Microservices: experience of use in a loaded project

At the HighLoad ++ 2016 conference, M-Tech development manager Vadim Madison spoke about growth from a system for which a hundred microservices seemed like a huge number to a loaded project, where a couple of thousand microservices are routine.
The topic of my report is how we launched microservices in production on a fairly loaded project. This is a kind of aggregated experience, but since I work at M-Tech, let me tell you a few words about who we are.
')
In short, we are engaged in video delivery - give the video in real time. We are a video platform for "NTV-Plus" and "Match TV". These are 300 thousand simultaneous users who resort in 5 minutes. This is 300 terabytes of content that we give per hour. This is such an interesting task. How does this all serve?
What is this story about? This is about how we grew up, how the project developed, how some rethinking of some of its parts, of some kind of interaction took place. Anyway, this is about project scaling, because this is all - in order to withstand even more load, provide customers with even more functionality and not fall, not lose key characteristics. In general, to make the client satisfied. Well, a little bit about what path we have gone. Where we started.

This is the starting point, some starting point, when we had 2 servers in the Docker cluster. Then the databases were run in the same cluster. Something of this kind in our infrastructure was not. The infrastructure was minimal.

If you look at what was in our core infrastructure, then this is Docker and TeamCity as a system for delivering code, assemblies, and so on.
The next milestone - what I call the middle of the road - was a fairly serious growth of the project. When we got 80 servers already. When we built a separate dedicated cluster for databases on special machines. When we began to move to a distributed repository based on CEPH. When we began to think that it might be time to reconsider how our services interact with each other, and came close to the fact that it was time for us to change our monitoring system.
Well, actually what we have come to now. There are already hundreds of servers in the Docker cluster — hundreds of running microservices. Now we have come to the conclusion that we are starting to divide our system into certain service subsystems at the level of data buses, at the level of logical separation of systems. When these microservices became too much, we began to split up the system in order to better serve it, to understand it better.
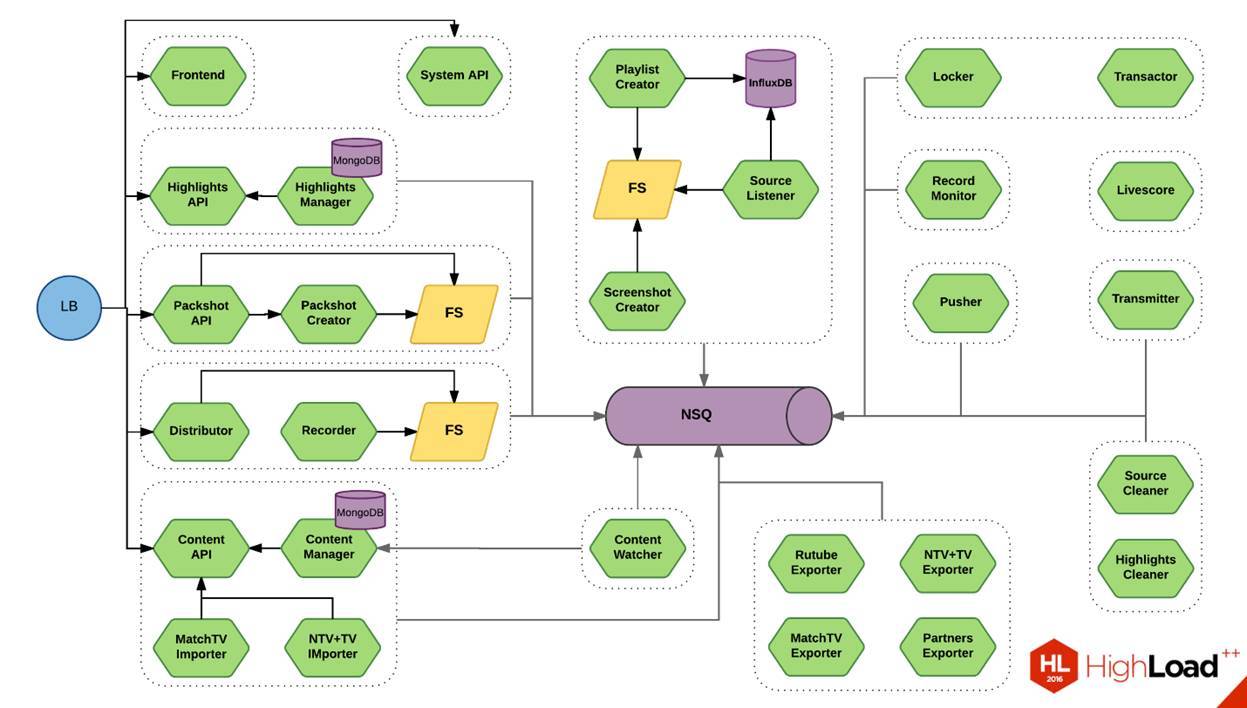
Now on the screen you see the scheme. This is one small piece of our system. This is the thing that allows you to cut video. I showed a similar scheme six months ago on RIT ++. Then green microservices were, in my opinion, 17 pieces. Now there are 28 of them. If you look at it, this is 1/20 of our system. You can imagine the approximate scale.
Details
One of the interesting points is the transport between our services. Classically begin with the fact that transport should be as efficient as possible. We also thought about it, decided that protobuf is our everything.
It looked like this:
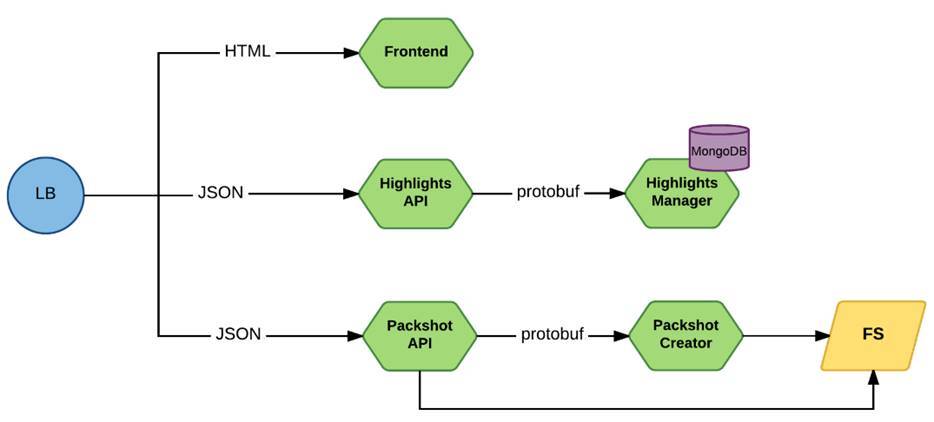
The request via Load Balancer comes to front-line microservices. These are either Frontend, or services that provide the API directly, they worked through JSON. And to the internal services, the requests went already through protobuf.
By itself, protobuf is such a pretty good thing. It really gives a certain compactness in the messaging. Now there are already fairly fast implementations that allow serializing and deserializing data with minimal overhead. It can be considered a conditionally typed query.
But if you look at the section of microservices, it is noticeable that between services you get some semblance of a proprietary protocol. As long as you have 1, 2 or 5 services, you can safely release a console utility for each microservice, which will allow you to access a specific service and check what it returns. If he blunted something - pull him and see. This somewhat complicates the work with these services from the point of view of support.
Before a certain stage, this was not a serious problem - there were not so many services. Plus, guys from Google released gRPC. We looked at what, in principle, for our purposes at that time he was doing everything we needed. We slowly migrated to it. And bams - one more thing appeared in our stack.

Here is also quite an interesting detail in the implementation. This thing is based on HTTP / 2. This is the thing that really works out of the box. If your environment is not very dynamic, if your instances do not change, do not move around the cars often enough, then this is, in general, a good thing. Moreover, at the moment there is support for a bunch of languages - both server and client.
Now if you look at this in the context of microservices. On the one hand, the thing is good, but on the other - it is a thing in itself. So much so that when we began to standardize our logs in order to aggregate them in a single system, we were faced with the fact that you cannot get logs directly from the gRPC.
As a result, we came to the conclusion that we wrote our own logging system, slipped it into gRPC. She made parsing of the messages issued via gRPC with us, brought them to our mind, and then we could put it into our logging system normally. And plus the situation when you first describe the service and the types of this service, then compile them, increases the dependence of the services among themselves. For microservices this is a certain problem, the same as a certain complexity of versioning.
As you probably already guessed, in the end we came to the conclusion that we began to think about JSON. And we ourselves did not believe for a long time that after some kind of compact, conditionally binary protocol, we suddenly return to JSON until we came across an article from the DailyMotion guys who wrote about the same thing: “Damn, we also know how to cook JSON, they know how to cook everything in the world, why do we create additional difficulties for ourselves? ”

As a result, we gradually began to migrate from gRPC to JSON in some of its implementation. That is, yes, we left HTTP / 2, we took fast enough implementations to work with JSON.
Got all those buns that we have. We can contact our service via cURL. Our testers use Postman, and they are fine too. At any stage of working with these services, everything became simple. This is one thing that, on the one hand, is a controversial decision, and on the other hand, it really helps with maintenance.
By and large, if you look at JSON, then the only real disadvantage that you can present to it right now is the lack of compactness of this description. Those 30%, which, as statistically stated, are the difference between the same MessagePack or something else, in fact, according to our measurements, the difference is not so big, and it is not always so critical when we talk about a supported system.
Plus, with the transition to JSON, we received additional buns. Such as, for example, protocol versioning. At some point, the situation began to emerge in us, that through the same protobuf we describe some kind of new version of the protocol. Accordingly, customers, consumers of this particular service, must also move to it. It turns out that if you have several hundred services, even 10% of them must move. This is a large cascade effect. You have changed in one service, and 10 more need to be redone.
As a result, we began to develop a situation where the developer of this service released the fifth, sixth, seventh version, and in fact the production load is still on the fourth, because developers of related services have their deadlines and priorities. They simply do not have the ability to constantly rebuild the service, move to a new version of the protocol. Actually it turned out that new versions are released, but they are not in demand. But the bugs in the old versions, we have to implement some obscure ways. This complicated support.
As a result, we came to the conclusion that we stopped producing versions of the protocols. We fixed a certain basic version, within the framework of which we can add some properties, but in some very limited limits. And consumer services began to use JSON-scheme.
This is how it looks like:

Instead of 1, 2 and 3, we have version 1 and the scheme that applies to it.

Here is a typical response from one of our services. This is Content Manager. He gave information about the broadcast. Here, for example, the scheme of one of the consumers.
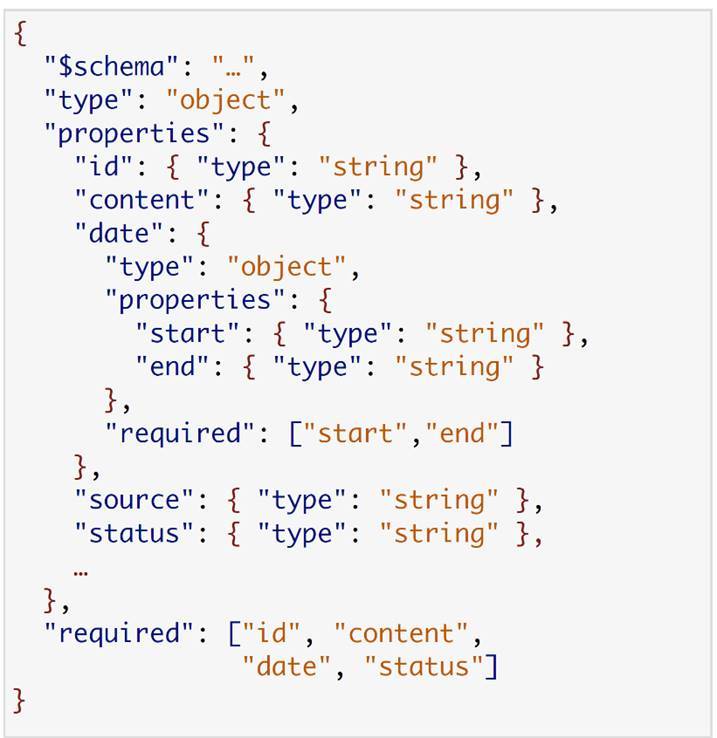
Here the most interesting line is the bottom one, where we have the required block. If we look, we will see that this service actually needs only 4 fields from all this data - id, content, date, status. If you really apply this scheme, then as a result the consumer service needs only this data.

They really are in every version, in every variation of the first version of the protocol. This simplified the move to new versions. We began to release new releases, and the migration of consumers to them has greatly simplified.
The next, important moment that arises when we talk about microservices, and, in general, about any system. Just in microservices it feels stronger and faster. These are situations when the system becomes unstable.
When you have a chain of calls for 1-2 services, then there are no special problems. You don’t see any global difference between a monolithic and a distributed application. But when your chain grows to 5-7, at some stage something fell off. You really do not know why it fell off, what to do about it. Debugging is quite difficult. If, at the level of a monolithic application, you turned on the debugger, just went through the steps and found this error, then you have such factors as network instability, unstable operation under load, and something else. And such things - in such a distributed system, with a bunch of such nodes - become very noticeable.

Then, at the beginning, we went the classic way. We decided to monitor everything, to understand what was breaking and where, to try to somehow deal with it promptly. We began to send metrics from our microservices, collect them into a single database. We, through Diamond, began to collect data on the machines, what happens to them through cAdvisor. We began to collect information on Docker-containers, merge it all into InfluxDB and build dashboards in Grafana.
And here we have 3 more bricks in our infrastructure, which is gradually growing.
Yes, we began to understand more what is happening here. We began to respond more quickly to the fact that something fell apart. But it did not stop falling apart.
Because, oddly enough, the main problem of the microservice architecture is precisely the fact that you have services that are unstable. That works, it does not work, and the reasons for this can be a lot. Up to the fact that your service is overloaded, and you send an additional load on it, it goes down for a while. After some time due to the fact that he does not serve everything, the load from him decreases, and he begins to serve again. Such a leapfrog leads to the fact that such a system is very difficult to maintain and to understand what is wrong with it.
As a result, we gradually came to the conclusion that it is better for this service to fall, than it jumps here and there. This understanding led us to the fact that we began to change our approach to how we implement our services.
The first of the important points. We began to introduce in each of our service restrictions on incoming requests. Each service we have become aware of how much it is able to serve customers. How does he know this, I will tell you a little later. He stops accepting all those requests that are above or above this limit. He gives honest 503 Service Unavailable. The one who addresses to it, understands that it is necessary to choose other note - this is unable to serve.
Thus, we reduce the request time in case something is wrong with the system. On the other hand, we increase its stability.
Second moment. If rate limiting is on the side of the destination service, then the second pattern that we began to introduce everywhere is Circuit Breaker. This is a pattern that we, roughly speaking, implement on the client.
Service A, he has as possible points of appeal, for example, 4 instances of service B. So he went to the registry, said: "Give me the addresses of these services." Got them 4 pieces. Went to the first, he replied that everything is ok. Service marked "yes", you can go to him. According to Round Robin, he scatters appeals. Went to the second, he did not answer for the right time. Everything, we bany him for some time and go to the next. That one, for example, returns an incorrect version of the protocol with us - no matter why. He bans him too. Going to the fourth.
The result is 50% of the services, they are really able to help him serve the client. To these two he will go. Those two that for some reason did not suit him, he bans for some time.
This allowed us to seriously increase the stability of the work as a whole. There is something wrong with the service - we shoot it off, an alert is raised that the service has been shot off, and we understand further what could be wrong.
In response to the introduction of the Circuit Breaker pattern, we have another thing in our infrastructure - Hystrix.
The guys from Netflix not only realized the support of this pattern, but also did it visually how to understand if something was wrong with your system:
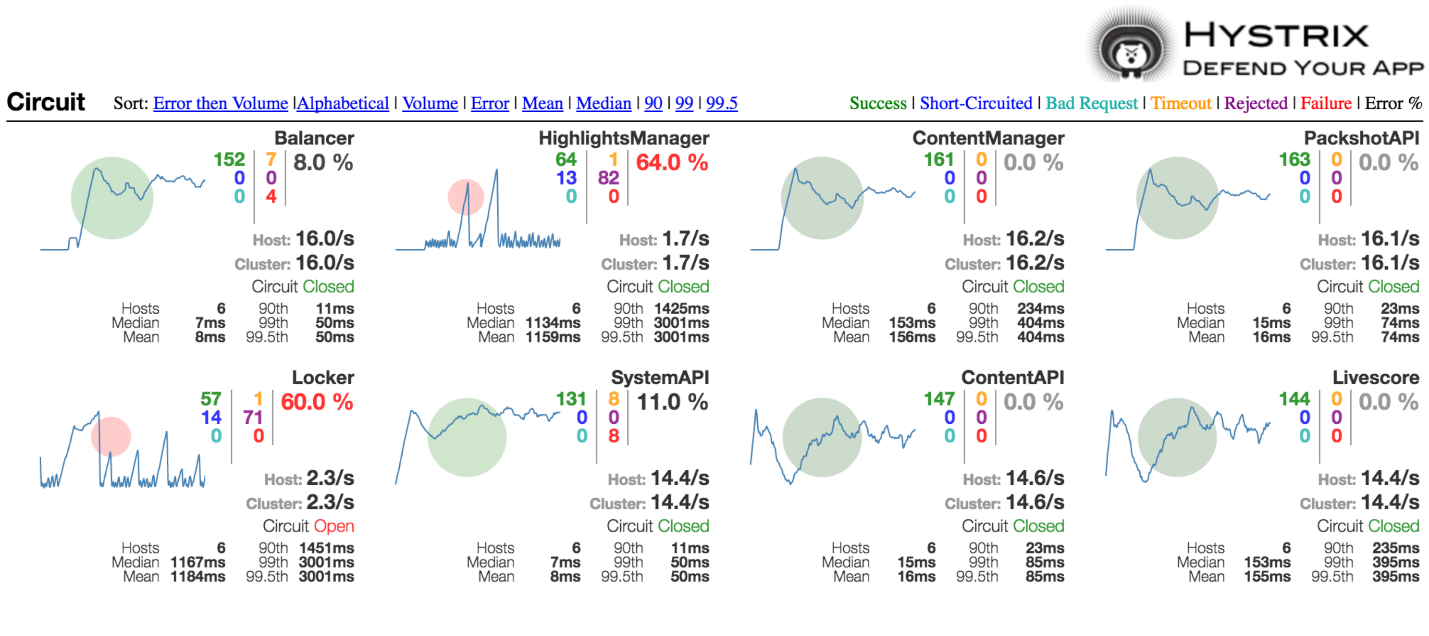
Here the size of this circle shows how much traffic you have relative to others. The color indicates how good or bad the system is. If you have a green circle, then probably you are fine. If red - not so rosy.
Something like this, when you have to completely shoot the service. A switch worked on it.
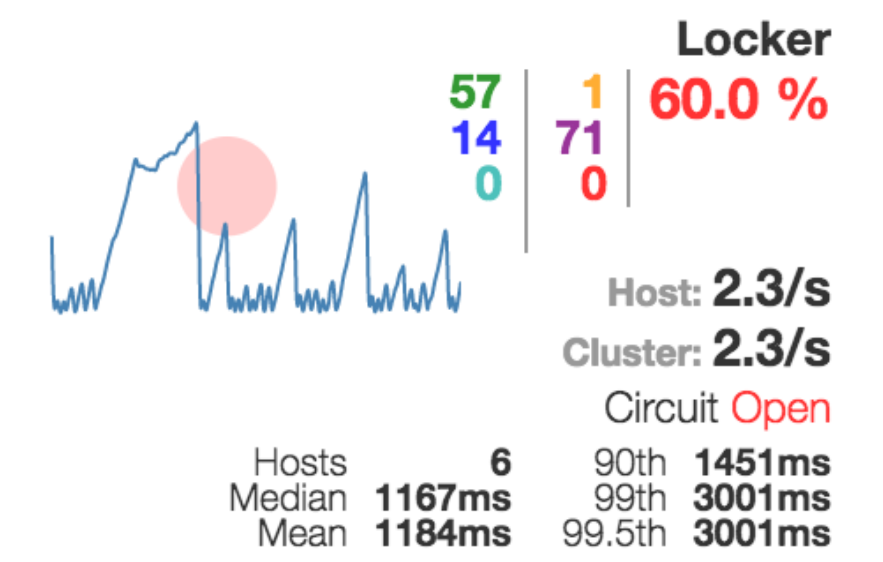
We have ensured that our system has become more or less stable. We have each service had at least two instances, so that we could switch by shooting one or the other. But this did not give us an understanding of what was happening with our system. If we have somewhere along the way fell off during the execution of the request, then how to understand it?
Here is the standard query:
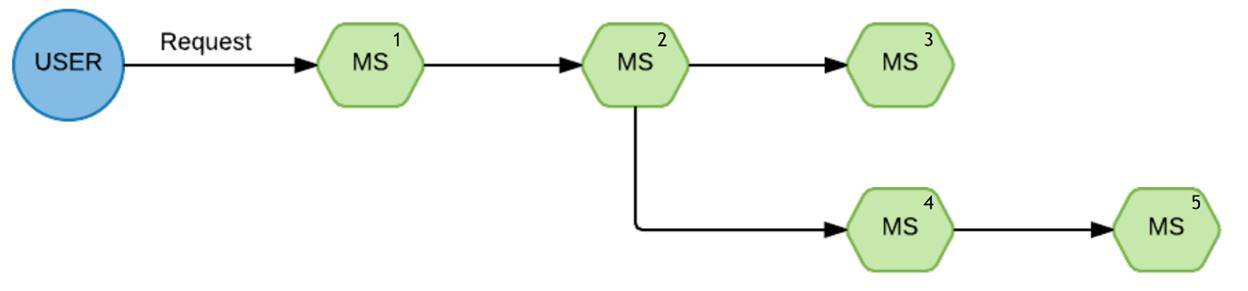
Such a chain of execution. From the user came a request for the first service, then for the second, from the second he split the branch to the third and fourth.
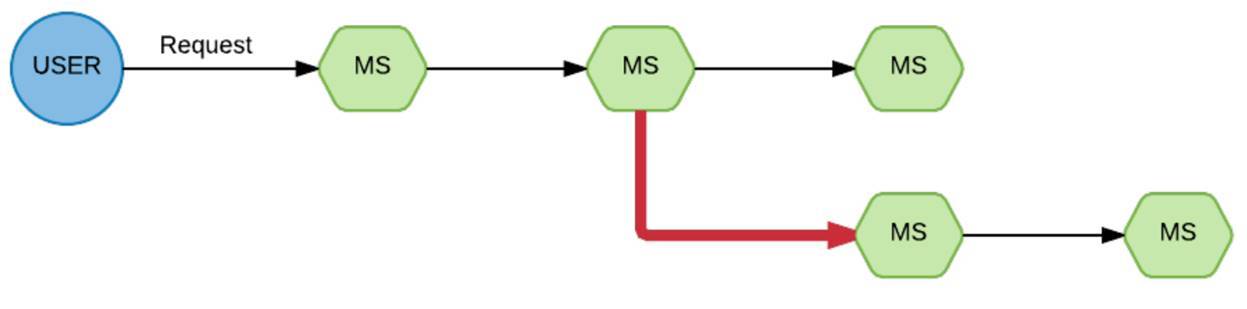
Wham, and we have one of the branches disappeared. Really wonder why. When we faced this situation and began to figure out what to do here, how we can improve the visibility of the situation, we came across such a thing as Appdash. This is a trace service.
It looks like this:
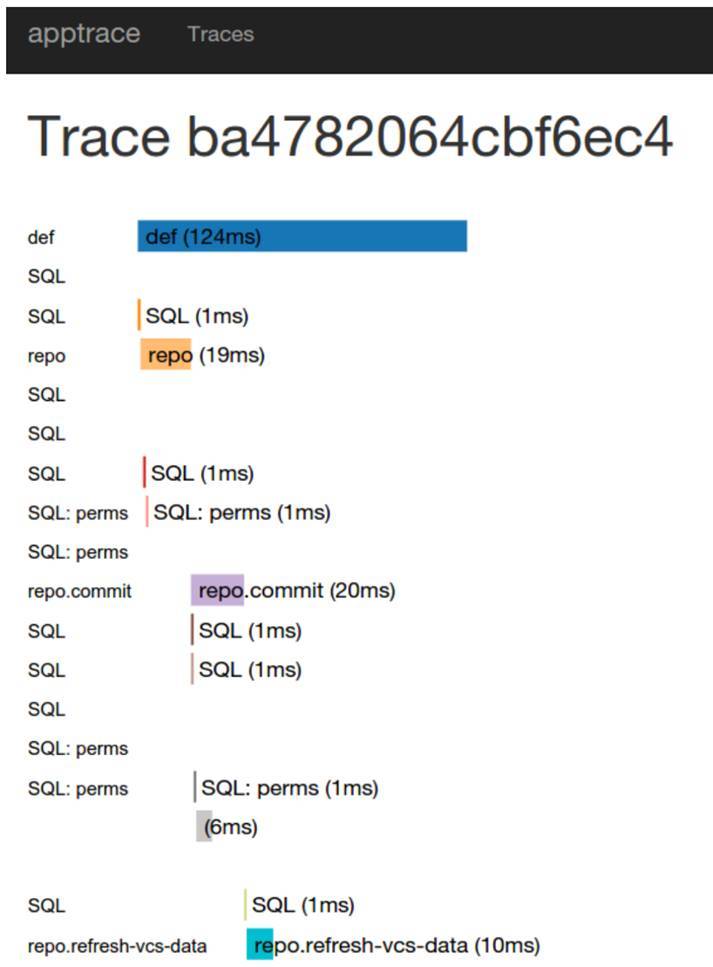
I must say, it was exactly the thing to try, to understand, or it was. It was easiest to implement it into our system, because by that moment we had moved quite tightly to Go. Appdash had a ready connection library. We looked at that, yes, this thing helps us, but the implementation itself is not very convenient for us.
Then, instead of Appdash, we got a Zipkin. This is the thing that the guys from Twitter did. It looks like this:
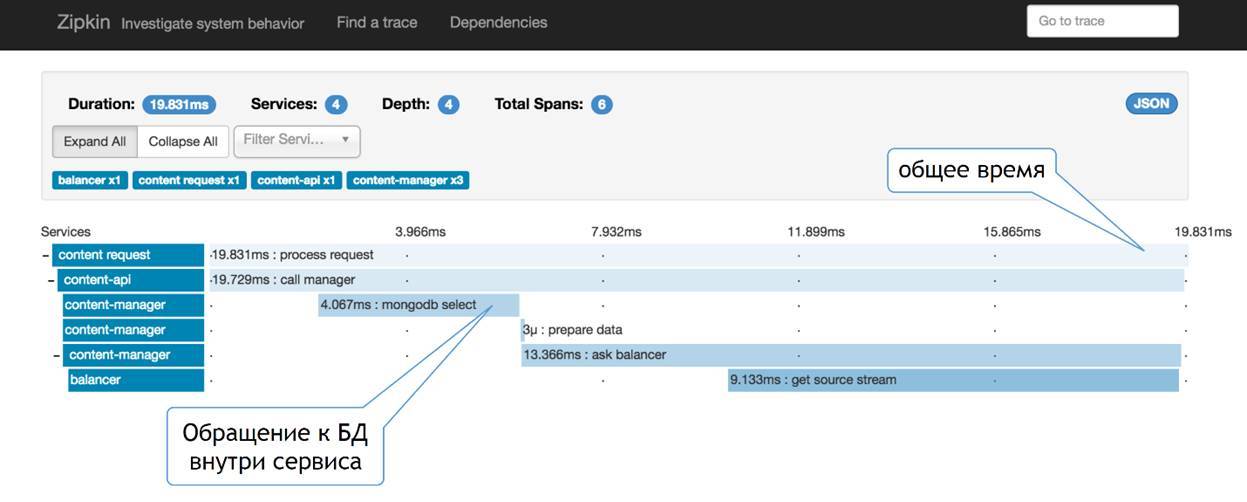
It seems to me a little more visually. Here we see that we have a certain number of services. We see how our request passes through this chain, we see what part of this service eats up in each of the services. On the one hand, we see a certain general time and division by services, on the other - no one bothers us to add here the same information about what is happening inside the service.
That is, some kind of payload, access to the database, reading out something from the file system, accessing the caches - this can all be added here and see what could be the most time added to this request in your request. The thing that allows us to do this probros is a through TraceID. I will continue to talk about him a little bit.
This is how we began to understand what is happening in a particular request, why it suddenly falls for a particular client. All is well and suddenly someone has something wrong. We began to see a certain basic context and understand what is happening with the service.
Not so long ago, a certain standard was developed for the tracing system. Just some agreement between the main suppliers of trace systems on how to implement the client API and client libraries so that this implementation can be made as simple as possible. Now there is an implementation through Opentracing for almost all major languages. You can safely use.
We learned to understand which of the services suddenly did not allow us to serve the client. We see that some of the parts blunted, but it is not always clear why. The context is insufficient.
We have logging. Yes, this is a fairly standard thing, this is ELK. Maybe in our small variation.

We do not collect directly through the heap forward as Logstash. We first send it to Syslog, with the help of Syslog we aggregate it on collecting machines. From there already through forward we put in ElasticSearch and in Kibana. Relatively standard stuff. What is the trick?
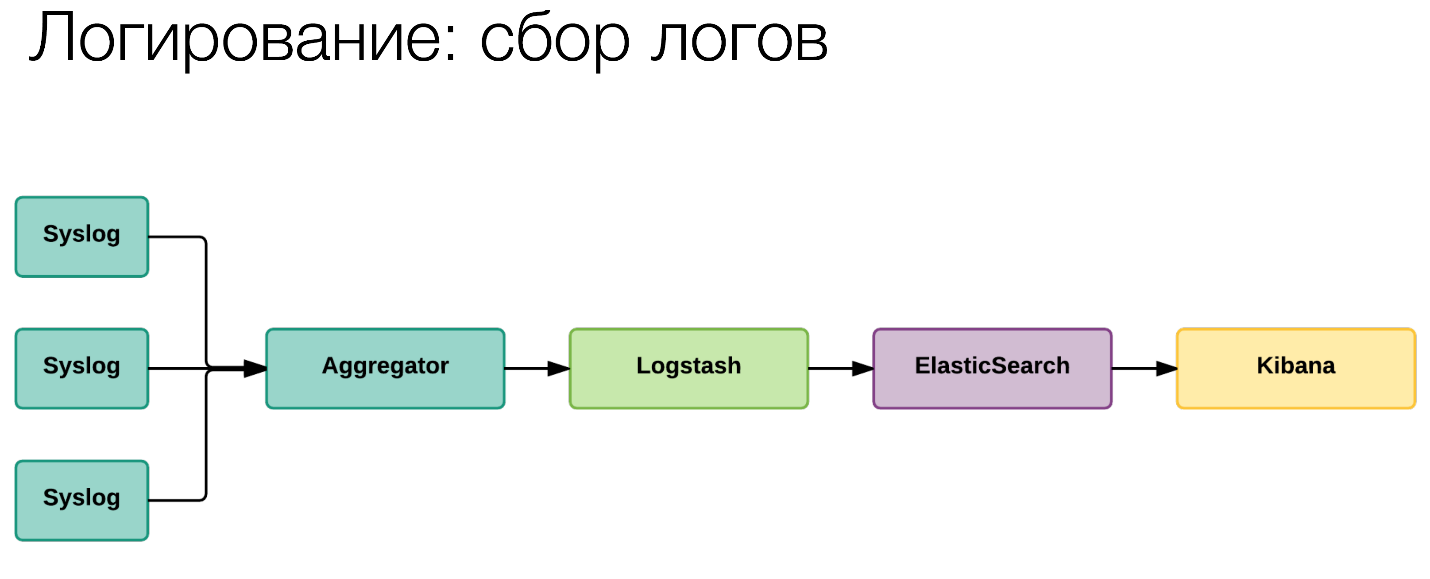
In that, wherever it is possible, where we really understand that it really refers to this particular request, we began to add the TraceID that I showed on the screen with Zipkin to these logs.
As a result, we see in the logs on Kashana Dashboard the full context of execution for a specific user. Obviously, if the service got into prod, then it is conditionally already working. He passed autotests, testers have already looked at him, if necessary. It should work. If it does not work in any particular situation, then, apparently, there were some prerequisites. These prerequisites in this detailed log, which we see with such filtering on a specific trace for a particular request, help to understand much more quickly what exactly is wrong in this situation. As a result, we have seriously reduced the time to understand the causes of the problem.
The next interesting point. We have entered a dynamic debug mod. In principle, we now have not such a wild amount of logs - about 100-150 gigabytes, I do not remember the exact figure. But it is in the basic logging mode. If we wrote at all super-detail, it would be terabytes. To process them would be insanely expensive.
Therefore, when we see that we have some kind of problem, we go to specific services, enable debug mod on them through the API and watch what happens. Sometimes we first see what happens. Sometimes we shoot off a service that creates a problem with us, without turning it off, we turn on the debug mod on it and then we already understand what was wrong with it.
As a result, this rather seriously helps us in terms of the ELK stack, which is quite voracious. On some critical services, we additionally do error aggregation. That is, the service itself understands that it is a very critical error, which is moderately critical, and resets it all into Sentry.
She cleverly enough knows how to aggregate these errors, reduce them by certain metrics, and make filters on basic things. On a number of services we use it. And we started using it from the time when we had monolithic applications, which we still have. Now we enter on some services on the microservice architecture.
The most interesting thing. How do we scale this whole kitchen? Here you need to tell some introductory. For each of our car that serves the project, we treat as a black box.
We have an orchestration system. We started with Nomad. But no, in fact, we started with Ansible, with our scripts. At some point this began to be missed. By that time, there was already some version of Nomad. We looked, she bribed us with its simplicity. We decided that this is the thing that we can move to now.
Along the way, Consul appeared with her as a registry for service discovery. Also Vault, in which we store the secret data: passwords, keys, all secret that can not be stored in Git.
Thus, it turned out that all cars became conditionally identical. There is a Docker on the machine, there is a Consul agent on it, a Nomad agent. This, by and large, is a finished machine, which can be taken and copied one-on-one, at the right moment to put into operation. When they become unnecessary, can be decommissioned. Moreover, if you have a cloud, then you can prepare the machine in advance, turn it on at peak times. And when the load fell back, turn off. This is quite a serious savings.
At some point, Nomad we outgrew.We moved to Kubernetes, and Consul began to play the role of a central configuration system for our services with all that it implies.
We have come to the fact that we have some kind of stack in order to automatically scale. How do we do it?
First step. We have imposed some limits on three characteristics: memory, processor, network.
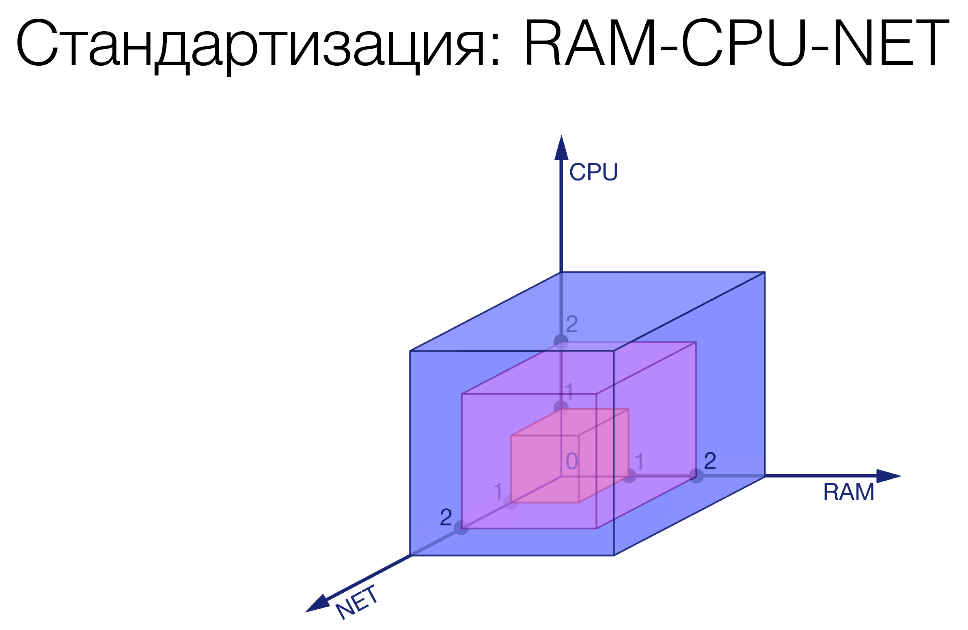
We recorded three gradations in each of these quantities. Cut some bricks. As an example:
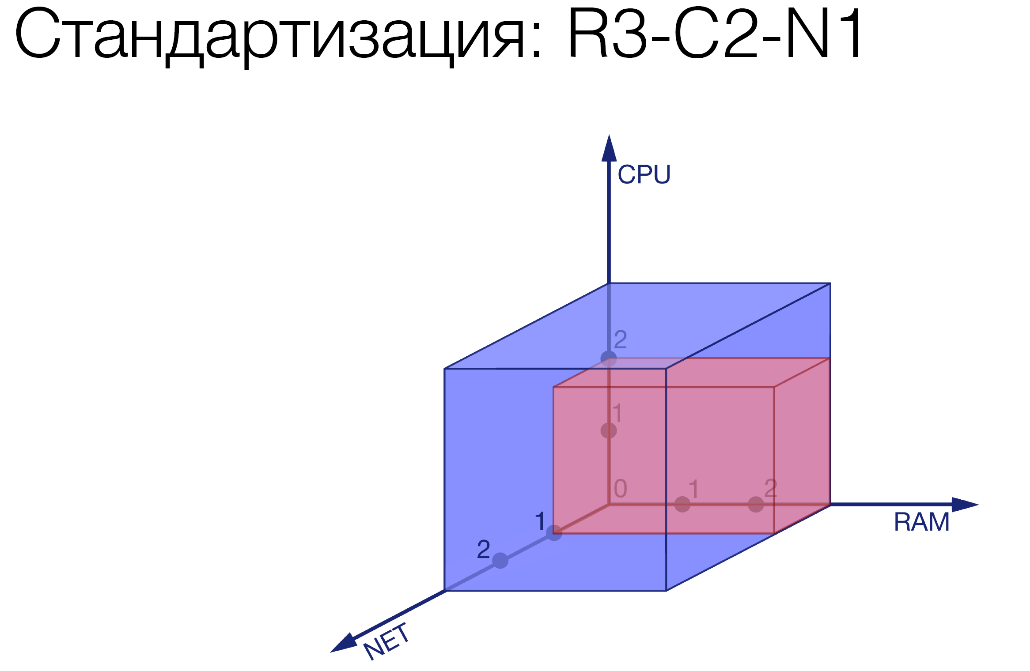
R3-C2-N1. We have limited a certain service, gave it quite a bit of network, a little more processor and a lot of memory. There is some gluttonous service.
We introduce mnemonics exactly, because we can dynamically twist enough values in a wide range already in our system, which we call the decision service. At the moment, these values are approximately as follows:
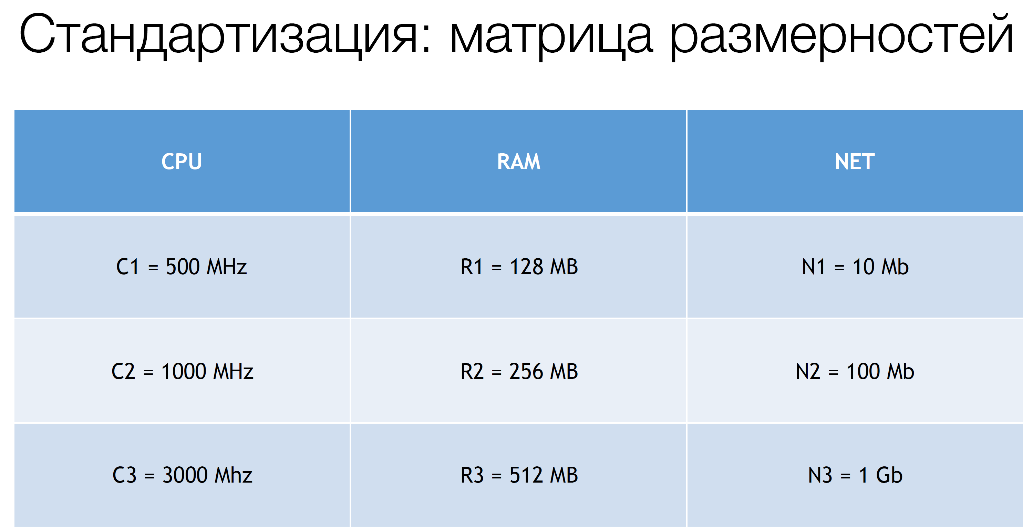
In fact, we still have C4, R4, but these are values that are completely beyond the scope of these standards. They are negotiated separately.
It looks like this:

The next preparatory stage. We look at what type of scalability for this service.
The easiest is when your service is completely independent. You can linearly rivet this service. 2 times more users came - you launched 2 times more instances. You are fine again.
The second type is when your scalability depends on external resources. Roughly speaking, this service is included in the database. The base has a certain opportunity to serve a certain number of customers. You must take this into account. Either you need to understand when the degradation of the system begins and you cannot add more instances, or simply somehow understand how much you can already rest on it now.
And the third, most interesting option is when you are limited to some kind of external system. As an example - external billing. You know that he will not serve more than 500 requests. And even though you are launching 100 of your services, it’s still 500 requests to billing, and hello!
We must also take these limits into account. So we realized what type of service we have, we put the corresponding tag and then we look at how it works in our pipeline.
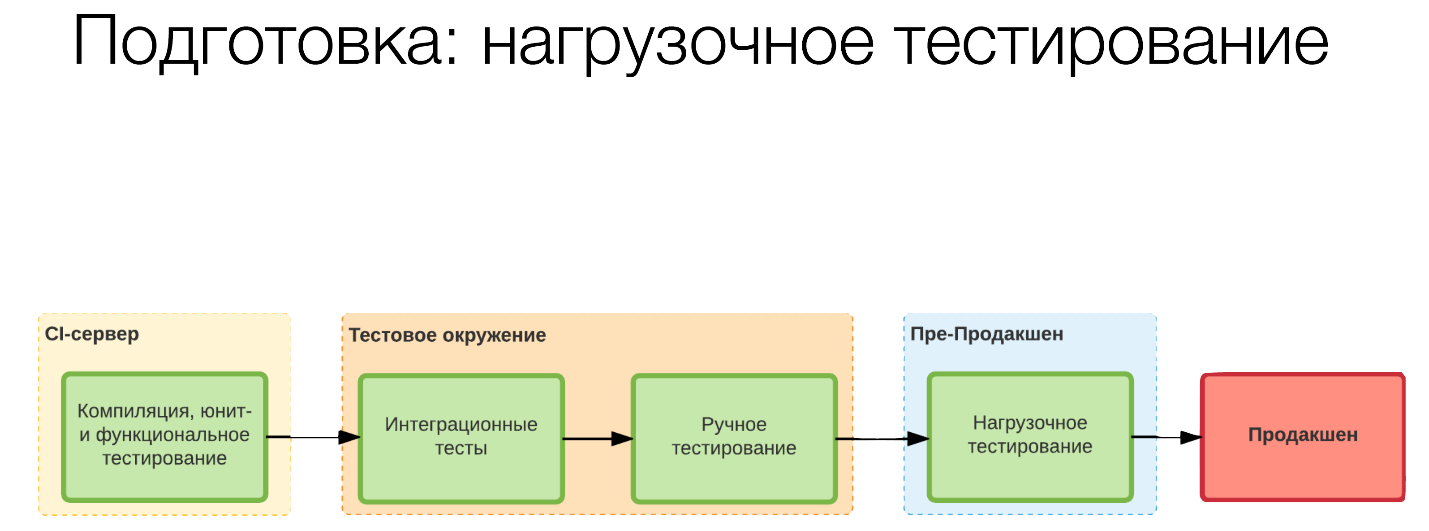
By default, we have assembled on the CI server, and have launched some unit tests. We have passed integration tests on the test environment, testers have checked something with us. Then we went to load testing in pre-production.
If we have a service of the first type, then we take an instance, run it in this isolated environment and give it the maximum load. We make several rounds, we take the minimum number from the received values. We put it in InfluxDB and say that this is the limit that is in principle possible for this service.
If we have a service of the second type, then here we run these instances in increment in some quantity, until we see that the degradation of the system has begun. We appreciate how fast or slow it is. Here we draw conclusions, if we know any particular load on our systems, is that enough at all? Is there a stock we need? If it is not there, then at this stage we set an alert and do not release this service in production. We are saying to the developers: “Guys, you either need to shard something or else introduce some kind of toolkit that would allow for a more linear scaling of this service.”

If we are talking about a third type of service, then we know its limit, we launch one copy of our service, in the same way we give the load and see how much this service can serve. If we know, for example, that the limit of the same billing is 1000 requests, 1 instance serves 200, then we understand that 5 instances are the maximum that can correctly serve it.
All this information in InfluxDB we saved. Decision service appears. It looks 2 borders: upper and lower. By moving beyond the upper boundary, he realizes that you need to add instances, and maybe even machines for these instances. The reverse is also true. When the load drops (night), we don’t need so many machines, we can reduce the number of instances on some services, turn off the machines and thereby save a little money.
The general scheme looks like this:
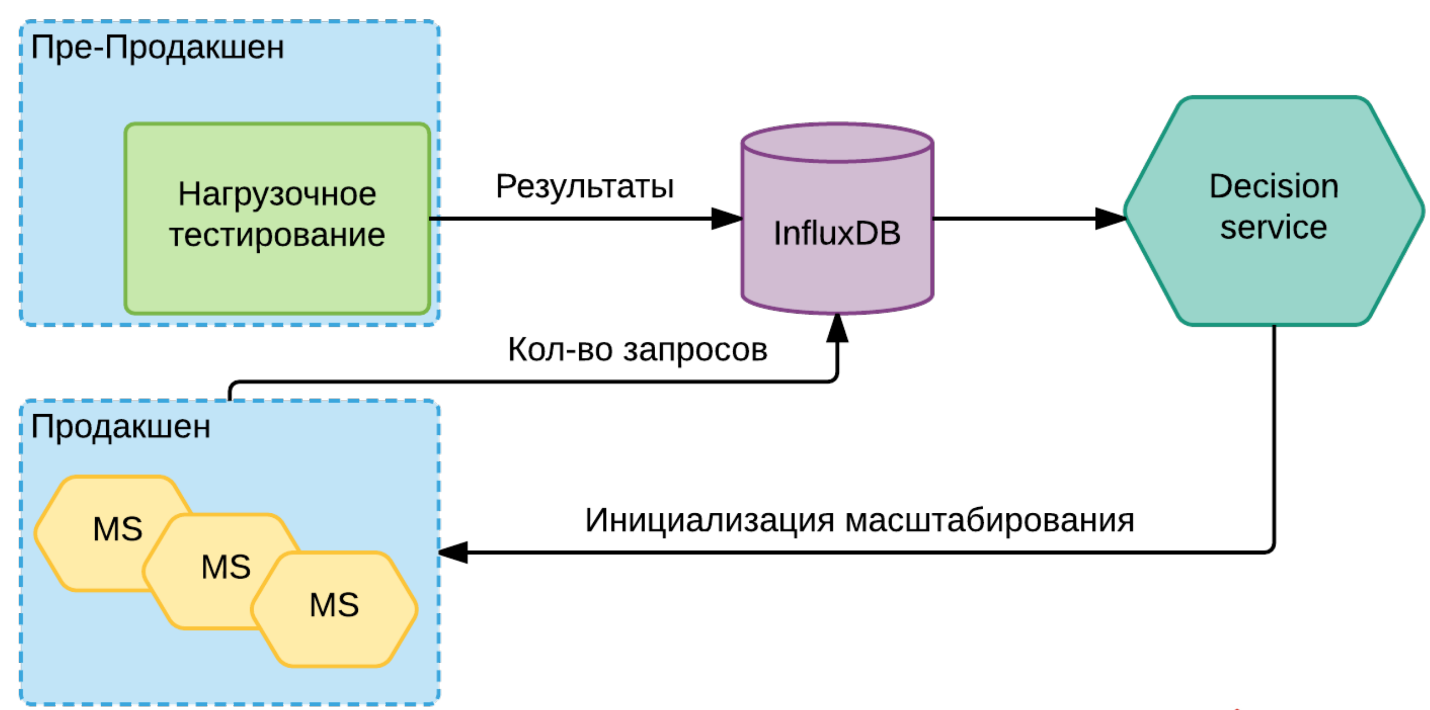
Each service through its metrics regularly says what is the current load on it. She goes to the same InfluxDB. When the Decision service sees that for this particular version of this particular instance we are approaching the threshold, it already gives the Nomad or Kubernetes command to add new instances. Perhaps he is initiating a new service in the cloud before that, perhaps he is doing some other preparatory work. But the bottom line is that it initiates the need to raise a new instance.
If it is clear that we will soon reach the limit for some limited services, then he raises the appropriate alert. Yes, we conditionally cannot do anything with it except to save the queue or something else, but at least we know that we may soon have such a problem and can already begin to prepare for it.
This is what concerns scaling in some common things. And all this parsley with a bunch of services, it eventually led to the fact that we looked at another such thing a little sideways - this is Gitlab CI.
Traditionally, we collected our services through TeamCity. At some point, we realized that we have one template for all services, because each service is unique, he knows how to roll himself into a container. It became quite difficult to produce these projects here, there were a lot of them. And to describe it in a yml-file and put it together with the service itself turned out to be quite convenient. Therefore, we are gradually introducing this thing, for a little while, but the prospects are interesting.
Well, actually, what I would like to say to myself when we started all this stuff.
Firstly, this is what if we are talking about the development of microservices, then the first thing I would advise is to start right away with some kind of orchestration system . Let it be as simple as the same Nomad that you run with the command
nomad agent -devand get a complete orchestration system, immediately with a raised Consul, with Nomad himself and with this whole kitchen.This makes it clear that you are working in a kind of black box. You are trying to immediately move away from being tied to a specific machine, tied to the file system on a specific machine. Something like this, it immediately rebuilds your thinking.
And, of course, right at the development stage, you should have it laid out that each service has at least two instances , otherwise you will not be able to easily shoot off any problematic services, some things that make it difficult for you.
The next moment is, of course, some architectural things. As part of microservices, one of the most important of these things is the message bus..
A classic example: you have a user registration. How to make it the easiest way? To register, you need to create an account, create a user in billing, you need to make him an avatar and something else. Here you have a certain number of services, you receive a request to some such super-service, and he is already starting to scatter requests to all his wards. As a result, every time he knows more and more about the services he needs to pull in order to complete the registration.
It is much easier, safer and more effective to do it differently. Leave 1 service that makes registration. He has registered a user. Then you throw the event into this shared bus “I registered the user, the ID is such and such, the minimum information”. And it will receive all the services for which this information is useful. One will go to the account in the billing will do, the other welcome letter will send.
As a result, your system will lose such a rigid connectivity. You will not have such super-services that know about everything and about everyone. It actually makes it very easy to operate with such a system.
Well, what I mentioned. No need to try to repair these services.. If you have a problem with any particular instance, try to localize it, transfer traffic to other, maybe, just raised instances. And then understand what is wrong. The viability of the system will greatly improve.
Naturally, in order to understand what is happening with your system, how effective it is, you need to collect metrics .
Here is an important point: if you don’t understand a metric, if you don’t know how to use it, if it doesn’t tell you anything, then you don’t need to collect it. Because at some point, these metrics become a billion. You spend a lot of CPU time just to choose what you need, spend tons of time filtering what you don't need. It lies dead weight.
You understand that you need some kind of metric - start collecting it. Something is not needed - do not collect. This greatly simplifies the handling of this data, because it becomes really very fast a lot of them.
If you see some kind of problem, then you don’t need to do something for everyone. In most cases, the system itself must somehow respond . You really need an alert only in that situation when it requires some kind of your action. If you don’t need to run something there in the middle of the night, it means that this is not an alert, but some kind of warning that you have taken note of and in some conditionally-regular mode will be able to process.
Well, actually everything. Thank.
Microservices: experience of use in a loaded project
Source: https://habr.com/ru/post/323154/
All Articles