Implementing OOP inheritance in classes that work with SQL and MS Entity Framework
This article is devoted to creating a data model that would fit beautifully on SQL and contain the “right” OOP inheritance. I must say that this problem arose in different projects at my time, and it was solved there in different ways too. The names of the approaches are taken from the terminology of the respective projects.
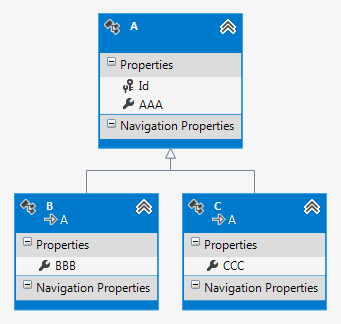
The easiest way is to completely trust the Entity Framework mechanism. If you create an empty project, and in it - an empty data model, to which you add classes, on the basis of which the database will be generated, you get something like this (the tool is Visual Studio 2012):
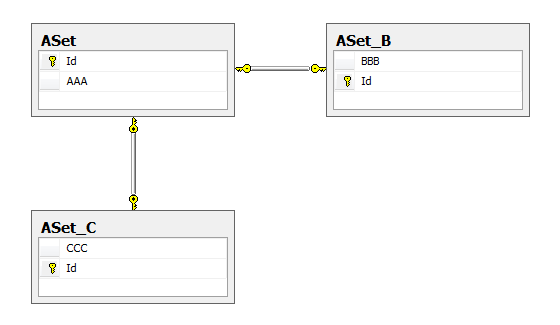
After creation, the following data model will be located in SQL Server:
Well, very optimally, I must admit. The only thing that confuses is the specific names of the tables. Here are the corresponding scripts for creating database tables obtained using the Tasks / Generate scripts tool:
')
In this approach, only table names are confused.
This method shows how it was done before, when the sky was taller, and dinosaurs were still writing programs in Fortran. (To tell the truth, it seemed to me that in the epoch of MS SQL Server 2005 and Visual Studio 2008 I obtained exactly this result using the “Generate Database from Model” from the Entity Framework.)
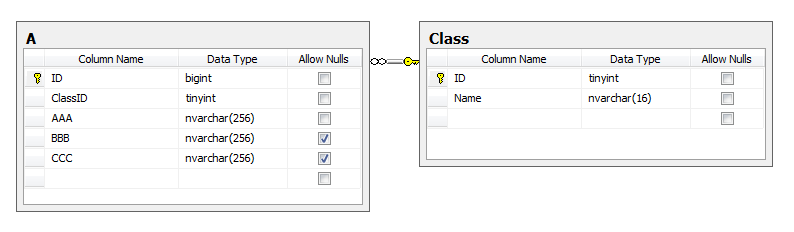
I omit the scripts and database-first data model, since they are quite trivial. The minus of the given approach is obvious. As soon as classes B and C increase the number of columns that are not related to ancestor A (especially if these are char [] fields of a constant size), then the disk space occupied by the table starts to grow sharply, while the share of useful information in this cemetery bytes is proportionally reduced. Normalization? - no, have not heard ... Unfortunately, for historical reasons (for example, to maintain backward compatibility), such schemes are still found in large enterprise-projects that have been developed for several years. But in new developments, this is clearly not worth doing. You are welcome…
Creating a view over tables that have the same fields in the code can be represented using the interface (view view in code) and the classes that implement it (table view in code). There are two advantages. The first is that there are no problems with inefficient use of disk space, as in the previous approach. Second, you can use indexes and other things that speed up the unloading of data from the database. Minus - the code for SQL queries for sampling and adding data will have to be written in pens. For example, here is the sample code from this view:
Obviously, the fields of tables B and C do not allow such a query. You can also shove it into getting these BBB and CCC columns, with the result that the answer with a bunch of NULLs will be very similar to the Classification option:
Personally, my two-wheeled pedal-steering solution is to create a separate table for each descendant class, which will be associated with the table of the parent-class relations "1-to-1."
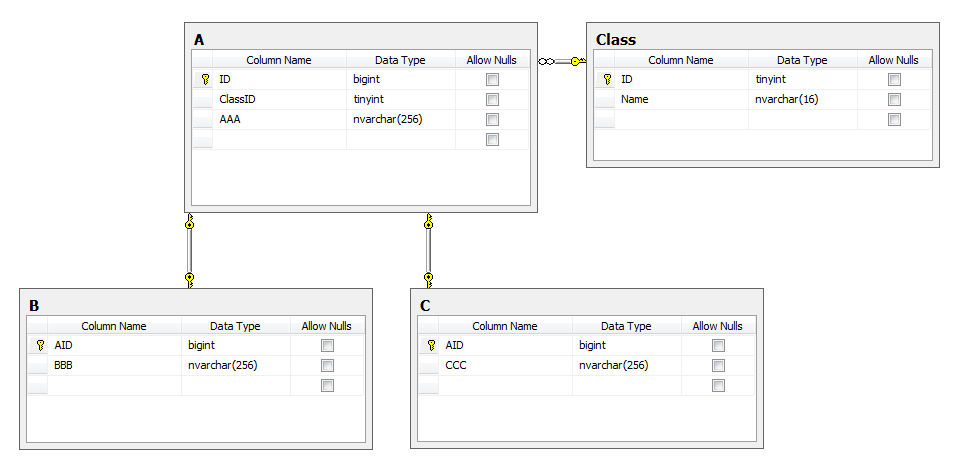
Obviously, it is necessary to maintain the integrity of such a scheme with the help of triggers that will cut records from the parent table when deleting the corresponding children (and vice versa) and control the addition / editing of records so that the child from table X matches the record of the parent with type “X” and not , for example, "Y".
Since I like to use the Entity Framework in my projects, I have to make additional efforts to create the appropriate class structure. In parallel with the classes from the folder “Entity”, where the generated code is database-first, there is also a folder “BusinessLogic”, the classes in which already have more distinct connections. This is how the transformation code “Entity Framework → Business Logic” and “Business Logic → Entity Framework” is done.
Advantages compared to:
It is clear that the proposed approach is never a “golden bullet”. Especially when the “default” method works so well. But I think that he may still be useful to someone in any specific circumstances.
Approach # 1: Default
The easiest way is to completely trust the Entity Framework mechanism. If you create an empty project, and in it - an empty data model, to which you add classes, on the basis of which the database will be generated, you get something like this (the tool is Visual Studio 2012):
After creation, the following data model will be located in SQL Server:
Well, very optimally, I must admit. The only thing that confuses is the specific names of the tables. Here are the corresponding scripts for creating database tables obtained using the Tasks / Generate scripts tool:
')
CREATE TABLE [dbo].[ASet]( [Id] [int] IDENTITY(1,1) NOT NULL, [AAA] [nvarchar](max) NOT NULL, CONSTRAINT [PK_ASet] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] CREATE TABLE [dbo].[ASet_C]( [CCC] [nvarchar](max) NOT NULL, [Id] [int] NOT NULL, CONSTRAINT [PK_ASet_C] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] CREATE TABLE [dbo].[ASet_B]( [BBB] [nvarchar](max) NOT NULL, [Id] [int] NOT NULL, CONSTRAINT [PK_ASet_B] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] ALTER TABLE [dbo].[ASet_C] WITH CHECK ADD CONSTRAINT [FK_C_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE ALTER TABLE [dbo].[ASet_C] CHECK CONSTRAINT [FK_C_inherits_A] ALTER TABLE [dbo].[ASet_B] WITH CHECK ADD CONSTRAINT [FK_B_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE ALTER TABLE [dbo].[ASet_B] CHECK CONSTRAINT [FK_B_inherits_A] In this approach, only table names are confused.
Approach # 2: Classification
This method shows how it was done before, when the sky was taller, and dinosaurs were still writing programs in Fortran. (To tell the truth, it seemed to me that in the epoch of MS SQL Server 2005 and Visual Studio 2008 I obtained exactly this result using the “Generate Database from Model” from the Entity Framework.)
I omit the scripts and database-first data model, since they are quite trivial. The minus of the given approach is obvious. As soon as classes B and C increase the number of columns that are not related to ancestor A (especially if these are char [] fields of a constant size), then the disk space occupied by the table starts to grow sharply, while the share of useful information in this cemetery bytes is proportionally reduced. Normalization? - no, have not heard ... Unfortunately, for historical reasons (for example, to maintain backward compatibility), such schemes are still found in large enterprise-projects that have been developed for several years. But in new developments, this is clearly not worth doing. You are welcome…
Approach # 3: Polymorphic View
Creating a view over tables that have the same fields in the code can be represented using the interface (view view in code) and the classes that implement it (table view in code). There are two advantages. The first is that there are no problems with inefficient use of disk space, as in the previous approach. Second, you can use indexes and other things that speed up the unloading of data from the database. Minus - the code for SQL queries for sampling and adding data will have to be written in pens. For example, here is the sample code from this view:
CREATE VIEW [A] AS SELECT * FROM ( SELECT [AID] AS ID, 1 AS [ClassID], [AAA] FROM [B] UNION ALL SELECT [AID] AS ID, 2 AS [ClassID], [AAA] FROM [C] ) Q Obviously, the fields of tables B and C do not allow such a query. You can also shove it into getting these BBB and CCC columns, with the result that the answer with a bunch of NULLs will be very similar to the Classification option:
CREATE VIEW [A] AS SELECT * FROM ( SELECT [AID] AS ID, 1 AS [ClassID], [AAA], [BBB], NULL AS [CCC] FROM [B] UNION ALL SELECT [AID] AS ID, 2 AS [ClassID], [AAA] , NULL AS [BBB], [CCC] FROM [C] ) Q Approach # 4: Hierarchical Tables
Personally, my two-wheeled pedal-steering solution is to create a separate table for each descendant class, which will be associated with the table of the parent-class relations "1-to-1."
Obviously, it is necessary to maintain the integrity of such a scheme with the help of triggers that will cut records from the parent table when deleting the corresponding children (and vice versa) and control the addition / editing of records so that the child from table X matches the record of the parent with type “X” and not , for example, "Y".
Since I like to use the Entity Framework in my projects, I have to make additional efforts to create the appropriate class structure. In parallel with the classes from the folder “Entity”, where the generated code is database-first, there is also a folder “BusinessLogic”, the classes in which already have more distinct connections. This is how the transformation code “Entity Framework → Business Logic” and “Business Logic → Entity Framework” is done.
- Create an IA interface in the folder "Entity".
public interface IA { AA { get; } EntityReference<A> AReference { get; } } - We inherit from it the autogenerated classes B and C lying in the same folder.
- Create an enum with the type name AClassEnum, into which we rewrite virtually all the rows from the Class table.
- In the BusinessLogic folder, create the classes abstract A, B: A, and C: A. (By the way, it is not necessary to make A abstract - I just did it because of the requirements.)
- We write about the following:
public abstract class A { public long ID { get; set; } public abstract ClassEnum Class { get; } public string AAA { get; set; } protected A() { } protected A(Entity.IA a) { if (!a.AReference.IsLoaded) { a.AReference.Load(MergeOption.NoTracking /* – */); } if (aAClassID != (byte) Class) { throw new Exception("Class type {0} instead of {1}!", aAClass, (ClassEnum) aAClassID)); } ID = aAID; } public Entity. A CreateA() { return new Entity.A { ClassID = (byte) Class, }; } } public class B : A { public string BBB { get; set; } public override ClassEnum Class { get { return ClassEnum.B; } } public B() : base() { } public B(Entity.B b) : base(b) { BBB = b.BBB; } public override Entity.B ToEntity() { return new Entity.B { A = CreateA(), BBB = BBB, }; } } // C
Advantages compared to:
- ... the default approach is more beautiful table names
- ... the "classification" table - less data
- ... view - everything is nicely imported into the Entity Framework
It is clear that the proposed approach is never a “golden bullet”. Especially when the “default” method works so well. But I think that he may still be useful to someone in any specific circumstances.
Source: https://habr.com/ru/post/322596/
All Articles