
[1 1 0 1 1 0 1 1 1 1 0 1]
Coordinates of cluster centroids:
[[0.10063133 0.09188067 0.99327433 0.09156133 0.09171533 0.983849
0.111834 0.62697033 0.09678833 0.111834 0.98281533 0.10330433]
[0.98170167 0.98112844 0.16664533 0.98110611 0.98111689 0.29161989
0.98232411 0.85348389 0.98145933 0.98232411 0.01724133 0.98186144]]
Analysis results: Total documents: 9. Documents left after exclusion not related: 9
No. Doc [0, 3] - 0.0-Cosine distance measure -General words - ['human']
No. Doc [3, 2] - 0.0-Cosine distance measure -General words - ['system', 'ep']
No. Doc [2, 4] - 0.0-Cosine distance measure -General words - ['user']
№№ Doc [4, 1] - 0.001-Cosine distance measure -General words - ['user', 'respons', 'time']
№№ Doc [6, 5] - 0.001-Cosine distance measure -General words - ['tree']
№№ Doc [7, 6] - 0.002-Cosine distance measure -General words - ['graph', 'tree']
№№ Doc [8, 7] - 0.067-Cosine distance measure -General words - ['graph', 'minor']
No. Doc [1, 8] - 0.548-Cosine distance measure -General words - ['survey']
Module menu.py can be compiled in exe. Data entry is carried out through settings.py.
LSA experts type the code, run the program and it will tell you about the additional features that I intend to miss. I hope you find this useful.
At once I want to note that the article is intended for an audience not only familiar with the LSA method, but also with minimal experience in its practical application. Therefore, using the standard set of English-language short messages for testing, I will give a printout of the source data and the results of their processing and a graph of the semantic space.
Background documents
Nom.dok-- 0 Text-Human machine interface for ABC computer applications
Nom.dok-- 1 Text-A user opinion of computer system response time
Nom.dok-- 2 Text-The EPS user interface
Nom.dok-- 3 Text-System and human system engineering testing of EPS
Nom.dok-- 4 Text-Relation of the user perceived response time to error measurement
Nom.dok-- 5 Text-The generation of random, binary, ordered trees
Nom.dok-- 6 Text-The intersection graph of paths in trees
Nom.dok-- 7 Text-Graph minors IV: Widths of trees and well-quasi- ordering
Nom.dok-- 8 Text-Graph minors: A survey
')
- Words that occur only once:
['opinion', 'binari', 'in', 'engin', 'iv', 'width', 'order', 'test', 'error', 'intersect', 'abc', 'perceiv', ' path ',' generat ',' relat ',' to ',' measur ',' machin ',' manag ',' for ',' random ',' applic '] - Stop words:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours',' we ',' you ',' your ',' yours', 'yourself', ' yourselves', 'he', 'him', 'his',' himself ',' she ',' her ',' hers', 'herself', 'it', 'its',' itself ',' they ' , 'them', 'their', 'theirs',' themselves', 'what', 'which', 'who', 'whom', 'this',' that ',' these ',' those ',' am ',' is', 'are', 'was',' were ',' be ',' been ',' being ',' have ',' has', 'had', 'having', 'do' , 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', until ',' while ',' of ',' at ',' by ',' for ',' with ',' about ',' against ',' between ',' into ',' through ',' during ' , 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', ' over ',' under ',' again ',' further ',' then ',' once ',' here ',' there ',' when ',' where ',' why ',' how ',' all ' , 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', ' only ',' own ',' same ',' so ',' than ',' too ',' very ',' s', 't', 'can', 'will', 'just', 'don' , 'should', 'no w '] - Word (base):
['human', 'interfac', 'comput', 'survey', 'user', 'system', 'respons', 'time', 'ep', 'tree', 'graph', 'minor'] - Distribution of words on documents:
{'interfac': [0, 2], 'user': [1, 2, 4], 'minor': [7, 8], 'comput': [0, 1], 'graph': [6, 7, 8], 'tree': [5, 6, 7], 'time': [1, 4], 'human': [0, 3], 'ep': [2, 3], 'system' : [1, 2, 3, 3], 'survey': [1, 8], 'respons': [1, 4]}
The first matrix of rows and columns filled
[[1. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1.]
[1. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[1. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1.]
[0. 1. 0. 0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 1.]
[0. 1. 1. 2. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 1. 1. 1.]
[0. 1. 1. 0. 1. 0. 0. 0. 0. 0.]]
The original frequency matrix number of words --- 12 is greater than or equal to the number of document-9
comput {[1. 1. 0. 0. 0. 0. 0. 0. 0. 0.]}
ep {[0. 0. 1. 1. 0. 0. 0. 0. 0.]}}
graph {[0. 0. 0. 0. 0. 0. 1. 1. 1.]}
human {[1. 0. 0. 1. 0. 0. 0. 0. 0.]}}
interfac {[1. 0. 1. 0. 0. 0. 0. 0. 0. 0.]}
minor {[0. 0. 0. 0. 0. 0. 0. 1. 1.]}
respons {[0. 1. 0. 0. 1. 0. 0. 0. 0.]}}
survey {[0. 1. 0. 0. 0. 0. 0. 0. 1.]}
system {[0. 1. 1. 2. 0. 0. 0. 0. 0.]]}
time {[0. 1. 0. 0. 0. 0. 0. 0. 0.]]}
tree {[0. 0. 0. 0. 0. 1. 1. 1. 0.]}
user {[0. 1. 1. 0. 1. 0. 0. 0. 0.]]}
The matrix normalized by the TF-IDF method: rows-words -12 columns - documents - 9.
comput {[0.5 0.25 0. 0. 0. 0. 0. 0. 0.]}
ep {[0. 0. 0.38 0.38 0. 0. 0. 0. 0.]}
graph {[0. 0. 0. 0. 0. 0. 0.55 0.37 0.37]}
human {[0.5 0. 0. 0.38 0. 0. 0. 0. 0.]}
interfac {[0.5 0. 0.38 0. 0. 0. 0. 0. 0.]}}
minor {[0. 0. 0. 0. 0. 0. 0. 0.5 0.5]}
respons {[0. 0.25 0. 0. 0.5 0. 0. 0. 0.]}
survey {[0. 0.25 0. 0. 0. 0. 0. 0. 0.5]}
system {[0. 0.18 0.27 0.55 0. 0. 0. 0. 0.]}
time {[0. 0.25 0. 0. 0.5 0. 0. 0. 0.]}
tree {[0. 0. 0. 0. 0. 1.1 0.55 0.37 0.]}
user {[0. 0.18 0.27 0. 0.37 0. 0. 0. 0.]}
The first 2 columns of the orthogonal matrix U of words, the singular transformation of a normalized matrix: rows of words -12
comput {[-0.0045 0.3471]}
ep {[-0.0014 0.3404]}
graph {[-0.3777 0.0363]}
human {[-0.0017 0.4486]}
interfac {[-0.0017 0.4309]}
minor {[-0.2351 0.0542]}
respons {[-0.0053 0.218]}
survey {[-0.0827 0.1223]}
system {[-0.0039 0.4297]}
time {[-0.0053 0.218]}
tree {[-0.8917 -0.0508]}
user {[-0.0043 0.2744]}
The coordinates x - 0.891700 and y - 0.050800 of the reference word --tree, from which all distances are calculated.
The first 2 rows of the diagonal matrix S
[[1.37269958 0. 0]
[0. 1.06667558]]
The first 2 rows of the orthogonal matrix Vt of the documents of the singular transformation of the normalized matrix are: columns of documents -9.
[[0.0029 0.0189 0.0025 0.0024 0.005 0.7145 0.5086 0.4278 0.2175]
[-0.5749 -0.331 -0.453 -0.5026 -0.2996 0.0524 0.0075 -0.0204 -0.0953]]
Matrix to reveal hidden links
comput {[0.21 0.12 0.17 0.19 0.11 -0.01 0. 0.01 0.04]}
eps {[0.21 0.12 0.16 0.18 0.11 -0.02 0. 0.01 0.04]}
graph {[0.02 0.02 0.02 0.02 0.01 0.37 0.26 0.22 0.12]}
human {[0.28 0.16 0.22 0.24 0.14 -0.02 0. 0.01 0.05]}
interfac {[0.26 0.15 0.21 0.23 0.14 -0.02 0. 0.01 0.04]}
minor {[0.03 0.03 0.03 0.03 0.02 0.23 0.16 0.14 0.08]}
respons {[0.13 0.08 0.11 0.12 0.07 -0.01 0. 0.01 0.02]}
survey {[0.08 0.05 0.06 0.07 0.04 0.07 0.06 0.05 0.04]}
system {[0.26 0.15 0.21 0.23 0.14 -0.02 0. 0.01 0.04]}
time {[0.13 0.08 0.11 0.12 0.07 -0.01 0. 0.01 0.02]}
tree {[-0.03 0.01 -0.02 -0.02 -0.01 0.88 0.62 0.52 0.26]}
user {[0.17 0.1 0.13 0.15 0.09 -0.01 0. 0.01 0.03]}
Matrix of cosine distances between documents
[[1. 0.998649 1. 1. 0.999932 -0.06811 -0.009701
0.05267 0.405942]
[0.998649 1. 0.998673 0.998635 0.999186-0.016168 0.04228
0.104496 0.452889]
[1. 0.998673 1. 1. 0.999938 -0.067637 -0.009226
0.053143 0.406376]
[1. 0.998635 1. 1. 0.999929-0.068378-0.00997
0.052401 0.405696]
[0.999932 0.999186 0.999938 0.999929 1. -0.056489 0.001942
0.064293 0.416555]
[-0.06811 -0.016168 -0.067637 -0.068378 -0.056489 1. 0.998292
0.992706 0.884128]
[-0.009701 0.04228 -0.009226 -0.00997 0.001942 0.998292 1. 0.998054
0.909918]
[0.05267 0.104496 0.053143 0.052401 0.064293 0.992706 0.998054 1.
0.934011]
[0.405942 0.452889 0.406376 0.405696 0.416555 0.884128 0.909918
0.934011 1.]]
Clustering cosine distances between documents.
Cluster Tags:
[1 1 1 1 1 0 0 0 0]
Coordinates of cluster centroids:
[[0.09520025 0.14587425 0.095664 0.09493725 0.10657525 0.9687815
0.976566 0.98119275 0.93201425]
[0.9997162 0.9990286 0.9997222 0.9997128 0.999797 -0.0553564
0.003065 0.0654006 0.4174916]]
Matrix of cosine distances between words
comput {[1. 0.999961 0.108563 0.999958 0.999959 0.237261 0.999936
0.835577 0.999992 0.999936 -0.04393 0.999996]}
ep {[0.999961 1. 0.09976 1. 1. 0.228653 0.999796
0.830682 0.999988 0.999796 -0.052771 0.999933]}
graph {[0.108563 0.09976 1. 0.099439 0.099594 0.991462 0.119832
0.636839 0.104697 0.119832 0.988361 0.111252]}
human {[0.999958 1. 0.099439 1. 1. 0.228339 0.99979
0.830502 0.999986 0.99979-0.053094 0.999929]}
interfac {[0.999959 1. 0.099594 1. 1. 0.22849 0.999793
0.830589 0.999987 0.999793 -0.052938 0.999931]}
minor {[0.237261 0.228653 0.991462 0.228339 0.22849 1. 0.248265
0.731936 0.233482 0.248265 0.960085 0.239888]}
respons {[0.999936 0.999796 0.119832 0.99979 0.999793 0.248265 1. 0.841755
0.999884 1. -0.032595 0.999963]}
survey {[0.835577 0.830682 0.636839 0.830502 0.830589 0.731936 0.841755 1.
0.833435 0.841755 0.512136 0.83706]}
system {[0.999992 0.999988 0.104697 0.999986 0.999987 0.233482 0.999884
0.833435 1. 0.999884 -0.047814 0.999978]}
time {[0.999936 0.999796 0.119832 0.99979 0.999793 0.248265 1. 0.841755
0.999884 1. -0.032595 0.999963]}
tree {[-0.04393 -0.052771 0.988361 -0.053094 -0.052938 0.960085 -0.032595
0.512136 -0.047814 -0.032595 1. -0.041227]}
user {[0.999996 0.999933 0.111252 0.999929 0.999931 0.239888 0.999963
0.83706 0.999978 0.999963-0.041227 1.]}
Clustering cosine distances between words
Cluster Tags
[1 1 0 1 1 0 1 1 1 1 0 1]
Coordinates of cluster centroids:
[[0.10063133 0.09188067 0.99327433 0.09156133 0.09171533 0.983849
0.111834 0.62697033 0.09678833 0.111834 0.98281533 0.10330433]
[0.98170167 0.98112844 0.16664533 0.98110611 0.98111689 0.29161989
0.98232411 0.85348389 0.98145933 0.98232411 0.01724133 0.98186144]]
Analysis results: Total documents: 9. Documents left after exclusion not related: 9
No. Doc [0, 3] - 0.0-Cosine distance measure -General words - ['human']
No. Doc [3, 2] - 0.0-Cosine distance measure -General words - ['system', 'ep']
No. Doc [2, 4] - 0.0-Cosine distance measure -General words - ['user']
№№ Doc [4, 1] - 0.001-Cosine distance measure -General words - ['user', 'respons', 'time']
№№ Doc [6, 5] - 0.001-Cosine distance measure -General words - ['tree']
№№ Doc [7, 6] - 0.002-Cosine distance measure -General words - ['graph', 'tree']
№№ Doc [8, 7] - 0.067-Cosine distance measure -General words - ['graph', 'minor']
No. Doc [1, 8] - 0.548-Cosine distance measure -General words - ['survey']
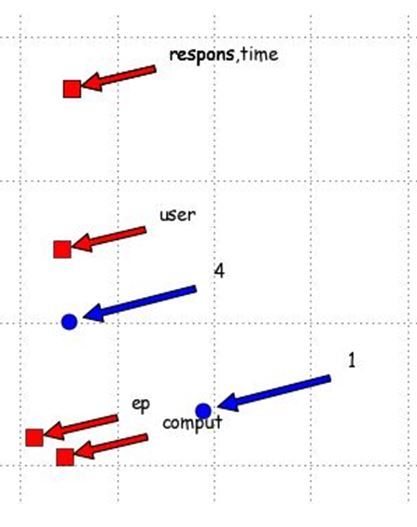
- Location in the semantic space of words and documents

- Use the magnifier to view rich areas
Program code
- Module menu.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys from tkinter.filedialog import * from tkinter.messagebox import * import numpy import numpy as np from numpy import * from sklearn.cluster import KMeans import nltk import scipy from settings import docs,stem,stopwords ddd=len(docs) from nltk.stem import SnowballStemmer stemmer = SnowballStemmer(stem) doc=[w for w in docs] import matplotlib.pyplot as plt import matplotlib as mpl mpl.rcParams['font.family'] = 'fantasy' mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial' def STart(): clear_all() txt.insert(END,' \n') for k, v in enumerate(docs): txt.insert(END,'.--%u -%s \n'%(k,v)) if var1.get()==0: return word_1() elif var1.get()==1: t=" " word=nltk.word_tokenize((' ').join(doc)) stopword=[stemmer.stem(w).lower() for w in stopwords] return WordStopDoc(t,stopword) def word_1(): txt1.delete(1.0, END) txt2.delete(1.0, END) word=nltk.word_tokenize((' ').join(doc)) n=[stemmer.stem(w).lower() for w in word if len(w) >1 and w.isalpha()] stopword=[stemmer.stem(w).lower() for w in stopwords] fdist=nltk.FreqDist(n) t=fdist.hapaxes() txt1.insert(END,' :\n%s'%t) txt1.insert(END,'\n') return WordStopDoc(t,stopword) def WordStopDoc(t,stopword): d={} c=[] p={} for i in range(0,len(doc)): word=nltk.word_tokenize(doc[i]) word_stem=[stemmer.stem(w).lower() for w in word if len(w)>1 and w.isalpha()] word_stop=[ w for w in word_stem if w not in stopword] words=[ w for w in word_stop if w not in t] p[i]=[w for w in words] for w in words: if w not in c: c.append(w) d[w]= [i] elif w in c: d[w]= d[w]+[i] txt1.insert(END,'-:\n') txt1.insert(END, stopwords) txt1.insert(END,'\n') txt1.insert(END,'C():\n') txt1.insert(END,c) txt1.insert(END,'\n') txt1.insert(END,' :\n') txt1.insert(END,d) txt1.insert(END,'\n') return Create_Matrix(d,c,p) def Create_Matrix(d,c,p): a=len(c) b=len(doc) A = numpy.zeros([a,b]) c.sort() for i, k in enumerate(c): for j in d[k]: A[i,j] += 1 txt1.insert(END, ' :\n') txt1.insert(END,A) txt1.insert(END,'\n') return Analitik_Matrix(A,c,p) def Analitik_Matrix(A,c,p): wdoc = sum(A, axis=0) pp=[] q=-1 for w in wdoc: q=q+1 if w==0: pp.append(q) if len(pp)!=0: for k in pp: doc.pop(k) word_1() elif len(pp)==0: rows, cols = A.shape txt1.insert(END,' ---%u -%u \n'%(rows,cols)) nn=[] for i, row in enumerate(A): st=(c[i], row) stt=sum(row) nn.append(stt) txt1.insert(END,st) txt1.insert(END,'\n') if var.get()==0: return TF_IDF(A,c,p) elif var.get()==1: l=nn.index(max(nn)) return U_S_Vt(A,c,p,l) def TF_IDF(A,c,p): wpd = sum(A, axis=0) dpw= sum(asarray(A > 0,'i'), axis=1) rows, cols = A.shape txt1.insert(END,' TF-IDF : - -%u - --%u \n'%(rows,cols)) for i in range(rows): for j in range(cols): m=float(A[i,j])/wpd[j] n=log(float(cols) /dpw[i]) A[i,j] =round(n*m,2) gg=[] for i, row in enumerate(A): st=(c[i], row) stt=sum(row) gg.append(stt) txt1.insert(END,st) txt1.insert(END,'\n') l=gg.index(max(gg)) return U_S_Vt(A,c,p,l) def U_S_Vt(A,c,p,l): U, S,Vt = numpy.linalg.svd(A) rows, cols = U.shape for j in range(0,cols): for i in range(0,rows): U[i,j]=round(U[i,j],4) txt1.insert(END,' 2 U , : -%u\n'%rows) for i, row in enumerate(U): st=(c[i], row[0:2]) txt1.insert(END,st) txt1.insert(END,'\n') kt=l wordd=c[l] res1=-1*U[:,0:1] wx=res1[kt] res2=-1*U[:,1:2] wy=res2[kt] txt1.insert(END,' x --%f y--%f --%s, \n'%(wx,wy,wordd) ) txt1.insert(END,' 2 S \n') Z=np.diag(S) txt1.insert(END,Z[0:2,0:2] ) txt1.insert(END,'\n') rows, cols = Vt.shape for j in range(0,cols): for i in range(0,rows): Vt[i,j]=round(Vt[i,j],4) txt1.insert(END,' 2 Vt : -%u\n'%cols) st=(-1*Vt[0:2, :]) txt1.insert(END,st) txt1.insert(END,'\n') res3=(-1*Vt[0:1, :]) res4=(-1*Vt[1:2, :]) X=numpy.dot(U[:,0:2],Z[0:2,0:2]) Y=numpy.dot(X,Vt[0:2,:] ) txt1.insert(END,' \n') rows, cols =Y.shape for j in range(0,cols): for i in range(0,rows): Y[i,j]=round( Y[i,j],2) for i, row in enumerate(Y): st=(c[i], row) txt1.insert(END,st) txt1.insert(END,'\n') return Word_Distance_Document(res1,wx,res2,wy,res3,res4,Vt,p,c,Z,U) def Word_Distance_Document(res1,wx,res2,wy,res3,res4,Vt,p,c,Z,U): xx, yy = -1 * Vt[0:2, :] rows, cols = Vt.shape a=cols b=cols B = numpy.zeros([a,b]) for i in range(0,cols): for j in range(0,cols): xxi, yyi = -1 * Vt[0:2, i] xxi1, yyi1 =-1 * Vt[0:2, j] B[i,j]=round(float(xxi*xxi1+yyi*yyi1)/float(sqrt((xxi*xxi+yyi*yyi)*(xxi1*xxi1+yyi1*yyi1))),6) txt1.insert(END,' \n') txt1.insert(END,B) txt1.insert(END,'\n') txt1.insert(END,' \n') X = np.array(B) kmeans = KMeans(n_clusters=2, random_state=0).fit(X) txt1.insert(END,' \n') txt1.insert(END,kmeans.labels_) txt1.insert(END,'\n') txt1.insert(END,' \n') txt1.insert(END,kmeans.cluster_centers_) txt1.insert(END,'\n') Q= np.matrix(U) UU = QT rows, cols = UU.shape a=cols b=cols B = numpy.zeros([a,b]) for i in range(0,cols): for j in range(0,cols): xxi, yyi = -1 * UU[0:2, i] xxi1, yyi1 = -1 * UU[0:2, j] B[i,j]=round(float(xxi*xxi1+yyi*yyi1)/float(sqrt((xxi*xxi+yyi*yyi)*(xxi1*xxi1+yyi1*yyi1))),6) txt1.insert(END,' \n') for i, row in enumerate(B): st=(c[i], row[0:]) txt1.insert(END,st) txt1.insert(END,'\n') txt1.insert(END,' \n') X = np.array(B) kmeans = KMeans(n_clusters=2, random_state=0).fit(X) txt1.insert(END,' \n') txt1.insert(END,kmeans.labels_) txt1.insert(END,'\n') txt1.insert(END,' \n') txt1.insert(END,kmeans.cluster_centers_) arts = [] txt2.insert(END,' : :%u. :%u\n'%(ddd,len(doc))) if ddd>len(doc): txt2.insert(END," :") txt2.insert(END,'\n') for k, v in enumerate(doc): ww='.№ - %i. Text -%s'%(k,v) txt2.insert(END, ww) txt2.insert(END,'\n') for k in range(0,len(doc)): ax, ay = xx[k], yy[k] dx, dy = float(wx - ax), float(wy - ay) if var2.get()==0: dist=float(sqrt(dx * dx + dy * dy)) elif var2.get()==1: dist=float(wx*ax+wy*ay)/float(sqrt(wx*wx+wy*wy)*sqrt(ax*ax+ay*ay)) arts.append((k,p[k],round(dist,3))) q=(sorted(arts,key = lambda a: a[2])) dd=[] ddm=[] aa=[] bb=[] for i in range(1,len(doc)): cos1=q[i][2] cos2=q[i-1][2] if var2.get()==0: qq=round(float(cos1-cos2),3) elif var2.get()==1: sin1=sqrt(1-cos1**2) sin2=sqrt(1-cos2**2) qq=round(float(1-abs(cos1*cos2+sin1*sin2)),3) tt=[(q[i-1])[0],(q[i])[0]] dd.append(tt) ddm.append(qq) for w in range(0,len(dd)): i=ddm.index(min(ddm)) aa.append(dd[i]) bb.append(ddm[i]) del dd[i] del ddm[i] for i in range(0,len(aa)): if len([w for w in p[aa[i][0]]if w in p[aa[i][1]]])!=0: zz=[w for w in p[aa[i][0]]if w in p[aa[i][1]]] else: zz=[' '] cs=[] for w in zz: if w not in cs: cs.append(w) if var2.get()==0: sc=" " elif var2.get()==1: sc=" " tr ='№№ %s- %s-%s - -%s'%(aa[i],bb[i],sc,cs) txt2.insert(END, tr) txt2.insert(END,'\n') return Grafics_End(res1,res2,res3,res4,c) def Grafics_End(res1,res2,res3,res4,c): # plt.title('Semantic space', size=14) plt.xlabel('x-axis', size=14) plt.ylabel('y-axis', size=14) e1=(max(res1)-min(res1))/len(c) e2=(max(res2)-min(res2))/len(c) e3=(max(res3[0])-min(res3[0]))/len(doc) e4=(max(res4[0])-min(res4[0]))/len(doc) plt.axis([min(res1)-e1, max(res1)+e1, min(res2)-e2, max(res2)+e2]) plt.plot(res1, res2, color='r', linestyle=' ', marker='s',ms=10,label='Words') plt.axis([min(res3[0])-e3, max(res3[0])+e3, min(res4[0])-e4, max(res4[0])+e4]) plt.plot(res3[0], res4[0], color='b', linestyle=' ', marker='o',ms=10,label='Documents №') plt.legend(loc='best') k={} for i in range(0,len(res1)): xv=float(res1[i]) yv=float(res2[i]) if (xv,yv) not in k.keys(): k[xv,yv]=c[i] elif (xv,yv) in k.keys(): k[xv,yv]= k[xv,yv]+','+c[i] plt.annotate(k[xv,yv], xy=(res1[i], res2[i]), xytext=(res1[i]+0.01, res2[i]+0.01),arrowprops=dict(facecolor='red', shrink=0.1),) k={} for i in range(0,len(doc)): xv=float((res3[0])[i]) yv=float((res4[0])[i]) if (xv,yv) not in k.keys(): k[xv,yv]=str(i) elif (xv,yv) in k.keys(): k[xv,yv]= k[xv,yv]+','+str(i) plt.annotate(k[xv,yv], xy=((res3[0])[i], (res4[0])[i]), xytext=((res3[0])[i]+0.015, (res4[0])[i]+0.015),arrowprops=dict(facecolor='blue', shrink=0.1),) plt.grid() plt.show() def close_win(): if askyesno("Exit", "Do you want to quit?"): tk.destroy() def save_text(): save_as = asksaveasfilename() try: x = txt.get(1.0, END)+ '\n'+txt1.get(1.0, END) + '\n'+txt2.get(1.0, END) f = open(save_as, "w") f.writelines(x) f.close() except: pass clear_all() def clear_all(): txt.delete(1.0, END) txt1.delete(1.0, END) txt2.delete(1.0, END) tk= Tk() tk.geometry('700x650') main_menu = Menu(tk) tk.config(menu=main_menu) file_menu = Menu(main_menu) main_menu.add_cascade(label="LSA", menu=file_menu) file_menu.add_command(label="Start", command= STart) file_menu.add_command(label="Save text", command= save_text) file_menu.add_command(label="Clear all fields", command= clear_all) file_menu.add_command(label="Exit", command= close_win) txt = Text(tk, width=72,height=10,font="Arial 12",wrap=WORD) txt.pack() txt1= Text(tk, width=72,height=10,font="Arial 12",wrap=WORD) txt1.pack() txt2= Text(tk, width=72,height=10,font="Arial 12",wrap=WORD) txt2.pack() var = IntVar() ch_box = Checkbutton(tk, text="to use TF_IDF/no to use TF_IDF", variable=var) ch_box.pack() var1 = IntVar() ch_box1 = Checkbutton(tk, text="to exclude words used once/no to exclude words used once", variable=var1) ch_box1.pack() var2 = IntVar() ch_box2 = Checkbutton(tk, text="Evckid distance/cos distance", variable=var2) ch_box2.pack() tk.title("System of the automated semantic analysis") tk.mainloop() - Module settings.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import nltk from nltk import * from nltk.corpus import brown stopwords= nltk.corpus.stopwords.words('english') docs =[ "Human machine interface for ABC computer applications", "A survey of user opinion of computer system response time", "The EPS user interface management system", "System and human system engineering testing of EPS", "Relation of user perceived response time to error measurement", "The generation of random, binary, ordered trees", "The intersection graph of paths in trees", "Graph minors IV: Widths of trees and well-quasi-ordering", "Graph minors: A survey" ] stem='english' #'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', #'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
Module menu.py can be compiled in exe. Data entry is carried out through settings.py.
LSA experts type the code, run the program and it will tell you about the additional features that I intend to miss. I hope you find this useful.
Links
- Latent-semantic analysis [Electronic resource]. / "Megamind" on Habrahabr - Mode of access: \ www / URL habrahabr.ru/post/110078 - 04/30/2016 - Top. from the screen
- Latent-semantic analysis and search in Python [Electronic resource] ./ “Megamind” on Habrahabr — Access mode: \ www / URL habrahabr.ru/post/197238 , free - 30.0 04.2016. - Title from the screen
Source: https://habr.com/ru/post/323516/
All Articles