How we built the infrastructure for our financial service
In this material, we in the team of the payment system for online stores Fondy will tell you what problems we encountered when developing our project and how they were solved.
The infrastructure of any IT company can be divided roughly roughly into two components: technologies (software, hardware, services) and business processes. Now the infrastructure of our company is quite stable, the processes allow us to grow rapidly and, although it does not do without failures, they happen to be much less frequent than at the beginning of the journey:
')
But it was not immediately. When we started to create a company three years ago, we had ten years of practical experience in working with technologies, both payment and information, but there was no experience in building business and processes from scratch. In this column we will describe what mistakes we made, what problems we faced and how they were solved in the process of building the infrastructure that we have today.
At the start, everything seemed pretty simple and extremely clear. We knew which technologies we would use and which business model to experience. By duties, we determined that the CEO and CTO would close the main management tasks:
And we will hire such specialists in the team:
Next, we started to search for the right employees. And we ran into the first problems rather quickly.
For some reason, from the very beginning we had no luck finding a system administrator. We worked with three guys for very short periods of time, but only a year later we were able to find a good and reliable specialist. All this year, the deployment of our server infrastructure (development environment, product environment, release build, task tracking system, software version control system) went with varying success and with serious delays, delaying the release of MVP.
Additional difficulties were created by the fact that, as a payment platform, we must be certified for security standards, and the administrator must have the relevant knowledge and experience to develop and implement a hardware architecture.
Take the search for key professionals very responsibly. It is better to hire an HR agency that will search for candidates according to the requirements and qualifications described, and all you have to do is conduct an interview. If at the stage of creating a team you do not have enough competence to interview a specialist, ask someone of your friends, acquaintances, partners with the necessary qualifications to do it for you.
It is worth remembering that the team is running at the speed of the slowest participant, and hiring a low-skilled or without the right specialist experience, you run the risk that the work of the rest of the team will be greatly slowed down.
We have planned the launch of a minimally working product within four months. But no matter how much we decompose the tasks in detail and do not discuss the implementation deadlines with the developers, any task was delayed for a period 2-3 times more from the stated one.
We could not manage to load employees with at least 50% work. A narrow neck constantly appeared somewhere: the task has not yet been described, the server is not ready to deploy the development and testing environment, or the team does not understand the priority of the tasks.
In the system of accounting tasks there were no clear processes, and all tasks were dropped in one pile, from which the developer chose either an arbitrary task or the one he likes most. Most of the tasks hung on the "last mile" - it seems that all the subtasks are done, but it is impossible to assemble all the "bricks".
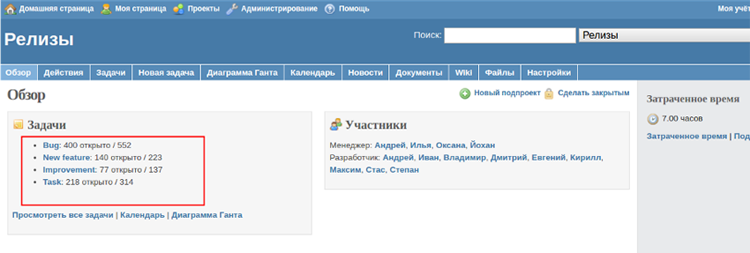
The screenshot clearly shows the ratio of unclosed tasks (400) to their total number (552)
At first it seems to you that something is wrong with the team, and apparently you hired weak specialists, and it is worth to dismiss or replace many. But in fact, the main problem is the lack of business processes.
To build the infrastructure in which development is fast, the tasks go through each stage (production, development, testing, release) in the shortest possible time it is important to involve specialists in the project who have experience in teams that work on flexible methodologies such as Agile, Scrum, Xp.
With a high degree of probability in its pure form, no development methodology can approach you and you will have to look for a middle ground. In order not to spend too much time, precious for business, in stuffing the cones, try to involve experienced specialists in setting up the processes.
When the processes gradually began to improve, the first customers appeared, the pace of growth grew, the next test for us was the allocation of resources to automate the processes.
Most startups are shutting down at a rapid growth stage due to a disproportionate increase in the cost of servicing a business. When we automated the system for connecting new clients to the service, it turned out that our accounting department was no longer able to cope with financial reports and balance sheets, and lawyers were drawing up contracts and elaborating legal aspects.
Before us was a dilemma - on the one hand, we could not stop the development of releases and abandon the already small development resources to automate back office operations, on the other, if the number of our clients increased tenfold, we would have to hire 10-20 more specialists that would eat up all of our income and drove into a big minus.
We are sure that many Internet entrepreneurs faced a problem when an accountant or a lawyer begins to adjust the vector of business development, demanding to shift priorities from the front office to direct them to back office: for example, to abandon the development of significant functionality that customers need on the site or in the main product, and focus on developing operational automation tasks.
At this stage, it is important for the enterprise to understand that back office cannot manage the business, but it is also impossible to ignore its needs. It is worth adjusting priorities and trying to automate the most massive routine operations - in the future, when your competitors will manually send contracts and acts of work done to customers, making human error and spending trust, you will appreciate the importance of what you have done.
After a year of work, we began to calculate how much server equipment and software cost. And here we have played into the hands of great experience and verified over the years decision.
We did not buy our own hardware and build the hardware infrastructure, and we chose the Amazon AWS cloud, which is represented in 38 accessibility zones around the world and conforms to dozens of standards, norms, security certificates, to host servers, and it is protected from DDoS and physical access by third parties and organizations. .
The total number of Amazon servers, according to third-party analysts, already in 2012 was almost half a million, which gives almost unlimited opportunities for scaling. It is terrible to think about how much time and resources you need to spend in order to provide at least a small part of what Amazon does in the infrastructure of its project on its own.

At the stage of product development, this choice gave us great advantages - for the first six months, all server hardware cost us no more than $ 300 per month. This time was enough for us to develop MVP and test the hypothesis of our business model.
In terms of software costs, we have always been supporters of open source software. There is an erroneous opinion that open-source products are less secure due to their open source code and carry greater business risks in terms of vulnerability, stability and quality of technical support. But as a company that undergoes an annual security audit and a quarterly external scan for intrusion attempts, we can say that open source software is in no way inferior to the famous proprietary products of well-known software giants, and even surpasses in some aspects.
When deploying your own hardware infrastructure, pay attention to cloud solutions. They are generally cheaper to operate with small volumes and easier to configure and maintain. In our situation, one system administrator is able to provide support for more than 30 servers without compromising overall efficiency. Also significantly reduce the costs of open-source-products: databases, application servers, CMS, CRM, version control systems, code and task tracking.
In addition, special attention should be paid to corporate security. Recently, a large number of cyber attacks are aimed specifically at business. From this point of view, you should entrust your security to specialized companies and tools, for example, DDoS protection systems, intrusion detection, external scanning for vulnerabilities.
In fact, it is impossible to get rid of the fall of applications, the failure of equipment, breaks in communications and other force majeure situations. Even the most reliable systems fail. For example, a lightning strike in 2011 put some of Amazon’s equipment out of action and many sites went offline.
You should always expect that at any moment any part of your infrastructure can fail: server, application, telephone call center, Internet backbone provider. Since we sign a contract (Service Level Agreement) with our clients, which guarantees a service level of 99.95%, we have tried to fully fulfill all critical nodes of our infrastructure to the fullest extent and adhere to the “let it fall” strategy - in case of a fall we always have backup copies of services, which in most cases are included in the work of an automatic monitoring system.
The company also developed a Disaster recovery plan - a document that describes a matrix of escalation of IT incidents (where to run, what to do, what specialists to call), as well as areas of responsibility of employees and top managers for business processes that were violated.
Step 1: set up monitoring of your services - there are several free applications that allow, for example, to notify Telegram or Slack if your site has become unavailable.
Step 2: First of all, try to reserve those nodes that require the least resources for this: the main site, applications, database. If possible, make sure that the main database and the backup are in different geographical areas or data centers (remember the story of the lightning in Amazon).
Step 3: Work out the incident escalation matrix. Separate various possible situations by their criticality and assign responsible employees. Determine for them the maximum reaction time, for example, if the company's main site is not available, then:
At the moment, the main problem with which we, as an enterprise that has become on the "rails" of business processes, is struggling, is the development of innovations at the same pace that we gained at the start. Increasing momentum, we gradually begin to dive into daily operational tasks, which sometimes take up so many resources that most of the time the team has to spend on supporting current processes, rather than creating a new one.
In order to adapt to the rapidly changing demands of business and fintech industry, we now divide our team into two divisions: Innovation and Operation Team. The main objectives of the Operation Team are to maintain the level of service of the current business and ensure the income of the existing business model.
In turn, the priority for the Innovation Team is to support rapid changes - the generation of new ideas and products, the introduction of innovations, the adherence to market trends and business needs. We believe that we will also manage to cope with this problem.

The infrastructure of any IT company can be divided roughly roughly into two components: technologies (software, hardware, services) and business processes. Now the infrastructure of our company is quite stable, the processes allow us to grow rapidly and, although it does not do without failures, they happen to be much less frequent than at the beginning of the journey:
')
- 35 employees provide offices in Russia, Ukraine, Latvia, the Czech Republic, Great Britain, Slovakia and Kazakhstan, thereby covering two major jurisdictions: the EU and the CIS.
- More than 30 servers provide guaranteed serviceability (Service Level) of the system at the level of 99.95% (no more than 20 minutes of planned, as well as unanticipated downtime per month) and are ready for a multiple increase in load.
- The development is carried out according to the Continuous Integration methodology using automated testing, which allows you to install updates on the production system several times a day, without fear of getting a large number of errors.
- Business processes are structured in such a way that each new functionality goes from one idea to another within 2-3 weeks, and the launch of a new project is no more than 3-4 months.
But it was not immediately. When we started to create a company three years ago, we had ten years of practical experience in working with technologies, both payment and information, but there was no experience in building business and processes from scratch. In this column we will describe what mistakes we made, what problems we faced and how they were solved in the process of building the infrastructure that we have today.
Start
At the start, everything seemed pretty simple and extremely clear. We knew which technologies we would use and which business model to experience. By duties, we determined that the CEO and CTO would close the main management tasks:
- CEO - business processes, operational, financial, legal tasks, product creation;
- Technical Director - technological architecture, software development, project management.
And we will hire such specialists in the team:
- System Administrator;
- two backend developers;
- two frontend developers;
- tester for manual and automated testing;
- accountant;
- lawyer;
- financial monitoring specialist;
- antifraud monitoring specialist.
Next, we started to search for the right employees. And we ran into the first problems rather quickly.
Problem 1. Employee search
For some reason, from the very beginning we had no luck finding a system administrator. We worked with three guys for very short periods of time, but only a year later we were able to find a good and reliable specialist. All this year, the deployment of our server infrastructure (development environment, product environment, release build, task tracking system, software version control system) went with varying success and with serious delays, delaying the release of MVP.
Additional difficulties were created by the fact that, as a payment platform, we must be certified for security standards, and the administrator must have the relevant knowledge and experience to develop and implement a hardware architecture.
The board
Take the search for key professionals very responsibly. It is better to hire an HR agency that will search for candidates according to the requirements and qualifications described, and all you have to do is conduct an interview. If at the stage of creating a team you do not have enough competence to interview a specialist, ask someone of your friends, acquaintances, partners with the necessary qualifications to do it for you.
It is worth remembering that the team is running at the speed of the slowest participant, and hiring a low-skilled or without the right specialist experience, you run the risk that the work of the rest of the team will be greatly slowed down.
Problem 2. Running MVP on schedule
We have planned the launch of a minimally working product within four months. But no matter how much we decompose the tasks in detail and do not discuss the implementation deadlines with the developers, any task was delayed for a period 2-3 times more from the stated one.
We could not manage to load employees with at least 50% work. A narrow neck constantly appeared somewhere: the task has not yet been described, the server is not ready to deploy the development and testing environment, or the team does not understand the priority of the tasks.
In the system of accounting tasks there were no clear processes, and all tasks were dropped in one pile, from which the developer chose either an arbitrary task or the one he likes most. Most of the tasks hung on the "last mile" - it seems that all the subtasks are done, but it is impossible to assemble all the "bricks".
The screenshot clearly shows the ratio of unclosed tasks (400) to their total number (552)
At first it seems to you that something is wrong with the team, and apparently you hired weak specialists, and it is worth to dismiss or replace many. But in fact, the main problem is the lack of business processes.
The board
To build the infrastructure in which development is fast, the tasks go through each stage (production, development, testing, release) in the shortest possible time it is important to involve specialists in the project who have experience in teams that work on flexible methodologies such as Agile, Scrum, Xp.
With a high degree of probability in its pure form, no development methodology can approach you and you will have to look for a middle ground. In order not to spend too much time, precious for business, in stuffing the cones, try to involve experienced specialists in setting up the processes.
Problem 3. Fast growth, scaling and automation of processes.
When the processes gradually began to improve, the first customers appeared, the pace of growth grew, the next test for us was the allocation of resources to automate the processes.
Most startups are shutting down at a rapid growth stage due to a disproportionate increase in the cost of servicing a business. When we automated the system for connecting new clients to the service, it turned out that our accounting department was no longer able to cope with financial reports and balance sheets, and lawyers were drawing up contracts and elaborating legal aspects.
Before us was a dilemma - on the one hand, we could not stop the development of releases and abandon the already small development resources to automate back office operations, on the other, if the number of our clients increased tenfold, we would have to hire 10-20 more specialists that would eat up all of our income and drove into a big minus.
The board
We are sure that many Internet entrepreneurs faced a problem when an accountant or a lawyer begins to adjust the vector of business development, demanding to shift priorities from the front office to direct them to back office: for example, to abandon the development of significant functionality that customers need on the site or in the main product, and focus on developing operational automation tasks.
At this stage, it is important for the enterprise to understand that back office cannot manage the business, but it is also impossible to ignore its needs. It is worth adjusting priorities and trying to automate the most massive routine operations - in the future, when your competitors will manually send contracts and acts of work done to customers, making human error and spending trust, you will appreciate the importance of what you have done.
Problem 4. Where to place server hardware, what software to choose and how much it should cost
After a year of work, we began to calculate how much server equipment and software cost. And here we have played into the hands of great experience and verified over the years decision.
We did not buy our own hardware and build the hardware infrastructure, and we chose the Amazon AWS cloud, which is represented in 38 accessibility zones around the world and conforms to dozens of standards, norms, security certificates, to host servers, and it is protected from DDoS and physical access by third parties and organizations. .
The total number of Amazon servers, according to third-party analysts, already in 2012 was almost half a million, which gives almost unlimited opportunities for scaling. It is terrible to think about how much time and resources you need to spend in order to provide at least a small part of what Amazon does in the infrastructure of its project on its own.
At the stage of product development, this choice gave us great advantages - for the first six months, all server hardware cost us no more than $ 300 per month. This time was enough for us to develop MVP and test the hypothesis of our business model.
In terms of software costs, we have always been supporters of open source software. There is an erroneous opinion that open-source products are less secure due to their open source code and carry greater business risks in terms of vulnerability, stability and quality of technical support. But as a company that undergoes an annual security audit and a quarterly external scan for intrusion attempts, we can say that open source software is in no way inferior to the famous proprietary products of well-known software giants, and even surpasses in some aspects.
The board
When deploying your own hardware infrastructure, pay attention to cloud solutions. They are generally cheaper to operate with small volumes and easier to configure and maintain. In our situation, one system administrator is able to provide support for more than 30 servers without compromising overall efficiency. Also significantly reduce the costs of open-source-products: databases, application servers, CMS, CRM, version control systems, code and task tracking.
In addition, special attention should be paid to corporate security. Recently, a large number of cyber attacks are aimed specifically at business. From this point of view, you should entrust your security to specialized companies and tools, for example, DDoS protection systems, intrusion detection, external scanning for vulnerabilities.
Problem 5. How to ensure the stability of the infrastructure and protect against falls
In fact, it is impossible to get rid of the fall of applications, the failure of equipment, breaks in communications and other force majeure situations. Even the most reliable systems fail. For example, a lightning strike in 2011 put some of Amazon’s equipment out of action and many sites went offline.
You should always expect that at any moment any part of your infrastructure can fail: server, application, telephone call center, Internet backbone provider. Since we sign a contract (Service Level Agreement) with our clients, which guarantees a service level of 99.95%, we have tried to fully fulfill all critical nodes of our infrastructure to the fullest extent and adhere to the “let it fall” strategy - in case of a fall we always have backup copies of services, which in most cases are included in the work of an automatic monitoring system.
The company also developed a Disaster recovery plan - a document that describes a matrix of escalation of IT incidents (where to run, what to do, what specialists to call), as well as areas of responsibility of employees and top managers for business processes that were violated.
The board
Step 1: set up monitoring of your services - there are several free applications that allow, for example, to notify Telegram or Slack if your site has become unavailable.
Step 2: First of all, try to reserve those nodes that require the least resources for this: the main site, applications, database. If possible, make sure that the main database and the backup are in different geographical areas or data centers (remember the story of the lightning in Amazon).
Step 3: Work out the incident escalation matrix. Separate various possible situations by their criticality and assign responsible employees. Determine for them the maximum reaction time, for example, if the company's main site is not available, then:
- the monitoring officer must call the system administrator within five minutes;
- if it was not possible to call within 20 minutes, or the problem is not solved - call the technical director;
- if the problem is still not resolved within 1 hour - inform the top management via SMS;
- if the problem persists within two hours, inform the top management in a telephone call with the organization of a conference stake with the other participants in the escalation matrix.
Problem 6. How not to get bogged down in the operating routine and continue to produce innovations
At the moment, the main problem with which we, as an enterprise that has become on the "rails" of business processes, is struggling, is the development of innovations at the same pace that we gained at the start. Increasing momentum, we gradually begin to dive into daily operational tasks, which sometimes take up so many resources that most of the time the team has to spend on supporting current processes, rather than creating a new one.
In order to adapt to the rapidly changing demands of business and fintech industry, we now divide our team into two divisions: Innovation and Operation Team. The main objectives of the Operation Team are to maintain the level of service of the current business and ensure the income of the existing business model.
In turn, the priority for the Innovation Team is to support rapid changes - the generation of new ideas and products, the introduction of innovations, the adherence to market trends and business needs. We believe that we will also manage to cope with this problem.
Source: https://habr.com/ru/post/322774/
All Articles