How custom solutions helped save on network infrastructure

Building a CDN infrastructure is associated with a large number of technical issues: from choosing equipment and installing it in data centers to a user interface for interacting with network capabilities. We provide a translation of an article from the Fastly blog, where the team talks about very interesting custom solutions for working with the network (much of which was independently used in the Airi infrastructure).
As a result of infrastructure optimization, we managed to achieve minimal downtime in case of failure of any node and large system scalability.
Scaling
Gradually developing a CDN is not easy, since the very essence of the service involves customers with an extensive geography of requests. Therefore, Fastly initially focused on what was missing in the industry: maximum transparency and control over how content is delivered at the “frontier”.
')
When we first started, our lack of experience in networking technologies had little effect on what. Our typical point of presence (POP) consisted of two hosts directly connected to BGP (Border Gateway Protocol) providers. By the beginning of 2013, we had grown so much that this number of hosts was not enough.
Scale our topology by connecting even more caches directly to providers, as shown in fig. 1 (a) was impossible. Providers do not want to work this way because of the cost of ports and the complexity of setting up additional BGP sessions.
Fig. 1. Impact of scalable network topology
An obvious solution could be a network device, as shown in Figure 2. 1 (b). Although this could be a valid compromise, the nature of a CDN is such that it implies a constant increase in geographic coverage and traffic.
Today, our smallest points of presence include two network devices, as shown in Fig. 1 ©. How it works is shown in fig. 2. The router receives routes directly from providers via BGP and inserts them into the Forwarding Information Base (FIB). A lookup table implemented by hardware is used to select a route. Hosts direct traffic to the router, which redirects packets to the most appropriate next network segment, according to a search in the device FIB.
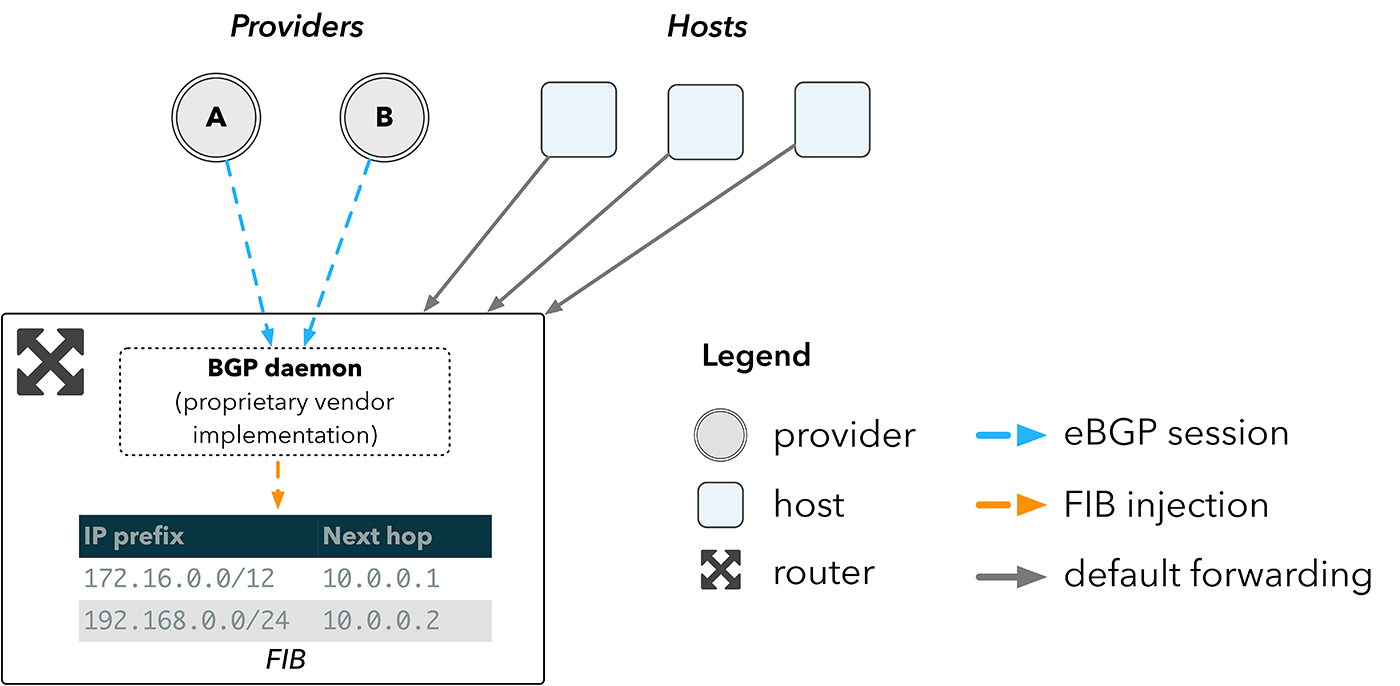
Fig. 2. Network topology using a router
The larger the FIB, the more routes the device can store. Border routers should be able to store the routing table for the entire Internet, which now exceeds 600,000 entries. The hardware that is required to store such a FIB forms the bulk of the cost of the router.
Routing without routers
In traditional cloud environments, the cost of border routers is quickly becoming insignificant amid the sheer volume of servers and switches they serve. But CDNs should have a large number of advantageously located points from where they deliver content. Therefore, network devices can account for a significant share of the cost of the CDN infrastructure.
We didn’t like the idea of spending several million dollars on a very expensive network hardware. We would rather invest this money in regular servers, which are directly responsible for how effectively we deliver the content.
We could use switches, but they have a very limited FIB — on the order of tens of thousands of routes, which is much less than what we need. By 2013, vendors such as Arista began to introduce functionality that would help us cope with this limitation. Vendors began to let us run our own software on the switches.
Instead of relying on the FIB in a network device, we could forward traffic to the hosts. BGP sessions from our providers would still be terminated on the switches, but the routes would go to the hosts.
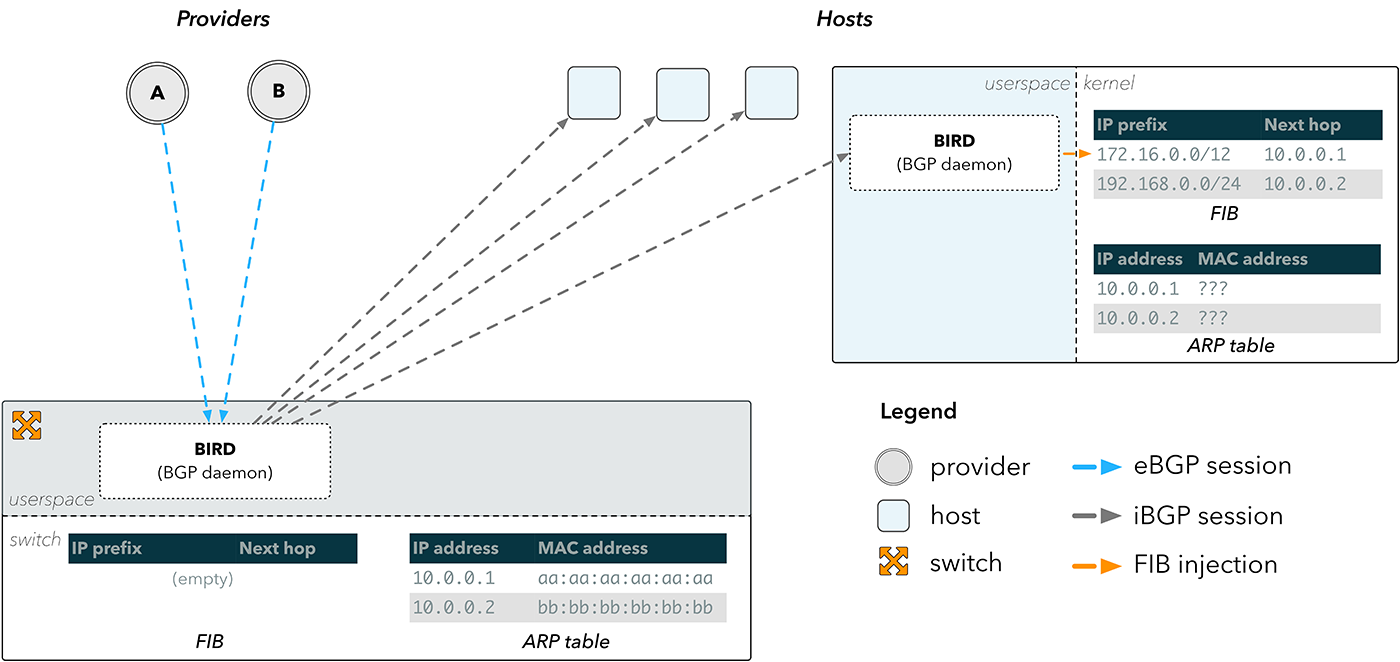
Fig. 3. Reflection of BGP routes
External BGP sessions (eBGP) are terminated on a BGP daemon, such as BIRD, which is running on the switch. The resulting routes are then sent through internal BGP sessions (iBGP) to BIRD running on the hosts, which then inserts the routes directly into the host core.
This solves the problem of bypassing the FIB on the switch, but not the problem of how to send packets back to the Internet. An entry in the FIB consists of the destination prefix and the address of the next network section. To send a packet to the next leg, the device must know its physical address on the network. This data is stored in the Address Resolution Protocol (ARP) protocol table.
In fig. Figure 3 shows that the switch has the correct ARP information for our providers, since it is connected directly to them. The hosts do not possess it and therefore cannot determine the next network segment for what was sent to them via BGP.
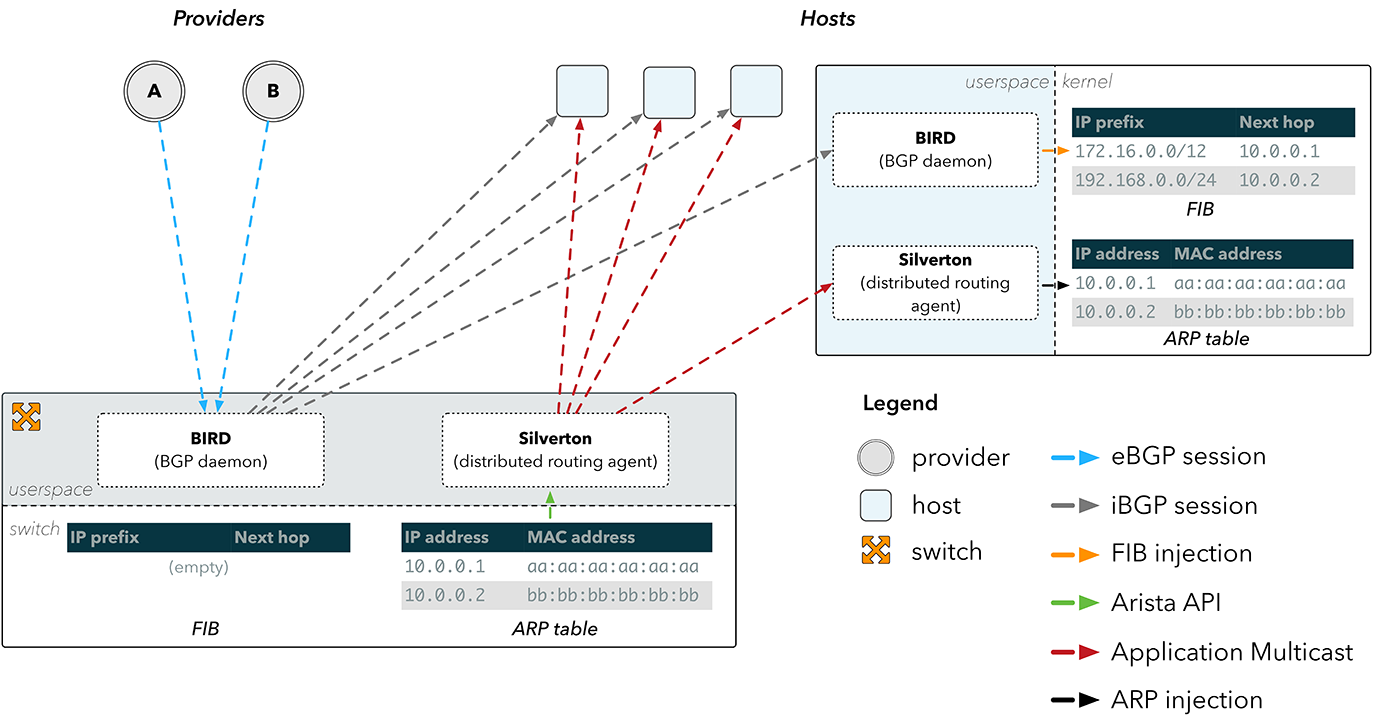
Fig. 4. Spreading ARP with Silverton
Silverton - Distributed Routing Agent
This has led to the emergence of Silverton, our own network controller that manages the routing at our points of presence. We realized that we can simply launch a daemon on the switch, which learns about changes in the ARP table through the API on Arista devices. Having learned about the change in the physical MAC address of the provider, Silverton then spreads this information through our network, and the clients on the hosts reconfigure our servers with information on how to directly reach the providers.
Having the IP and MAC addresses of the provider, the first step for Silverton on the client side is to “trick” the host so that it “believes” that this IP address is directly accessible via the interface or local link. This can be achieved by configuring the IP address of the provider as “peer” in the interface via iproute:
$ ip addr add <localip> peer 10.0.0.1 dev eth0 If the host considers the provider's IP address as a local link, it will look for its MAC address in the ARP table. This can also be corrected:
$ ip neigh replace 10.0.0.1 lladdr aa:aa:aa:aa:aa:aa nud permanent dev eth0 Now every time the route search will return the next leg as 10.0.0.1, and the traffic will be sent to aa: aa: aa: aa: aa: aa directly.
The switch receives data frames from the host to a physical MAC address, which is known to be connected directly. The switch can determine which interface to send the frame to by viewing the local MAC address table, which indicates the corresponding MAC address of the destination and the outgoing interface.
Although the described process may seem rather complicated, our first version of Silverton contained less than 200 lines of code. And it saved us hundreds of thousands of dollars at every point of presence that we deployed. Over time, Silverton “grew up” and began to provide the entire dynamic network configuration: from designating description fields to manipulating routing advertisements and emptying BGP sessions.
In addition, Silverton provided a valuable level of abstraction. He maintained the illusion that each host was directly connected to each provider, which was our starting point (Fig. 1 — option A). By maintaining multiple routing tables in the kernel and choosing which one to use for each package, we were able to create tools and applications on top of Silverton. An example is the st-ping utility, which pings destinations for all connected providers.

Fig. 5. Ping on all transit providers at the point of presence
Prerequisites for Faild
Since we have already seen that by getting rid of traditional network devices, capital expenditures can be significantly reduced, we paid attention to load balancers.
Traditionally, the load was distributed solely using balancers or ECMP routers. Recently, the opposite approach began to gain momentum, in particular, services such as MagLev and GLB are balancing using software running on hosts.
Our development Faild is a synthesis of two approaches, where we use hardware processing on traditional switches wherever possible, and transfer processing to the hosts where necessary. The result of this approach was a distributed balancer.
Balancing client requests: walking on a tightrope
Imagine a set of servers that serves a number of clients, as shown in Figure 2. 6. From the client’s point of view, which server served his request is completely irrelevant as long as the response is received fairly quickly. This gives flexibility in comparing which requests are processed by which resources. This is called load balancing and is implemented at almost every level of the network stack. Here we focus on balancing incoming client requests in the context of a CDN.
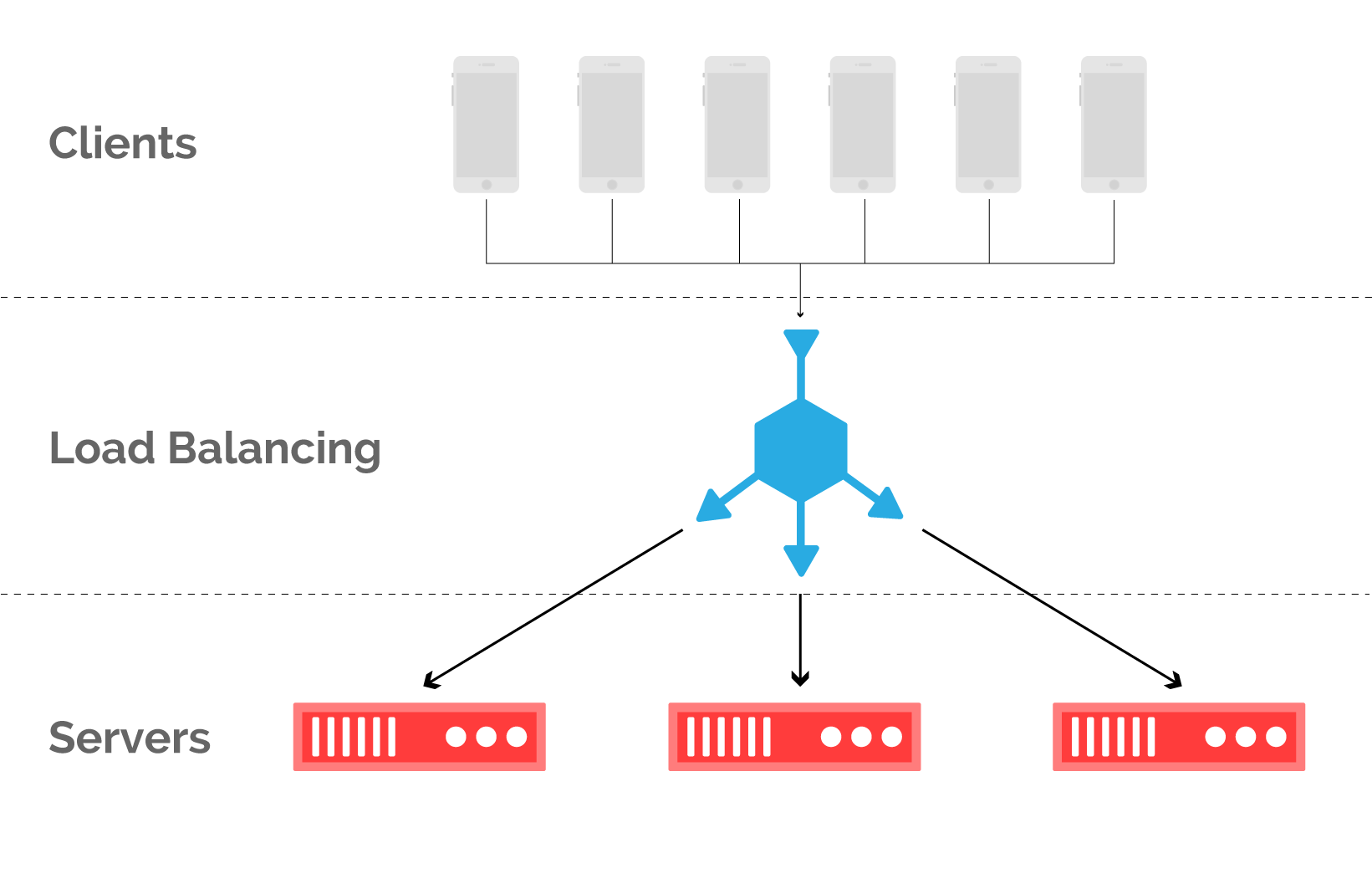
Fig. 6. Balancing client requests with cache servers at the point of presence.
The main problem with balancing http requests is the inevitable limitation: if a packet from an established TCP connection is redirected to the wrong server, then the corresponding TCP stream will be dropped.

Fig. 7. Network topology using the balancer (a) and its corresponding packet stream (b)
Balancers usually work as proxies, terminate connections from clients and send traffic to the backend servers, as shown in fig. 7 (a)
The balancer can monitor the status of the backend servers in order to decide where to send incoming flows. When properly implemented, the distribution of requests across the backend servers is close to optimal, but it is very expensive. The balancer monitors the status of each network connection, and this is a difficult task, for which specialized hardware is often used.
However, maintaining connection status information is an added challenge. As you know, the sender is easier to create connections than the recipient - to track them, and this asymmetry in TCP is regularly used during DOS attacks. Most balancers contain additional means to prevent SYN flooding, but they are still the bottleneck of the network. Even virtualized balancers that run on conventional hardware, such as Google MagLev, require monitoring the status of threads, and therefore DOS attacks are also dangerous for them.
DNS: Workaround
DNS turns names into addresses, and this can be used for load balancing between servers if only the IP addresses of normally functioning servers are returned.

Fig. 8. Architecture of server selection via DNS (a) and the corresponding packet stream (b)
This approach does not require monitoring the status of threads and therefore scales well. However, it has a fundamental limitation in terms of failover. The DNS response can be cached by the resolvers for minutes, and sometimes even hours. The response caching period is transmitted via the TTL field in the response, but this is not always taken into account by resolvers. Therefore, the propagation of the change may take a considerable amount of time during which the client will be connected to the idle server.
Companies such as Spotify or Netflix can control both the end-user application and the servers at the border, and therefore can bypass this DNS problem by integrating server selection into their applications. CDNs like Fastly cannot do this, since they have to work with a variety of options, from video streaming to API calls. The only thing that is known for sure is that the request will be made over HTTP.
ECMP: "Lesser Evil"
Another known alternative is ECMP (Equal Cost Multi-Path). ECMP maps to the same destination prefix several subsequent network sections, and the selection of such a section is determined by hashing the fields in the header of the packet being forwarded. By calculating the hash of such fields that do not change during the life of the stream (source addresses, destinations, and ports), we can be sure that all packets of the stream are sent to the same next network segment.
Servers can signal via BGP that they are available to a connected switch that hashes packets.
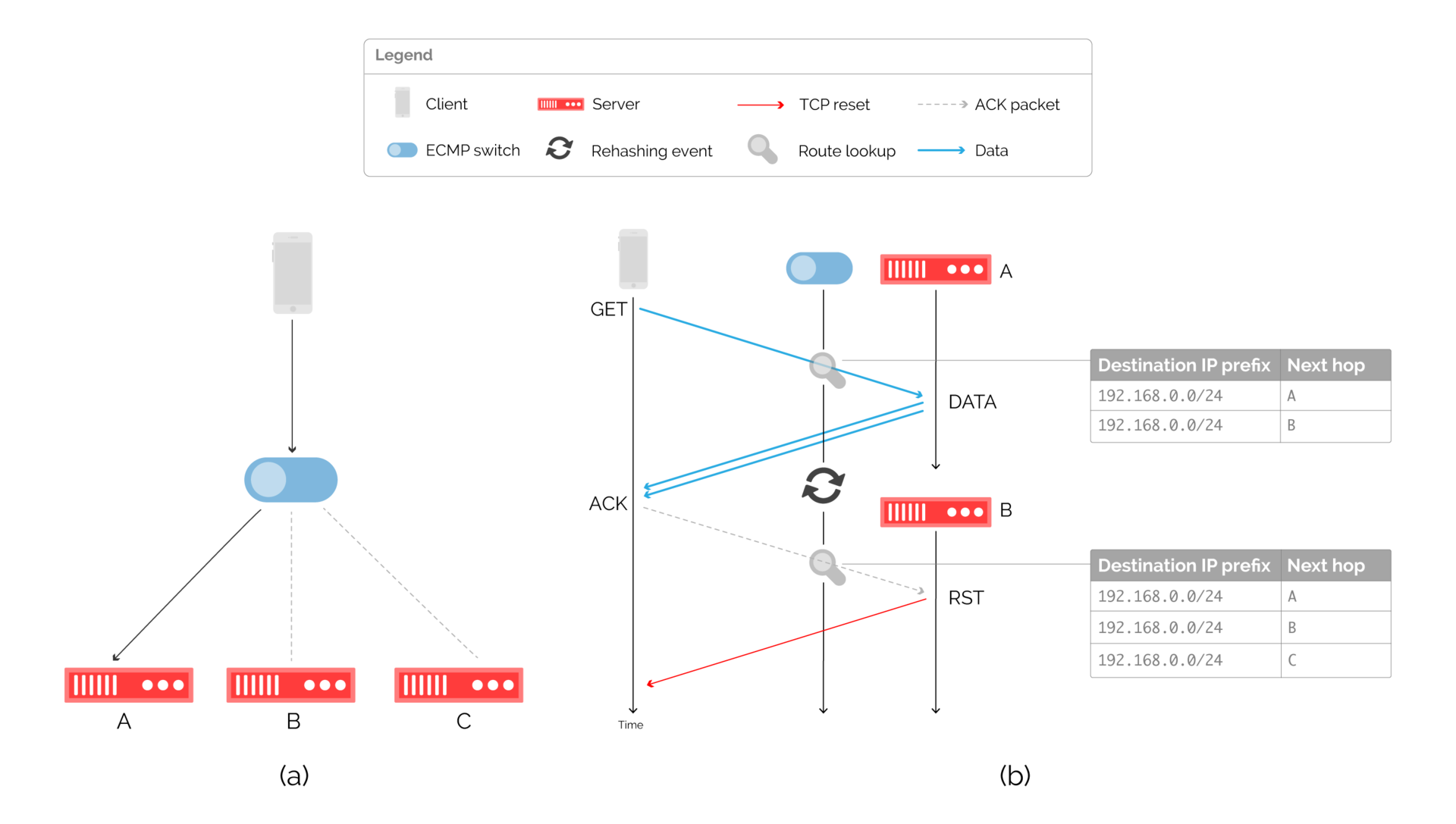
Fig. 9: Balancing through the ECMP switch and the corresponding packet flow at the time of the re-cache.
The disadvantage of this approach is that, until recently, manufacturers did not maintain a consistent hash in ECMP. When changing the route caused by the addition or exclusion of the server, the hash result could change, which is why packets could be sent to another server. This situation is shown in Fig. 9 (b).
Despite this, ECMP remains a popular approach in the CDN industry. By discarding state tracking, ECMP works well with stable server operation, creating connection problems when changing states.
"Elastic" ECMP: first approximation
Rehashing happens when the information about the routes changes (the next sections of the network). A possible alternative would be to use ARP tables as a workaround. By specifying the following static network sections in the routing table, we can force the switch to search the ARP table. We can also reconfigure the ARP table to affect packet forwarding.
Two problems arise:
- We can no longer use routing protocols, such as BGP or OSPF, to direct traffic to servers. Conventional routing protocols provide accessibility by modifying the routing table, but our approach takes traffic management to the connection layer. We need to write a controller that directly changes the ARP table on the switch, as shown in Figure 10. The controller communicates with agents running on the connected caches. Each agent checks the state of the local Varnish entity, which processes http requests from end clients.
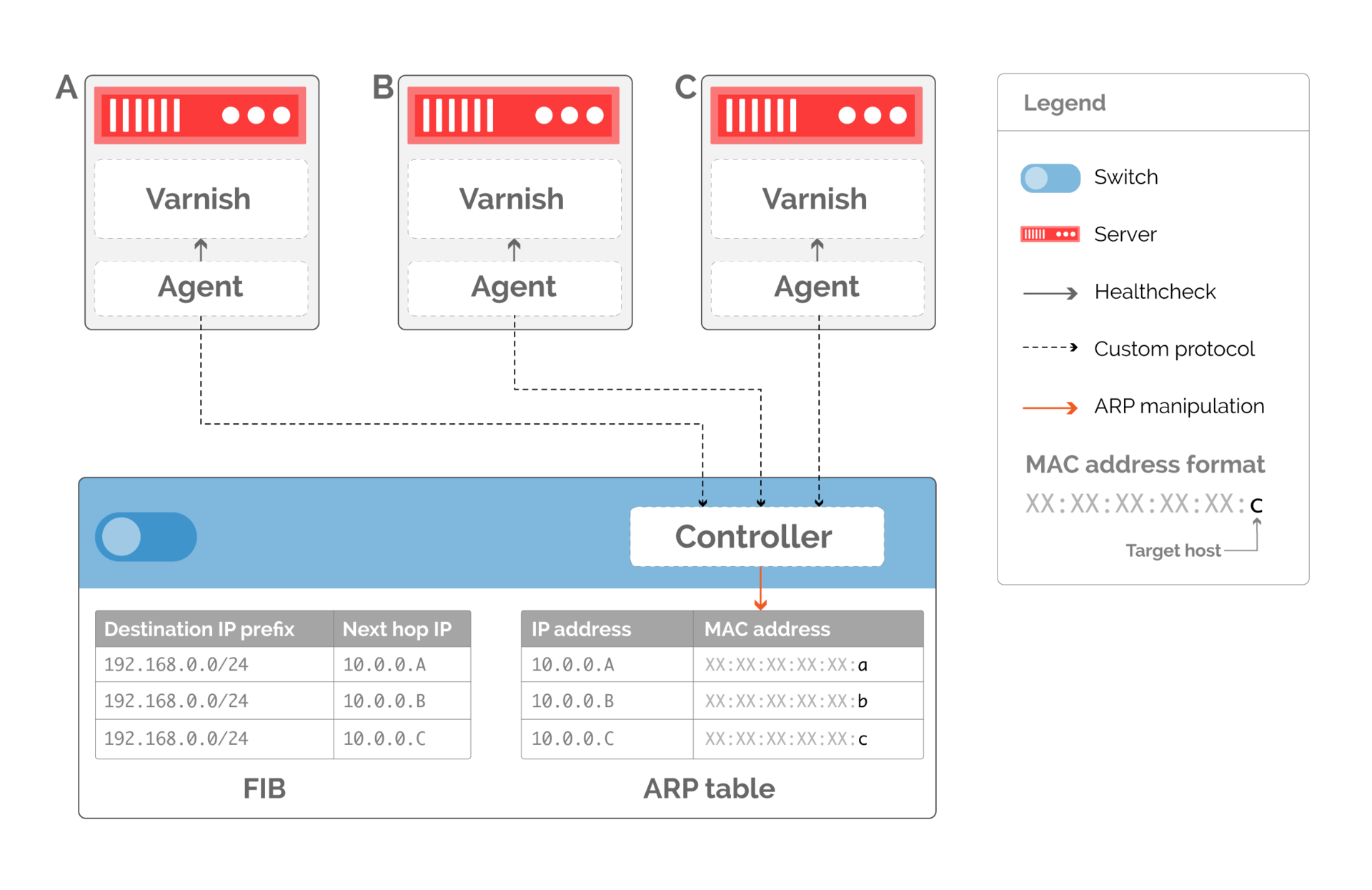
Fig. 10. Custom routing protocol based on changing the ARP-table. The routing table remains constant, and the ARP table is modified to indicate available servers. - The depth of detail with which we can balance traffic is now directly related to the number of the following network segments in the routing table. As shown in fig. 10, if we remove the server serving the traffic, we need to rewrite the ARP entry so that it points to the available server, potentially doubling the traffic to another server. To avoid this, we can create several following network sections, as shown in Fig. 11. If we have two next virtual network sections for each server, then the available servers will have an equal number of ARP entries pointing to them when server B stops working.
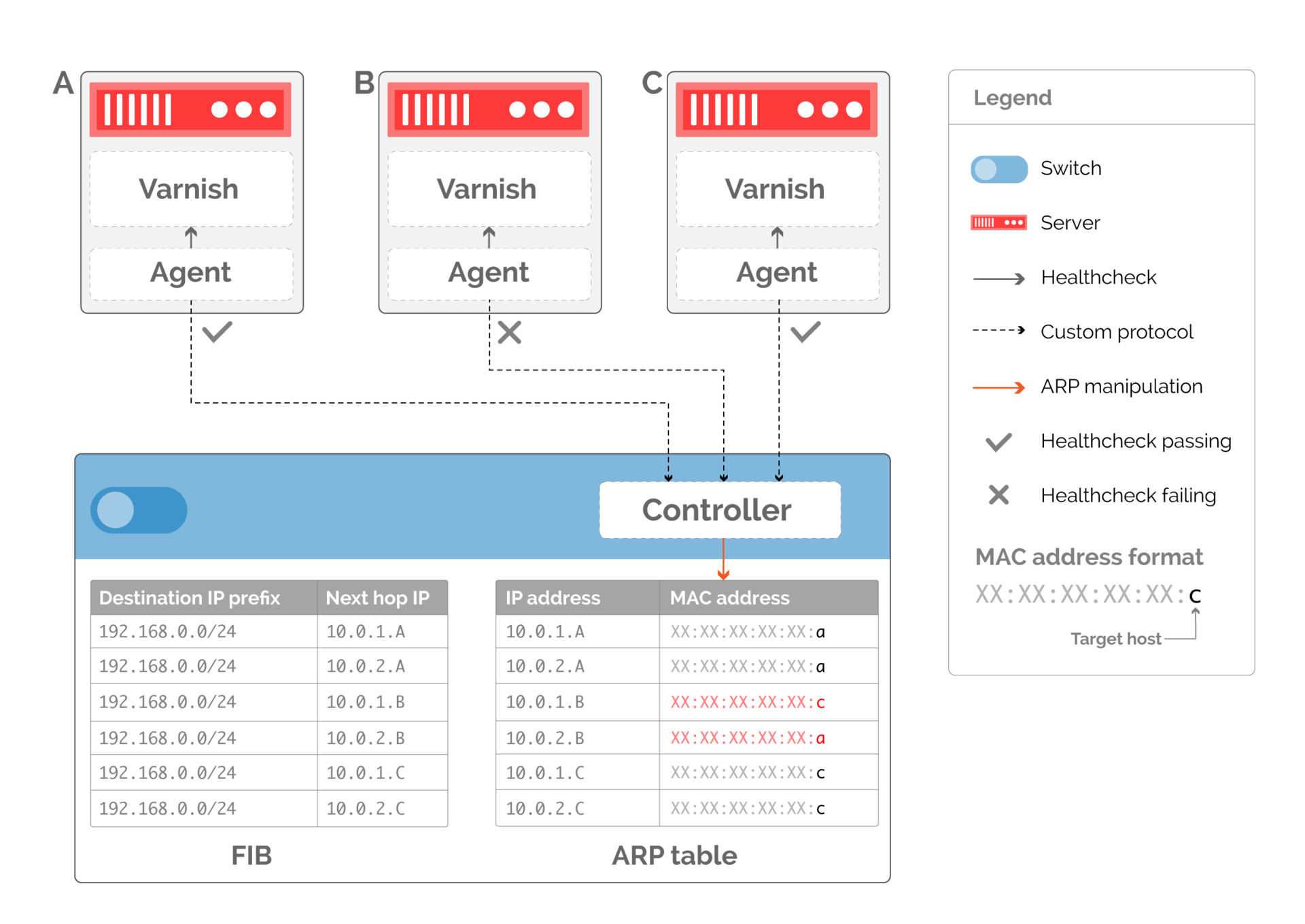
Fig. 11. The following additional network sections ensure uniform traffic distribution when server B stops working.
Faild: bypass layer
“Elastic” ECMR still cannot provide accurate server output from the number of workers. Let's go back to pic. 11. If host B fails, it will cause traffic to go to all remaining servers. All existing connections will be reset.
It is believed that this is inevitable, and it is worthwhile to put up with it, because it is caused by rare phenomena of hardware failure or software problems. However, in practice, servers are often derived from “production” in order to upgrade software. Dropping connections due to this causes not only a temporary traffic problem. This makes it difficult to quickly introduce new software, since every upgrade will cause problems.
Proper failover cannot be implemented only on the switch, since it does not “know” which threads are active at any given time. Our solution was to distribute state tracking between the controller and the hosts. For this we have developed our own solution Faild.
The first step to tidying the server out of production is to signal that. Although our previous examples assumed that the host interface has only one MAC address, in practice there is no such limitation. We can add to the ARP table on the switch not only information about the previously running host, but also about the new one (Fig. 12).
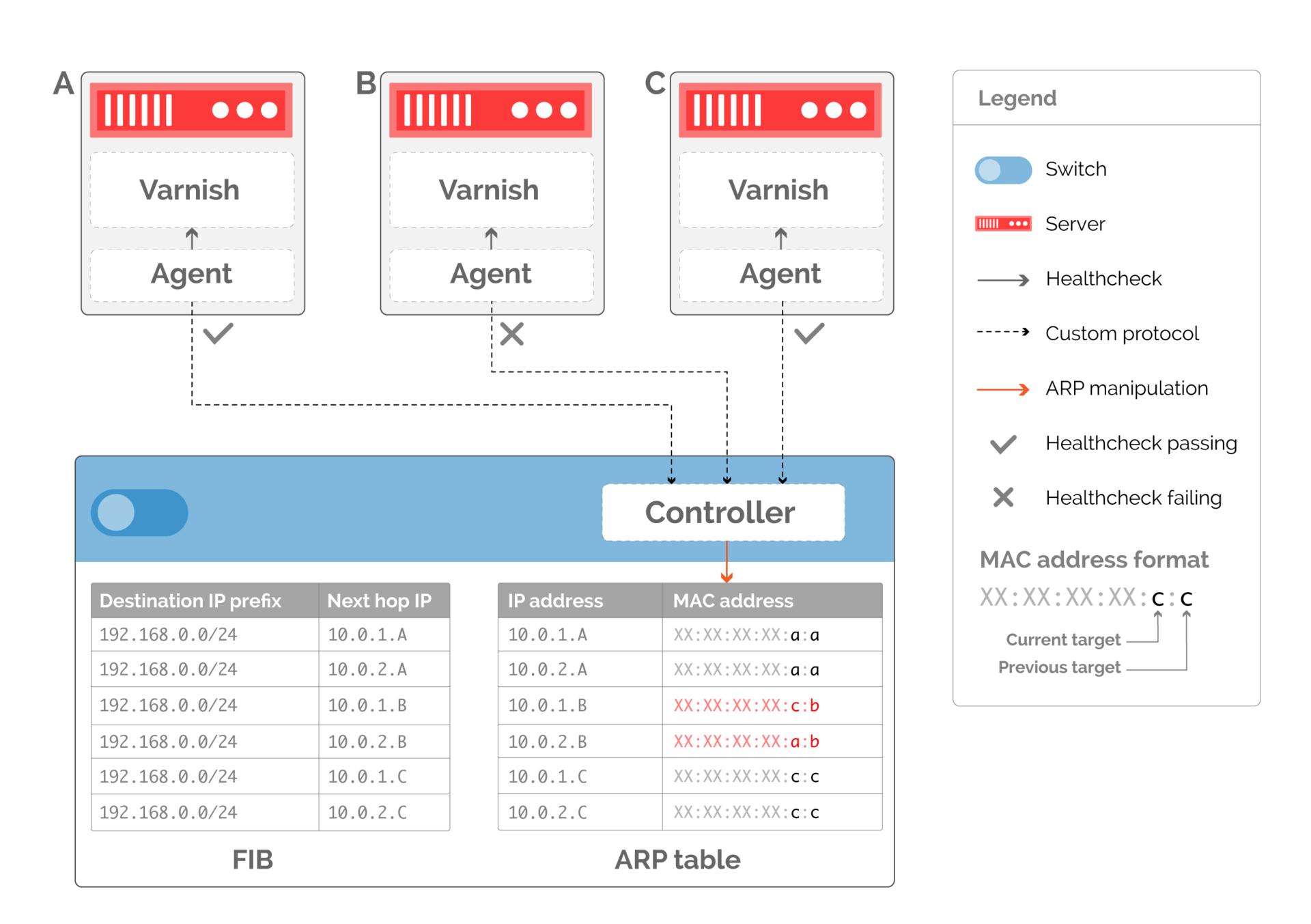
Fig. 12. Coding of hosts to replace broken via MAC addresses
Now that we have transmitted the availability information to the switch, we can delegate the balancing decision to the servers. This not only eliminates the need to monitor the status of flows in the network. It also transfers the computational load to the servers, which are larger at the point of presence than the switches.
This computational load is reduced through the implementation of processing on the receiving side as a separate kernel module. It effectively processes incoming packets according to the destination MAC address (see Figure 13).
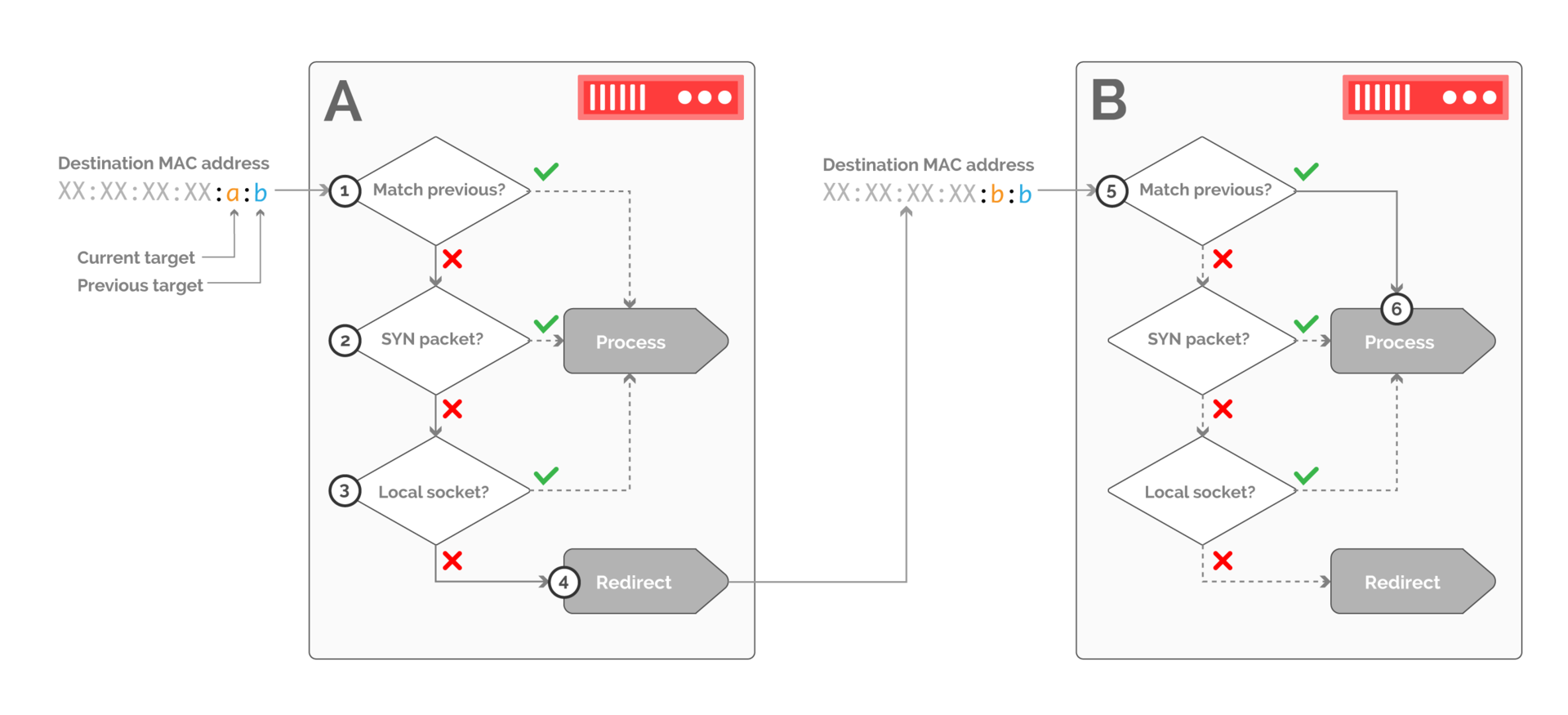
Fig. 13. An example of packet processing on the receiving side when traffic is transferred from host B to host A. Packets are filtered on host A and are only accepted if they belong to a new connection or match a local TCP socket.
The kernel module of the receiving host must first determine whether the previous destination matches this host. If yes, then processing is transferred to the local network stack. If not, you need to make sure that the packet belongs to the new connection (via the SYN flag in the TCP header - step 2), or to an existing connection, which can be done through a search in the socket table (step 3).
If none of these conditions are met, the packet is redirected to the previous destination via rewriting the MAC header.
Similar logic applies on host B (step 5). In this case, the host specified as the previous destination corresponds to the host, so the packet is accepted.
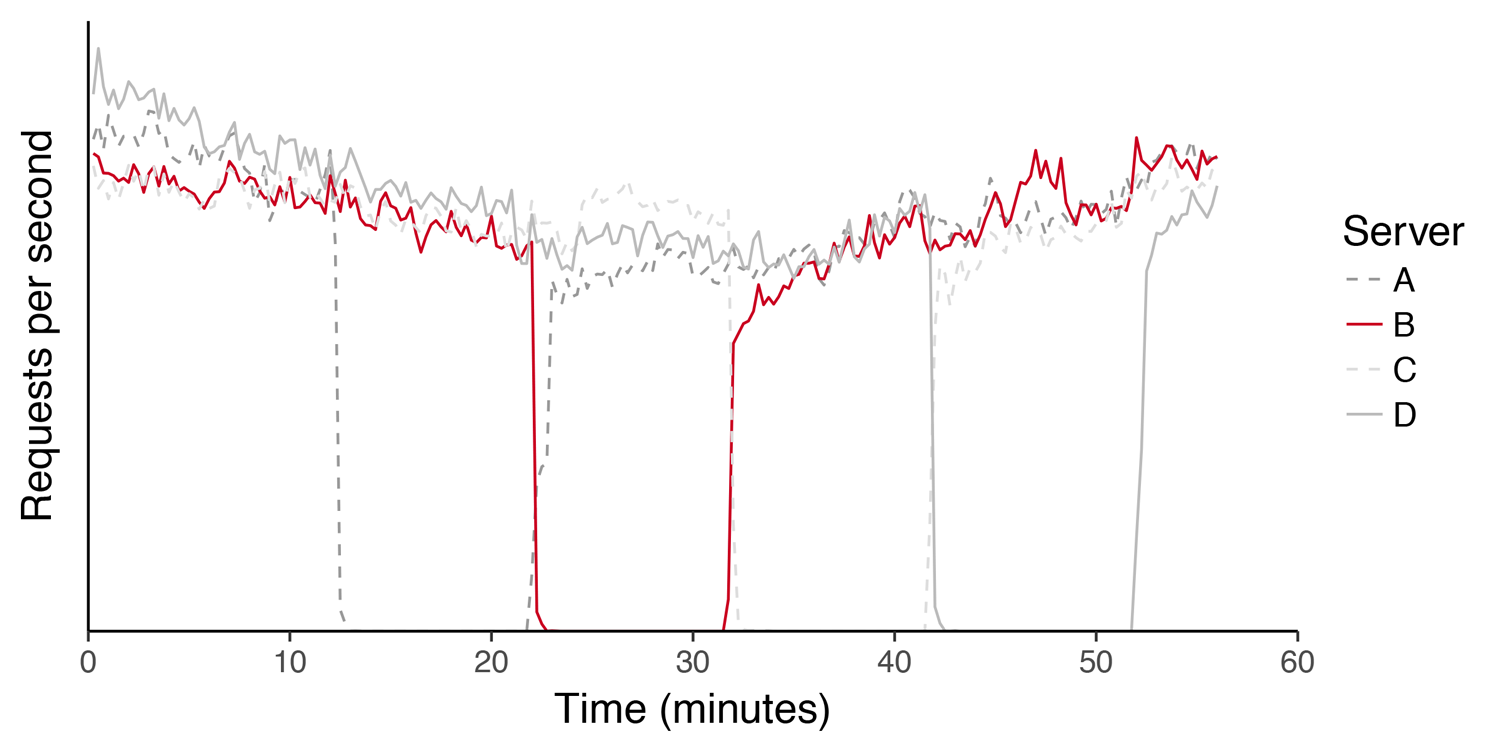
Fig. 14. Load graph (requests per second) on a cluster of servers during a sequential kernel upgrade. Hosts leave and return to "production" without affecting the service.
The introduction of Faild over the past 3 years has affected not only the work with traffic. By reducing the negative impact of the required work on the servers, Faild allowed us to deploy new software faster, without affecting customers, as well as speeding up our reaction to the detection of vulnerabilities.
Results
Fastly has reached a volume of millions of requests per second since the Faild solution was introduced in 2013. A significant contribution to this was made by “elastic” balancing, which reduces the cost of reconfiguring the network without loss to users.
Through the combination of ECMP, rewriting of ARP and manipulation with the core, this growth was supported by custom solutions, without acquiring anything more complicated than ordinary switches.
Source: https://habr.com/ru/post/322946/
All Articles