Web scraper development to extract data from the open data portal of Russia data.gov.ru
Sometimes it is necessary to obtain data from web pages and save it in a structured form.
Web scraping tools ( web scraping ) are developed to extract data from websites. These tools are useful to those who are trying to get data from the Internet. Web scraping is a technology that allows you to get data without having to open many pages and do copy-paste. These tools allow you to manually or automatically retrieve new or updated data and save it for later use. For example, using web scraping tools you can extract information about products and prices from online stores.
Possible scenarios for using web scraping tools:
There are a large number of tools that allow you to extract data from websites without writing a single line of “ 10 Web Scraping Tools to Extract Online Data ” code. Tools can be standalone applications, web sites or browser plugins. Before you write your own web scraper, it is worth exploring existing tools. At a minimum, this is useful from the point of view that many of them have very good video tutorials explaining how it all works.
')
Web scraper can be written in Python ( Web Scraping using python ) or R ( More examples of using R to solve practical business problems ).
I will write in C # (although, I believe that the approach used will not depend on the development language). I will try to pay special attention to those annoying mistakes that I made by believing that everything will work easily and simply.
Why I did it and how I used it, you can read here:
So, I want to extract information about the data sets from the open data portal of Russia data.gov.ru and save for further processing as a simple text file in the csv format. Data sets are displayed page by page in the form of a list, each element of which contains brief information about the data set.

To get more information, you must click on the link.
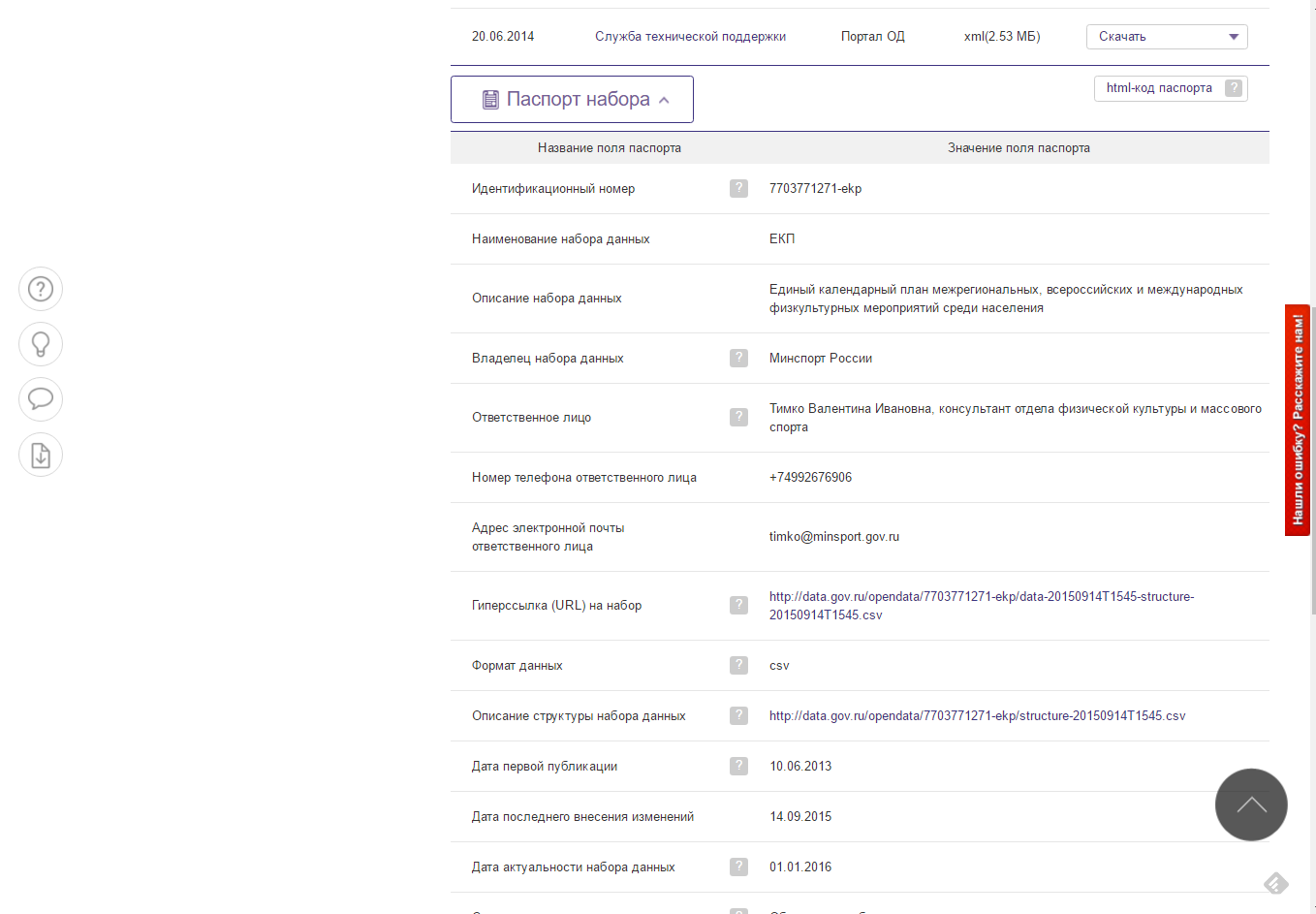
Thus, in order to get information about data sets, I need to:
What I will not do is to load the page myself using HttpClient or WebRequest, self-parse the page.
I will use the ScrapySharp framework. ScrapySharp has a built-in web client that can emulate a real web browser. Also, ScrapySharp allows you to easily parse Html using CSS selectors and Linq. The framework is an add-on over the HtmlAgilityPack . Alternatively, consider, for example, AngleSharp .
To start using ScrapySharp, just add the corresponding nuget package .
Now you can use the built-in web browser to load the page:
Page returned as an object of type WebPage. The page is represented as a set of nodes of the HtmlNode type. Using the InnerHtml property, you can view the Html code of the element, and using the InnerText, you can get the text inside the element.
Actually, in order to extract the necessary information, I need to find the necessary element of the page and extract the text from it.
Question: how to view the page code and find the item you want?
You can simply see the page code in the browser. You can, as recommended in some articles, use a tool like Fiddler .

But it seemed to me more convenient to use the Developer Tools in Google Chrome.

For the convenience of analyzing the page code, I installed the XPath Helper extension for Chrome. Almost immediately it is clear that all the elements of the list contain the same CSS class .node-dataset. To verify this, you can use one of the console functions to search for CSS style.

The specified style is found on the page 30 times and exactly corresponds to the element of the list containing brief information about the data set.
I get all the list items containing .node-dataset using ScrapySharp.
and extract all the div elements that contain the text.
In fact, there are many options for extracting the necessary data. And I acted on the principle “if something works, then don't touch it.”
For example, a link to extended information can be obtained from the about attribute
In ScrapySharp this can be done as follows:
Actually, this is all that is needed to extract information about a data set from the list.
It would seem that all is well, but it is not.
Error number 1. I believe that the data is always the same and there can be no errors in them (I already wrote here about the quality of the loaded data here Analysis of data sets from the open data portal data.gov.ru ).
For example, the text “Recommended” is present for some data sets. I do not need this information. I had to add a check:
I save the received information in the usual lists:
because there are errors in the data. If I create a typed structure, I will immediately have to handle these errors. I did it easier - I saved the data in a csv file. What will happen to them next, I do not really care now.
To go through all the pages, I did not reinvent the wheel. Just look at the link structure:
To go to the desired page, you can use a direct link:
Of course, it was possible to search for a link to the next page, but, then how will I request pages in parallel? All I need is to determine how many pages there are.
I use a simple XPath query to get the required item.
I previously checked it in the Chrome developer tools console.

I can go through all the pages and extract brief information about the data sets and get links to full information pages (data sheet).
Error number 2. The server always returns the desired page.
It would be naive to believe that everything will work as intended. Internet connection may be lost, the last page can be deleted (I had it that way), the server may decide that this is a DDOS attack. Yes, at some point the server stopped responding to me - too many requests.
To defeat the mistake, I used the following strategy:
And the only way I could really get all the pages.
Getting a passport dataset turned out to be a simple task. All information lay in the table. And I just had to extract the text from the desired column.
Each data set has an estimate, which is determined by the vote of the portal users. The score is not in the table, but in a separate p tag.
To extract the score, you need to find the p tag with the class .vote-current-score.
Problem solved. Data retrieved. You can save them to a text file.
To fully test the resulting web-scraper, I wrapped it in a simple REST service, within which I run the background download process .

And placed it in Azure.
So that it was convenient to control the process, added a simple interface.

The service retrieves data and saves as files. In addition, the service compares the extracted data with the previous version and stores information about the number of added, deleted, modified data sets.
findings
Creating a web scraper is not an overly complex task.
To create a web scraper, it’s enough to understand what Html is, how CSS and XPath are used.
There are ready-made frameworks that greatly simplify the task, allowing you to concentrate directly on extracting data.
Google Chrome’s developer tools are enough to figure out what to get and how.
There are many options for how to extract data, and all of them are correct if the result is achieved.
Web scraping tools ( web scraping ) are developed to extract data from websites. These tools are useful to those who are trying to get data from the Internet. Web scraping is a technology that allows you to get data without having to open many pages and do copy-paste. These tools allow you to manually or automatically retrieve new or updated data and save it for later use. For example, using web scraping tools you can extract information about products and prices from online stores.
Possible scenarios for using web scraping tools:
- Data collection for marketing research
- Retrieve contact information (email addresses, phone numbers, etc.) from different sites to create your own lists of suppliers, manufacturers, or any other persons of interest.
- Downloading solutions from StackOverflow (or other similar sites with questions and answers) to enable offline reading or storing data from various sites - thereby reducing dependence on Internet access.
- Job search or job openings.
- Tracking the prices of goods in various stores.
There are a large number of tools that allow you to extract data from websites without writing a single line of “ 10 Web Scraping Tools to Extract Online Data ” code. Tools can be standalone applications, web sites or browser plugins. Before you write your own web scraper, it is worth exploring existing tools. At a minimum, this is useful from the point of view that many of them have very good video tutorials explaining how it all works.
')
Web scraper can be written in Python ( Web Scraping using python ) or R ( More examples of using R to solve practical business problems ).
I will write in C # (although, I believe that the approach used will not depend on the development language). I will try to pay special attention to those annoying mistakes that I made by believing that everything will work easily and simply.
Why I did it and how I used it, you can read here:
- Downloading data from open data.gov.ru
- Analyzing data sets from open data portal data.gov.ru
- Using data sets from the open data portal of Russia data.gov.ru
And briefly
I was interested in how useful the open data from data.gov.ru can be, and the existing api and links on the portal itself did not allow downloading the actual data.
So, I want to extract information about the data sets from the open data portal of Russia data.gov.ru and save for further processing as a simple text file in the csv format. Data sets are displayed page by page in the form of a list, each element of which contains brief information about the data set.
To get more information, you must click on the link.
Thus, in order to get information about data sets, I need to:
- Go through all pages containing data sets.
- Extract brief information about the dataset and link to the page with complete information.
- Open each page with complete information.
- Extract full information from the page.
What I will not do is to load the page myself using HttpClient or WebRequest, self-parse the page.
I will use the ScrapySharp framework. ScrapySharp has a built-in web client that can emulate a real web browser. Also, ScrapySharp allows you to easily parse Html using CSS selectors and Linq. The framework is an add-on over the HtmlAgilityPack . Alternatively, consider, for example, AngleSharp .
To start using ScrapySharp, just add the corresponding nuget package .
Now you can use the built-in web browser to load the page:
// - ScrapingBrowser browser = new ScrapingBrowser(); // - WebPage page = browser.NavigateToPage(new Uri("http://data.gov.ru/opendata/")); Page returned as an object of type WebPage. The page is represented as a set of nodes of the HtmlNode type. Using the InnerHtml property, you can view the Html code of the element, and using the InnerText, you can get the text inside the element.
Actually, in order to extract the necessary information, I need to find the necessary element of the page and extract the text from it.
Question: how to view the page code and find the item you want?
You can simply see the page code in the browser. You can, as recommended in some articles, use a tool like Fiddler .
But it seemed to me more convenient to use the Developer Tools in Google Chrome.
For the convenience of analyzing the page code, I installed the XPath Helper extension for Chrome. Almost immediately it is clear that all the elements of the list contain the same CSS class .node-dataset. To verify this, you can use one of the console functions to search for CSS style.
The specified style is found on the page 30 times and exactly corresponds to the element of the list containing brief information about the data set.
I get all the list items containing .node-dataset using ScrapySharp.
var Table1 = page.Html.CssSelect(".node-dataset") and extract all the div elements that contain the text.
var divs = item.SelectNodes("div") In fact, there are many options for extracting the necessary data. And I acted on the principle “if something works, then don't touch it.”
For example, a link to extended information can be obtained from the about attribute
<div rel="dc:hasPart" about="/opendata/1435111685-maininfo" typeof="sioc:Item foaf:Document dcat:Dataset" class="ds-1col node node-dataset node-teaser gosudarstvo view-mode-teaser clearfix" property="dc:title" content=" () ()"> In ScrapySharp this can be done as follows:
String link = item.Attributes["about"]?.Value Actually, this is all that is needed to extract information about a data set from the list.
It would seem that all is well, but it is not.
Error number 1. I believe that the data is always the same and there can be no errors in them (I already wrote here about the quality of the loaded data here Analysis of data sets from the open data portal data.gov.ru ).
For example, the text “Recommended” is present for some data sets. I do not need this information. I had to add a check:
if (innerText != "") { items.Add(innerText); } I save the received information in the usual lists:
List<string> items = new List<string>() because there are errors in the data. If I create a typed structure, I will immediately have to handle these errors. I did it easier - I saved the data in a csv file. What will happen to them next, I do not really care now.
To go through all the pages, I did not reinvent the wheel. Just look at the link structure:
<div class="item-list"><ul class="pager"><li class="pager-first first"><a title=" " href="/opendata?query=">« </a></li> <li class="pager-previous"><a title=" " href="/opendata?query=&page=32">‹ </a></li> <li class="pager-item"><a title=" 30" href="/opendata?query=&page=29">30</a></li> <li class="pager-item"><a title=" 31" href="/opendata?query=&page=30">31</a></li> … <li class="pager-item"><a title=" 37" href="/opendata?query=&page=36">37</a></li> <li class="pager-item"><a title=" 38" href="/opendata?query=&page=37">38</a></li> <li class="pager-next"><a title=" " href="/opendata?query=&page=34"> ›</a></li> <li class="pager-last last"><a title=" " href="/opendata?query=&page=423"> »</a></li> </ul></div> To go to the desired page, you can use a direct link:
http://data.gov.ru/opendata?query=&page={0} Of course, it was possible to search for a link to the next page, but, then how will I request pages in parallel? All I need is to determine how many pages there are.
WebPage page = _Browser.NavigateToPage(new Uri("http://data.gov.ru/opendata")); var lastPageLink = page.Html.SelectSingleNode("//li[@class='pager-last last']/a"); if (lastPageLink != null) { string href = lastPageLink.Attributes["href"].Value; … I use a simple XPath query to get the required item.
I previously checked it in the Chrome developer tools console.
I can go through all the pages and extract brief information about the data sets and get links to full information pages (data sheet).
Error number 2. The server always returns the desired page.
It would be naive to believe that everything will work as intended. Internet connection may be lost, the last page can be deleted (I had it that way), the server may decide that this is a DDOS attack. Yes, at some point the server stopped responding to me - too many requests.
To defeat the mistake, I used the following strategy:
- If the server did not return the page, repeat n times (not endlessly, the page may no longer exist).
- If the server did not return the page, do not request it immediately, but make a timeout of k milliseconds. And with the next error for the same page, increase it.
- Request not all pages at once, but with a slight delay.
And the only way I could really get all the pages.
Getting a passport dataset turned out to be a simple task. All information lay in the table. And I just had to extract the text from the desired column.
List<string> passport = new List<string>(); var table = page.Html.CssSelect(".sticky-enabled").FirstOrDefault(); if (table != null) { foreach (var row in table.SelectNodes("tbody/tr")) { foreach (var cell in row.SelectNodes("td[2]")) { passport.Add(cell.InnerText); } } } Each data set has an estimate, which is determined by the vote of the portal users. The score is not in the table, but in a separate p tag.
To extract the score, you need to find the p tag with the class .vote-current-score.
var score = PageResult.Html.SelectSingleNode("//p[@class='vote-current-score']"); Problem solved. Data retrieved. You can save them to a text file.
To fully test the resulting web-scraper, I wrapped it in a simple REST service, within which I run the background download process .
And placed it in Azure.
So that it was convenient to control the process, added a simple interface.
The service retrieves data and saves as files. In addition, the service compares the extracted data with the previous version and stores information about the number of added, deleted, modified data sets.
findings
Creating a web scraper is not an overly complex task.
To create a web scraper, it’s enough to understand what Html is, how CSS and XPath are used.
There are ready-made frameworks that greatly simplify the task, allowing you to concentrate directly on extracting data.
Google Chrome’s developer tools are enough to figure out what to get and how.
There are many options for how to extract data, and all of them are correct if the result is achieved.
Source: https://habr.com/ru/post/323202/
All Articles