Open machine learning course. Topic 2: Data Visualization with Python

The second lesson is devoted to data visualization in Python. First, we will look at the basic methods of the Seaborn and Plotly libraries, then we will analyze the data set familiar to us from the first article on the outflow of customers of the telecom operator and look into the n-dimensional space using the t-SNE algorithm. There is also a video of a lecture based on this article as part of the second launch of the open course (September-November 2017).
UPD: now the course is in English under the brand mlcourse.ai with articles on Medium, and materials on Kaggle ( Dataset ) and on GitHub .
Now the article will be much longer. Ready? Go!
- Primary data analysis with Pandas
- Visual data analysis with Python
- Classification, decision trees and the method of nearest neighbors
- Linear classification and regression models
- Compositions: bagging, random forest
- Construction and selection of signs
- Teaching without a teacher: PCA, clustering
- Training in gigabytes with Vowpal Wabbit
- Time Series Analysis with Python
- Gradient boosting
Plan for this article
- Demonstration of the main methods of Seaborn and Plotly
- An example of visual data analysis
- Peeping into n-dimensional space with t-SNE
- Homework number 2
- Overview of useful resources
Demonstration of the main methods of Seaborn and Plotly
At the beginning, as always, we set up the environment: we import all the necessary libraries and slightly adjust the default display of images.
# Anaconda import warnings warnings.simplefilter('ignore') # jupyter'e %matplotlib inline import seaborn as sns import matplotlib.pyplot as plt # svg %config InlineBackend.figure_format = 'svg' # from pylab import rcParams rcParams['figure.figsize'] = 8, 5 import pandas as pd After that we will load data with which we will work into DataFrame . For the examples, I chose the sales and rating data for video games from Kaggle Datasets .
df = pd.read_csv('../../data/video_games_sales.csv') df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 16719 entries, 0 to 16718 Data columns (total 16 columns): Name 16717 non-null object Platform 16719 non-null object Year_of_Release 16450 non-null float64 Genre 16717 non-null object Publisher 16665 non-null object NA_Sales 16719 non-null float64 EU_Sales 16719 non-null float64 JP_Sales 16719 non-null float64 Other_Sales 16719 non-null float64 Global_Sales 16719 non-null float64 Critic_Score 8137 non-null float64 Critic_Count 8137 non-null float64 User_Score 10015 non-null object User_Count 7590 non-null float64 Developer 10096 non-null object Rating 9950 non-null object dtypes: float64(9), object(7) memory usage: 2.0+ MB Some features that pandas counted as object will be explicitly cast to float or int types.
df['User_Score'] = df.User_Score.astype('float64') df['Year_of_Release'] = df.Year_of_Release.astype('int64') df['User_Count'] = df.User_Count.astype('int64') df['Critic_Count'] = df.Critic_Count.astype('int64') Data is not available for all games, so let's leave only those records that do not have gaps using the dropna method.
df = df.dropna() print(df.shape) (6825, 16) In total, there are 6825 objects in the table and 16 features for them. Let's look at the first few entries using the head method to make sure that everything is correct. For convenience, I left only those signs that we will continue to use.
useful_cols = ['Name', 'Platform', 'Year_of_Release', 'Genre', 'Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count', 'Rating' ] df[useful_cols].head() 
Before we get into the methods of the seaborn and plotly , let's discuss the simplest and often convenient way to visualize data from the pandas DataFrame - use the plot function.
For example, let's build a graph of sales of video games in different countries depending on the year. To begin with, we filter only the columns we need, then calculate the total sales by year and call the plot function with no parameters for the resulting DataFrame .
sales_df = df[[x for x in df.columns if 'Sales' in x] + ['Year_of_Release']] sales_df.groupby('Year_of_Release').sum().plot() The implementation of the plot function in pandas based on the matplotlib library.
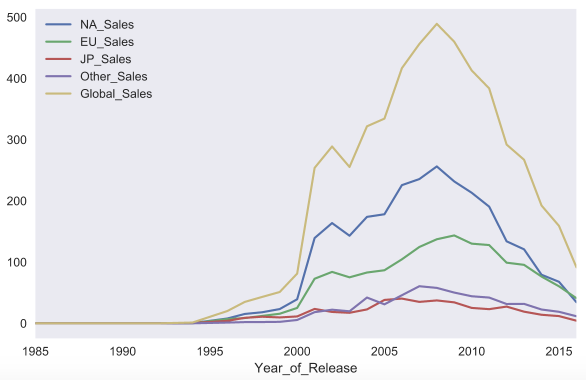
Using the kind parameter, you can change the type of chart, for example, to bar chart . Matplotlib allows you to customize graphics very flexibly. On the graph, you can change almost anything, but you will need to rummage through the documentation and find the necessary parameters. For example, the parameter rot is responsible for the slope of the labels to the x axis.
sales_df.groupby('Year_of_Release').sum().plot(kind='bar', rot=45) 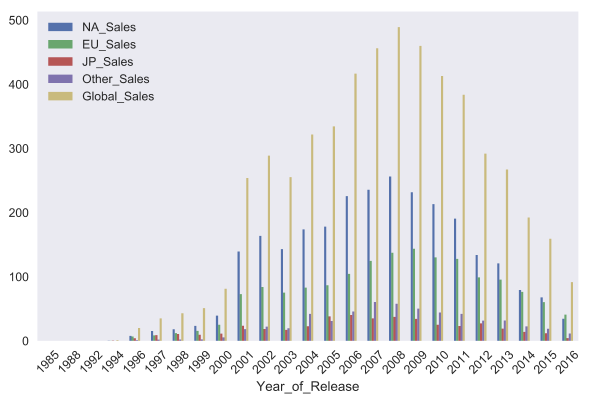
Seaborn
Now let's go to the seaborn library. Seaborn is essentially a higher level API based on the matplotlib library. Seaborn contains more adequate default settings for graphic design. Also in the library there are quite complex types of visualization, which in matplotlib would require a large amount of code.
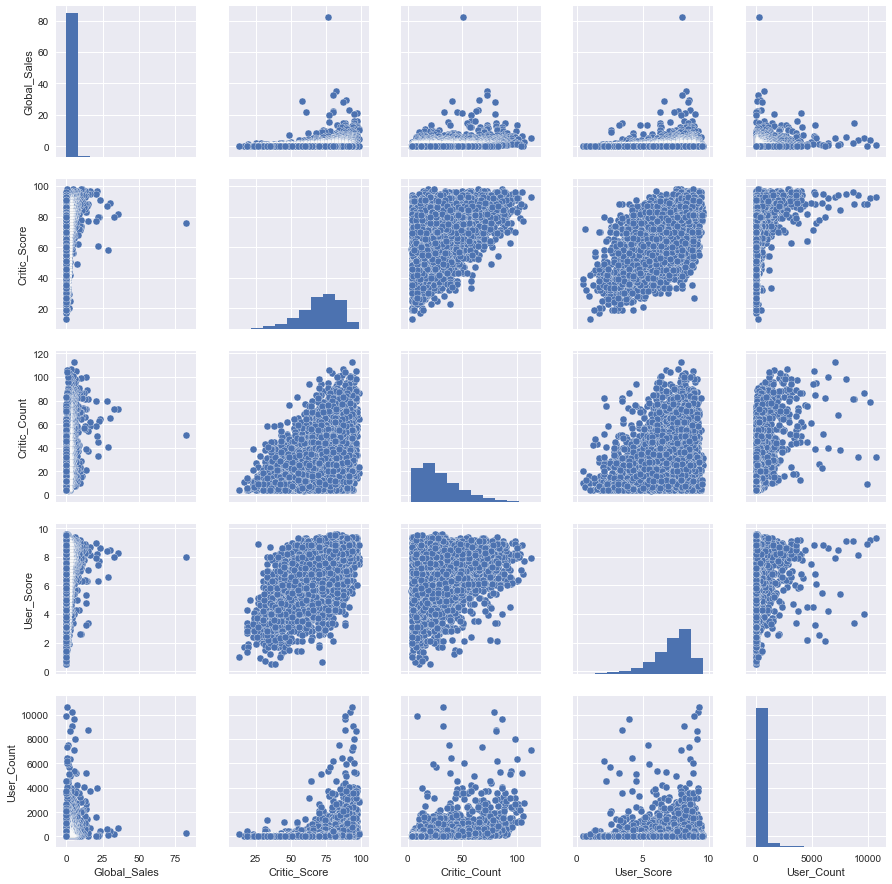
Let's get acquainted with the first such "complex" type of graphs of the pair plot ( scatter plot matrix ). This visualization will help us to look at one picture, as different signs are interconnected.
cols = ['Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count'] sns_plot = sns.pairplot(df[cols]) sns_plot.savefig('pairplot.png') As you can see, histograms of the sign distributions are located on the diagonal of the matrix of graphs. The rest of the graphs are the usual scatter plots for the corresponding pairs of signs.
To save graphs to files, use the savefig method.
With the help of seaborn you can also build dist plot distribution. For example, let's look at the distribution of Critic_Score critics' Critic_Score . By default, a histogram and kernel density estimation are displayed on the graph.
sns.distplot(df.Critic_Score) 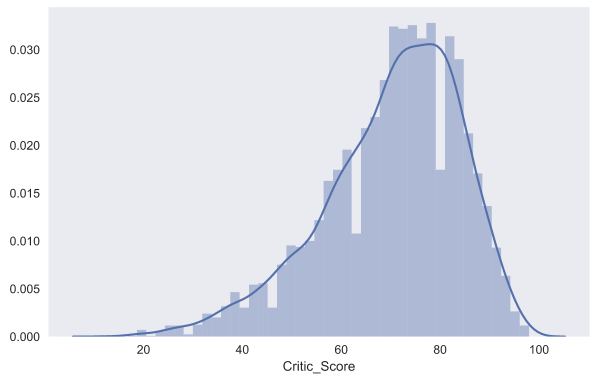
In order to take a closer look at the relationship of two numerical features, there is also a joint plot - this is a hybrid of the scatter plot and histogram . Let's look at how the critique of Critic_Score and Critic_Score are related to each other.
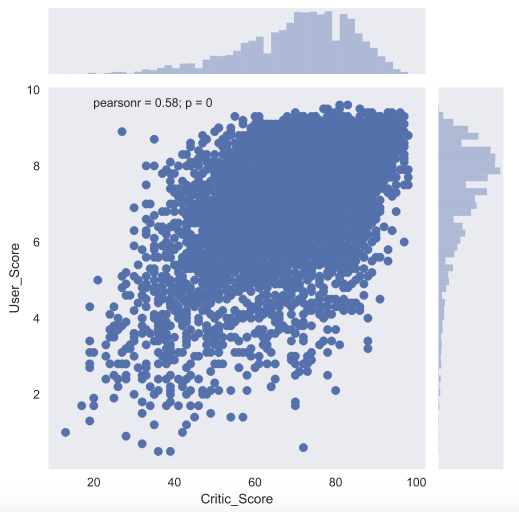
Another useful type of graph is box plot . Let's compare the ratings of games from critics for the top 5 largest gaming platforms.
top_platforms = df.Platform.value_counts().sort_values(ascending = False).head(5).index.values sns.boxplot(y="Platform", x="Critic_Score", data=df[df.Platform.isin(top_platforms)], orient="h") 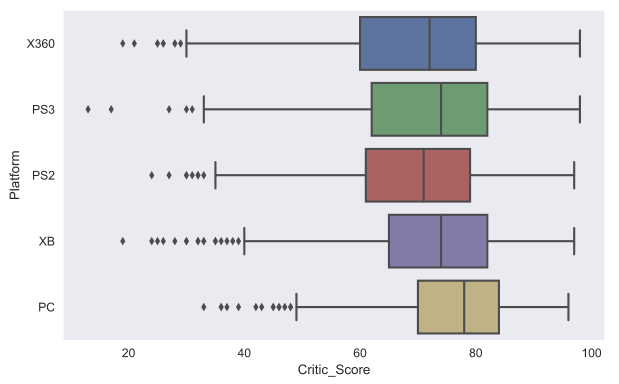
I think it is worth discussing a little more in detail how to understand box plot . Box plot consists of a box (which is why it is called a box plot ), antenna bars and points. The box shows the interquartile range of distribution, that is, respectively 25% ( Q1 ) and 75% ( Q3 ) percentile. The dash inside the box indicates the median of the distribution.
With the box figured out, let's go to the mustache. The whiskers reflect the entire range of points except for outliers, that is, the minimum and maximum values that fall in the gap (Q1 - 1.5*IQR, Q3 + 1.5*IQR) , where IQR = Q3 - Q1 is the interquartile range. The dots on the graph indicate outliers (those values that do not fit into the range of values given by the graph mustache).
It’s better to see once to understand, so here’s a picture from Wikipedia :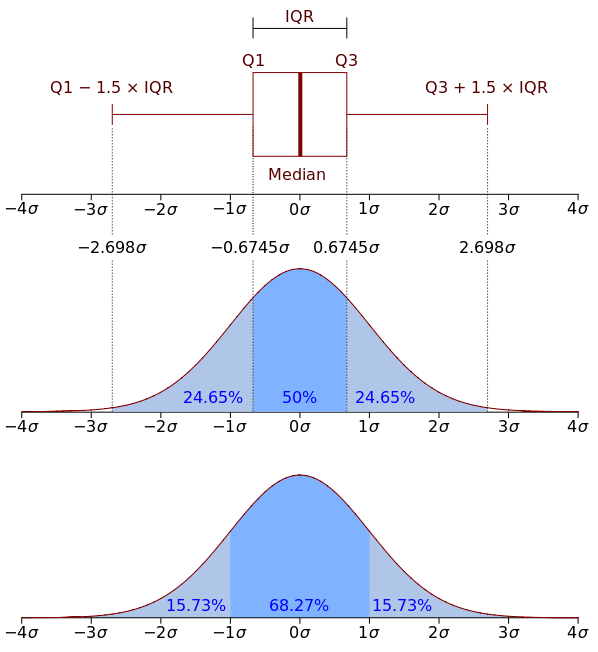
And one more type of graphs (the last of those we consider in this article) is the heat map . Heat map allows you to look at the distribution of a numerical trait by two categorical. We visualize the total sales of games by genre and gaming platforms.
platform_genre_sales = df.pivot_table( index='Platform', columns='Genre', values='Global_Sales', aggfunc=sum).fillna(0).applymap(float) sns.heatmap(platform_genre_sales, annot=True, fmt=".1f", linewidths=.5) 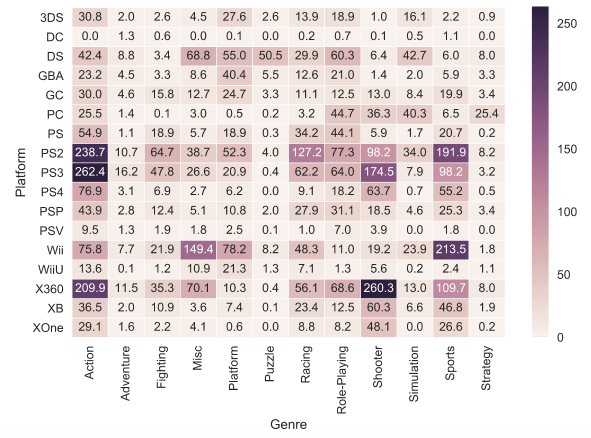
Plotly
We looked at visualizations based on the matplotlib library. However, this is not the only option for python graphing. We will also plotly acquainted with the plotly library. Plotly is an open-source library that allows you to build interactive graphics in jupyter.notebook'e without having to dig into javascript code.
The beauty of interactive graphs is that you can see the exact numerical value when you hover the mouse, hide uninteresting rows in the visualization, zoom in on a certain part of the graph, etc.
Before we begin, we import all the necessary modules and initialize plotly using the init_notebook_mode .
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot import plotly import plotly.graph_objs as go init_notebook_mode(connected=True) To begin with, we will build a line plot with the dynamics of the number of games released and their sales by year.
# years_df = df.groupby('Year_of_Release')[['Global_Sales']].sum().join( df.groupby('Year_of_Release')[['Name']].count() ) years_df.columns = ['Global_Sales', 'Number_of_Games'] # trace0 = go.Scatter( x=years_df.index, y=years_df.Global_Sales, name='Global Sales' ) # trace1 = go.Scatter( x=years_df.index, y=years_df.Number_of_Games, name='Number of games released' ) # title layout data = [trace0, trace1] layout = {'title': 'Statistics of video games'} # c Figure fig = go.Figure(data=data, layout=layout) iplot(fig, show_link=False) In plotly visualization of the object Figure , which consists of data (an array of lines, which are called traces in the library) and design / style, is responsible for the layout object. In simple cases, you can call the iplot function and just from the traces array.
The show_link parameter show_link responsible for links to the plot.ly online platform on the graphs. Since usually this functionality is not needed, I prefer to hide it to prevent accidental clicks.
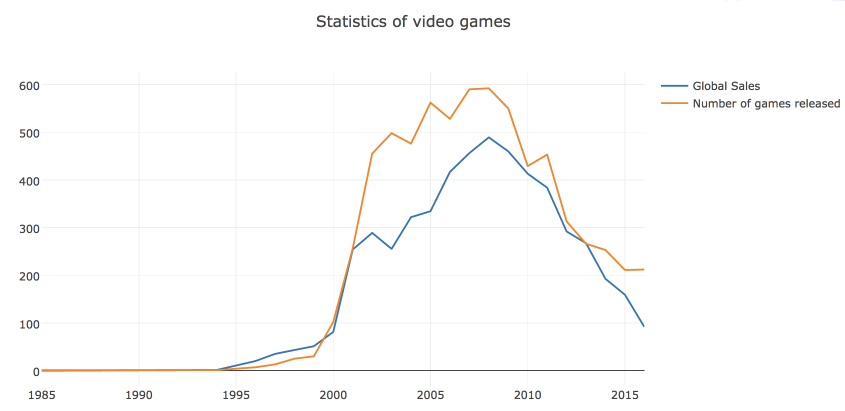
You can immediately save the graph as an html file.
plotly.offline.plot(fig, filename='years_stats.html', show_link=False) We will also look at the market share of gaming platforms, calculated by the number of games released and by total revenue. To do this, build a bar chart .
# platforms_df = df.groupby('Platform')[['Global_Sales']].sum().join( df.groupby('Platform')[['Name']].count() ) platforms_df.columns = ['Global_Sales', 'Number_of_Games'] platforms_df.sort_values('Global_Sales', ascending=False, inplace=True) # traces trace0 = go.Bar( x=platforms_df.index, y=platforms_df.Global_Sales, name='Global Sales' ) trace1 = go.Bar( x=platforms_df.index, y=platforms_df.Number_of_Games, name='Number of games released' ) # title x layout data = [trace0, trace1] layout = {'title': 'Share of platforms', 'xaxis': {'title': 'platform'}} # Figure fig = go.Figure(data=data, layout=layout) iplot(fig, show_link=False) 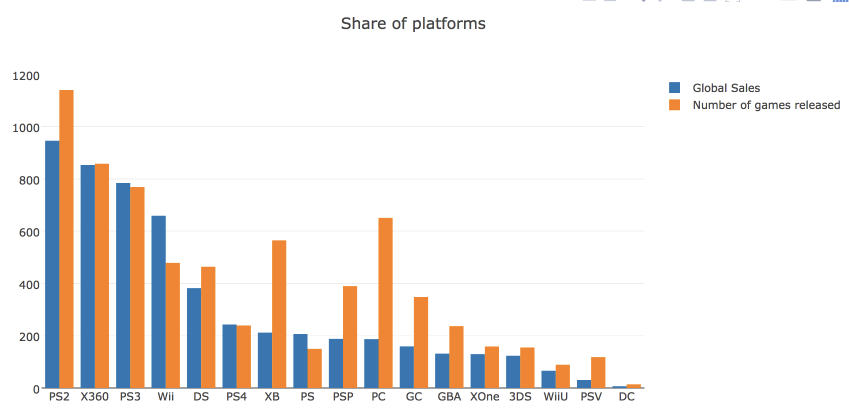
In plotly you can build a box plot . Consider the distribution of critics' ratings depending on the game genre.
# Box trace data = [] for genre in df.Genre.unique(): data.append( go.Box(y=df[df.Genre==genre].Critic_Score, name=genre) ) # iplot(data, show_link = False) 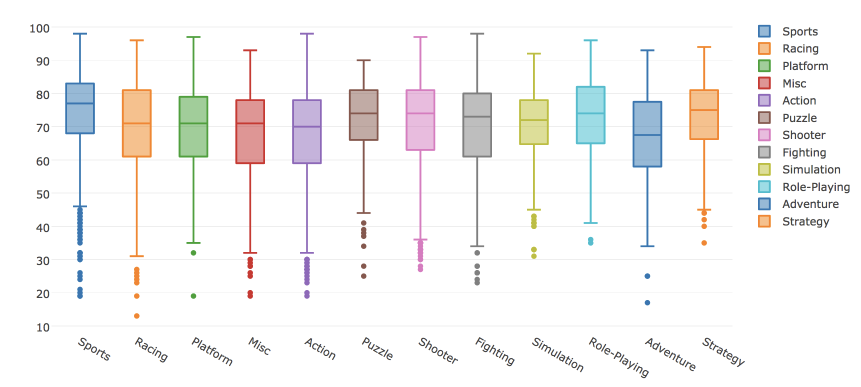
With the help of plotly you can build other types of visualizations. The graphics are pretty nice with default settings. However, the library allows you to flexibly customize various rendering parameters: colors, fonts, captions, annotations, and more.
An example of visual data analysis
We read in DataFrame data on the outflow of customers of the telecom operator familiar to us from the first article .
df = pd.read_csv('../../data/telecom_churn.csv') Check whether everything was considered normal - let's look at the first 5 lines ( head method).
df.head() 
Number of rows (clients) and columns (features):
df.shape (3333, 20) Let's look at the signs and see that there are no gaps in any of them - there are 3333 entries everywhere.
df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 3333 entries, 0 to 3332 Data columns (total 20 columns): State 3333 non-null object Account length 3333 non-null int64 Area code 3333 non-null int64 International plan 3333 non-null object Voice mail plan 3333 non-null object Number vmail messages 3333 non-null int64 Total day minutes 3333 non-null float64 Total day calls 3333 non-null int64 Total day charge 3333 non-null float64 Total eve minutes 3333 non-null float64 Total eve calls 3333 non-null int64 Total eve charge 3333 non-null float64 Total night minutes 3333 non-null float64 Total night calls 3333 non-null int64 Total night charge 3333 non-null float64 Total intl minutes 3333 non-null float64 Total intl calls 3333 non-null int64 Total intl charge 3333 non-null float64 Customer service calls 3333 non-null int64 Churn 3333 non-null bool dtypes: bool(1), float64(8), int64(8), object(3) memory usage: 498.1+ KB | Title | Description | Type of |
|---|---|---|
| State | State letter code | categorical |
| Account length | How long does a customer have been served by the company? | quantitative |
| Area code | Phone number prefix | quantitative |
| International plan | International roaming (connected / not connected) | binary |
| Voice mail plan | Voicemail (connected / not connected) | binary |
| Number vmail messages | Number of voice messages | quantitative |
| Total day minutes | Total duration of conversations in the afternoon | quantitative |
| Total day calls | Total number of calls during the day | quantitative |
| Total day charge | Total amount of payment for services in the afternoon | quantitative |
| Total eve minutes | The total duration of conversations in the evening | quantitative |
| Total eve calls | Total number of calls in the evening | quantitative |
| Total eve charge | The total amount of payment for services in the evening | quantitative |
| Total night minutes | The total duration of conversations at night | quantitative |
| Total night calls | Total number of calls at night | quantitative |
| Total night charge | Total payment for services at night | quantitative |
| Total intl minutes | Total duration of international calls | quantitative |
| Total intl calls | Total international calls | quantitative |
| Total intl charge | Total amount of payment for international calls | quantitative |
| Customer service calls | The number of calls to the service center | quantitative |
Target variable: Churn - Outflow symptom, binary (1 - client loss, i.e. outflow). Then we will build models that predict this sign for the rest, so we called it target.
Let's look at the distribution of the target class - customer churn.
df['Churn'].value_counts() False 2850 True 483 Name: Churn, dtype: int64 df['Churn'].value_counts().plot(kind='bar', label='Churn') plt.legend() plt.title(' '); 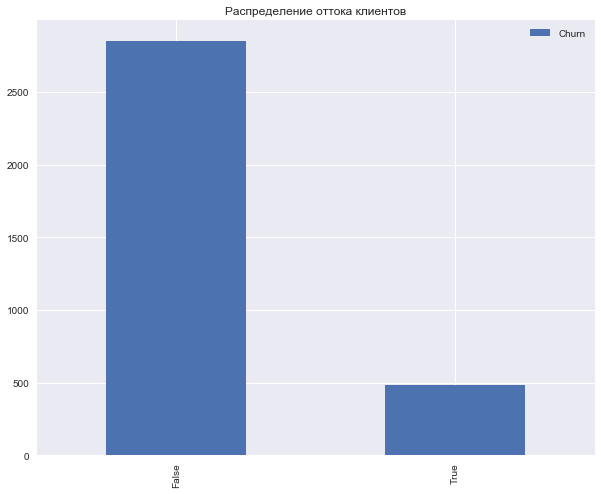
Select the following groups of signs (among all but Churn ):
- binary: International plan , Voice mail plan
- categorical: State
- serial: Customer service calls
- quantitative: all others
Let's look at the correlation of quantitative traits. From the colored correlation matrix, one can see that signs such as Total day charge are counted according to the minutes spoken ( Total day minutes ). That is, 4 signs can be thrown out, they do not carry useful information.
corr_matrix = df.drop(['State', 'International plan', 'Voice mail plan', 'Area code'], axis=1).corr() sns.heatmap(corr_matrix); 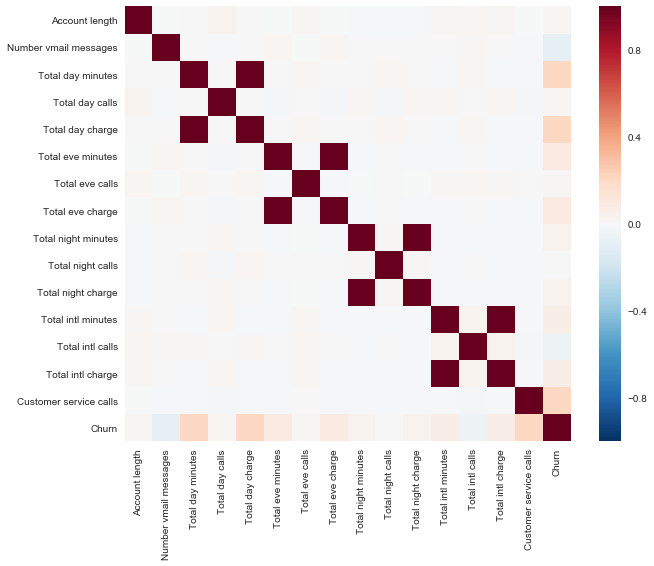
')
Now let's look at the distribution of all quantitative traits of interest to us. We will look at binary / categorical / ordinal signs separately.
features = list(set(df.columns) - set(['State', 'International plan', 'Voice mail plan', 'Area code', 'Total day charge', 'Total eve charge', 'Total night charge', 'Total intl charge', 'Churn'])) df[features].hist(figsize=(20,12)); 
We see that most of the signs are distributed normally. Exceptions are the number of calls to the service center ( Customer service calls ) (the Poisson distribution is more appropriate here) and the number of voice messages ( Number vmail messages , the peak at zero, that is, those whose voicemail is not connected). The distribution of the number of international calls ( Total intl calls ) is also shifted.
It is also useful to build such pictures, where the distribution of signs are drawn on the main diagonal, and outside the main diagonal there are scatter diagrams for pairs of signs. It happens that this leads to some conclusions, but in this case, everything is approximately clear, without surprises.
sns.pairplot(df[features + ['Churn']], hue='Churn'); 
Next, we will look at how the signs are related to the target - to the outflow.
Construct boxplot-s, describing the statistics of the distribution of quantitative traits in two groups: among loyal and departed customers.
fig, axes = plt.subplots(nrows=3, ncols=4, figsize=(16, 10)) for idx, feat in enumerate(features): sns.boxplot(x='Churn', y=feat, data=df, ax=axes[idx / 4, idx % 4]) axes[idx / 4, idx % 4].legend() axes[idx / 4, idx % 4].set_xlabel('Churn') axes[idx / 4, idx % 4].set_ylabel(feat); 
By eye, we see the biggest difference for the signs of Total day minutes , Customer service calls and Number vmail messages . Subsequently, we will learn to determine the importance of signs in a classification task using random forest (or gradient boosting), and it turns out that the first two are really very important signs for predicting outflow.
Let's look separately at the pictures with the distribution of the number of minutes spoken in the afternoon among loyal / departed. On the left - familiar to us boxboxes, on the right - smoothed histograms of the distribution of a numerical attribute in two groups (rather, rather, a beautiful picture, everything is clear from boxsplot).
An interesting observation: on average, retired customers use more communication. Perhaps they are dissatisfied with tariffs, and one of the measures to combat the outflow will be a reduction in tariff rates (the cost of mobile communication). But this is the company will need to conduct additional economic analysis, whether such measures will be justified.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) sns.boxplot(x='Churn', y='Total day minutes', data=df, ax=axes[0]); sns.violinplot(x='Churn', y='Total day minutes', data=df, ax=axes[1]); 
Now we will depict the distribution of the number of calls to the service center (we built this picture in the first article). There are not many unique values of the feature (the feature can be considered both quantitative integer and ordinal), and more graphically depict the distribution using countplot . Observation: the share of churn increases greatly from 4 calls to the service center.
sns.countplot(x='Customer service calls', hue='Churn', data=df); 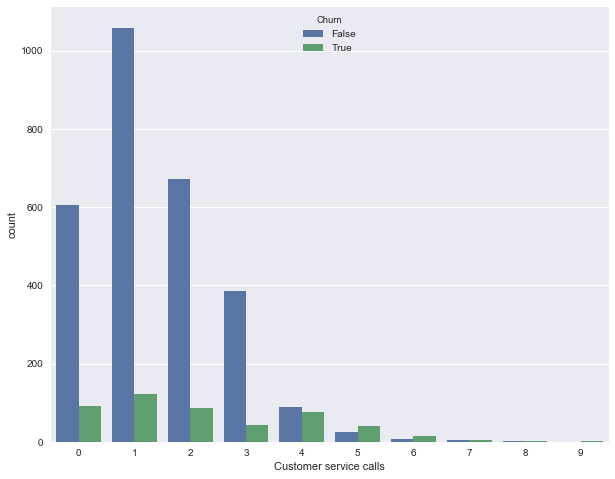
Now let's look at the connection between the binary features of the International plan and the Voice mail plan with the outflow. Observation : when roaming is connected, the outflow rate is much higher, i.e. International roaming is a strong sign. About voice mail this can not be said.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) sns.countplot(x='International plan', hue='Churn', data=df, ax=axes[0]); sns.countplot(x='Voice mail plan', hue='Churn', data=df, ax=axes[1]); 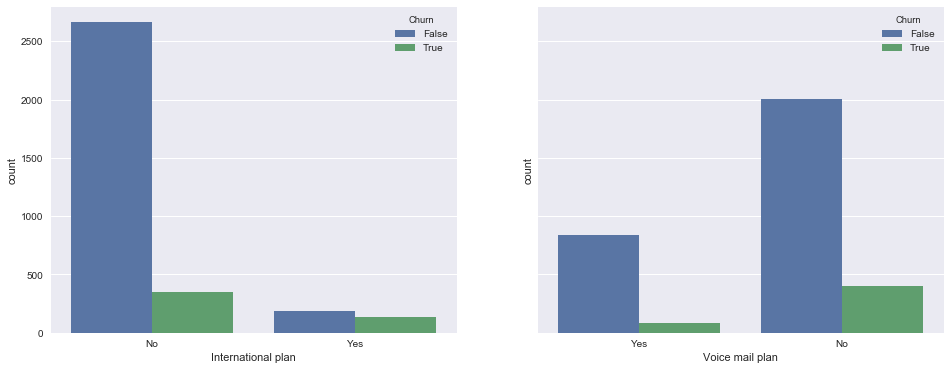
Finally, let’s see how the categorical attribute State is associated with outflow. It is not so pleasant to work with him, since the number of unique states is quite large - 51. You can build a summary tablet at the beginning or calculate the percentage of outflow for each state. But the data for each state is not enough (there are only 3 to 17 customers left in each state), so perhaps the State sign should not be added to the classification models because of the risk of retraining (but we will check for cross-validation , stay tuned!).
Outflow shares for each state:
df.groupby(['State'])['Churn'].agg([np.mean]).sort_values(by='mean', ascending=False).T 

It can be seen that in New Jersey and California, the share of outflow is above 25%, while in Hawaii and Alaska it is less than 5%. But these conclusions are based on too modest statistics and it is possible that these are just the features of the available data (here you can also test hypotheses about the correlation of Matthews and Cramer, but this is beyond the scope of this article).
Peeping into n-dimensional space with t-SNE
Construct a t-SNE representation of the same outflow data. The name of the method is complex - t-distributed Stohastic Neighbor Embedding, mathematics is also cool (and we will not go into it, but for those who want it - this is the original article by D. Hinton and his graduate student in JMLR), but the basic idea is simple, like a door: we will find such a display from the multidimensional feature space to the plane (or in 3D, but almost always 2D is chosen), so that points that are far from each other on the plane also appear remote, and close points also map to close ones. That is, neighbor embedding is a kind of search for a new view of data, in which the neighborhood is preserved.
A few details: let's throw out the states and the sign of churn, binary Yes / No-signs translate into numbers ( pd.factorize ). You also need to scale the sample - subtract its average from each attribute and divide it by the standard deviation, StandardScaler does.
from sklearn.manifold import TSNE from sklearn.preprocessing import StandardScaler # , X = df.drop(['Churn', 'State'], axis=1) X['International plan'] = pd.factorize(X['International plan'])[0] X['Voice mail plan'] = pd.factorize(X['Voice mail plan'])[0] scaler = StandardScaler() X_scaled = scaler.fit_transform(X) %%time tsne = TSNE(random_state=17) tsne_representation = tsne.fit_transform(X_scaled) CPU times: user 20 s, sys: 2.41 s, total: 22.4 s Wall time: 21.9 s plt.scatter(tsne_representation[:, 0], tsne_representation[:, 1]); 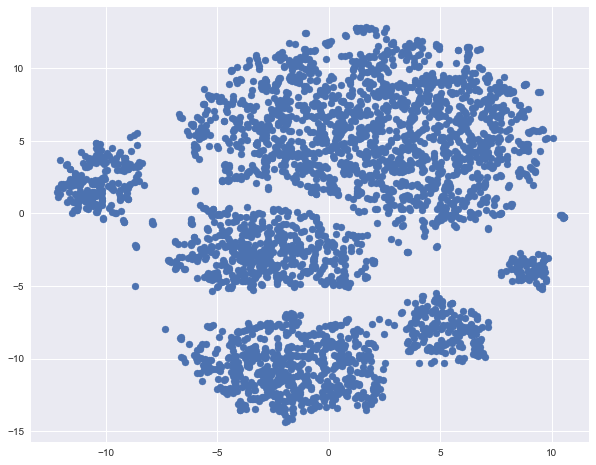
Let us color the resulting t-SNE outflow data representation (blue - loyal, orange - gone customers).
plt.scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['Churn'].map({0: 'blue', 1: 'orange'})); 
We see that the departed customers are mostly "handful" in some areas of the attribute space.
To better understand the picture, you can also paint it on the other binary features - roaming and voice mail. The blue areas correspond to objects with this binary sign.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) axes[0].scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['International plan'].map({'Yes': 'blue', 'No': 'orange'})); axes[1].scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['Voice mail plan'].map({'Yes': 'blue', 'No': 'orange'})); axes[0].set_title('International plan'); axes[1].set_title('Voice mail plan'); 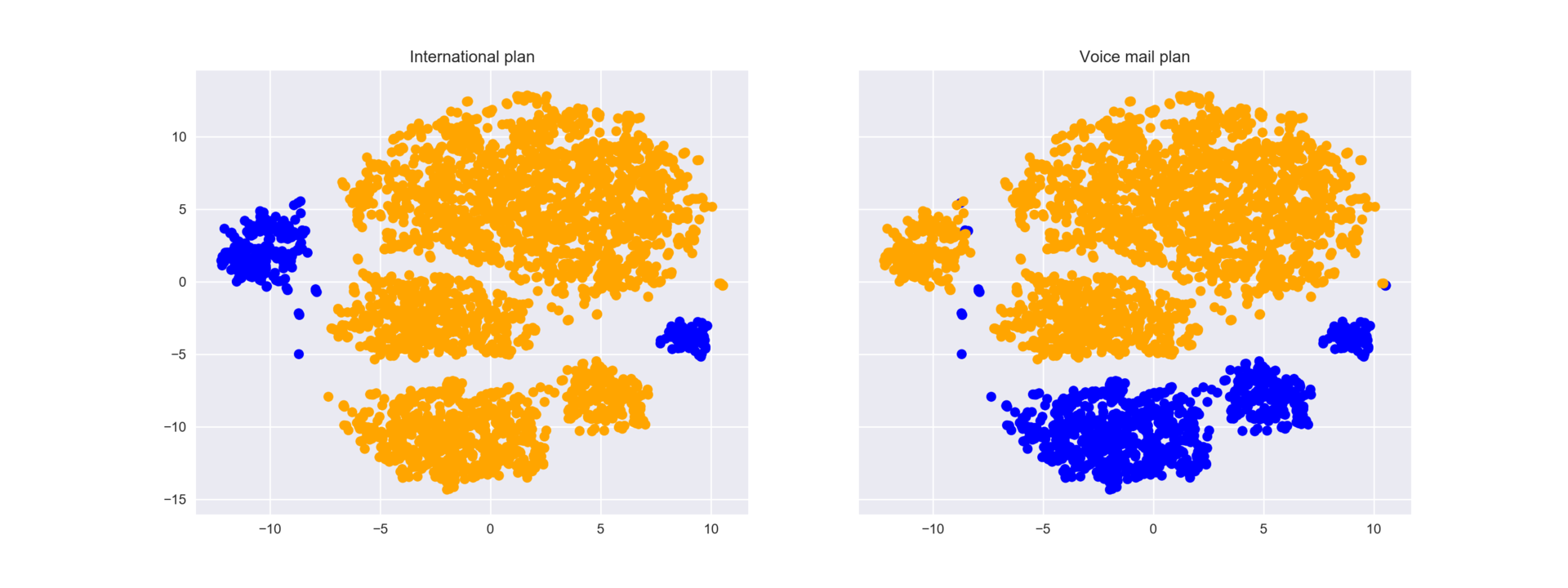
Now it is clear that, for example, a lot of departed clients are grouped in the left cluster of people with roaming turned on, but without voice mail.
Finally, we note the disadvantages of t-SNE (yes, it is also better to write a separate article on it):
- large computational complexity. This implementation of
sklearnmost likely will not help in your real task; on large samples it is worth looking in the direction of Multicore-TSNE ; - the picture can change a lot when changing the
random seed, it complicates interpretation. Here is a good t-SNE tutorial. But in general, such pictures should not be made far-reaching conclusions - do not guess the coffee grounds. Sometimes something catches the eye and is confirmed by the study, but this does not often happen.
And a couple of pictures. With the help of t-SNE, you can really get a good idea of the data (as in the case of handwritten numbers, here's a good article), or you can just draw a Christmas tree toy.


Homework number 2
Actual homework is announced during the regular session of the course, you can follow in the VC group and in the repository of the course.
In order to consolidate the material, we propose to perform this task - to conduct a visual analysis of data on publications in Habrahabr. You can check yourself by sending the answers in a web form (there you will also find a solution).
Overview of useful resources
- Extended version of this article in English - Medium story
- Video recording of the lecture based on this article.
- First of all, official documentation and a gallery of examples of various graphs for
seaborn plotly: ,- ,
plotlypython . c , , drop-down menu.
yorko ( ).
Source: https://habr.com/ru/post/323210/
All Articles