Search without internet. New beta application Yandex
Many of us still find ourselves in situations where you need to quickly find important information, but access to the Internet is limited or absent. And one thing is to try to open an entertainment post on the site, and quite another to look for the telephone number of the hotline of a bank or hospital. Today for the first time I will tell Habr's readers how the acceleration of search in the Yandex application led to the opportunity to search for important information without the Internet.

But first you need to understand the main thing: why do we even take on offline search, if the sites from the search results are still unavailable in the absence of a network?
')
EDGE search
Yandex radars traditionally show people who enter a request, but then leave the page without waiting for the download due to poor mobile Internet. In this situation, we could not affect the overall quality of the network and the download speed of all sites, but at least the search process was less painful and it was worth a little time to save. Actually, this is why this project was originally called an EDGE search, i.e. search on slow internet.
You can speed up the search in two ways. First, optimize the web version as much as possible and the APIs that the application uses. And this work is also underway, but even this is not enough. Secondly, you can pre-load on the device that is useful in case of a bad connection. Obviously, it’s physically impossible to fit the entire Internet index on the phone. Therefore, it was necessary to go by the local storage of the already-prepared search results for specific queries. For what? No one knows how to predict the future requests of a person with high accuracy (but we are learning). Therefore we take popular repeated requests.
When we talk about popular queries, many imagine a query [VKontakte] and several similar ones. In fact, we have hundreds of thousands of less obvious requests that are regularly repeated in large quantities. And this is many hundreds of megabytes of results. And we planned to save not only search results, but also hints that appear during the query entry process. And here, many will ask: why keep prompts offline, because a person is quite capable of entering a request without them?
When entering requests in the Yandex application, users see not ordinary search tips, but in the form of individual words / word pairs (ie, predictive text input ). Regular prompts cannot be edited: if you need to add a word, you will have to enter the entire query yourself. Hints in the form of words allow you to make edits, cover a much larger number of requests and significantly speed up their input by a person.
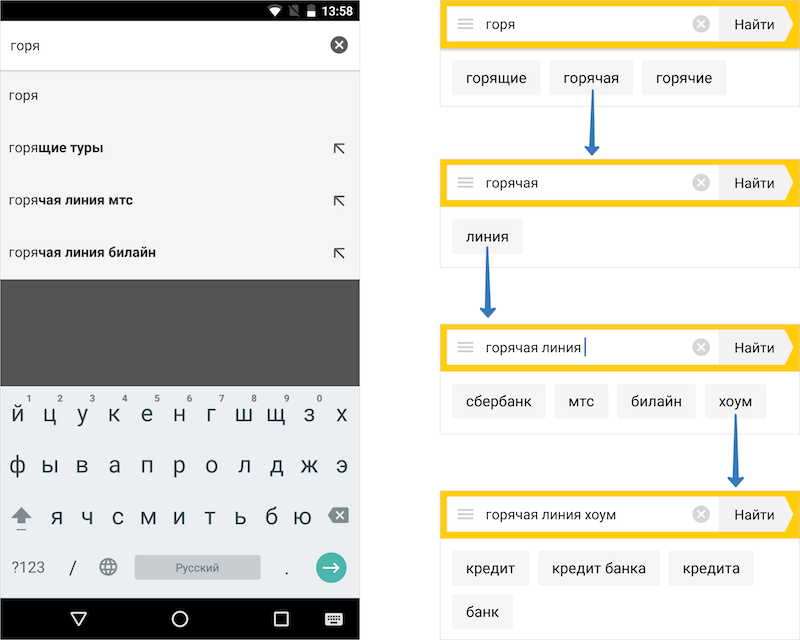
But the main thing is that the tips were especially useful when working offline. These hints help people formulate their question as most do, and this, in turn, increases the chance that the answer will be obtained from the local cache. That is why it was important to keep the tips.
Empirically, we picked up a certain minimum of search queries (about 150 thousand) and prompts, less than which there was no longer any sense to store. But the volume of all this baggage still went beyond decent (a few hundred megabytes). Even taking into account the fact that for each query only the top 10 results were stored. It was necessary to do something.
From optimization to offline
Began to look for all that could be sent "under the knife." Each result contained not only links to sites, but favicons and snippets. Favikonki - these are pictures, which means that here it was possible to achieve serious savings. The same site can be found in the results for completely different queries, so we did not initially duplicate favicons, but stored them across sites. And then we made it so that the probability of saving the favicon is directly proportional to the frequency with which the site appears in the search results. In other words, we have abandoned most faviconok, but visually it is not very striking.
But to give up snippets is not so easy, because this information is no less important for people than the headline. The snippet often already contains the answer to the question. Therefore, for ordinary queries, we have rejected snippets for only the last two results. For navigation, where the first results usually respond well to queries, we have reduced not only the number of snippets to the first 3-4, but also the results themselves to 5 sites instead of 10. Similarly, we reduced all the outputs where there is a response of the witcher .
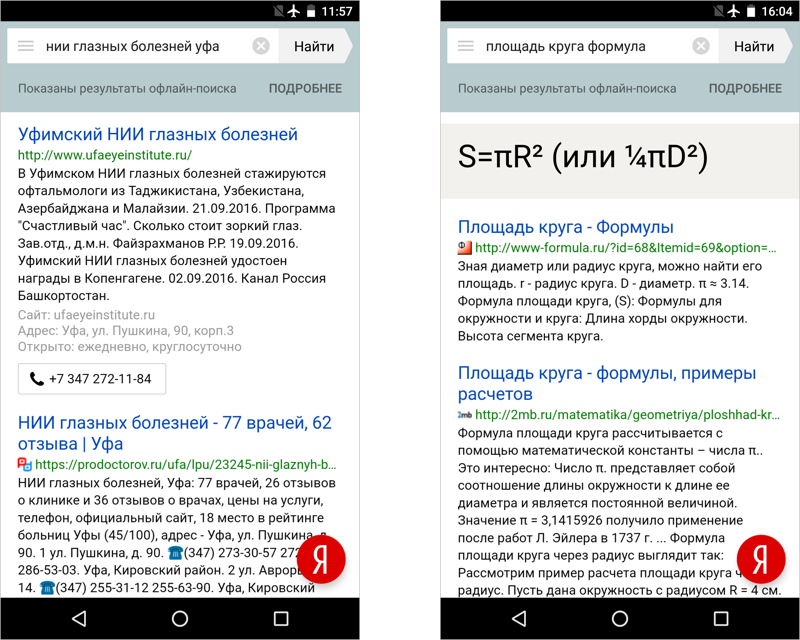
The more we reduced the usual search results in favor of ready-made answers, the closer we came to the understanding that our EDGE search not only speeds up work, but is able to respond to a wide range of questions without an Internet connection at all. Without even noticing, we were already working on an offline search. So, the bet should be done on ready-made answers. Realizing this, we began to enrich the database with important facts that could not get there before because of the popularity of the query. These results contain only the answers, without issuing sites.
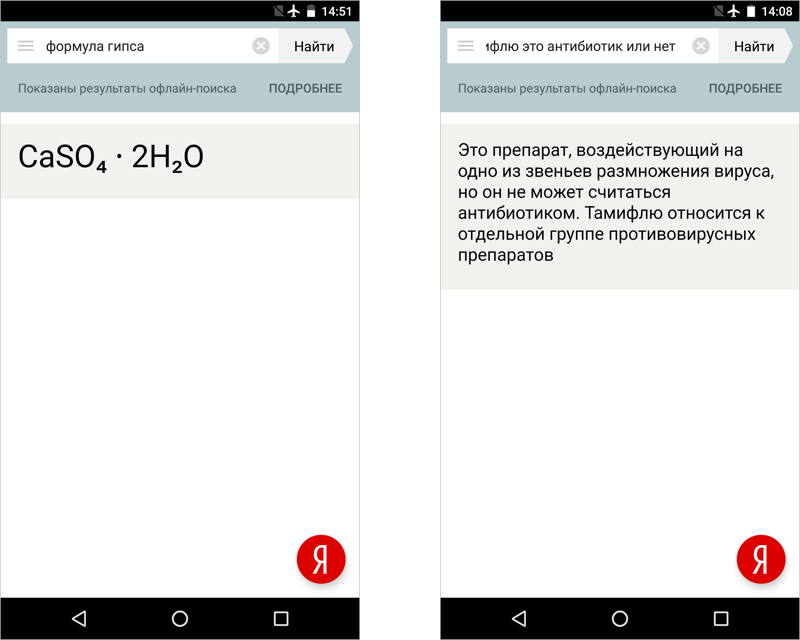
In a similar pattern, we copied into the database all the object response cards and all requests for which the object response is available. Cards for offline search differ from the originals by the almost complete lack of pictures: we removed them for reasons of economy.
The growth of the fact base required further work on optimization and a data storage structure that would be careful with the device resources.
Dictionaries
The base is downloaded to the device not entirely, but in the form of separate dictionaries, and only with a Wi-Fi connection and only with a sufficient charge level. The breakdown into dictionaries is done for two reasons. Firstly, if the connection breaks when loading, then during the next attempt only those dictionaries that did not have time to download earlier will be downloaded. Secondly, to save space, the base is loaded and stored on the device in a compressed form, but with each request it is not unpacked entirely, but only with the necessary parts.
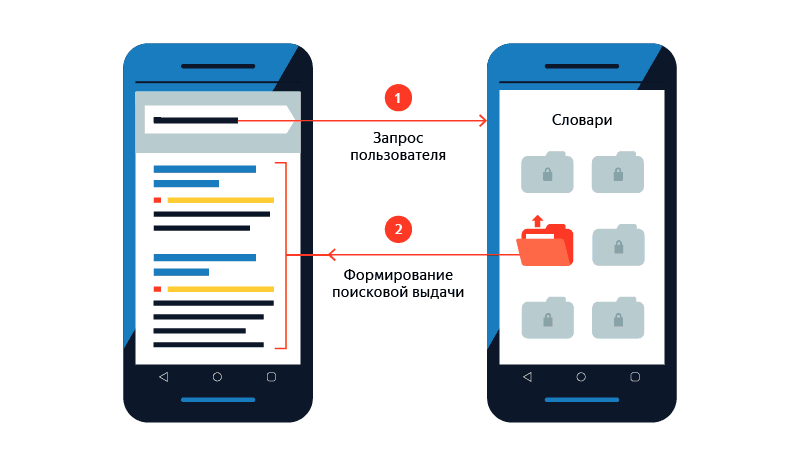
Each dictionary contains queries that begin with specific letters, as well as all the data for issuing and prompts for these queries. Sorting data before dividing it into dictionaries by the first letters of the queries turned out to be more logical than, for example, by their popularity. Imagine the situation: in the first dictionary are the most popular queries, in the second - a little less popular, and so on. But the popularity of queries often changes, and this will lead to the need to regularly update dictionaries only in order to move the query from one to another. These are costs of traffic, energy and time. Therefore, it was important to make sure that when the database was updated, queries did not move between dictionaries. Alphabetical order turned out to be a simple and effective solution.
Answers to the same requests may vary in different parts of the country, therefore, dictionaries are formed for different regions. Moreover, during short-term visits to another region, the application will not be in a hurry with updating the dictionaries - we have provided travel and tourism scenarios.
No matter how hard we try, the offline search does not cover all possible queries, but it already helps out on average every third. As with any average result, this means that one part of users encounters offline answers more often than the other. Therefore, we, of course, allow to completely disable offline search in the settings.
Our team would be interested to know the opinion of Habr's readers about this direction and get feedback on the work of the Yandex beta application for Android. Thank.
But first you need to understand the main thing: why do we even take on offline search, if the sites from the search results are still unavailable in the absence of a network?
')
EDGE search
Yandex radars traditionally show people who enter a request, but then leave the page without waiting for the download due to poor mobile Internet. In this situation, we could not affect the overall quality of the network and the download speed of all sites, but at least the search process was less painful and it was worth a little time to save. Actually, this is why this project was originally called an EDGE search, i.e. search on slow internet.
You can speed up the search in two ways. First, optimize the web version as much as possible and the APIs that the application uses. And this work is also underway, but even this is not enough. Secondly, you can pre-load on the device that is useful in case of a bad connection. Obviously, it’s physically impossible to fit the entire Internet index on the phone. Therefore, it was necessary to go by the local storage of the already-prepared search results for specific queries. For what? No one knows how to predict the future requests of a person with high accuracy (but we are learning). Therefore we take popular repeated requests.
When we talk about popular queries, many imagine a query [VKontakte] and several similar ones. In fact, we have hundreds of thousands of less obvious requests that are regularly repeated in large quantities. And this is many hundreds of megabytes of results. And we planned to save not only search results, but also hints that appear during the query entry process. And here, many will ask: why keep prompts offline, because a person is quite capable of entering a request without them?
When entering requests in the Yandex application, users see not ordinary search tips, but in the form of individual words / word pairs (ie, predictive text input ). Regular prompts cannot be edited: if you need to add a word, you will have to enter the entire query yourself. Hints in the form of words allow you to make edits, cover a much larger number of requests and significantly speed up their input by a person.
But the main thing is that the tips were especially useful when working offline. These hints help people formulate their question as most do, and this, in turn, increases the chance that the answer will be obtained from the local cache. That is why it was important to keep the tips.
Empirically, we picked up a certain minimum of search queries (about 150 thousand) and prompts, less than which there was no longer any sense to store. But the volume of all this baggage still went beyond decent (a few hundred megabytes). Even taking into account the fact that for each query only the top 10 results were stored. It was necessary to do something.
From optimization to offline
Began to look for all that could be sent "under the knife." Each result contained not only links to sites, but favicons and snippets. Favikonki - these are pictures, which means that here it was possible to achieve serious savings. The same site can be found in the results for completely different queries, so we did not initially duplicate favicons, but stored them across sites. And then we made it so that the probability of saving the favicon is directly proportional to the frequency with which the site appears in the search results. In other words, we have abandoned most faviconok, but visually it is not very striking.
But to give up snippets is not so easy, because this information is no less important for people than the headline. The snippet often already contains the answer to the question. Therefore, for ordinary queries, we have rejected snippets for only the last two results. For navigation, where the first results usually respond well to queries, we have reduced not only the number of snippets to the first 3-4, but also the results themselves to 5 sites instead of 10. Similarly, we reduced all the outputs where there is a response of the witcher .
The more we reduced the usual search results in favor of ready-made answers, the closer we came to the understanding that our EDGE search not only speeds up work, but is able to respond to a wide range of questions without an Internet connection at all. Without even noticing, we were already working on an offline search. So, the bet should be done on ready-made answers. Realizing this, we began to enrich the database with important facts that could not get there before because of the popularity of the query. These results contain only the answers, without issuing sites.
In a similar pattern, we copied into the database all the object response cards and all requests for which the object response is available. Cards for offline search differ from the originals by the almost complete lack of pictures: we removed them for reasons of economy.
The growth of the fact base required further work on optimization and a data storage structure that would be careful with the device resources.
Dictionaries
The base is downloaded to the device not entirely, but in the form of separate dictionaries, and only with a Wi-Fi connection and only with a sufficient charge level. The breakdown into dictionaries is done for two reasons. Firstly, if the connection breaks when loading, then during the next attempt only those dictionaries that did not have time to download earlier will be downloaded. Secondly, to save space, the base is loaded and stored on the device in a compressed form, but with each request it is not unpacked entirely, but only with the necessary parts.
Each dictionary contains queries that begin with specific letters, as well as all the data for issuing and prompts for these queries. Sorting data before dividing it into dictionaries by the first letters of the queries turned out to be more logical than, for example, by their popularity. Imagine the situation: in the first dictionary are the most popular queries, in the second - a little less popular, and so on. But the popularity of queries often changes, and this will lead to the need to regularly update dictionaries only in order to move the query from one to another. These are costs of traffic, energy and time. Therefore, it was important to make sure that when the database was updated, queries did not move between dictionaries. Alphabetical order turned out to be a simple and effective solution.
Answers to the same requests may vary in different parts of the country, therefore, dictionaries are formed for different regions. Moreover, during short-term visits to another region, the application will not be in a hurry with updating the dictionaries - we have provided travel and tourism scenarios.
No matter how hard we try, the offline search does not cover all possible queries, but it already helps out on average every third. As with any average result, this means that one part of users encounters offline answers more often than the other. Therefore, we, of course, allow to completely disable offline search in the settings.
Our team would be interested to know the opinion of Habr's readers about this direction and get feedback on the work of the Yandex beta application for Android. Thank.
Source: https://habr.com/ru/post/323422/
All Articles