Uber - the reasons for the transition from Postgres to MySQL
At the end of July 2016, a truly historical article appeared on the Uber corporate blog about the reasons for the company's transition from PostgreSQL to MySQL. Since then, a lot of copies have been broken in hot discussions of this material, Uber’s arguments were carefully prepared, the company was accused of bias, technical illiteracy, inability to effectively interact with the community and other deadly sins, while several changes were made to Postgres, designed to solve some of the problems described. The list of consequences does not end there, and it can be continued for a very long time.
Probably it would not be an exaggeration to say that over the past few years this has become one of the most notorious and resonant events connected with the PostgreSQL DBMS, which, by the way, we love and use extensively. This situation certainly benefited not only the systems mentioned, but also the movement of Free and Open Source as a whole. At the same time, unfortunately, the Russian translation of the article did not appear. Due to the significance of the event, as well as a detailed and interesting from a technical point of view material presentation, in which in the style of “Postgres vs MySQL” there is a comparison of the physical data structure on the disk, organization of primary and secondary indexes, replication, MVCC, updates and support of a large number of connections, we decided to fill this gap and translate the original article. Result you can find under the cut.
Introduction
At an early stage of development, the Uber architecture consisted of a monolithic server application in Python that used Postgres to store data. Since then, much has changed: the model of microservices was applied, as well as new data processing and storage platforms. In particular, we used to use Postgres in many cases, but now we’ve switched to Schemaless , a new distributed storage system running on top of MySQL. In this article we will talk about some of the shortcomings of Postgres and explain why we decided to build Schemaless and other services based on MySQL.
Postgres architecture
We encountered several Postgres flaws, including:
- architecture inefficiency in terms of writing,
- poor data replication
- table damage cases
- MVCC issues on replicas
- difficulty updating.
We will look at these limitations by analyzing how Postgres places table and index data on disk, especially when compared to the MySQL approach implemented with the InnoDB storage subsystem . Please note: the analysis presented here is for the most part based on our experience with the rather old version of Postgres 9.2. But as far as we know, the internal architecture that we are discussing in this article has not seriously changed in new releases of Postgres. Moreover, the basic principles of presenting data on disk, which are used in version 9.2, have not changed significantly since at least Postgres 8.3 (that is, it is almost 10 years old).
Disk format
A relational DBMS must provide several key tasks:
- performing insert / update / delete operations;
- making changes to the data schema;
- implementation of the mechanism for controlling parallel access using multiversion (multiversion concurrency control, MVCC), which allows different connections to the database to use transactions when working with data.
The interaction of the above mechanisms largely determines how the DBMS will store data on disk.
One of the key aspects of Postgres design is immutable strings. They are called tuples in Postgres. Tuples have unique identifiers — ctid , which essentially represent a specific disk space (i.e., offset on physical media). Several ctid could potentially describe a single line (for example, if there are multiple versions of the line within the MVCC or when the space occupied by the old versions of the line has not yet been freed by autovacuum ). An organized collection of tuples forms a table. Tables have indexes that have a specific data structure (usually B-trees), by means of which index fields are matched with data identified by ctid.
The user is usually not confronted with ctid, but understanding these identifiers will help to better understand how Postgres stores data on disk. To get ctid rows, add the “ctid” column to the query:
uber@[local] uber=> SELECT ctid, * FROM my_table LIMIT 1; -[ RECORD 1 ]--------+------------------------------ ctid | (0,1) ... ... Let's take a simple user table as an example. Each row has an automatically increasing primary key id, first name, last name and year of birth. We will also create a secondary composite index for the full name (first name and surname) and another secondary index for the year of birth. DDL instructions for creating such a table might look like this:
CREATE TABLE users ( id SERIAL, first TEXT, last TEXT, birth_year INTEGER, PRIMARY KEY (id) ); CREATE INDEX ix_users_first_last ON users (first, last); CREATE INDEX ix_users_birth_year ON users (birth_year); Note: these instructions create three indexes: an index for the primary key and two secondary indexes.
Fill the table with the data of famous mathematicians:
| id | first | last | birth_year |
| one | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| four | Muhammad | al-Khwārizmī | 780 |
| five | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| eight | Henri | Poincaré | 1854 |
As mentioned earlier, each line contains a unique, non-default ctid. The internal representation of the table may look as follows:
| ctid | id | first | last | birth_year |
| A | one | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | four | Muhammad | al-Khwārizmī | 780 |
| E | five | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| H | eight | Henri | Poincaré | 1854 |
The primary key index, which is used to match id and ctid identifiers, is defined as follows:
| id | ctid |
| one | A |
| 2 | B |
| 3 | C |
| four | D |
| five | E |
| 6 | F |
| 7 | G |
| eight | H |
A B-tree (B-tree) is built on the basis of the id field, and each node contains a ctid value. Note: in this case, the order of index entries coincides with the order of entries in the table. This is due to the autoincrement of the id field, but this is not always the case.
Secondary indexes look similar. The main difference is that the records are stored in a different order, since the B-tree must be organized lexicographically. The index (first, last) begins with the names arranged in alphabetical order:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Srinivasa | Ramanujan | F |
The birth_year index is clustered in ascending order:
| birth_year | ctid |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
Unlike the primary index by id, in both secondary indexes the values of the ctid field do not lexicographically increase.
Suppose that you need to update one of the records in the table. Change al-Khwārizmī's year of birth to 770. As we mentioned earlier, string tuples are immutable. Thus, to update the record, you need to add a new tuple to the table. It will have a new ctid, let's call it I. Postgres should be able to distinguish the new active tuple I from the old version D. For this, each tuple has a field with the version number and a pointer to the previous tuple (if there is one). Accordingly, the updated table is as follows:
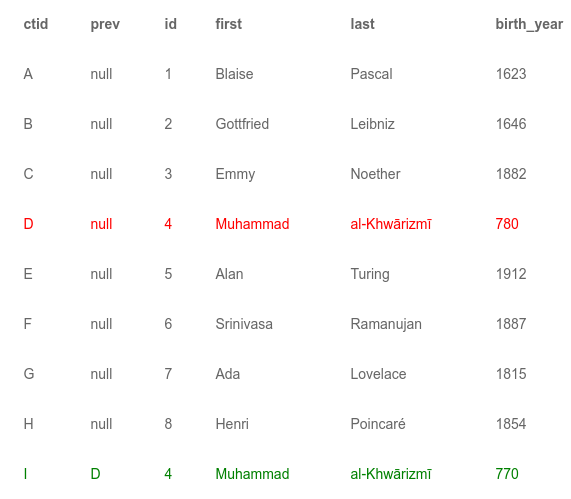
Since we now have two rows with al-Khwārizmī, the indexes should contain entries for each of them. For brevity, we omit the index on the primary key and show only the secondary indexes:

')
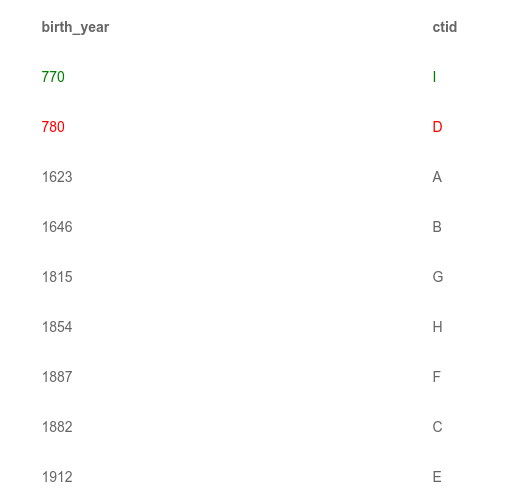
The old version is highlighted in red, and the new one - in green. Under the hood of Postgres, there is another field in which the version of the tuple is stored. This field allows the DBMS to show transactions only those rows that they should see.
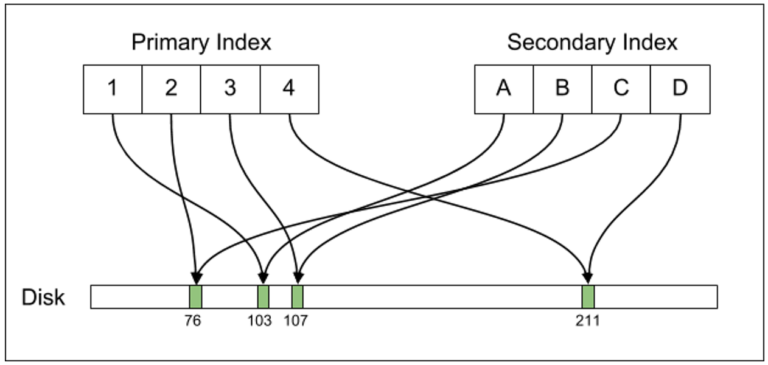
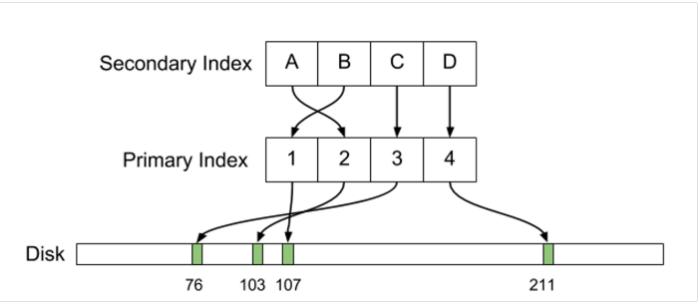
In Postgres, the primary and secondary indexes directly indicate the physical displacements of the tuples on the disk. If you change the location of the line indexes need to be updated.
Replication
If stream replication is configured in Postgres, for example, when inserting a new row into the table, such a change needs to be replicated. For recovery purposes after failures , a forward-looking write log (WAL) is built into the DBMS, which is used to perform two-phase commit . The DBMS must maintain WAL even when streaming replication is disabled, since WAL is also needed to comply with the principles of atomicity and durability of the ACID requirements.
To better understand WAL, consider the case of an unplanned DBMS shutdown, which can occur, for example, during a power outage. WAL makes all the changes that the DBMS plans to make in the contents of the tables and indexes on the disk. Postgres daemon compares WAL to disk data after launch. In the event that there is something in WAL that has not yet been written to disk, the DBMS makes changes, matching the data on the disk and the contents of the proactive write log. Then the DBMS rolls back those instructions in WAL that refer to uncommitted transactions.
Postgres streaming replication is implemented by forwarding WAL from the master to replicas that actually work in disaster recovery mode, constantly applying WAL updates just as it would have done if the system was started after an abnormal shutdown. The only difference in streaming replication from disaster recovery is that replicas work in hot standby mode, handling read requests in parallel with streaming changes, while the Postgres database in recovery mode usually refuses to maintain any requests until the recovery process is complete.
Since WAL was designed for recovery purposes, low-level information about updating data on disk is written to it. WAL content is at the level of the actual presentation of tuple data on a disk, including their physical offsets (i.e. ctid values). If you suspend the master and the replica that is completely synchronized with it, the actual location of the data on the disks of both systems will be identical literal bytes to bytes. Thus, tools like rsync can be used to restore replica data if it is far behind the master.
What are the features of Postgres design?
Features Postgres led to difficulties and reduced efficiency of working with data in Uber .
Record Gain
The first issue with Postgres design is with write enhancement . Usually, this term is mentioned in connection with the peculiarities of the operation of SSD disks: a logically small update (say, writing a few bytes) becomes a much more serious and resource-intensive operation at the physical level. A similar problem exists in Postgres. In our previous example, when we made a logical small update, changing the year of birth of al-Khwārizmī, physically the system had to perform at least four operations:
1) write the new tuple into the tablespace ,
2) update the index on the primary key, adding an entry for the new tuple,
3) update the index (first, last), adding an entry for the new tuple,
4) update the birth_year index, adding an entry for the new tuple
In fact, these four items reflect only the changes made in the main tablespace (main tablespace), but they also need to be taken into account in WAL, so the total number of write operations is even greater.
It is worth mentioning points 2 and 3 separately. After we updated the year of birth of al-Khwārizmī, neither the primary key of the record, nor the meaning of the name and surname changed. And yet the indices have to be updated, since a new tuple has appeared in the database. For tables with a large number of secondary indexes, these additional steps can lead to significant write overhead. For example, for a table with a dozen indexes, updating the field covered by only one index should be extended to the other nine, since it is necessary to write in them the ctid of the new row.
Replication
The problem with recording enhancement also affects replication, which is performed at the disk data presentation level. Instead of transferring a small logical record, such as, for example, “Change the year of birth for ctid D, setting it to 770”, the DBMS must send all WAL elements relating to the four above-mentioned operations accompanying the record. Thus, the problem of recording gain goes into the problem of replication gain, and the Postgres replication data stream very quickly becomes so significant that it can take up much of the available network bandwidth.
In cases where replication is performed within the same datacenter, there will most likely not be a problem with bandwidth. Modern network equipment can handle large amounts of data, and many hosting providers charge a small fee for transferring data within the data center or provide this service for free. However, when it is necessary to set up replication between machines in different data centers, problems can begin to grow like a snowball. For example, Uber first used physical servers in a colocation center on the West Coast. In case of disaster recovery, we placed several replicas on additional servers on the East Coast.
Through the use of cascade replication, we were able to reduce the amount of data sent between data centers to the values necessary for replication between one master and one replica. However, postgres replication “verbosity” can still lead to the need to transfer too large volumes if many indices are used. Buying high-speed data channels connecting different parts of the country is expensive. But even when money is not a problem, it is simply impossible to get speeds comparable to the local network connections of the datacenters. This bandwidth problem also makes it difficult to archive WAL. In addition to sending WAL updates from the West Coast to the East Coast, we archived it in a web-based file storage. These archives could be used both in case of need for disaster recovery and for the deployment of new replicas. During peak loads, the bandwidth of the network connection to the file storage was simply not enough to keep up with the WAL updates created during the work with the database.
Data corruption
During the standard operation to increase database capacity, which used the replica enhancement mechanism, we encountered an error in Postgres 9.2. Replicas incorrectly handled the timeline switch, with the result that some of them incorrectly applied WAL updates. Due to this error, some of the entries that should have been deactivated by the versioning mechanism did not receive a corresponding note, that is, they remained active.
Using the following query, we can illustrate how this error will be reflected in our example with a user table:
SELECT * FROM users WHERE id = 4; The query will return two entries: the initial string for al-Khwārizmī with a birth year equal to 780, as well as a new entry with birth_year = 770. If we add a ctid column to the query, we will get different values of these identifiers, as in two different strings.
This problem turned out to be extremely unpleasant for us for several reasons. First: it was impossible to say exactly how many lines were affected. In some cases, duplicates caused the application to malfunction. As a result, we had to add instructions to the application code to detect such situations. Secondly, since the error appeared on all servers, each of them spoiled different strings, that is, on one replica, line X could be damaged, and Y was untouched, but on another replica, line X could be in order, and Y - damaged. In fact, we did not know exactly how many replicas had corrupted data, and whether this problem was manifested on the wizard.
As far as we understood, only a few lines were usually damaged on the entire base, but still we were extremely concerned, since the indices could be completely corrupted due to the fact that replication is performed on a physical level. An essential feature of B-trees is the need for their periodic rebalancing , and this operation can completely change the tree structure, since the subtrees are moved to other places on the disk. When moving damaged data, significant parts of the tree may be incorrect.
As a result, we were able to find the error and, having analyzed it, find out that the lines were not damaged on the cue, which was becoming the new master. By resynchronizing with a fresh snapshot of the wizard, we corrected the data on all replicas. It was a very laborious process, because at that time we could afford to simultaneously remove only a few replicas from the workload load balancing pool.
The bug found appeared in some releases of Postgres 9.2 and has been fixed a long time ago. However, we are very concerned about the fact that such a thing turned out to be possible. At any time, we can expect the release of a new version of Postgres with a similar error, and due to the nature of the replication mechanism, the problem may spread to all databases in the replication hierarchy.
MVCC on replicas
Postgres does not actually support MVCC replicas. Since WAL updates are applied on replicas, there is a copy of the database on them at any time with the same data on the disk as on the wizard . For Uber, this is a serious problem.
To ensure the operation of the MVCC mechanism, the DBMS needs to store old versions of strings. , , , . Postgres WAL , . , , . Postgres : WAL , Postgres .
Postgres , . , . , , . , , . , . , , -, , , ORM, , .
Postgres
, , Postgres. Postgres 9.3 Postgres 9.2; 9.2- 9.3-.
- .
- pg_upgrade. , .
- .
- . , .
- .
- . , , , .
Postgres 9.1 9.2. , . , Postgres 9.3, , . Postgres 9.2, , 9.5.
Postgres 9.4 pglogical , Postgres. pglogical Postgres, , , 9.4 9.5 . Postgres, . , Postgres, pglogical .
MySQL
Postgres , MySQL Uber Engineering , , , Schemaless. , MySQL . MySQL Postgres. InnoDB , , , MySQL.
InnoDB —
Postgres, InnoDB MVCC . , InnoDB, . Postgres.
, Postgres , InnoDB , ( ctid Postgres), . , MySQL :
| first | last | id (primary key) |
| Ada | Lovelace | 7 |
| Alan | Turing | five |
| Blaise | Pascal | one |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincaré | eight |
| Muhammad | al-Khwārizmī | four |
| Srinivasa | Ramanujan | 6 |
(first, last), : , .
InnoDB Postgres, . , , , . InnoDB . - MVCC , MySQL (rollback segment) .
, al-Khwārizmī. id=4 ( « », birth year — , ). birth year « », . ( (first, last)). , , birth_year. , , , signup_date, last_login_time . ., , Postgres .
(vacuum) (compaction). , , , . : Postgres autovacuum .

MySQL : , , , . .
- statement-based- SQL- ( :
sql UPDATE users SET birth_year=770 WHERE id = 4). - row-based- .
- (mixed) .
. Statement-based- , . , row-based-, WAL Postgres, «», .
MySQL , . . « timestamp X T_1 T_2». .
Postgres , , , « XYZ 8,382,491». WAL. ( , , timestamp) : . , WAL . , MySQL WAL PostgreSQL.
MVCC . MySQL , MVCC-, . , Postgres , , , MVCC.
MySQL , . , , B- , . MySQL , SQL- ( ). , .
, MySQL , . MySQL , , . , . MySQL — , , , . MySQL .
MySQL
Postgres MySQL, . MySQL , Postgres.
-. Postgres , . Postgres (page cache) . , Postgres 768 , RSS- , Postgres, 25 . , 700 Linux.
, RSS. Postgres lseek(2) read(2) . , . Postgres : pread(2) , (seek + read) .
InnoDB LRU (buffer pool) InnoDB. Linux, . Postgres, InnoDB :
- LRU. , , , .
- . InnoDB —. TLB , , , huge pages .
MySQL (thread). : , . , MySQL 10 000 . MySQL .
Postgres . . , . , IPC , . Postgres 9.2 System V IPC (futexes) , , , , .
, , Postgres . , , Postgres . ( ) (connection pooler) . pgbouncer . , ( “idle in transaction”), . .
Conclusion
Postgres Uber, , . Postgres, MySQL ( Schemaless ), NoSQL-, Cassandra. MySQL Uber.
Evan Klitzke () Uber Engineering . , Uber 2012.
Source: https://habr.com/ru/post/322624/
All Articles