DariaDB. Database development for storing time series
For more than a year, as I have my own hobby project, in which I am developing a database engine for storing time series - dariadb. The task is quite interesting - there are complex algorithms and a completely new area for me. During the year the engine itself was made, a small server for it and the client. All this is written in C ++. And if the client server is still in a fairly raw state, the engine has already gained some stability. The task of storing time series is fairly common where there are at least some measurements (from SCADA systems to server status monitoring).
To solve this problem, there are a number of solutions of different degrees of tricking:
As an introductory article I can advise an article from FaceBook “ Gorilla: A Fast, Scalable, In-Memory Time Series Database ” widely known in certain circles.
The main task of dariadb was to create an embeddable solution that could be built (like SQLite) into your application and pass it on to storing, processing and analyzing time series. At the moment, the tasks, reception, storage and processing of measurements have been completed. The project is still of a research nature, so now it is not suitable for use in production. Anyway, bye :)
Time series of measurements
The time series of measurements is a sequence of four {Time, Value, Id, Flag}, where
- Time, measurement time (8 bytes)
- Value, itself stopped (8 bytes)
- Id, time series identifier (4 bytes)
- Flag, metering flag (4 bytes)
The flag is used only when reading. There is a special flag “no data” ( _NO_DATA = 0xffffffff), which is set for values that are not at all or do not satisfy the filter. If the request for the flag field is not 0 (zero), then for each dimension that matches the request time, the logical AND operation is applied to its flag flag field; if the answer is equal to the filter, then the measurement passes. The value comes in ascending order of the timestamp (but this is not necessary, sometimes you need to write down the value “into the past”), you need to be able to make a slice and query for intervals.
Read the slice
The cutoff of the value for the time series to the timestamp T is the value that exists at time T or “to the left” of this time. We always return the left nearest, but only if we are satisfied with the flag. If there is no value or the flag does not match, then “no data”. 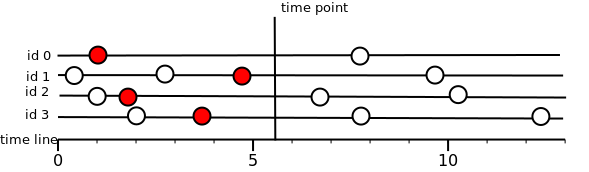
Here it is important to understand why exactly “no data” is returned for values that did not fall under the flag. It may happen that none of the stored values fall under the flag, then it will lead to reading the entire repository. Therefore, it was decided that if there is a value at the time of the cut, but the flag did not match, then we believe that there is no value.
Read interval.
Everything is much simpler: all values that fall in the time interval are returned. Those. the condition from <= T <= to should be satisfied, where T is the time of measurement. 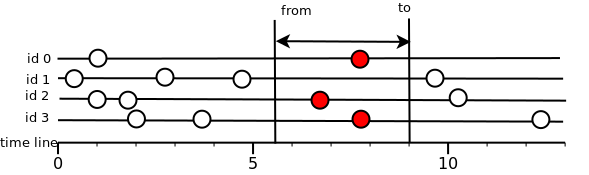
If the measurement falls within the interval, but does not satisfy the flag, then it is rejected. Data is always given to the user in ascending timestamp order.
Minmaxes, latest values, statistics.
It is also possible to get for each time series its minimum and maximum time, which is recorded in the storage; Last recorded value; different statistics on the interval.
Base storage device
The result was a project with the following characteristics:
- Support unsorted values
- Values that are recorded in the repository can no longer be changed.
- Various writing strategies.
- Storage on a disk in the form of an LSM tree ( https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80 %D0BB% D0%B2%D0% BE ).
- High write speed: 2.5 - 3.5 million records per second when writing to disk; 7-9 million records per second when writing to memory.
- Recovery after failures.
- CRC32 for all compressed values.
- Two variants of data request: Functor API (async) - a callback function is transmitted for the request, which will be used for each value that is in the request. Standard API - return values as a list or dictionary.
Statistics on the interval: time min / max; min / max values number of measurements; sum of values
The following layers are implemented: storage in RAM, storage on disk in log files, storage in compressed form.
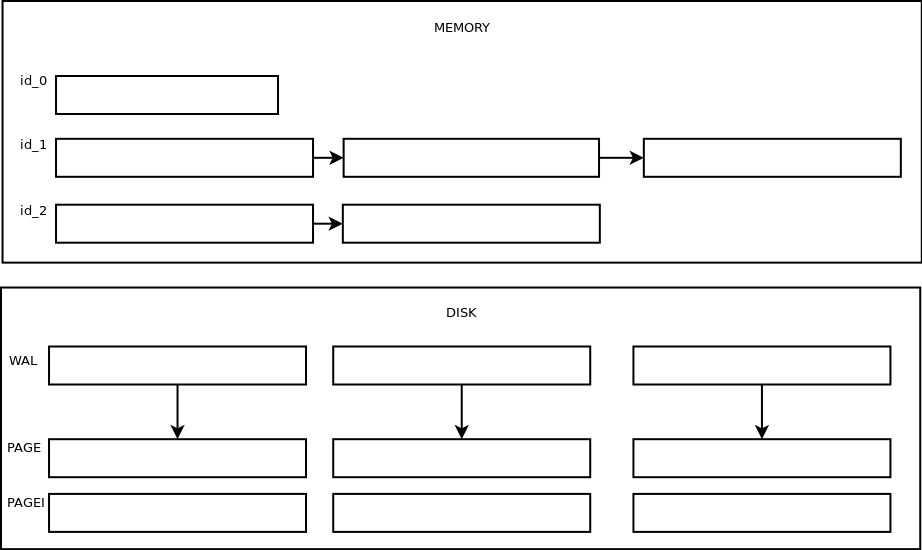
Log files (* .wal)
These are just log files. A small buffer is kept in memory, when filled, it is sorted and flushed to disk. The maximum size of the buffer and the file is regulated by the settings (see below). With requests, the entire file is read and the values in the request are given to the user. No indexes and markers to speed up the search, just a log file. The file name is formed from the creation time of this file in microseconds + extension (wal).
Compressed pages (* .page)
Pages are obtained by compressing log files and their name is the same as the log file from which the page was obtained. If at startup we find that there are pages with the same name (excluding the extension) as the log file, then we conclude that the storage was not stopped in the normal way, the page is deleted and compression is repeated again. These files are already better optimized for reading. They consist of sets of chunks, each chunk stores sorted and compressed values for one time series, the maximum chunk size is limited by settings. At the end of the file is the footer, which stores the minmax of the time, the bloom filter for the id of the time series in the file, statistics for the stored time series.

An index file is created for each page. The index file contains a set of minmaks of time for each chunk in the page, the id of the time series, the position in the page. Thus, when querying for an interval or a slice, we just need to find the necessary chunks in the index file and subtract them from the page. In each chunk, the values are stored in a compressed form. Each measurement field has its own algorithm (inspired by the famous article “Gorilla: A Fast, Scalable, In-Memory Time Series Database”):
DeltaDelta - for time
Xor - for the values themselves
LEB128 - for flags
As a result, compression on different data reaches up to 3 times.
Index file footers are always in the cache and are used to quickly search for the necessary pages to display results.
Memory storage
In memory, each time series is stored in a list (a simple std :: list from stl) chunks, and for a quick search, a B + tree is built over all of this, built on the maximum time of each chunk. Thus, when requesting an interval or a slice, we simply find chunks that contain the data we need, unpack them and return them. Storage in memory is limited in maximum size, i.e. if we write too vigorously into it, the limit will end quickly and then everything will go according to the scenario determined by the storage strategy
Storage strategies
WAL - data is written only to log files, clipping to pages does not automatically start, but it is possible to start compression of all log files manually.
COMPRESSED - data is written to the log files, but as soon as the file reaches the limit (see settings), a new file is created next to it, and the old one is put in a queue for compression.
MEMORY - everything is written into memory, as soon as we reach the limit, the oldest chunks are starting to be flushed to disk.
- CACHE - we write both to memory and to disk. This strategy gives a write speed like that of COMPRESSED, but a quick search for fresh recently recorded data. For this, the memory limit is also relevant, if we reach it, the old chunks are simply deleted.
Repacking and writing to the past.
It is possible to record data in any order. If the MEMORY strategy and we are writing to the past, which is still in memory, then we will simply add new data to the existing chunk. If we write so far into the past that this time is no longer in memory, or the storage strategy is not MEMORY, then the data will be written to the current chunk, but when reading the data, the k-merge algorithm will be used, which slows down the reading a little if There are many such chunks. To avoid this, there is a call to repack, which repackages pages, removing duplicates and sorting data in ascending order of time. At the same time, pages collapse so that at each level there are no more pages than specified by the settings (LSM is a tree).
Creating a time series
The selection of an identifier for a time series can be implemented independently, or it can be assigned to dariadb - the ability to create named time series is implemented, then by name you can get an identifier, and it can be registered in the desired measurement. It is easier than it seems. In any case, if you record a measurement, but it is not described in the file with time series (it is created automatically during storage initialization), then the measurement will be recorded without any problems.
Settings
Settings can be set through the Settings class (see example below). The following settings are available:
- wal_file_size - the maximum size of the log file in dimensions (not in bytes!).
- wal_cache_size is the size of the buffer in memory, to which measurements are written, before getting into the log file.
- chunk_size - the size of the chunk in bytes. strategy - the storage strategy.
- memory_limit is the maximum amount of memory used by the storage in RAM.
- percent_when_start_droping — The percentage of the RAM’s memory full of storage when the reset of chunks begins.
- percent_to_drop - how many percent of memory should be cleared when we reached the limit of memory.
- max_pages_in_level - the maximum number of pages (.page) at each level.
Final benchmarks
I will give speed characteristics on typical tasks.
Conditions:
2 streams write 50 time series, in each row of measurement for 2 days. Measurement frequency - 2 measurements per second. As a result, we get 2000000 measurements. Machine Intel core i5 2.8 760 @ GHz, 8 Gb ram, hard disk WDC WD5000AAKS, Windows 7
Average write speed per second:
| WAL, zp / sec | Compressed, zp / sec | MEMORY, Zap / sec | CACHE, ZP / s |
|---|---|---|---|
| 2.600.000 | 420.000 | 5,000,000 | 420.000 |
Reading the slice.
N random time series is selected, for each there is a time at which exactly there are values and a slice is requested for a random time in this interval.
| WAL, sec | Compressed, sec | MEMORY, sec | CACHE, sec |
|---|---|---|---|
| 0.03 | 0.02 | 0.005 | 0.04 |
Time reading interval for 2 days for all values:
| WAL, sec | Compressed, sec | MEMORY, sec | CACHE, sec |
|---|---|---|---|
| 13 | 13 | 0.5 | five |
Read interval for a random amount of time
| WAL, z / a | Compressed, z / a | MEMORY, zap / s | CACHE, z / a |
|---|---|---|---|
| 2.043.925 | 2.187.507 | 27.469.500 | 20.321.500 |
How to collect and try everything.
The project was immediately thought of as cross-platform, its development goes on windows and ubuntu / linux. Compilers gcc-6 and msvc-14 are supported. Building via clang is not supported yet.
Dependencies
On Ubuntu 14.04, you need to connect ppa ubuntu-toolchain-r-test:
$ sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test $ sudo apt-get update $ sudo apt-get install -y libboost-dev libboost-coroutine-dev libboost-context-dev libboost-filesystem-dev libboost-test-dev libboost-program-options-dev libasio-dev libboost-log-dev libboost-regex-dev libboost-date-time-dev cmake g++-6 gcc-6 cpp-6 $ export CC="gcc-6" $ export CXX="g++-6" An example of using as an embedded project ( https://github.com/lysevi/dariadb-example )
$ git clone https://github.com/lysevi/dariadb-example $ cd dariadb-example $ git submodule update --init --recursive $ cmake . Build the project from the developer
$ git clone https://github.com/lysevi/dariadb.git $ cd dariadb $ git submodules init $ git submodules update $ cmake . Running tests
$ ctest --verbose . Example
Creation of storage and filling with values
#include <iostream> #include <libdariadb/dariadb.h> #include <libdariadb/utils/fs.h> int main(int, char **) { const std::string storage_path = "exampledb"; // , if (dariadb::utils::fs::path_exists(storage_path)) { dariadb::utils::fs::rm(storage_path); } // . auto settings = dariadb::storage::Settings::create(storage_path); settings->save(); // . p1 p2 // auto scheme = dariadb::scheme::Scheme::create(settings); auto p1 = scheme->addParam("group.param1"); auto p2 = scheme->addParam("group.subgroup.param2"); scheme->save(); // . auto storage = std::make_unique<dariadb::Engine>(settings); auto m = dariadb::Meas(); auto start_time = dariadb::timeutil::current_time(); // // // [currentTime:currentTime+10] m.time = start_time; for (size_t i = 0; i < 10; ++i) { if (i % 2) { m.id = p1; } else { m.id = p2; } m.time++; m.value++; m.flag = 100 + i % 2; auto status = storage->append(m); if (status.writed != 1) { std::cerr << "Error: " << status.error_message << std::endl; } } } Opening storage and reading interval.
#include <libdariadb/dariadb.h> #include <iostream> // void print_measurement(dariadb::Meas&measurement){ std::cout << " id: " << measurement.id << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } void print_measurement(dariadb::Meas&measurement, dariadb::scheme::DescriptionMap&dmap) { std::cout << " param: " << dmap[measurement.id] << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } class QuietLogger : public dariadb::utils::ILogger { public: void message(dariadb::utils::LOG_MESSAGE_KIND kind, const std::string &msg) override {} }; class Callback : public dariadb::IReadCallback { public: Callback() {} void apply(const dariadb::Meas &measurement) override { std::cout << " id: " << measurement.id << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } void is_end() override { std::cout << "calback end." << std::endl; dariadb::IReadCallback::is_end(); } }; int main(int, char **) { const std::string storage_path = "exampledb"; // . , // dariadb::utils::ILogger_ptr log_ptr{new QuietLogger()}; dariadb::utils::LogManager::start(log_ptr); auto storage = dariadb::open_storage(storage_path); auto scheme = dariadb::scheme::Scheme::create(storage->settings()); // . auto all_params = scheme->ls(); dariadb::IdArray all_id; all_id.reserve(all_params.size()); all_id.push_back(all_params.idByParam("group.param1")); all_id.push_back(all_params.idByParam("group.subgroup.param2")); dariadb::Time start_time = dariadb::MIN_TIME; dariadb::Time cur_time = dariadb::timeutil::current_time(); // dariadb::QueryInterval qi(all_id, dariadb::Flag(), start_time, cur_time); dariadb::MeasList readed_values = storage->readInterval(qi); std::cout << "Readed: " << readed_values.size() << std::endl; for (auto measurement : readed_values) { print_measurement(measurement, all_params); } // std::cout << "Callback in interval: " << std::endl; std::unique_ptr<Callback> callback_ptr{new Callback()}; storage->foreach (qi, callback_ptr.get()); callback_ptr->wait(); { // auto stat = storage->stat(dariadb::Id(0), start_time, cur_time); std::cout << "count: " << stat.count << std::endl; std::cout << "time: [" << dariadb::timeutil::to_string(stat.minTime) << " " << dariadb::timeutil::to_string(stat.maxTime) << "]" << std::endl; std::cout << "val: [" << stat.minValue << " " << stat.maxValue << "]" << std::endl; std::cout << "sum: " << stat.sum << std::endl; } } Read data slice
Here, opening the repository and getting identifiers is no different from the previous example, so I will give only an example of getting a slice
dariadb::Time cur_time = dariadb::timeutil::current_time(); // ; dariadb::QueryTimePoint qp(all_id, dariadb::Flag(), cur_time); dariadb::Id2Meas timepoint = storage->readTimePoint(qp); std::cout << "Timepoint: " << std::endl; for (auto kv : timepoint) { auto measurement = kv.second; print_measurement(measurement, all_params); } // dariadb::Id2Meas cur_values = storage->currentValue(all_id, dariadb::Flag()); std::cout << "Current: " << std::endl; for (auto kv : timepoint) { auto measurement = kv.second; print_measurement(measurement, all_params); } // . std::cout << "Callback in timepoint: " << std::endl; std::unique_ptr<Callback> callback_ptr{new Callback()}; storage->foreach (qp, callback_ptr.get()); callback_ptr->wait(); Links
')
Source: https://habr.com/ru/post/323256/
All Articles