Build a cache with efficient multithreaded access

Hello! My name is Pasha Matlashov. I am the Director of Game Server Development Department in the Plarium gaming company.
Today, using our projects as an example, I will talk about caching features, pitfalls, and how to get around them.
Prerequisites
Our servers process 8500 requests per second and store information about 200 million users. To provide effective linear scaling, we apply user segmentation (it’s also sharding). The process of distributing new users follows a simple balancing rule: the new user falls into the least “populated” segment. Such segmentation is static, which provides ease of development. Additionally, to simplify the architecture, there is a rule: user data can be edited only on the segment on which it is stored. This allows you to not worry about issues such as distributed locks and transactions. Within the server, the user is called a gaming entity.
')
Data lock
To regulate the flow and correct data editing, you can go on the principle of optimistic or pessimistic blocking.
Using optimistic locking does not guarantee that by the end of the transaction, parallel entities / threads / queries will not change the data. To minimize the number of data reads before editing, we remember the version of the game entity. When the changed data is saved to the database, we additionally save the value of the old version.
In this approach, there is a minus: there may be situations where the game entity will have to be re-read due to the large amount of interaction.
Imagine that a user buys a building and a battle is fired at the same time. Both of these events change the game essence. It may happen that the result of the battle will be calculated at the time of applying the building purchase logic. The data is stored in the database, changing the user revision. We need to throw away a huge array of data. Additionally, you need to take into account that the preservation of the game entity in the database includes the stage of serialization and data compression. As a result, the data is sent to the database, but the revision does not match. You need to get the entity from the database again, reproduce the transaction logic, serialize, compress the data, try again to fix the version of the data in the hope that nothing changes. This approach complicates the code and consumes extra resources.
We went on the principle of pessimistic blocking. Before any action, data is locked - this guarantees the sole editing process.
Choosing a place to lock data
Continuing to go to the database where data is stored is long and resource-expensive. It is easier to lock in the memory of the workflow than in the database. But you need to comply with certain guarantees:
- All methods follow user data only to the server.
- Developers ensure that data is edited only on the segment where the user is stored.
- Only one copy of the user should be in memory.
As a result, we come to the user cache, which improves the efficiency of working with data. The cache keeps track of the uniqueness of a copy of each entity and provides a blocking location. In such a scenario, the cache works on the write-through principle.
The work of the cache with game entities can be described in stages:
- Subtract the user from the database to the cache.
- Getting exclusive access to data by blocking.
- Editing a user in the cache.
- Save user to database. Current user data remains in the cache.
“But what if you put the cache in another process, for example, in Memcached?” You will say :) In this situation, you need to take into account that there will be additional costs for serialization and deserialization when interacting with the external cache and transferring it over the network.
In the case of multithreading and a large number of processes, theoretically, a situation may arise in which a copy of the user will exist in parallel in two cache processes. This phenomenon is caused by an interesting feature of ASP.NET. When the assembly changes in the deployed site, for a while there are 2 instances of the site: the first modifies the old code and the old requests, and the second creates a new process for the new requests with a new memory. Technically, the game entity from the new site can load before all the processes on the old one are completed. Each copy of the site believes that only it has these game entities, which is why data loss occurs.
We encountered such a problem when rebooting and pouring out a new version of the server. Standardly at 2–3 users "were lost" troops. To resolve this issue, we have banned the simultaneous launch of two applications at the code level.
To avoid deadlock threads, we follow a number of rules:
- Lock take indicating timeout.
- Do not take more than one lock at a time.
- Change of several entities through the exchange of messages in the queue.
First decision
The first thing that comes to mind for organizing work with the cache is to use a Dictionary of the form <Id, User>. But such a decision has a minus. Dictionary is well suited for single-threaded applications. In a multithreaded environment, it becomes non-thread-safe and requires additional protection.
Dictionary protection can be implemented through a single exclusive lock, under which the presence of the desired user in the collection is checked. If there is no user, the game entity is loaded and returned to the calling code. To ensure sequential access, the called code will be blocked on the user. To optimize a little, you can use ReaderWriterLock (or any other variant on the same topic).
But everything is complicated by the fact that any cache sooner or later reaches the threshold size and requires data crowding out. What will happen in this case?
We will model the situation in accordance with the above decision. The cache contains a gaming entity. A request came, took the game entity into the context of the lock, and started editing it. In parallel, there is a displacement of the game entity from the cache - for example, the flow of crowding out has managed to designate this data as old in use. At this time, another request comes to the game entity, but it is no longer in the cache. The request reads the data from the database, puts in the cache, takes the context and also starts editing. As a result, we get two copies of the game entity, and this violates our own guarantee of uniqueness (Figure 1). Data is lost, and lucky that request, which will save the gaming entity last.
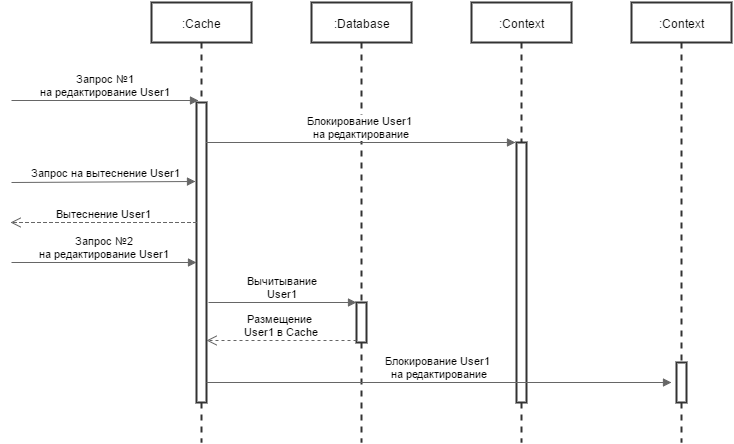
Picture 1
Obviously, you need to reckon with the stream that is already editing the game entity. It is possible to block all entities that should be repressed, but this is labor-intensive and inefficient. If, for example, 20,000 game entities are cached and 10% of them need to be supplanted, 2000 locks will occur. Additionally, if some locks are busy, you will have to wait for them to be released.
Pin and UnPin operations
We decided to implement Pin and UnPin operations. Instead of storing an entity as a value in a Dictionary, we store a certain CacheItem, which indicates a lock on the game entity, the entity itself, and a usage count. The counter is used to regulate access during preemption. When a context is created, the counter value is increased by using Interlocked operation on the CacheItem (Pin operation), when the context is released, it is decreased (UnPin operation). We added the Shrink operation, which displaces objects with a zero value of the counter by the date of the last use. A global blocking of the entire Dictionary is used without an entry for the individual blocking of each entity. Pin is executed in the context of the same lock to preserve the atomicity of receiving and blocking the entity.
// User Cache private readonly object _lock = new object(); private Dictionary<long, UserCacheItem<TUser>> _dict = new Dictionary<long, UserCacheItem<TUser>>(); public bool TryGet(long userId, out UserCacheItem<TUser> userCacheItem, bool pinCacheItem) { lock(_lock) { if (!_dict.TryGetValue(userId, out userCacheItem)) return false; userCacheItem.UpdateLastAccessTime(); if (pinCacheItem) userCacheItem.PinInCache(); return true; } } // Shrink private void ShrinkOldest(int shrinkNumber) // shrinkNumber - quantity CacheItem superseded. { lock(_lock) { var orderedByAccess = _dict.OrderBy(pair => pair.Value.LastAccessTime).Where(pair => !pair.Value.IsPinnedInCache()); int i = 0; foreach (var pair in orderedByAccess) { i++; if (i > shrinkNumber) break; _dict.Remove(pair.Key); } } } // UserCacheItem public class UserCacheItem<TUser> where TUser : class, IUser, new() { private int _pinnedInCache; // _pinnedInCache prevents deletion of data from the Cache on Shrink public object Locker = new object(); // userCacheItem blocked before user editing public long UserId; public TUser User; public DateTime LastAccessTime; public UserCacheItem(TUser user) { UserId = user.Id; User = user; UpdateLastAccessTime(); } public void UpdateLastAccessTime() { LastAccessTime = DateTime.UtcNow; } public void PinInCache() { Interlocked.Increment(ref _pinnedInCache); } public void UnpinInCache() { Interlocked.Decrement(ref _pinnedInCache); } public bool IsPinnedInCache() { return _pinnedInCache != 0; } } It seems to be all beautiful and very effective, but there are drawbacks. First, the global blocking of the entire Dictionary in terms of resource protection is very large - it protects too much data. This is comparable to a huge library and one old grandmother, who in turn gives everyone books. Until Shrink is complete, no one can take context. Secondly, there remains a high competition of threads for execution in the device of Lock itself.
Classic synchronization tools on Windows or Linux to lock or release locks require entering kernel mode. For blocking in Mutex, for example, even if it is free, you need plus or minus 1000 processor cycles. At one time, optimizations were created for this process (for example, CRITICAL_SECTION in native applications, Monitor in .NET). Initially, an attempt is made to take a lock with a single Interlocked.CompareExchange operation, if it is free. If it is busy, it is assumed that the lock is released soon, and SpinWait occurs. Only after the expiration of the maximum number of spins begins waiting for the flow to block. This is very profitable: either there will be no competition, or because of the short blocking time, extra processor clock cycles will not be spent on switching to kernel mode.
This is an excellent optimization in time and processor resources, but theoretically it is possible to choose a degree of competition for blocking, which, due to SpinWait operations, will lead to excessive or explosive consumption of the processor. Let me explain exactly how this can happen: the request detects that Lock is currently busy, and decides to spend, for example, 32 cycles on SpinWait. After repeated unsuccessful attempts, he decides to go to sleep. In such a competition, each Lock will spend extra cycles on Spin in quite a large amount. We have one exclusive lock for the entire segment, through which all requests must pass. In the worst case, this can lead to a critical mass of competition, which will load the processor by 100%.
Six months ago, Microsoft fixed this bug for us in the implementation of ASP.NET, and recently we again found a similar one.
When we were busy with the new version of the cache, a problem arose: during the period of average CPU utilization (about 50–60%), consumption could sharply increase to 100%. This anomalous surge was not associated with an increase in the number of requests over the network or a sharp influx of new users — the server worked at a normal pace.
In .NET there are lots of unique and useful performance counters. One of them with the help of the Monitor class shows how much competition is taking place per second - that is, how many collisions there were on classic locks. With a typical CPU consumption, the collision was an average of 70 per second. At the time of 100 percent loading - 500-600. But the most interesting thing is that the coverage rate of our code with an average load was 90–92%, and at the time of loading the rate dropped to 17%. Our code literally squeezed something else.
What we found: in ASP.NET, there is a closed type BufferAllocator and several derivatives of it. Inside this type there is a pool that allows you to reuse already allocated buffers to reduce the number of objects created. It is implemented very simply: Stack, which is protected by a single lock. The problem was that one application accounted for only one copy of each given type. In fact, we received several global locks that took all requests, albeit for a short time.
After a long review, Microsoft fixed its bug - the number of such allocators was increased to one for each HttpApplication instance. This significantly reduced the number of competitions for blocking and saved us from the anomaly for several months.
Recently, again, there was a problem of sudden and long consumption of 100% of the processor. Already knowing what to look for, we found a bug very close - in the HttpApplicationFactory type, which buffers the HttpApplication instances in the Stack, blocking on each request.
An application with such a bug is considered from several months to six months. We have developed a mechanism that affectionately call the "handbrake". Its essence is simple: the server monitors the CPU utilization and the state of high load on the server. If the state persists for three minutes, we slow down all incoming requests for a short, random period of time, disrupting the chain reaction.
As a result, the peaks became short-lived and invisible to users.
Search for new solutions
Lock acted as a bottleneck of the entire server. It is as if the whole city had one road with one traffic light. We wanted to increase the number of locks in order to reduce the number of competitions. After all, if we increase the number of roads and traffic lights to 10, there will be no less cars, but traffic will be faster.
We found a great ConcurrentDictionary class in .NET. It has locks and baskets, the number of which is equal to the product of the existing processors by 4. The class is implemented as a low lock and allows you to modify yourself from several threads in parallel. If 2 objects go to 2 baskets, they can be locked at the same time, if they are in one - they just wait in the queue. This class is blocked only on addition, subtraction occurs without locks.
Operation evict
When we used Dictionary and Lock, Pin went inside Lock. With ConcurrentDictionary, data retrieval and Pin have become two non-atomic operations. Imagine that we have an Item that lies in the ConcurrentDictionary. We take the context of the gaming entity without blocking and set Pin, but at the same time Shrink comes in, displaces the gaming entity and performs Remove. It turns out a clear race.
You can avoid this situation by simply putting another Lock on Pin, but it will look very ugly. It’s as if the supermarket had 20 cash desks, you paid for one of them, but you still have to go through an extra one so that you can re-pierce the goods for verification with a check.
We came up with a banal simple idea. We wrote the Evict operation, which sets the pin count to a deliberately incorrect value of −1, using the usual Interlocked.CompareExchange operation, if the original value is 0.
Let's return to the situation described above, but already taking into account Evict. There is an Item that lies in ConcurrentDictionary. At the same time comes a request to change the game entity and its replacement. If Evict managed to set the value to −1, Shrink realizes that now this entity is not occupied by anyone and will not be taken later. Pin at this time pretends that there is no object, and tries to go back to ConcurrentDictionary. If Evict didn’t have time to change the value, Shrink realizes that the game entity has grabbed Pin first, and doesn’t touch anything.
In a situation where a Pin with a value of 0 wants to simultaneously take 2 processes, we say that 2 Items can be pinned more than once (Pin will take the value 2). Lock at the same time there will be only one. The value will be set to 2.
public bool PinInCache() { int oldCounter; do { oldCounter = this._pinnedInCache; if (oldCounter < 0) return false; } while (Interlocked.CompareExchange(ref this._pinnedInCache, oldCounter + 1, oldCounter) != oldCounter); return true; } public void UnpinInCache() { Interlocked.Decrement(ref this._pinnedInCache); } public bool EvictFromCache() { return Interlocked.CompareExchange(ref this._pinnedInCache, -1, 0) == 0; } // UserCache public bool TryGet(long userId, out UserCacheItem<TUser> userCacheItem, bool pinCacheItem) { if (!_dict.TryGetValue(userId, out userCacheItem)) return false; userCacheItem.UpdateLastAccessTime(); // Return true if item was found. No need to pin or item was evicted. return !pinCacheItem || userCacheItem.PinInCache(); } private void ShrinkOldest(int shrinkNumber) { // Get N oldest elements. Evict the oldest elements from the Cache if possible // Make additional Select call to prevent detecting sequence in LINQ as ICollection in Buffer class and prevent using CopyTo method var orderedByAccess = _dict.Select(kvp => kvp).OrderBy(pair => pair.Value.LastAccessTime); UserCacheItem<TUser> dummy; int i = 0; foreach (var pair in orderedByAccess) { if (pair.Value.EvictFromCache()) { _dict.TryRemove(pair.Key, out dummy); if (++i >= shrinkNumber) return; } } } As a result, we have highly efficient synchronization on Interlocked operations. Thanks to Evict, we got a good reduction in competitions, and the pin point and Evict counter became the synchronization point for crowding out the gaming entity.
The rest of the caches, which do not require the support of such operations for editing and serve only to improve the efficiency of reading data, we also rewrote to use ConcurrentDictionary.
This approach gave a good additional effect: reduced the server load by 7%. During periods of non-critical due to a bug in ASP.NET, we have from 0 to 2 competitions per second and up to 10 in a short period after a complete garbage collection.
KeyLockManager and LockManager
We have developed for ourselves an interesting and quite effective tactic of work in a multi-threaded environment for editing objects. KeyLockManager essentially contains the same ideas as ConcurrentDictionary, Pin, UnPin. But in itself does not store any data, and allows you to synchronize streams by key value.
Suppose there is a goal to write data to a file or send it to the network from two streams at the same time, but there is no desire (or possibility) to put Stream instances in the cache itself. When using KeyLockManager, streams can be synchronized, for example, simply by the name of a file, while storing it in another place (or generally instantiating it only after they receive exclusive access by key).
LockManager is already a more complete derivative of the cache. It is essentially represented by the same ConcurrentDictionary with Pin, UnPin, and Evict, but without saving to the database. This is a generalization of the idea of synchronization with locks, where you can put absolutely any data.
We found the use of LockManager in visualizing the movement of troops on a global map.
Is everything good in the end?
Thanks to the situation with the bug in ASP.NET, we have become better versed in the features of the synchronization mechanism and parallel access to data and more efficiently use them. ConcurrentDictionary we now use everywhere, but we understand our actions and their consequences.
The only drawback of ConcurrentDictionary is there is no complete documentation on its work. All descriptions are addressed to novice users. In our own practice, we found the following points, which are definitely worth paying attention to. They are not in MSDN and in articles on similar subjects.
Count method - counting the number of elements in ConcurrentDictionary. Nowhere is it written that its execution implies blocking of all baskets and may adversely affect performance. Obviously, the Count on the contract tells you the exact value, but not in all situations it is necessary. If you want to calculate approximately, it is better to use the LINQ .Select (..). Count () operations.
The TryRemove method attempts to delete an object using the specified key. To do this, TryRemove locks the cart, and then searches. This is not bad, but there is a high probability that there is no object in the collection. It is better to first check its availability using TryGetValue, which does not block anything, and then try to delete it. Two search operations can often be more profitable than permanently blocking baskets.
The most interesting method is GetOrAdd. It either returns a value that lies on a specific key, or adds a value and returns it. GetOrAdd has 2 overloaded versions. The first version accepts the value, the second accepts the function to be called in case the value is not found, and will try to add it.
Paradox, but they work absolutely differently. The GetOrAdd variant with a value immediately locks the basket, determines that there is nothing there, and then only executes Add. GetOrAdd with function is valid without initial blocking. If there is nothing in the basket, it calls the function, gets the value, tries to block and add. What is the difference: in the case of a function, we can once again execute the code to calculate the value, but there will be less synchronization. In the case of value, we will perform a permanent lock, thereby increasing the competition. That is, because of a spelling error, you can fundamentally change the work inside. We are using a version of GetOrAdd that accepts a function.
LINQ operation OrderBy. When sending sequences, LINQ checks if the given sequence is an ICollection. Then instead of going through the sequence, the collection will be copied entirely. But this is the ConcurrentDictionary :) Internally, LINQ takes a sequence for a collection, creates a buffer, and copies it there. LINQ goes to this collection through the Count property, which, as we have already determined, blocks all baskets. If the size of the collection decreases, it will exclude the exception “the number of elements does not match.” We deliberately inserted an extra Select request to hide that the sequence could be a collection.
What's next?
At this stage, we have only theoretical ideas for improving the server. They can be used when in some of the server versions we decide to switch to full asynchrony. If the competition score for the ConcurrentDictionary is too large or the processes occur in asynchronous mode, you can synchronously block the object and not leave it until the object is available. Jeffrey Richter came up with excellent asynchronous locks: instead of waiting for the lock to be released, the thread will give up its function, which will be called when the lock is released. Waiting for release is not the same as blocking and waiting. This approach can be converted to cache.
PS
I will be glad to know your ideas, thoughts and discuss them in the comments. Tell us what features do you know and what would you like to read about in the following articles?
Source: https://habr.com/ru/post/323144/
All Articles