SharePoint 2013/2016 Monitoring: Key Performance Counters
Hello! My name is Lyubov Volkova, I am a systems architect in the business solutions development department. My main specialization is implementation, development of solutions, technical support for corporate SharePoint portals. Years of experience allows us to identify the main patterns that affect the performance of servers that are part of a typical farm.
The purpose of this post is to help the administrators of the corporate SharePoint portals in developing effective server maintenance plans. The text below summarizes the performance counters that we recommend for inclusion in the daily maintenance plans for the SharePoint 2013/2016 farm servers, as well as practical examples. You can use meter data to manually configure and analyze indicators of the express monitoring dashboard, as well as automate the receipt of notifications if the counters exceed threshold values during a period of time depending on the requirements and standards adopted by the organization.

')
There are several universal performance counters that should be monitored for any server system that is part of a SharePoint farm.
The amount of time the processor spends processing all command streams, except idle. This value is equal to the difference between 100% and the percentage of time that the processor spends on the idle thread. (An idle instruction flow takes up processor working time in the absence of other instruction flows.) This counter is the main indicator of processor utilization. It shows the average processor occupancy during the measurement interval.
It is necessary to monitor performance and maintain the load of all processors at a level no higher than 75%. At higher levels of workload, the system will not be able to cope with sudden bursts of activity. It will also avoid the domino effect when a failure of one component causes a failure of other components. For example, if you have three web servers, you need to make sure that the average CPU usage on all servers is less than 60% so that in case of failure of one of them, the other two processors can handle the additional load.
The average speed, in events per second, at which the processor receives and maintains hardware interrupts. This value does not include pending procedure calls, which are counted separately. This value is an indirect indicator of the activity of devices that form hardware interrupts, such as the system timer, mouse, disk drivers, data lines, network adapters and other peripheral devices. These devices usually interrupt the processor when it completes its work or when it is necessary to process a request. In this case, the normal execution of the command stream is suspended. The system timer typically interrupts the processor every 10 milliseconds, creating a 'background' of hardware interrupts. Therefore, this value represents the difference between the values of the last two samples divided by the duration of the sample interval.
Counter readings are processor dependent; A suitable starting value is 1,000 interrupts per second. A significant increase in the value of this counter without a corresponding increase in system activity indicates the presence of problems and may be associated with the operation of a network adapter, disk, or other equipment causing an interrupt.
The current length of the processor queue, as measured by the number of waiting threads. All processors use one common queue, in which threads are waiting to receive processor cycles. This counter does not include threads that are currently running. For CPU time, there is one queue even on computers with multiple processors. Therefore, if a computer has several processors, you need to divide this value by the number of processors that serve the load.
This counter reflects the current value and is not an average value over a certain time interval.
A continuous processor queue of less than five threads per processor is generally acceptable, and also depends on the workload. Values above the threshold typically indicate processor overload.
Shows the current cache size of the working set of the process (in bytes). A working set is a set of memory pages that were recently used by process threads. If the amount of free memory on the computer exceeds the threshold, unused pages are stored in the working set of the process event. When the amount of free memory falls below the threshold, the pages are removed from the working sets. If they are required, they will be transferred to the working set when resolving the RAM error, before being unloaded from the RAM.
This counter can indicate system-wide problems as well as problems associated with a specific process. A significant increase or decrease in the size of working sets leads to paging.
The recommended setting for the paging file is “RAM + 10”.
If deletion from the working sets occurs, you need to add the Process (*) \ Work Set counter to find out which processes are affected by the problem.
It is recommended to additionally compare the readings of this counter with the value of the “Memory \ Resident Bytes of the System Cache” counter to determine whether system-wide deletion of pages from working sets does not occur.
The readings of this counter must be analyzed together with the data of the CPU \% Processor Processor counter for the _Total object. If the load of all processors exceeds the threshold values, then the ASP.Net process load data will determine if this process is the source of the problem.
SharePoint processes that are recommended to include in monitoring:
Shows the current number of bytes allocated to a process that cannot be shared with other processes.
This counter can be used to detect memory leaks for processes.
For SharePoint processes, the value of this counter is compared with the cache size for these same processes to determine if there is a memory leak. The increase in the number of bytes of exclusive use for the process, accompanied by the same increase in its cache, indicates the correct behavior (memory leaks do not occur).
Shows the amount of virtual address space (in bytes) that the process is currently using.
It is used to determine if processes use a large amount of virtual memory.
The number of threads in this process that are currently active. Values above 2000 require increased attention from the system administrator, and 10,000 is a threshold value at which there can already be a noticeable decline in IIS performance, and as a result, the work of the corporate portal.
The speed of sending and receiving data through the network adapter. If this rate exceeds 40-50 percent of network bandwidth, additional clarification of the reasons may be required.
Average queue length for disk requests. Displays the number of disk requests waiting to be processed within a specified time interval. A normal queue is considered to be no more than 2 for a single disk. If there are more than two requests in the queue, then the disk is probably overloaded and does not have time to process incoming requests. To clarify exactly what operations the disk cannot cope with, you can use the counters “Average number of read requests” and “Average length of the write queue to disk”.
The average number of read requests that were queued for the corresponding disk during the measurement interval.
The average number of write requests that were queued for the corresponding disk during the measurement interval.
The speed at which data is transferred from this disk when performing read operations.
The speed at which data is transferred to this disk during write operations.
Based on the values of the counters, it can be concluded that the load on the disk system is minimal and is not a bottleneck of the system.
This counter shows the amount of physical memory available for allocation. If there is not enough memory, the page file will be used more intensively, and the number of page errors per second will increase. If the value of this counter is less than 2 GB on the web server, you need to kill the memory.
The percentage of committed memory (committed bytes) to the committed memory limit (committed limit). This value reflects the actual amount of available virtual memory. Please note that the limit of allocated memory can be changed if the paging file (page file) is increased. This value is a specific current value, and is not an average value over a certain time interval.
Threshold: 70% for warning, more than 90% is critical. At elevated values, it is enough to increase the amount of memory.
The counter shows the average number of page faults per second. Measured by the number of failed page reads per second. Page errors occur in the case when the process of requesting a page in memory occurs, and then the system cannot find it in the requested location. If the requested page is not found in memory, this error is called soft page fault . If the requested page needs to be restored from disk, this error is called a hard page fault .
Input pages / sec is the number of pages read from the disk when resolving links to pages that are not in memory at the time the link is processed. A page error occurs when a thread refers to a virtual memory page that is not in the working set of RAM. This counter also takes into account the paging (page exchange) performed by the system cache to access data requested by applications. This is an important source of information for identifying excessive load on memory and the resulting excessive paging. The recommended warning threshold is 1000.
The counter value shows how many reads per unit of time, regardless of the pages, were done while processing page breaks. This counter indicates that the working set of the process is too large for physical memory, and paging occurs with the disk. Displays only the number of reads, excluding the number of pages extracted for each operation. Large readings indicate a memory bottleneck. Excessive pumping can lead to slower response and instability.
Counters Input pages / sec and Read pages / sec should be considered together. The first one contains the number of pages read from the disk, and the second the number of read operations performed during swapping. These counters take into account Hard Page Faults - memory access operations, in which the page of data you are looking for is not in physical memory. Thus, if the Exchange Pages / sec, Reading pages / sec, Page Entry / sec are constantly at a high level, it can be assumed that the operating system is actively working with the paging file, which, in turn, indicates a lack of memory. Input of pages / sec. Value of this counter must be higher or equal to the value of Read pages / sec.
This counter shows the frequency of errors when searching for a page in the file system cache. This may be a software error if the page is found in memory, or a hardware error if the page is on disk.
Active use of the cache for read and write operations can greatly affect server performance. It is necessary to monitor the increase in the number of cache errors, which is indicated by a decrease in the value of Asynchronous fast reads / s or Forward Readings / s .
The speed of reading and writing pages to disk to resolve serious page failures. This value is the sum of the Input pages / sec and Page output / sec values. Counter readings are the main indicator of the types of failures that cause delays in the entire system. It shows the number of pages received to compensate for page failures in the file system cache. These pages are usually required by applications. The value of this counter must not exceed 10.
The size (in bytes) of the non-paged pool. A non-paged pool is a virtual memory area used for objects that cannot be written to disk and must remain in physical memory for the duration of its existence. This counter reflects only the current, not the average.
Requests for the allocation of space in a special system memory, where the components of the operating system request the space they need to function. The pages of a non-paged page pool cannot be uploaded to the paging file (page file) on the disk and remain in RAM for the entire period of their use. This counter reflects the current value, and is not an average value over a certain time interval.
Counter readings should not exceed the minimum of two values - 2x RAM and 128 GB.
If \ Memory \ Exchange pages / s, \ Memory \ Read pages / s, Memory \ Pages input / s are always at a high level, and \ Memory \ Cache errors / c on a low level, then we can assume that the operating system is active works with the page file, which, in turn, indicates a lack of memory. However, if \ Memory \ Cache Errors / s is also high, then, most likely, the situation is caused by active work with large files being mapped to memory. Usually it does not take much time.
Indicators of the average amount of physical memory is normal. Indications to increase its volume is not. The average percentage of the used physical memory is normal (65%), but approaches the threshold value of 70%.
Relatively high error rates are observed when accessing memory pages in combination with a small number of read operations performed during swapping. Counter reading Page input / sec is normal and well below the threshold value. The counter values Exchange pages / sec (15+) exceed the threshold value 10. It can be assumed that the system periodically actively uses the paging file. One of the most common reasons for this behavior of the system is uploading large volumes of files to the portal.
The percentage of paging file (page file) currently used.
Maximum use of the paging file (page file) in percent.
The server paging file, also known as the paging file, contains “virtual” memory addresses on the disk. Page errors occur when the process needs to be stopped and wait until the necessary “virtual” resources are copied from disk to memory. They will be more if the amount of physical memory is not enough.
Note that for SharePoint it is recommended to configure the paging file size to be 150% of the RAM. The absolute minimum should be the value of RAM + 1 MB.
Track the amount of physical memory available for allocation. If there is not enough memory, the page file will be used more intensively, and the number of page errors per second will increase.
The number of times the application has restarted during the lifetime of the web server. The value of this counter increases after each occurrence of the Application_OnEnd event (shutdown of the web application). Restarting an application can occur as a result of changes in the Web.config file, changes in assemblies in the \ Bin directory of the application, or a large number of changes to the web form pages. An unexpected increase in this value may be due to the fact that the shutdown of the web application occurred as a result of unforeseen circumstances. In this case, it is necessary to analyze the causes of the problems as soon as possible. The value of this counter should tend to zero.
The total number of requests rejected because the request queue was full. Rejection of requests is often performed due to lack of server resources to process them. This value corresponds to the number of HTTP error codes returned 503, meaning that the server is busy. Examples of the causes of resource deficiencies: a large number of requests to the web server, a large number of slow requests (non-optimized) to the DBMS, do not correctly work out the components of the solutions written by third-party developers. Thus, in order to identify the cause of the shortage of resources on the server and eliminate it, you need to carry a more detailed analysis of the web server using additional tools.
The MS SharePoint web application provides standard blocks for HTML pages that are displayed in the user's browser via HTTP and require prior data acquisition and processing (web parts, user controls, etc.). To prepare the final result of data processing, which is provided to the user on the corporate portal's web page, one or several requests to the database, file system, etc. may be required. This counter shows the number of requests waiting to be processed. The maximum default value for this counter is 5000. You can change this setting in the Machine.config file. The value of this counter should not exceed 70-75% of the threshold value, i.e. 3500-3750.
The number of restarts in the server workflow. The workflow can be restarted when an unexpected error occurs or during deliberate actions. The same reasons for restarting the workflow can be: high memory consumption by the application and CPU load, restarting is defined in the application pool settings. In the case of frequent workflow reloads, the response of the web resource, when the user accesses, will take a long time.
The value of this counter should tend to zero.
The last request waiting in the queue for processing in milliseconds. As the number of wait events increases, users will notice a decrease in performance when displaying web pages. As the number of wait events increases, users will notice a decrease in performance when pages are displayed.
The number of queries executed per second. Represents the current application bandwidth. At constant load, this number should remain in a certain range, prohibiting other server work (such as garbage collection, cache flush stream, external server facilities, etc.).
Data indicators of almost all ASP.Net counters tend to zero in combination with small values of the number of requests per second. You should pay attention to the high number of restarts of the web application (Application Restarts counter). It can be assumed that users periodically experience problems with the availability of a web resource, so the administrator of the corporate portal needs to find out and eliminate the causes of frequent failures in the operation of the web application.
Generation 0 garbage collection (# Gen 0 Collections) is the number of extraction of generation 0 objects (i.e. last added objects) by the garbage collector since the application started.
Generation 1 garbage collection (# Gen 1 Collections) is the number of generation 1 objects retrieved by the garbage collector since the application started.
Generation 2 garbage collection (# Gen 2 Collections) is the number of generation 2 objects retrieved by the garbage collector since the application started. This counter is incremented by 1 after trash collection for generation 2 is completed (also called full garbage collection).
When monitoring, it is necessary to pay attention to the ratio of “garbage collection for generation 0: garbage collection for generation 1: garbage collection for generation 2”, ensure that the number of garbage collection for generation 2 does not greatly exceed the number of collection fees for generation 0. The optimal ratio is 2
Displays the percentage of time spent collecting garbage from the last garbage collection cycle. This counter usually indicates the work done by the garbage collector to extract and compress memory on behalf of an application. This counter is updated only at the end of each garbage collection. This counter shows not the average, but the last observed value. In normal mode, the counter value should not exceed 5%.
The number of exceptions generated per second. This counter counts both processed and unhandled exceptions. It is assumed that exceptions occur only in rare cases and do not occur during the normal course of the program; This counter was introduced to signal potential performance problems in cases where the frequency of exception generation is too large (> 100). This counter does not provide averaging over time; it shows the ratio of the difference between the values observed in the last two measurements to the interval between measurements.
The value of this counter should tend to zero.
The readings of the counters from this group are considered in relation to a specific object instance, the corporate portal web application, for example, “SharePoint - 80”.
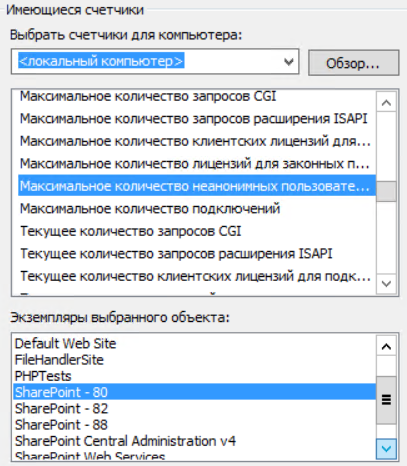
The number of connections to the web service that are currently installed. The higher the value, the greater the load on the SharePoint server.
ISAPI (Internet Server Application Programming Interface) is a set of interfaces provided by the MS IIS (Internet Information Services) web server for writing applications that interact with this server and expand its capabilities. ISAPI applications are dynamic link libraries (Dynamic Link Library, DLL) that interact directly with the IIS API. ISAPI applications are loaded and executed in the IIS address space, so the server does not need to create a new process for each HTTP request. Since Windows loads the dynamic link library once the first time the function is called in the DLL, the ISAPI application remains loaded and is not deleted until the web server is stopped / turned off (if ISAPI caching is enabled) or the application is not explicitly unloaded (if turned off).
The meter reading provides an indication of the frequency of ISAPI extension requests received by the web service.
The counter shows the average execution time of SQL queries. The return value should be as low as possible. The readings of this counter are significantly affected by the data on the load on the basic subsystems and their physical characteristics (memory, processor, network, disk devices). The readings of this meter are also affected:
The counter returns the number of currently running SQL queries. The value of the counter essentially depends on the specifics of the functionality implemented on the portal. The analysis of values must necessarily be carried out taking into account the specifics of processing the content: working with base lists and libraries, using groupings and filters in data representation, substitution fields, accessing lists with external data, processing requests to external data sources or processing lists with large numbers elements and more.
The counter returns the average execution time (in ms) of requests for web pages that were processed during data collection. Statistics includes data about the request for dynamic web pages, the construction of which is provided by ASP.Net.
The counter value indicates the number of current requests that are being processed. They can differ significantly in different periods and depend on the current number of calls to the SharePoint portal. The most important is the analysis of readings during peak hours in combination with indicators of the average execution of web page requests (Executing Time / Page Request) and data on the number of currently running SQL queries.
The percentage of pages that were rejected when they were requested. The return value should be as low as possible, because indicates that the pages were not requested from the cache and required the execution of a full cycle of the request for a web page on the server.
The counter value displays the number of incoming requests in the last second. Similar to Current Page Requests in relation to a strictly defined time interval - 1s.
The counter returns the number of threads currently running in the SharePoint code. Indicators depend on many factors: the processor and its characteristics, indicators on the basic subsystems (memory, processor, network, disk devices), the current load on the portal. The initiation of additional streams can be initiated programmatically in the code as part of solutions for the SharePoint platform.
Based on the average readings from the SharePoint Foundation counters, it can be assumed that during the operation of the corporate portal, there is no high load associated with user access to the web server.
Microsoft SQL Server uses calls to the system I / O functions of the Microsoft Windows Server operating system to perform disk read and write operations. SQL Server determines when and how to perform disk I / O operations, but the basic I / O operations are performed by the Windows operating system.
The following describes the minimum set of counters that we recommend monitoring in daily service plans.
The time in seconds spent on average per disk read operation. Shows the average time to complete a disk read operation. Basic indicators of this counter should not exceed 15 ms. If the reading time on average exceeds this value for quite a long time, this may indicate that there are problems in the I / O device.
The average recording time on a disk is the time in seconds spent on average per one operation of writing data to a disk. Basic indicators of this counter should not exceed 15 ms.
The Counters “Average Disk Read Time” and “Average Disk Write Time” measure wait times directly in the software add-on where the storage device disks are accessible to the operating system. They allow you to accurately measure how much time the disks and hardware environment spent on servicing I / O requests, regardless of what hardware and software were involved.
For OLTP systems, the average value should be less than 15 ms with valid peaks up to 25 ms. The less time it takes to read or write data, the faster the system will function.
Controlling an instance of Microsoft SQL Server allows you to determine whether CPU utilization levels are in standard ranges. A consistently high level of CPU usage may indicate the need for a CPU upgrade or the need to add multiple processors. Optimizing application performance can reduce CPU utilization. The processor system is most loaded with operations:
Below is a description of meters that we recommend monitoring in daily service plans.
SQL compilations done in seconds. Specifies the number of times the code compilation path was entered. Includes compilation operations caused by instruction-level recompilation in SQL Server. The SQL Server SQL Statistics in Microsoft SQL Server object provides counters to monitor the compilation and types of queries sent to an instance of SQL Server. Monitoring the number of compilations and re-compilations of queries and the number of batches received by an instance of SQL Server gives an idea of how quickly SQL Server responds to users and how efficiently the query optimizer processes them. Compilation takes a significant amount of time in processing a request. To save on compilation costs, the Database Engine stores the compiled query plan in the query cache. The purpose of caching is to reduce the number of compilations by storing already compiled queries for further reuse, eliminating the need to recompile similar queries that may come later. However, each unique query must be compiled at least once. Compiling queries can be caused by the following factors:
The counter indicates the number of streams received from the operating system schedulers (not from the SQL schedulers) to perform operations for other threads in the idle state. «Batch Requests/sec» , 5000 . .
. , .
Workfiles — , SQL Server. SQL Server Workfiles . Workfiles , SQL Server , . Workfiles Created/sec Batch Requests/sec 20%. Workfiles , .
, . SQL Server , . SQL Server , . , , SQL Server, .
, :
, SQL Server , .
SQL Server , , , , . SQL Server , , . , Memory: Available Bytes 100...50 MB Windows (trimming) , , . Min Server Memory Max Server Memory.
SQL Server, SQL, SharePoint.
b6s SQL 2147483647 Mb, SQL Server – 96 GB.
Max Server Memory ( SQL Server) :
SQL = TotalPhyMem — ( NumOfSQLThreads * ThreadStackSize ) — (1GB * ( NumOfCores /4)) — RAMOSReserve d — RAMForOtherApps , :

You can get information about the processors and the amount of physical memory on the server using the following script:
For b6s, the calculations will be as follows:
SQL The maximum size of the RAM = 98276 Mb - (480 * 2 Mb) - (1GB * ROUNDUP (32/4)) - 11793 Mb - 8000 Mb = 98276 Mb - 960 Mb - 8192 Mb - 11793 Mb - 8000 Mb = 69331 Mb.
Thus, the size of the buffer pool (with the corresponding value of “Max Server Memory”) can grow to 69,331 MB, thereby, without affecting the operation of the operating system.
The following is a description of counters for monitoring memory used by SQL Server, monitoring of which is recommended to be included in daily monitoring.
The meter data provides information about the ideal amount of memory required by the server.
The counter data provides information about the amount of memory allocated to the server by the memory manager. If Total Server Memory is less than Target Server Memory is a sign of low memory.
The proportion of pages found in the buffer cache without reading from the disk. This value is defined as the total number of hits in the cache divided by the number of refine cache requests for the last several thousand page access operations. After a long period, this ratio changes very little. Since reading from the cache is much faster than from disk, you should strive for the highest value of this indicator.
Specifies the average lifetime of pages in the buffer pool. The threshold is at least 300 seconds.
Indicates the total number of processes awaiting the working memory memory.
Values are within the norm, but it should be noted that Total Server Memory is less than Target Server Memory. This is usually a sign of low memory, but in this case the situation is different, as SQL Server requests memory as needed. If the memory requirements are minor, then Total Server Memory will remain much lower than Target Server Memory. SQL Server Memory Requirements for MS SharePoint Foundation 2013 - 8-16 GB for use in a production environment in a single-server farm ( more details here ). Thus, at this time, an increase in memory on the database server is not required.
If you get to the end of the text, it means that you are really digging deep into the administration theme of SharePoint Server. You may have questions that are beyond the scope of this text. Feel free to ask them in the comments.
The purpose of this post is to help the administrators of the corporate SharePoint portals in developing effective server maintenance plans. The text below summarizes the performance counters that we recommend for inclusion in the daily maintenance plans for the SharePoint 2013/2016 farm servers, as well as practical examples. You can use meter data to manually configure and analyze indicators of the express monitoring dashboard, as well as automate the receipt of notifications if the counters exceed threshold values during a period of time depending on the requirements and standards adopted by the organization.
')
System counters
There are several universal performance counters that should be monitored for any server system that is part of a SharePoint farm.
CPU
% Processor Time (_Total) \% Processor Time
The amount of time the processor spends processing all command streams, except idle. This value is equal to the difference between 100% and the percentage of time that the processor spends on the idle thread. (An idle instruction flow takes up processor working time in the absence of other instruction flows.) This counter is the main indicator of processor utilization. It shows the average processor occupancy during the measurement interval.
It is necessary to monitor performance and maintain the load of all processors at a level no higher than 75%. At higher levels of workload, the system will not be able to cope with sudden bursts of activity. It will also avoid the domino effect when a failure of one component causes a failure of other components. For example, if you have three web servers, you need to make sure that the average CPU usage on all servers is less than 60% so that in case of failure of one of them, the other two processors can handle the additional load.
Interrupts / sec (Interrupts / sec)
The average speed, in events per second, at which the processor receives and maintains hardware interrupts. This value does not include pending procedure calls, which are counted separately. This value is an indirect indicator of the activity of devices that form hardware interrupts, such as the system timer, mouse, disk drivers, data lines, network adapters and other peripheral devices. These devices usually interrupt the processor when it completes its work or when it is necessary to process a request. In this case, the normal execution of the command stream is suspended. The system timer typically interrupts the processor every 10 milliseconds, creating a 'background' of hardware interrupts. Therefore, this value represents the difference between the values of the last two samples divided by the duration of the sample interval.
Counter readings are processor dependent; A suitable starting value is 1,000 interrupts per second. A significant increase in the value of this counter without a corresponding increase in system activity indicates the presence of problems and may be associated with the operation of a network adapter, disk, or other equipment causing an interrupt.
System
Processor Queue Length
The current length of the processor queue, as measured by the number of waiting threads. All processors use one common queue, in which threads are waiting to receive processor cycles. This counter does not include threads that are currently running. For CPU time, there is one queue even on computers with multiple processors. Therefore, if a computer has several processors, you need to divide this value by the number of processors that serve the load.
This counter reflects the current value and is not an average value over a certain time interval.
A continuous processor queue of less than five threads per processor is generally acceptable, and also depends on the workload. Values above the threshold typically indicate processor overload.
Process
Working Set for _Total instance
Shows the current cache size of the working set of the process (in bytes). A working set is a set of memory pages that were recently used by process threads. If the amount of free memory on the computer exceeds the threshold, unused pages are stored in the working set of the process event. When the amount of free memory falls below the threshold, the pages are removed from the working sets. If they are required, they will be transferred to the working set when resolving the RAM error, before being unloaded from the RAM.
This counter can indicate system-wide problems as well as problems associated with a specific process. A significant increase or decrease in the size of working sets leads to paging.
The recommended setting for the paging file is “RAM + 10”.
If deletion from the working sets occurs, you need to add the Process (*) \ Work Set counter to find out which processes are affected by the problem.
It is recommended to additionally compare the readings of this counter with the value of the “Memory \ Resident Bytes of the System Cache” counter to determine whether system-wide deletion of pages from working sets does not occur.
% Processor Time (% Processor Time) for SharePoint Processes
The readings of this counter must be analyzed together with the data of the CPU \% Processor Processor counter for the _Total object. If the load of all processors exceeds the threshold values, then the ASP.Net process load data will determine if this process is the source of the problem.
SharePoint processes that are recommended to include in monitoring:
- w3wp;
- mssearch;
- noderunner;
- miiserver.
Private Bytes for SharePoint Processes
Shows the current number of bytes allocated to a process that cannot be shared with other processes.
This counter can be used to detect memory leaks for processes.
For SharePoint processes, the value of this counter is compared with the cache size for these same processes to determine if there is a memory leak. The increase in the number of bytes of exclusive use for the process, accompanied by the same increase in its cache, indicates the correct behavior (memory leaks do not occur).
Virtual Bytes for SharePoint Processes
Shows the amount of virtual address space (in bytes) that the process is currently using.
It is used to determine if processes use a large amount of virtual memory.
Thread count (Handle Count) for w3wp process
The number of threads in this process that are currently active. Values above 2000 require increased attention from the system administrator, and 10,000 is a threshold value at which there can already be a noticeable decline in IIS performance, and as a result, the work of the corporate portal.
Network adapter
Bytes Total / sec (Bytes Total / Sec)
The speed of sending and receiving data through the network adapter. If this rate exceeds 40-50 percent of network bandwidth, additional clarification of the reasons may be required.
Logical drive (Disk)
Average disk queue length (Avg. Disk Queue Length)
Average queue length for disk requests. Displays the number of disk requests waiting to be processed within a specified time interval. A normal queue is considered to be no more than 2 for a single disk. If there are more than two requests in the queue, then the disk is probably overloaded and does not have time to process incoming requests. To clarify exactly what operations the disk cannot cope with, you can use the counters “Average number of read requests” and “Average length of the write queue to disk”.
Average disk read queue length (Avg. Disk Read Queue Length)
The average number of read requests that were queued for the corresponding disk during the measurement interval.
Avg. Disk Write Queue Length (Avg. Disk Write Queue Length)
The average number of write requests that were queued for the corresponding disk during the measurement interval.
Disk read speed (bytes / sec) (Disk Reads / sec)
The speed at which data is transferred from this disk when performing read operations.
Disk Write Speed (Bytes / sec) (Disk Writes / sec)
The speed at which data is transferred to this disk during write operations.
An example of meter reading on the disk subsystem
| Average disk queue length | The average length of the disk read queue | The average length of the write queue to disk | Disk read speed (bytes / s) | Disk write speed (byte / s) |
|---|---|---|---|---|
| 0.015 | 0,004 | 0.011 | 0.723 | 9,578 |
Based on the values of the counters, it can be concluded that the load on the disk system is minimal and is not a bottleneck of the system.
Memory
Available MB (Available Mbytes)
This counter shows the amount of physical memory available for allocation. If there is not enough memory, the page file will be used more intensively, and the number of page errors per second will increase. If the value of this counter is less than 2 GB on the web server, you need to kill the memory.
% utilization of allocated memory (% committed bytes in use)
The percentage of committed memory (committed bytes) to the committed memory limit (committed limit). This value reflects the actual amount of available virtual memory. Please note that the limit of allocated memory can be changed if the paging file (page file) is increased. This value is a specific current value, and is not an average value over a certain time interval.
Threshold: 70% for warning, more than 90% is critical. At elevated values, it is enough to increase the amount of memory.
Page errors / sec (Page Faults / sec)
The counter shows the average number of page faults per second. Measured by the number of failed page reads per second. Page errors occur in the case when the process of requesting a page in memory occurs, and then the system cannot find it in the requested location. If the requested page is not found in memory, this error is called soft page fault . If the requested page needs to be restored from disk, this error is called a hard page fault .
Input Pages / sec (Pages Input / sec)
Input pages / sec is the number of pages read from the disk when resolving links to pages that are not in memory at the time the link is processed. A page error occurs when a thread refers to a virtual memory page that is not in the working set of RAM. This counter also takes into account the paging (page exchange) performed by the system cache to access data requested by applications. This is an important source of information for identifying excessive load on memory and the resulting excessive paging. The recommended warning threshold is 1000.
Read pages / sec (Page Reads / sec)
The counter value shows how many reads per unit of time, regardless of the pages, were done while processing page breaks. This counter indicates that the working set of the process is too large for physical memory, and paging occurs with the disk. Displays only the number of reads, excluding the number of pages extracted for each operation. Large readings indicate a memory bottleneck. Excessive pumping can lead to slower response and instability.
Counters Input pages / sec and Read pages / sec should be considered together. The first one contains the number of pages read from the disk, and the second the number of read operations performed during swapping. These counters take into account Hard Page Faults - memory access operations, in which the page of data you are looking for is not in physical memory. Thus, if the Exchange Pages / sec, Reading pages / sec, Page Entry / sec are constantly at a high level, it can be assumed that the operating system is actively working with the paging file, which, in turn, indicates a lack of memory. Input of pages / sec. Value of this counter must be higher or equal to the value of Read pages / sec.
Cache Faults / Cache Errors
This counter shows the frequency of errors when searching for a page in the file system cache. This may be a software error if the page is found in memory, or a hardware error if the page is on disk.
Active use of the cache for read and write operations can greatly affect server performance. It is necessary to monitor the increase in the number of cache errors, which is indicated by a decrease in the value of Asynchronous fast reads / s or Forward Readings / s .
Exchange pages / sec (Pages / sec)
The speed of reading and writing pages to disk to resolve serious page failures. This value is the sum of the Input pages / sec and Page output / sec values. Counter readings are the main indicator of the types of failures that cause delays in the entire system. It shows the number of pages received to compensate for page failures in the file system cache. These pages are usually required by applications. The value of this counter must not exceed 10.
Byte in non-paged pool (Pool Nonpaged Bytes)
The size (in bytes) of the non-paged pool. A non-paged pool is a virtual memory area used for objects that cannot be written to disk and must remain in physical memory for the duration of its existence. This counter reflects only the current, not the average.
Requests for the allocation of space in a special system memory, where the components of the operating system request the space they need to function. The pages of a non-paged page pool cannot be uploaded to the paging file (page file) on the disk and remain in RAM for the entire period of their use. This counter reflects the current value, and is not an average value over a certain time interval.
Counter readings should not exceed the minimum of two values - 2x RAM and 128 GB.
General recommendations for the analysis of indicators of memory counters
If \ Memory \ Exchange pages / s, \ Memory \ Read pages / s, Memory \ Pages input / s are always at a high level, and \ Memory \ Cache errors / c on a low level, then we can assume that the operating system is active works with the page file, which, in turn, indicates a lack of memory. However, if \ Memory \ Cache Errors / s is also high, then, most likely, the situation is caused by active work with large files being mapped to memory. Usually it does not take much time.
Example of indications of memory counters
| MB available | % used assignment of selected of memory | Page errors /with | Entering pages /with | Reading pages /with | Page Exchange /with | Byte in un- load- eme pool |
|---|---|---|---|---|---|---|
| 6312,758 | 65 | 605,378 | 15,936 | 1,105 | 15.995 | 115352406 |
Indicators of the average amount of physical memory is normal. Indications to increase its volume is not. The average percentage of the used physical memory is normal (65%), but approaches the threshold value of 70%.
Relatively high error rates are observed when accessing memory pages in combination with a small number of read operations performed during swapping. Counter reading Page input / sec is normal and well below the threshold value. The counter values Exchange pages / sec (15+) exceed the threshold value 10. It can be assumed that the system periodically actively uses the paging file. One of the most common reasons for this behavior of the system is uploading large volumes of files to the portal.
Page file
% of use (% Used)
The percentage of paging file (page file) currently used.
% use (peak) (% Used Peak)
Maximum use of the paging file (page file) in percent.
The server paging file, also known as the paging file, contains “virtual” memory addresses on the disk. Page errors occur when the process needs to be stopped and wait until the necessary “virtual” resources are copied from disk to memory. They will be more if the amount of physical memory is not enough.
Note that for SharePoint it is recommended to configure the paging file size to be 150% of the RAM. The absolute minimum should be the value of RAM + 1 MB.
Track the amount of physical memory available for allocation. If there is not enough memory, the page file will be used more intensively, and the number of page errors per second will increase.
Performance counters on SharePoint servers
ASP.Net and ASP.Net Application
ASP.Net. Application Restarts
The number of times the application has restarted during the lifetime of the web server. The value of this counter increases after each occurrence of the Application_OnEnd event (shutdown of the web application). Restarting an application can occur as a result of changes in the Web.config file, changes in assemblies in the \ Bin directory of the application, or a large number of changes to the web form pages. An unexpected increase in this value may be due to the fact that the shutdown of the web application occurred as a result of unforeseen circumstances. In this case, it is necessary to analyze the causes of the problems as soon as possible. The value of this counter should tend to zero.
ASP.Net. Requests Rejected
The total number of requests rejected because the request queue was full. Rejection of requests is often performed due to lack of server resources to process them. This value corresponds to the number of HTTP error codes returned 503, meaning that the server is busy. Examples of the causes of resource deficiencies: a large number of requests to the web server, a large number of slow requests (non-optimized) to the DBMS, do not correctly work out the components of the solutions written by third-party developers. Thus, in order to identify the cause of the shortage of resources on the server and eliminate it, you need to carry a more detailed analysis of the web server using additional tools.
ASP.Net. Requests Queued
The MS SharePoint web application provides standard blocks for HTML pages that are displayed in the user's browser via HTTP and require prior data acquisition and processing (web parts, user controls, etc.). To prepare the final result of data processing, which is provided to the user on the corporate portal's web page, one or several requests to the database, file system, etc. may be required. This counter shows the number of requests waiting to be processed. The maximum default value for this counter is 5000. You can change this setting in the Machine.config file. The value of this counter should not exceed 70-75% of the threshold value, i.e. 3500-3750.
ASP.Net. Worker Process Restarts
The number of restarts in the server workflow. The workflow can be restarted when an unexpected error occurs or during deliberate actions. The same reasons for restarting the workflow can be: high memory consumption by the application and CPU load, restarting is defined in the application pool settings. In the case of frequent workflow reloads, the response of the web resource, when the user accesses, will take a long time.
The value of this counter should tend to zero.
ASP.Net. Request Wait Time
The last request waiting in the queue for processing in milliseconds. As the number of wait events increases, users will notice a decrease in performance when displaying web pages. As the number of wait events increases, users will notice a decrease in performance when pages are displayed.
ASP.Net application. Requests / Sec (Requests / Sec)
The number of queries executed per second. Represents the current application bandwidth. At constant load, this number should remain in a certain range, prohibiting other server work (such as garbage collection, cache flush stream, external server facilities, etc.).
Example of ASP.Net meter readings and ASP.Net Application
| Application restarts | Requests Rejected | Requests Queued | Worker Process Restarts | Request Wait Time | Requests / Sec |
|---|---|---|---|---|---|
| 2.175 | 0 | 0 | 0 | 0 | 0.153 |
Data indicators of almost all ASP.Net counters tend to zero in combination with small values of the number of requests per second. You should pay attention to the high number of restarts of the web application (Application Restarts counter). It can be assumed that users periodically experience problems with the availability of a web resource, so the administrator of the corporate portal needs to find out and eliminate the causes of frequent failures in the operation of the web application.
Memory CLR .Net (Memory CLR .Net)
Garbage fees
Generation 0 garbage collection (# Gen 0 Collections) is the number of extraction of generation 0 objects (i.e. last added objects) by the garbage collector since the application started.
Generation 1 garbage collection (# Gen 1 Collections) is the number of generation 1 objects retrieved by the garbage collector since the application started.
Generation 2 garbage collection (# Gen 2 Collections) is the number of generation 2 objects retrieved by the garbage collector since the application started. This counter is incremented by 1 after trash collection for generation 2 is completed (also called full garbage collection).
When monitoring, it is necessary to pay attention to the ratio of “garbage collection for generation 0: garbage collection for generation 1: garbage collection for generation 2”, ensure that the number of garbage collection for generation 2 does not greatly exceed the number of collection fees for generation 0. The optimal ratio is 2
% time in GC (% Time in GC)
Displays the percentage of time spent collecting garbage from the last garbage collection cycle. This counter usually indicates the work done by the garbage collector to extract and compress memory on behalf of an application. This counter is updated only at the end of each garbage collection. This counter shows not the average, but the last observed value. In normal mode, the counter value should not exceed 5%.
CLR.Net Exceptions (Microsoft .NET CLR Exceptions)
The number of exceptions.sec (Exceps thrown / sec)
The number of exceptions generated per second. This counter counts both processed and unhandled exceptions. It is assumed that exceptions occur only in rare cases and do not occur during the normal course of the program; This counter was introduced to signal potential performance problems in cases where the frequency of exception generation is too large (> 100). This counter does not provide averaging over time; it shows the ratio of the difference between the values observed in the last two measurements to the interval between measurements.
The value of this counter should tend to zero.
Web Service
The readings of the counters from this group are considered in relation to a specific object instance, the corporate portal web application, for example, “SharePoint - 80”.
Number of current connections
The number of connections to the web service that are currently installed. The higher the value, the greater the load on the SharePoint server.
Number of ISAPI Extension Requests Per Second (ISAPI Extension Requests / sec)
ISAPI (Internet Server Application Programming Interface) is a set of interfaces provided by the MS IIS (Internet Information Services) web server for writing applications that interact with this server and expand its capabilities. ISAPI applications are dynamic link libraries (Dynamic Link Library, DLL) that interact directly with the IIS API. ISAPI applications are loaded and executed in the IIS address space, so the server does not need to create a new process for each HTTP request. Since Windows loads the dynamic link library once the first time the function is called in the DLL, the ISAPI application remains loaded and is not deleted until the web server is stopped / turned off (if ISAPI caching is enabled) or the application is not explicitly unloaded (if turned off).
The meter reading provides an indication of the frequency of ISAPI extension requests received by the web service.
SharePoint Foundation Counters
SQL Query Executing time
The counter shows the average execution time of SQL queries. The return value should be as low as possible. The readings of this counter are significantly affected by the data on the load on the basic subsystems and their physical characteristics (memory, processor, network, disk devices). The readings of this meter are also affected:
- Non-optimized execution plans for T-sql queries that may be involved in the solution code;
- Calling the stored procedures with the help of which various activities can be generated for the portal user;
- The degree of index performance optimization.
Executing SQL Queries
The counter returns the number of currently running SQL queries. The value of the counter essentially depends on the specifics of the functionality implemented on the portal. The analysis of values must necessarily be carried out taking into account the specifics of processing the content: working with base lists and libraries, using groupings and filters in data representation, substitution fields, accessing lists with external data, processing requests to external data sources or processing lists with large numbers elements and more.
Executing Time / Page Request
The counter returns the average execution time (in ms) of requests for web pages that were processed during data collection. Statistics includes data about the request for dynamic web pages, the construction of which is provided by ASP.Net.
Current Page Requests
The counter value indicates the number of current requests that are being processed. They can differ significantly in different periods and depend on the current number of calls to the SharePoint portal. The most important is the analysis of readings during peak hours in combination with indicators of the average execution of web page requests (Executing Time / Page Request) and data on the number of currently running SQL queries.
Reject Page Requests Rate
The percentage of pages that were rejected when they were requested. The return value should be as low as possible, because indicates that the pages were not requested from the cache and required the execution of a full cycle of the request for a web page on the server.
Incoming Page Requests Rate
The counter value displays the number of incoming requests in the last second. Similar to Current Page Requests in relation to a strictly defined time interval - 1s.
Active threads
The counter returns the number of threads currently running in the SharePoint code. Indicators depend on many factors: the processor and its characteristics, indicators on the basic subsystems (memory, processor, network, disk devices), the current load on the portal. The initiation of additional streams can be initiated programmatically in the code as part of solutions for the SharePoint platform.
Example of SharePoint Foundation Counters
| SQL Query Executing time | Executing SQL Queries | Executing Time / Page Requests | Current Page Request | Reject Page Requests Rate | Incoming Page Requests Rate | IActive Threads |
|---|---|---|---|---|---|---|
| 0.048 | 0.051 | 0.197 | 1,581 | 0 | 0.396 | 1,595 |
Based on the average readings from the SharePoint Foundation counters, it can be assumed that during the operation of the corporate portal, there is no high load associated with user access to the web server.
SQL Server Monitoring
Disk Subsystem Monitoring
Microsoft SQL Server uses calls to the system I / O functions of the Microsoft Windows Server operating system to perform disk read and write operations. SQL Server determines when and how to perform disk I / O operations, but the basic I / O operations are performed by the Windows operating system.
The following describes the minimum set of counters that we recommend monitoring in daily service plans.
Physical Disk \ Average Disk Read Time (Physical Disk \ Avg. Disk sec / read)
The time in seconds spent on average per disk read operation. Shows the average time to complete a disk read operation. Basic indicators of this counter should not exceed 15 ms. If the reading time on average exceeds this value for quite a long time, this may indicate that there are problems in the I / O device.
Physical Disk \ Average Disk Write Time (Physical Disk \ Avg. Disk sec / write)
The average recording time on a disk is the time in seconds spent on average per one operation of writing data to a disk. Basic indicators of this counter should not exceed 15 ms.
The Counters “Average Disk Read Time” and “Average Disk Write Time” measure wait times directly in the software add-on where the storage device disks are accessible to the operating system. They allow you to accurately measure how much time the disks and hardware environment spent on servicing I / O requests, regardless of what hardware and software were involved.
For OLTP systems, the average value should be less than 15 ms with valid peaks up to 25 ms. The less time it takes to read or write data, the faster the system will function.
CPU Control
Controlling an instance of Microsoft SQL Server allows you to determine whether CPU utilization levels are in standard ranges. A consistently high level of CPU usage may indicate the need for a CPU upgrade or the need to add multiple processors. Optimizing application performance can reduce CPU utilization. The processor system is most loaded with operations:
- compiling and recompilation of execution plans;
- sorting;
- hashing.
Below is a description of meters that we recommend monitoring in daily service plans.
<SQL Server Instance> SQL Statistics \ SQL Compilations / sec
SQL compilations done in seconds. Specifies the number of times the code compilation path was entered. Includes compilation operations caused by instruction-level recompilation in SQL Server. The SQL Server SQL Statistics in Microsoft SQL Server object provides counters to monitor the compilation and types of queries sent to an instance of SQL Server. Monitoring the number of compilations and re-compilations of queries and the number of batches received by an instance of SQL Server gives an idea of how quickly SQL Server responds to users and how efficiently the query optimizer processes them. Compilation takes a significant amount of time in processing a request. To save on compilation costs, the Database Engine stores the compiled query plan in the query cache. The purpose of caching is to reduce the number of compilations by storing already compiled queries for further reuse, eliminating the need to recompile similar queries that may come later. However, each unique query must be compiled at least once. Compiling queries can be caused by the following factors:
- Changes to the schema, including basic changes (adding columns or indexes to a table) or a statistical diagram (inserting or deleting a significant number of rows in the table);
- Environment change (SET instruction). Changes to session parameters (for example, recompiling a query may result in the ANSI_PADDING or ANSI_NULLS clause).
<SQL Server Instance> SQL Statistics \ Batch Requests / sec
The counter indicates the number of streams received from the operating system schedulers (not from the SQL schedulers) to perform operations for other threads in the idle state. «Batch Requests/sec» , 5000 . .
< SQL Server>SQL Statistics\SQL ReCompilations/sec
. , .
< SQL Server>Access Methods\Workfiles Created/sec. Workfiles
Workfiles — , SQL Server. SQL Server Workfiles . Workfiles , SQL Server , . Workfiles Created/sec Batch Requests/sec 20%. Workfiles , .
\ (Processor\Processor Queue Length)
, . SQL Server , . SQL Server , . , , SQL Server, .
| Batch Requests /sec | SQL Compilations /sec | SQL ReCompilations /sec | Workfiles Created /sec | Processor Queue Length |
|---|---|---|---|---|
| 19,998 | 0,675 | 0,006 | 1,267 | 0,151 |
, :
- SQL Compilations/sec Batch Requests/sec
0,6/19 = 0.03
, 3% . , . SQL Compilations/sec 10% Batch Requests/sec. . - SQL ReCompilations/sec SQL Compilations/sec
0,006/0,6 = 0.01
, 1% . SQL Recompilations/sec 10% SQL Compilations/sec. . - Workfiles Created/sec Batch Requests/sec
1/19 = 0.05
.
| Batch Requests/sec | SQL Compilations/sec Batch Requests/sec | SQL ReCompilations/sec SQL Compilations/sec | Workfiles Created/sec Batch Requests/sec |
|---|---|---|---|
| 0,034 | 0.01 | 0.06 | |
| 0.1 | 0.1 | 0.2 | |
| Yes | Yes | Yes |
, SQL Server , .
SQL Server , , , , . SQL Server , , . , Memory: Available Bytes 100...50 MB Windows (trimming) , , . Min Server Memory Max Server Memory.
SQL Server, SQL, SharePoint.
b6s SQL 2147483647 Mb, SQL Server – 96 GB.
Max Server Memory ( SQL Server) :
SQL = TotalPhyMem — ( NumOfSQLThreads * ThreadStackSize ) — (1GB * ( NumOfCores /4)) — RAMOSReserve d — RAMForOtherApps , :
- TotalPhyMem – .
- NumOfCores – - .
- NumOfSQLThreads – - , . - 4 NumOfSQLThreads 256. - 4 : NumOfSQLThreads = 256 + (NumOfCores- 4) * 8.
- ThreadStackSize = 2 x64. IA64 ThreadStackSize=4.
- RAMOSReserved – . 20% TotalPhyMem 15 12,5% .
- RAMForOtherApps – SQL- .
You can get information about the processors and the amount of physical memory on the server using the following script:
SELECT cpu_count AS [Logical CPU Count] , hyperthread_ratio AS [Hyperthread Ratio] , cpu_count / hyperthread_ratio AS [Physical CPU Count] , osi.physical_memory_kb / 1024 AS [Physical Memory (MB)] , sqlserver_start_time FROM sys.dm_os_sys_info as osi; For b6s, the calculations will be as follows:
- TotalPhyMem = 98276 MB.
- NumOfCores = 32.
- NumOfSQLThreads = 256 + ( 32-4 ) * 8 = 480.
- ThreadStackSize = 2 MB.
- RAMOSReserve d = 12.5% * 98276 MB = 11793 MB.
- RAMForOtherApps - Customer must determine this value by himself. In the current calculations, we assume a value of 8,000 MB per second instance of SQL.
SQL The maximum size of the RAM = 98276 Mb - (480 * 2 Mb) - (1GB * ROUNDUP (32/4)) - 11793 Mb - 8000 Mb = 98276 Mb - 960 Mb - 8192 Mb - 11793 Mb - 8000 Mb = 69331 Mb.
Thus, the size of the buffer pool (with the corresponding value of “Max Server Memory”) can grow to 69,331 MB, thereby, without affecting the operation of the operating system.
The following is a description of counters for monitoring memory used by SQL Server, monitoring of which is recommended to be included in daily monitoring.
<SQL Server Instance> Memory Node \ Target Server Memory
The meter data provides information about the ideal amount of memory required by the server.
<SQL Server Instance> Memory Node \ Total Server Memory
The counter data provides information about the amount of memory allocated to the server by the memory manager. If Total Server Memory is less than Target Server Memory is a sign of low memory.
<SQL Server instance> Buffer Manager \ Buffer cache hit ratio
The proportion of pages found in the buffer cache without reading from the disk. This value is defined as the total number of hits in the cache divided by the number of refine cache requests for the last several thousand page access operations. After a long period, this ratio changes very little. Since reading from the cache is much faster than from disk, you should strive for the highest value of this indicator.
<SQL Server Instance> Buffer Manager \ Page Life Expectancy
Specifies the average lifetime of pages in the buffer pool. The threshold is at least 300 seconds.
<SQL Server Instance> Memory Manager \ Memory Grants Pending
Indicates the total number of processes awaiting the working memory memory.
Example of indications of memory usage monitoring counters
| Target Server Memory (KiV) | Total Server Memory (KiV) | Buffer cache hit ratio | Page Life Expectancy | Lazy writes / sec | Memory Grants Pending |
|---|---|---|---|---|---|
| 5312958 | 3683571 | 99.92% | 9,905,712 | 10,739 | 0,018 |
Values are within the norm, but it should be noted that Total Server Memory is less than Target Server Memory. This is usually a sign of low memory, but in this case the situation is different, as SQL Server requests memory as needed. If the memory requirements are minor, then Total Server Memory will remain much lower than Target Server Memory. SQL Server Memory Requirements for MS SharePoint Foundation 2013 - 8-16 GB for use in a production environment in a single-server farm ( more details here ). Thus, at this time, an increase in memory on the database server is not required.
If you get to the end of the text, it means that you are really digging deep into the administration theme of SharePoint Server. You may have questions that are beyond the scope of this text. Feel free to ask them in the comments.
Source: https://habr.com/ru/post/322940/
All Articles