Booking.com search architecture

At the HighLoad ++ 2016 conference, Ivan Kruglov talked about how the Booking.com service developed its search - one of the central functions of the online hotel booking system.
Hello! I am Vanya, I write in Perl - you can sympathize with me. [Light laugh in the hall and from the stage.]
')
Okay. Seriously, my name is Ivan Kruglov, I'm from the company Booking.com, from the city of Amsterdam. I have been working there for the last 4 years, where for the last year and a half I have been working in a team that makes our search better.
I want to start a little distance. Here is from this phrase:

Do not be surprised if you do not know the author, this is my colleague Eduardo Shiota. Why do I want to show it? In my opinion, it very accurately reflects the culture of developing Booking.com. Its essence is that we must ensure the best impression, the best experience, grow and adapt quickly to the needs of our customers.
There are several components here, I want to briefly run through each of them, at the same time tell about Booking.com. We first presented on HighLoad ++. I think you will be interested.
Statistics
Let's start with growth. We grow like this:

The blue graph is the number of accommodation facilities that are currently in the database. Accommodation facilities are hotels, villas, apartments, and so on. At the moment there are about 1 million. The orange line is the number of nights booked daily. Through Booking.com daily booked over 1 million nights.
The second is quick adaptation. To adapt, you need to understand what your client wants. How to do it? We use this method: we make some observation, then we build a hypothesis why this is happening, and we check this hypothesis. If something went wrong, it means that our observations are incorrect, or its interpretation suffers. We go fix, try again. Most of these options. If our test showed “everything is OK,” then everything is fine, we can move on to the next observation.
The mechanism that we use to confirm these hypotheses is A / B testing or experiments. Experiments allow us to say with some statistical accuracy, yes or no.
There are many experiments, they are different. Experiments are such when we change something graphic on the site:

The classic example is the color of the button, either they added or changed the icon, or they added a new feature, a block appeared, a new item in the menu, and so on. This is something that is visible to the user.
The second kind of experiment is when something has changed inside. For example, we have a new API, or some new service, or we just upgraded or some package. In this case, we want to collect quantitative characteristics. Here on the slide is the response time distribution. The top is what was. Below is what became.

The next and most important point is that we want to confirm that our user has not become worse from our innovation, that is, his experience has not deteriorated.
There is another type of experiment that is very extensive and covers everything. Conventionally, it can be represented as:

What do I want to say here? It is clear that I am exaggerating a little, no one immediately pulls the code into production. But there is no testing - it is very minimal, it is performed by the developer himself.
We have very good monitoring, there is a good experiment tool, which allows us not only to run our experiment on some part of the traffic, but if something happens, we can quickly understand, put out the fire and move on. Plus, we have an error budget - error tolerance, which significantly reduces the moral burden on the developer. A set of these factors allows us to pay more attention to the business side of the issue than to the quality of its implementation.
If you count the number of experiments that are currently running on Booking.com, they will get more than a thousand. Such a number of experiments need to write, zadelopit. Preparing for the report, I looked at the statistics for the last year. It turned out that on average we do about 70 deployes per day. If this is put on a standard eight-hour working day, then it turns out that some part of the Booking.com site changes every 5-10 minutes.
Best experience
In order for our user to have the best impression, the entire company - not just the IT department - has to assemble a big puzzle. There are many elements in this puzzle, some less obvious, some more obvious, some less important, some super-important. For example, the list might look like this:

It is clear that the list is incomplete, just an example. One big obvious point that should be here is a good search, which, in turn, should provide two things: it should be fast, it should give up-to-date information. In my report, I will talk about these two things: the speed and relevance of information.
Let's talk a little about speed. Why is speed important? Why do we all make our sites faster?
Someone does to compete with competitors. Others do so that customers do not leave them, there was more conversion. If we ask Google, it will give us many articles that will talk about it. This is all so, on Booking.com we do it all. But we single out for ourselves another interesting component.
Let's imagine that we have a conditional search page, which conditionally takes two seconds. Imagine that these two seconds are our threshold, after which our client becomes ill. If within our search page our main search logic takes 90% of the time, then for all features, for all other experiments, only 10% of the time remains. If we suddenly launched some kind of hard experiment, then it can push us beyond two seconds.
If we did it quickly, the search began to occupy only 50% of the time, then a lot of time was freed up for new features, for new experiments. One of the things why we do on Booking.com quickly - we want to free up time for experiments, under the features.
Search
Then we talk about the search and what is special about it. We will talk about the evolution of the search, about its current architecture and conclusion.
I want to start with an example. Let's imagine that we have a guest who wants to go to Paris. He can go there alone, with his family, with friends, by car, if he lives close (then it is desirable that he has a parking lot, where he will stop), and he can also go by public transport (then it would be nice if the stop was not far). And of course, he wants breakfast. The task of Booking.com is to help him find a temporary place of residence that meets all his requirements.
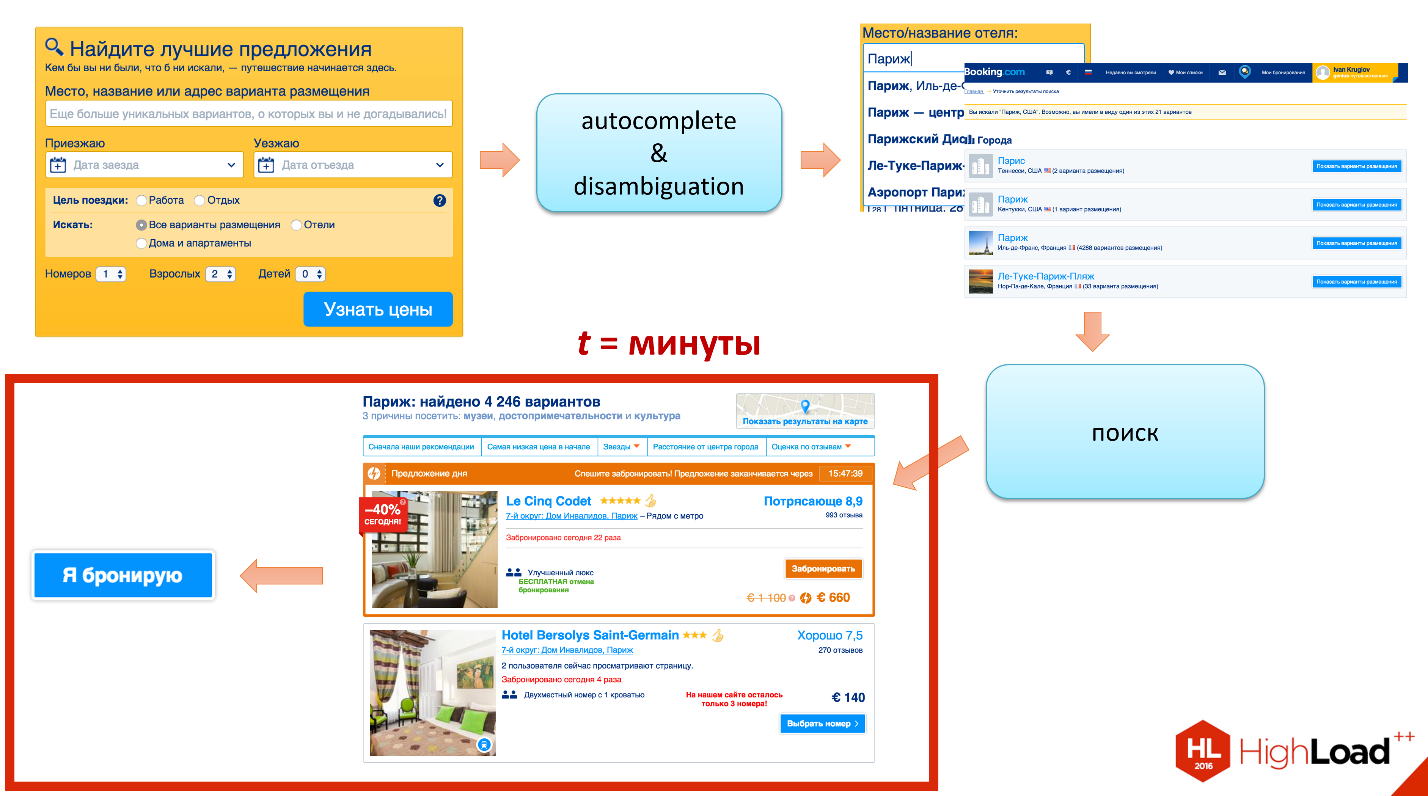
What does the interaction of our guest with the site look like in this case? He first comes to the main page. There is a form there, I think you all know it. He drives a "Paris". He immediately begins to interact with the autocomplete & disambiguation service (clarifying ambiguities), the purpose of which is to help us understand exactly what geo-location he has in mind.
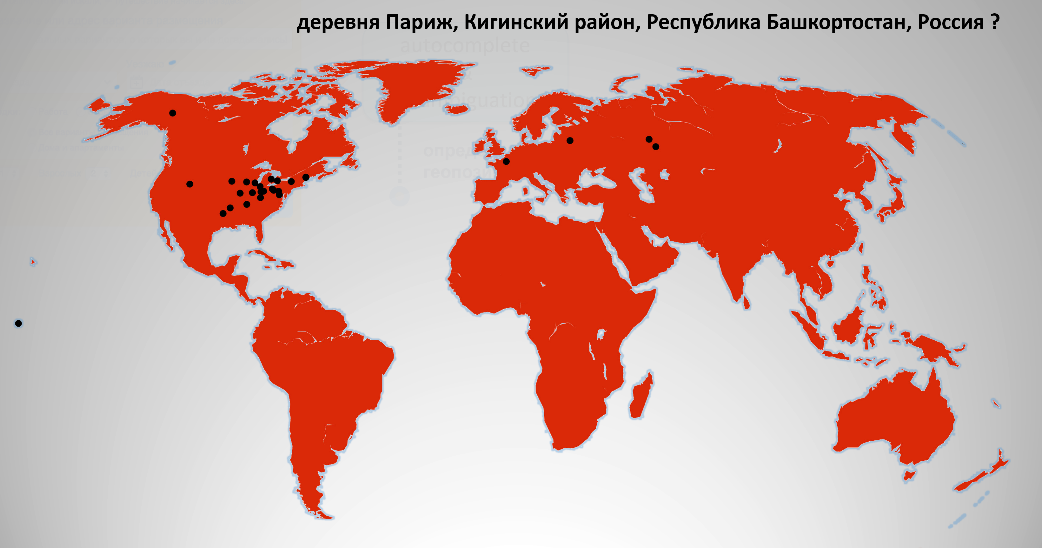
The fact is that if you simply search for the word "Paris", then it turns out that there are about 30 pieces in Paris all over the world. For example, the village of Paris, Kiginsky district, Republic of Bashkortostan, Russia. This is hardly what he had in mind. There is a village in Belarus, even two, one island of the Pacific Ocean, there are 10-15 pieces in the USA.
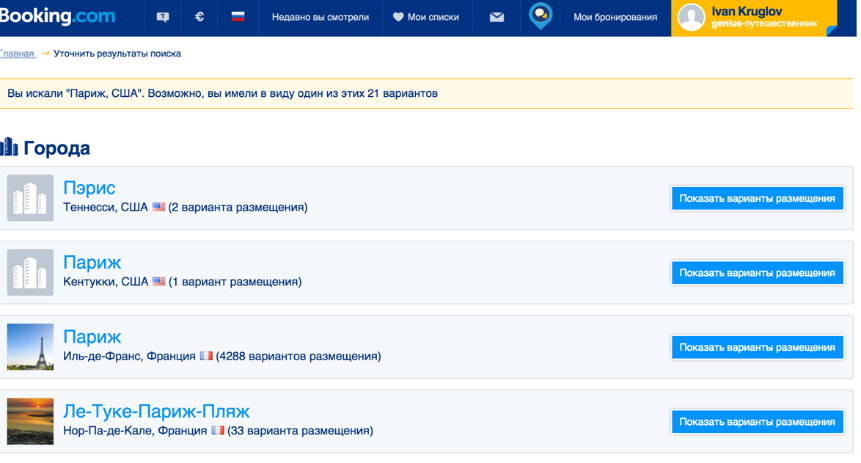
Our user begins to see a list where he can choose what he means.

If there is no element in the list, then our guest will be redirected to disambiguation, where, in fact, the same data, only the list is a little more - a couple of dozen elements.
As soon as our guest has explained what he wants (I want in that same Paris), a search query is formed in the search logic, which does the following:
- It selects a hotel by attributes , for example, filters hotels that do not have a parking, or which do not have breakfast.
- Then she does, if necessary, group fit . If our guest travels with his family, the family is large - 6 people, but we do not have a room that accommodates 6 people, we can try to play: 3 + 3, 4 + 2, 5 + 1.
- Next is the selection of hotels for availability .
- And in the end the ranking .
When the search service has worked, a search page is formed, on which our guest reads the description and review, looks at the prices, chooses. As a result, goes to the final stage - booking. At Booking.com - new booking, success, all is well.
Here I want to make two digressions. First, my further report will be about that search box, I will focus on the search logic, what is going on inside there. Second - I have already mentioned the selection for availability. Let me tell you what I meant to make it clear.
Here you need to define two terms. The first is inventory , availability. The second is availability . What is the difference?
Let's imagine that we have the “House with a Pipe” hotel. There is one room in it, and its owner wants to hand over this hotel for the New Year holidays. He set the following prices:

From January 1 to 2 - 2000 ₽, from 2 to 3 - 1750 ₽ and so on. This is the data our hotel works with. Hotel, room, date, price.
From the point of view of our guest, everything looks a little different. He thinks like this: “I want to stay in the“ House with a pipe ”hotel from January 1 to January 5, its price for me will be 6500 ₽”. The data is the same, the presentation is slightly different. The transition between these representations is not always trivial.
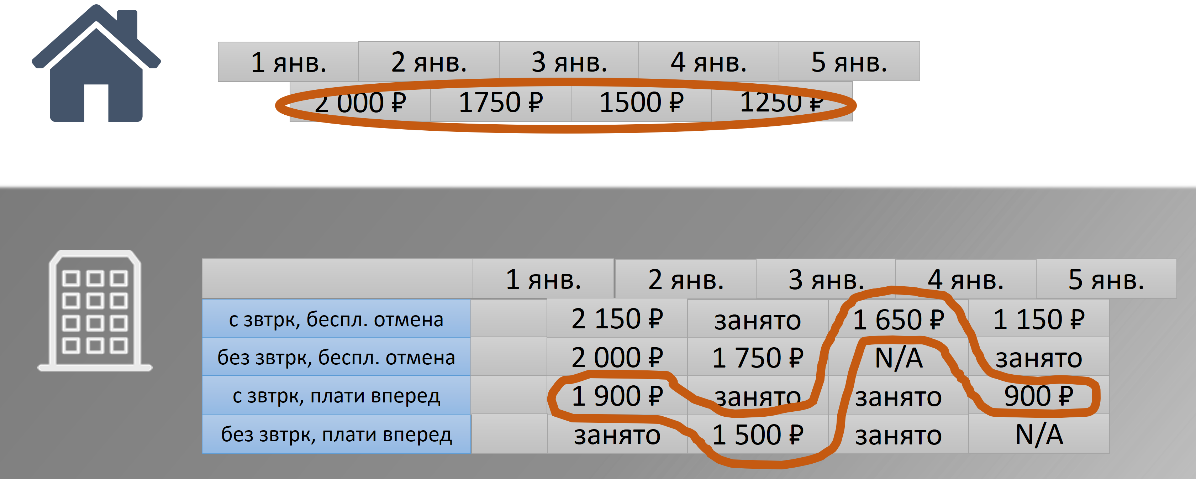
In this case, it is simple, we just take and summarize them. And if we have a big hotel where there are a lot of rooms, a lot of tariffs, a lot of policies, some rooms may be occupied, some politicians may be unavailable? The result is a non-trivial price calculation function.
Search evolution
With the introduction finished, it was determined with the search, I introduced the terminology. Let's go to hardcore.
In ancient times, when we had fewer than 100,000 hotels in our database, Booking.com used a warm LAMP stack. LAMP - Linux, Apache, MySQL and P - not PHP, but Perl. Also Booking.com used monolithic architecture. Business processes were as follows:
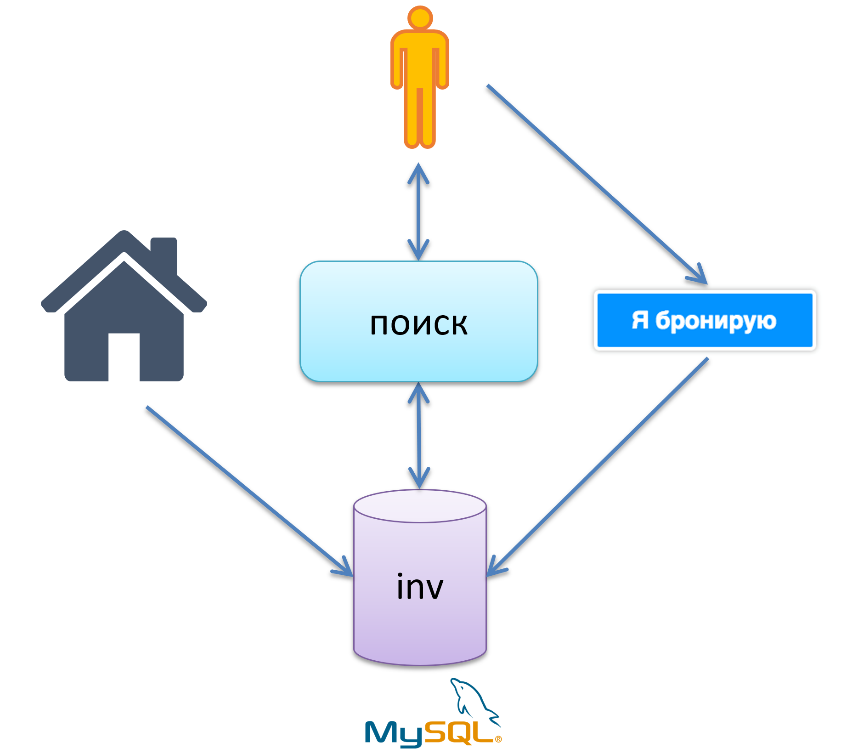
Our hotel. There is an inventory database in MySQL, the hotel brings in the data: I am such a hotel, I have such a room, on such and such days my price. Next, we have search logic that pulls data from the inventory database, calculates availability and gives the search result to our guest. Then the guest goes to the stage “I am booking”. The logic of this stage goes to the inventory database and makes a minus-minus to some record, saying that there is no such number anymore.
In the area of 2010, when there were about 150,000 hotels in the database, this approach has completely exhausted itself. The problem was in the difficult calculation of availability. This feature was very heavy. To better understand what the pain was, here is an example:

If at that time there were 500 hotels in the database, each with an average of 3 types of room, 2 tariffs, then in order for us to sample and sort it by price, you need about 3 thousand calculations. According to archival data, our stack could give something like this:

In one second I could calculate only 1000 prices for living in one day and only 90 for living in 30 days. The longer our stay, the more options we need to go through.
By the way, for this reason, in Booking.com for some time in 2008 there was no sorting by price. I personally remember the first time I came to Amsterdam while still a student. There was little money, I want to find the cheapest hotel. I could not sort by price for just this reason. Now this is all good.
What to do?
- The first thing that came to mind colleagues - let's all caches . It did not work. It turned out that the max cache hit ratio was only 60%.
- Let's rewrite everything to a new technology . We decided not to do so. Why? First, the monolithic architecture. That is, if you rewrite, then you need to rewrite most of it, it takes a lot of time. Secondly, agility will suffer. Companies need to move forward. Let's see what is better?
- Let's try to materialize everything.
What is materialization? In this context, this is about the following. Returning to the example, we take and simply predict all possible combinations of check-in and length of stay. For example, from the 1st to the 2nd, from the 1st to the 3rd, from the 1st to the 4th, from the 1st to the 5th, from the 2nd to the 3rd, from the 2nd go to 4th and so on We take and consider everything in advance.

We get good performance, because everything is calculated in advance, we just need to pull out this price. It turns out an even way, which is important. We don’t have a fast path when data comes from a cache, for example, and slow when it’s not in a cache. The disadvantage is a huge amount of data. We need to keep all these options.
On this option, and stopped. To understand how huge this data is, I'll show you the current information:

At the moment there are 1 million hotels, 3 types of rooms, 2 tariffs, from 1 to 30 days the duration of stay. (It is impossible to book a hotel for 2 months in Booking.com for a maximum of 30 days.) Data is considered approximately one and a half years in advance. If you multiply all these numbers, it turns out that about 100 billion prices are currently stored in Booking.com.
Business processes in the case of materialization

Familiar hotel, familiar inventory database. A new availability base and a materialization process appear, which materializes prices and adds them to the availability database. The search logic uses pre-calculated prices, and the booking logic still changes the data in the original inventory database. It turns out that inventory is our primary database in which the whole truth lies, and availability is its some cache, in which the hit ratio is always 100%.
With this scheme, there are two challenges. The most important thing: how to make it so as not to spoil the user experience? How not to make it so that we first said in the search logic that there is such a hotel, there is such a number, and then, when we went to the booking stage, we said that it does not exist? We need to maintain our two databases in a consistent form.
In order to solve this problem, made the following observation. I return you to the diagram, which I have already shown, how our user interacts with the service.
Look at this part, when the search selection was given, the transition to the stage “I am booking”. Here you can see that the time that the user spends here takes minutes: 5-10 minutes while we read the review, while we read the description. It turns out that when our guest moved to the booking stage, it may happen that the last room he wanted to book has already left. There is some natural inconsistency in the business model.
Even if we make our two databases absolutely consistent, there will always be a percentage of errors at the “I book” stage simply because that is nature. We thought, why would we then make the data completely consistent? Let's make them inconsistent, but the level of errors that occurs due to this inconsistency will be no higher than the threshold that is due to business processes.
Pipeline
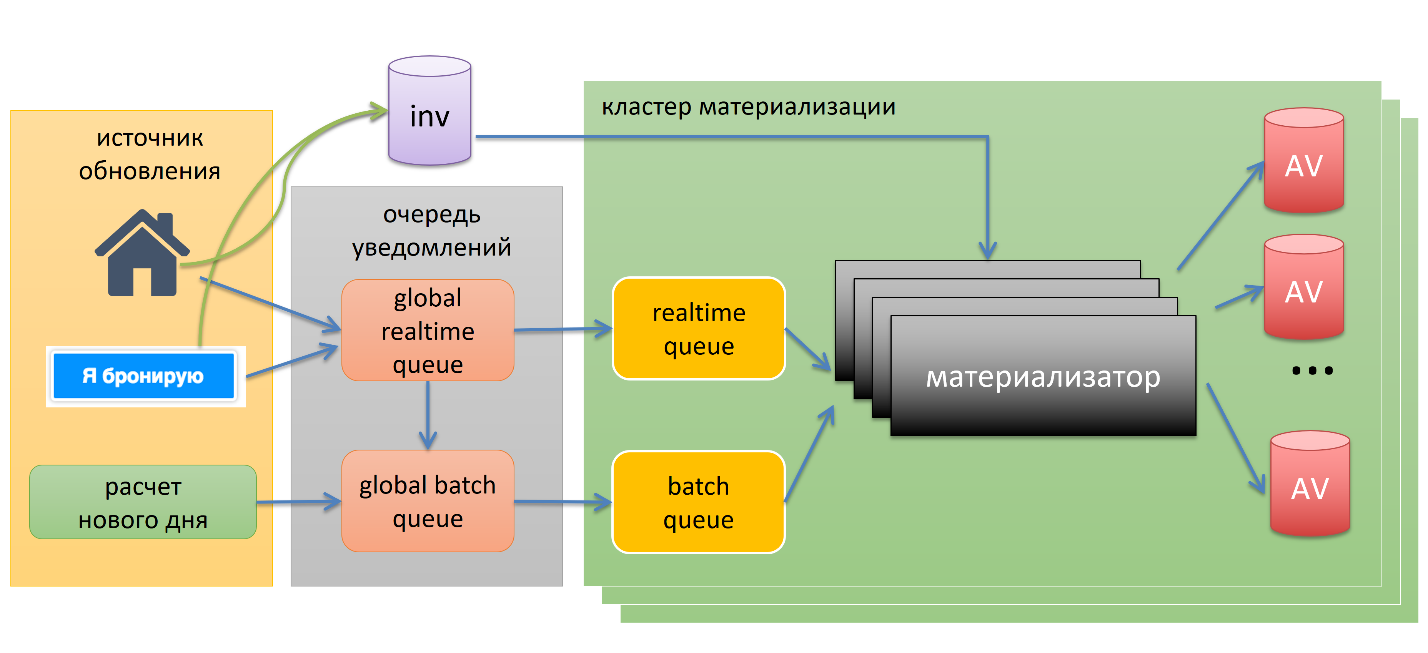
First of all, we have sources of updates. Whenever they make a change to inventory, they send a notification to one of the global queues. The notice is, for example, “such a hotel, they have booked a room” or “such a hotel has changed the price”.
There are two lines, one is realtime, the other is batch, this is a backlog. This is done to set some priorities. If we have a reservation for tomorrow, it makes sense to count faster than a reservation for the year ahead.
Further notifications flow into one of the materialization clusters, where there are many materialisers. They are specially made over capacity so that in the event of a problem, we can quickly pounce on our line, quickly calculate everything and quickly add everything to the base of availability. They pull the data from the inventory database, sort through all the possible options and put in the availability.
There is one interesting point. The blue button “I am booking” sends a notification not only in the case of a successful booking, but in the case of an unsuccessful booking, in the event of an error. In the event of an error, we know that there is potentially some inconsistency - let's calculate it just in case, that is, such a self-healing mechanism.
The last element is the calculation of the new day. Roughly speaking, availability is such a moving window with a size of one and a half years. Every day we need to calculate one year and one day ahead, for example. They always go through the batch queue for obvious reasons.
Data storage

There is a lot of data, requests for reading and search requests prevail. Therefore, optimized for reading. Used cunning clustered primary key index, stored in MySQL.
Why clustered? Why geo-location? Whenever a search is performed, it is performed on a group of hotels that are close to each other - this is a property of locality. It would be good if those hotels that are geographically close in reality, were close to the database. So that our poor MySQL would not have to run on our disk in different directions. The more compact the data is on the disk, the better.
For this we used the Z-order curve technique, I will not dwell on it, everything is very simple there. More on the link .
Did sharding on check-in. There are many entries: a single inventory entry can cause thousands of entries changes in availability. Therefore, we had to use SSD - hard drives did not hold the load. The load was 4 thousand IOPS.
results
- Received the acceleration of the calculation of availability in the 50-100 times. We do not need to count, everything is counted, just take and pull out the right.
- Due to the cunning clustered MySQL-index, we got a quick cold start. All data are close to each other, you need to pull up a few pages from the disk.
- Got the materialization time in normal less than a minute. In practice - tens of seconds.
- In order to make sure that our initial assumption is valid, we have overlaid the system from head to foot with all sorts of metrics and alerts. The key metric was quality check. Quality check is some kind of external process that selects from availability, selects from inventory, reads the availability based on this data, and compares. If our data matches, everything is fine. If there is no data different, or there is no record, and there too, we send a notification, some kind of alert. There are always such alerts, but it is critical that they do not go beyond a certain threshold.
Materialization solved the problem for a sufficiently long period of time. During this time, the stack has changed a bit, they began to use uWSGI + Nginx + Perl + MySQL.
In the area of 2014, there were about half a million hotels in the database, there was a growth in business, new features appeared, a search appeared by countries and regions. For example, in Italy - 100 thousand hotels.
We rested on the same problem, only slightly from the other side. The problem was that we have Perl, it is single-threaded. One request is processed by one worker. He is not able to digest all these samples, sortings and so on.
What to do? We decided to parallelize the whole thing according to the Map-Reduce scheme. Wrote your Map-Reduce framework. Switched to service-oriented architecture. And got the following results: we have big requests have become faster. Due to this, our request beats to smaller ones, it is sent to the worker, the worker looks at his small parts, sends the data back to the main worker, he merges the whole thing and builds the final result.
Large queries have become faster, but at the same time the search around the world began to take about 20 seconds. Still not very good, but better than it was. The counter result was that small queries became slower. The reason for this is big IPS overheads, in particular, for serialization and data transfer between processes. Perl is single-threaded, and we can only serialize it with a variety of processes.
This is about the time when they began to think about changing the architecture that led us to the architecture that we are currently using.
Current architecture
We understood that if we modernized what we had, tweak, tune, change workflow, then in the trailer it can be made to work for some time. But the stack was close to exhausting its capabilities. Our camel is a little tired.
I wanted to abandon outdated approaches. The architecture was built on the approaches under which the foundation was laid 5-10 years ago, when there were 50–100 thousand hotels in the database. Those approaches that were used at that time are very poorly suited when we have 500,000 or even a million hotels in our database, as at the moment.
I wanted to save MapReduce, I wanted to save the service-oriented architecture. I wanted our service to have quick access to availability and all other data that is needed to fulfill a search query. I wanted a fast database to write to quickly. For us update availability. I wanted to have cheap concurrency.
Looked around. We liked Tarantool, we tried it. That was about a year and a half ago. However, they decided not to use it for the following reasons.
First of all, we were greatly embarrassed by the fact that if we switch to Tarantool, we will have to write all the business logic on Lua. We don't know her very well, even though she is a good student. It's one thing when you have a script, a small stored procedure, another thing is the whole business logic on Lua. The second is the code that we took and immediately wrote on Lua, we did not work as fast as we would like. We had a parallel implementation in Java. Java code worked faster.
In the end, we decided to switch from Perl to Java. Java gives cheap multithreading, less constant factor. Java is basically faster, it has fewer internal overheads. We decided that all the data we have is in-memory for quick access. We decided that we are switching from MySQL to RocksDB.
Architecture

The search node is in the center of everything, its availability database is locally embedded. This means that the database is in the same namespace as your process. This node has in-memory indexes, there is an in-memory database that is persisted.
Nodes are many, they are combined into a cluster. In rows - shards, in columns - replicas. We apply static sharding; we assign handles to each node which shard it belongs to. The number of shards is such that all our data is stored in the memory of the node. We spread the data using the simple “division with remainder” operation, hotel_ id mod N. All replicas are equivalent. We have no master, we are all peer, there is no interaction between the nodes.
Now our search query falls on one of the coordinators, there are many of them. The task of the coordinator is to make a scatter-gather when we take a request and broadcast it to all shards. Each shard, after processing its local data, sends a request back to the coordinator, which merges this data and forms the final result.
Inside the shards a replica is selected randomly. If the replica is not available, we take and try another. Coordinators constantly ping all nodes to understand the current state of our cluster.
In fact, this is a standard search engine, the same Yandex or Google work about the same. We have a cherry here in the form of availability, we need to update the embedded databases, we need to update them in realtime, because the availability changes constantly.
To do this, we used our existing experience based on Perl and MySQL. We used the same Pipeline with a slight change: instead of writing data directly to the databases, we wrote to the materialized queue availability. Why is she materialized? Within the black square of materialization, all the queues were only notifications, that is, the orange queues are the data itself, the meat itself.
How do we update the availability data? Each node, regardless of someone takes and reads this queue, applies the update to its local state.We counted the data once, which is very expensive, and we apply it many times. In this queue, data is stored in the last hours. If the node is lagging behind, she would be able to catch up.
With this scheme, we have a cluster that is eventually consistent. In the end, if all nodes will not work at the same speed, we will stop our changes, then they will all come to the same state.
This situation suits us. Here we rely on the principle that we used in the construction of materialization: we do not need to make our base completely consistent. We only need to make sure that this level of errors does not go beyond the allowable value.
Here, again, there is a quality check, plus we use one metric: we monitor each line, we observe how far it is behind the end of the queue. If she is too far behind, we take her and pull her out of the cluster. This is an automated process.
Let's see what happens inside. We have input data:
- Geography: Paris;
- Attributes search: parking, breakfast and so on;
- Check-in, check-out;
- The composition of the "team" (for example, a family of 6 people).
, . , , value — . , , . , , . — , — .
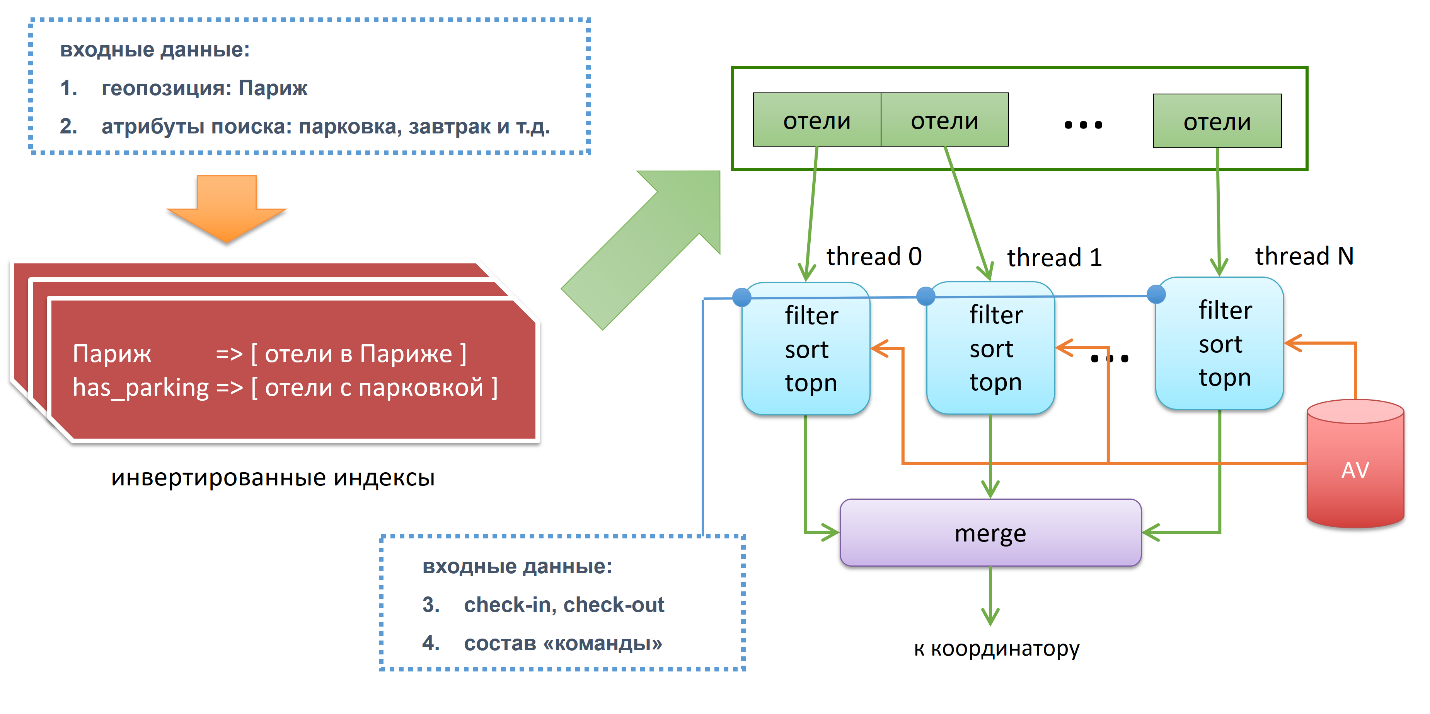
, , , . : availability, , , , . group fit. . topn.
For example, if our search query said “I want the first page,” on page 15 queries. That is, each of the threads will pull out only the top15 and send this data to the main thread, which will do the merge. Merge it is done in the following way: it takes data from all n-threads, it turns out ntop15 and they get top15 from them. Then sends the data to the coordinator, who in turn is waiting for the results from all the shard. From each shard he got top15 and again he does top15. It turns out a cascade reduction of data. So it works inside.
I promised to tell you why we stopped at RocksDB. For this you need to answer two sub-questions. Why is the embedded database? Why choose RocksDB?
Why is the embedded database? I want to demonstrate this sign:
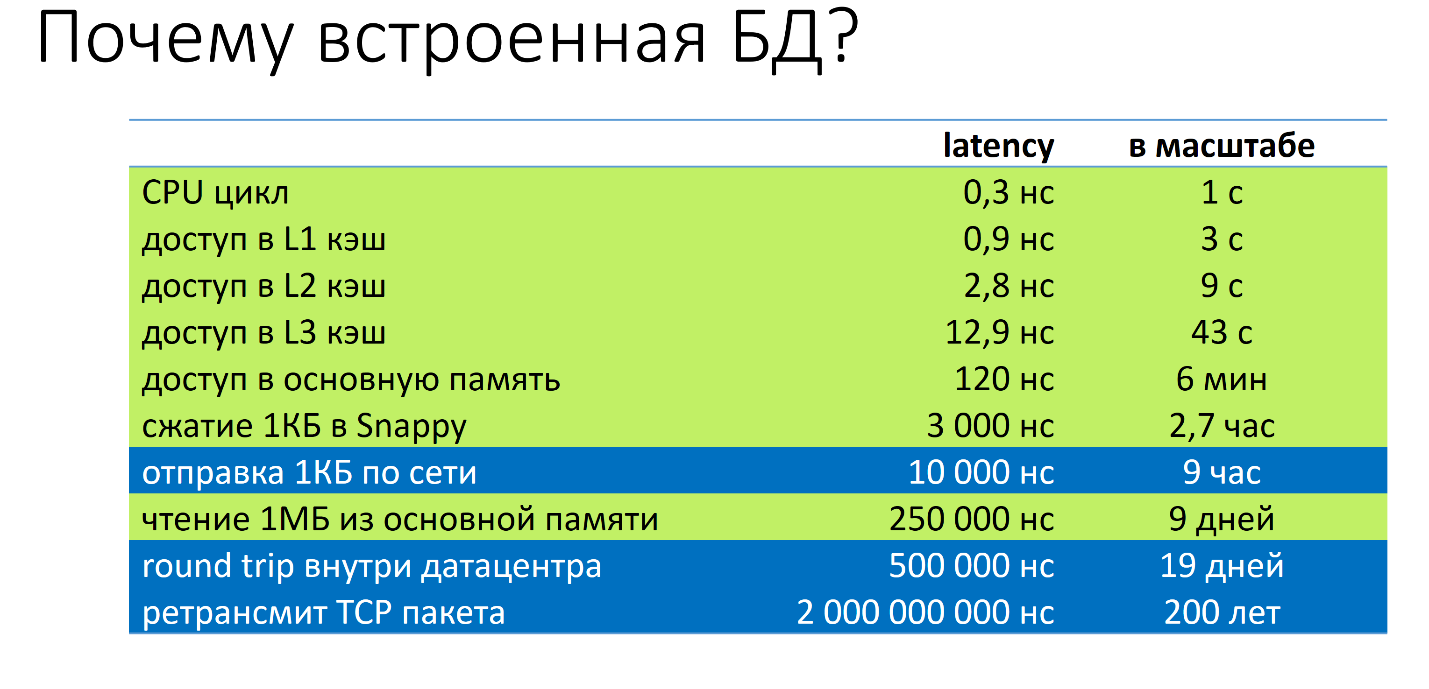
event latency. . — . 0,3 . , 1 ? L1 3 , L3 — 43 , — 6 , — 9 , round trip — 19 , TCP — 200 .
, , , . , — , MySQL, Cassandra, — . .
RocksDB, GitHub, Tarantool, , transaction, QPS (Queries per second), . , .
Why RocksDB? There is a very simple story. We needed a database that would handle our workload. We didn’t need any particular features, just key-value, just store, get, delete. We tried different options: MapDB, Tokyo / Kyoto cabinet, leveldb. How did you try? We just took them into battle conditions: dataset in pagecache, 80% reading + 20% writing, reading significantly prevails. RocksDB showed us the most stable random read performance with random writes. Random record is our update availability, and happy reading is our search queries. We stopped at this.
: RocksDB — Facebook. SSD optimized write and space amplification. . .
:

– , , , , . , . , ( , 30 ), (, 300 ).
, , , , . — , , — 2 . — , , 1,3 . 700 , , . .
Conclusion
: , . , , . RocksDB — , , , workload. , , , . , , .
The second. , . , — , , , .
. . 100 , — - 800 . — 8 . 800 , . , . , .
Be sure to look at your business processes. Your business processes can tell you a lot, they can significantly simplify life. In our case, we say that it makes no sense for us to maintain the consistency of the data between the two databases, because there is a lack of consistency in the business process. The main thing is that the level of errors that was not exceed a certain threshold.
On this I have everything, thank you very much for coming! I hope I told you something useful.
Ivan Kruglov - Search architecture on Booking.com
Source: https://habr.com/ru/post/323094/
All Articles