MySQL and MongoDB - when and what is better to use

Peter Zaitsev shows the difference between MySQL and MongoDB. This is a transcript of the report with Highload ++ 2016.
If you look at such a well - known DB-Engines Ranking , you can see that over the years, the popularity of open source databases is growing, and commercial ones are gradually decreasing.
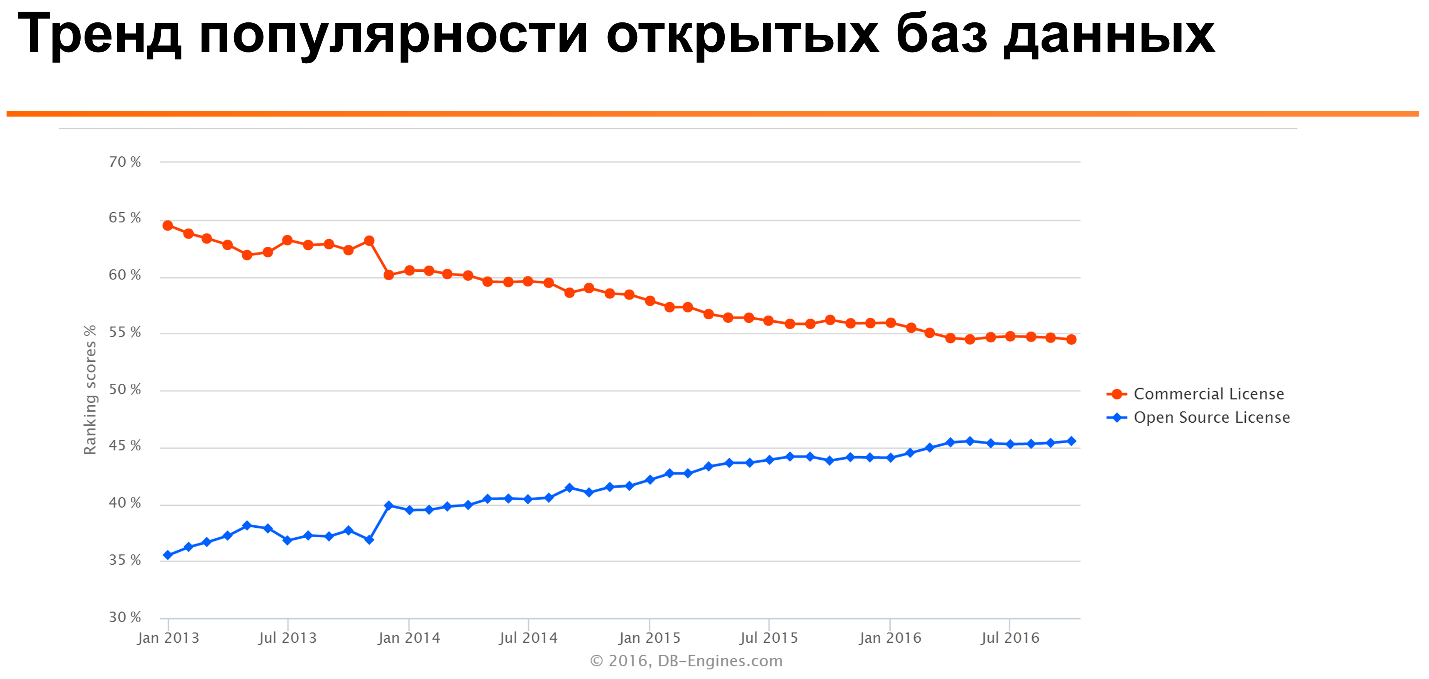
')
What is even more interesting: if you look at this relationship for different types of databases, you can see that for many types - such as colunar databases, time series, document stories - open source databases are the most popular. Only for older technologies, such as relational databases, or even more ancient ones, like the multivalue database, are commercial licenses much more popular.
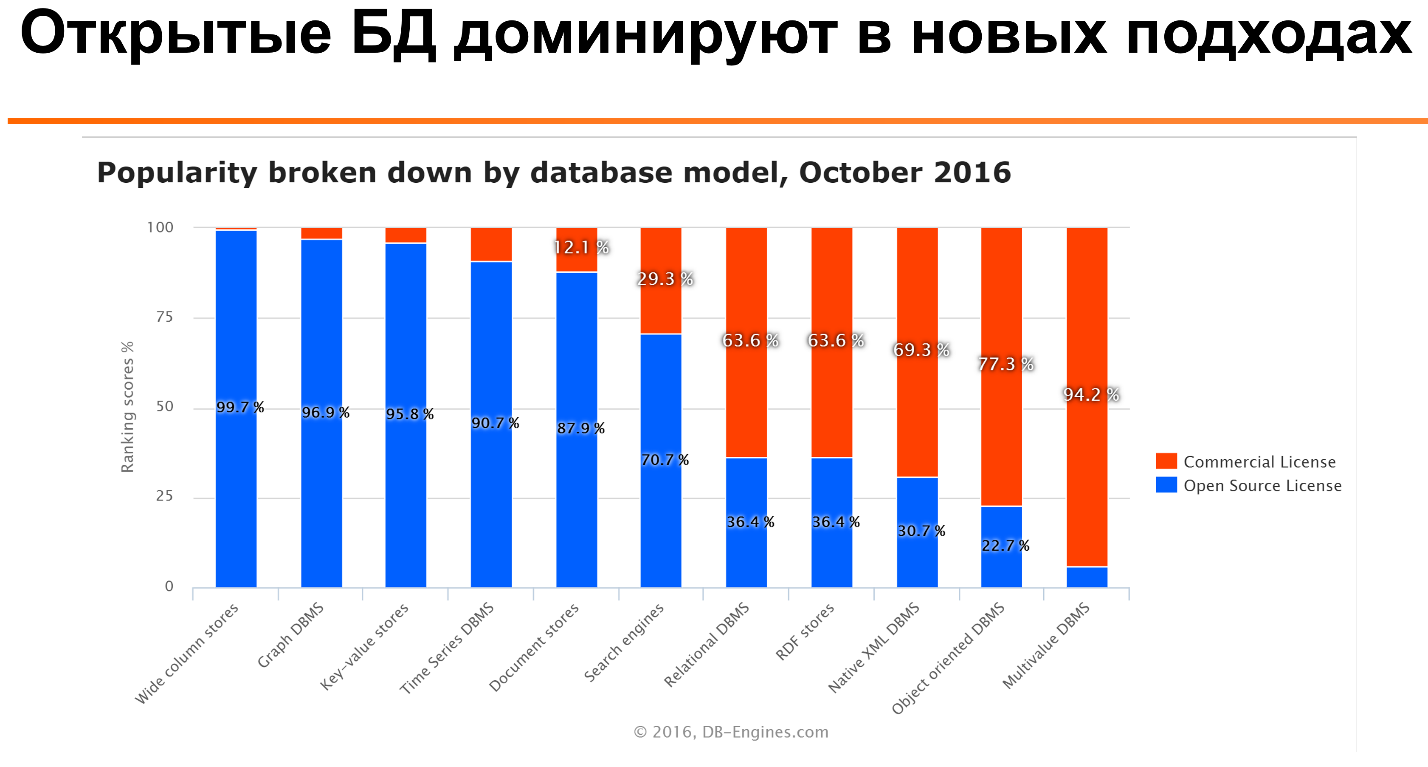
We see that for many applications, several databases are used to exploit their strengths. No database is optimized for all sorts of yuzkeys. Even if it is PostgreSQL [laughter on stage and in the hall].
On the one hand, this is a good choice, on the other - you need to try to find a balance, because the more different technologies we have, the harder it is to support them, especially if the company is not very big.
Often, we see that people come to such conferences, listen to Facebook or Yandex and say: “Wow! How many people are doing interesting. They have 20 different technologies used, and they wrote 10 more themselves. ” And then they try to use the same approach in their startup of 10 people, which works, of course, not very well. This is the case where size matters.
Architecture Approaches
Very often we see that the main operational storage and some additional services are used. For example, for caching or full-text search.
Another approach to architecture using different databases is microservices, each of which may have its own database, which is better optimized for the tasks of this particular service. As an example: the main repository can be on MySQL, Redis and Memcache for caching, Elastic Search or native Sphinx for searching. And something like Kafka - to transfer data to the analytics system, which was often done on something like Hadoop.
If we are talking about the main operational storage, we probably have two choices. On the one hand, we can choose relational databases, with the language of SQL. On the other hand, something is non-relational, and then look at the subspecies that are accessed in this case.
If we talk about NoSQL data models, there are also quite a lot of them. The most typical are either key value, or document, or a wide column database. Examples: Memcache, MongoDB, Cassandra, respectively.
Why in this case we compare MySQL and MongoDB? In fact, there are several reasons. If you look at the Ranking databases, we see that MySQL, according to this rating, is the most popular relational database, and MongoDB is the most popular non-relational database. Therefore, it is reasonable to compare them.
I also have the most experience using these two databases. At Percona, we work closely with them, work with many customers, help them make such a choice. Another reason: both technologies are initially focused on developers of simple applications. For those people for whom PostgreSQL is too difficult.
MongoDB was initially very actively focused on MySQL users. Therefore, very often people have experience of using and choosing between these two technologies.
In Percona, besides the fact that we are engaged in support, consulting for these technologies, we have quite a lot of open source software written for both technologies. On the slide you can see. In detail, I will not talk about it.

What follows about me personally: I do MySQL much more than MongoDB. Despite the fact that I will try to provide a balanced overview on my part, I may have some predispositions to MySQL, since I know its cockroaches better.
MySQL and MongoDB selection

Here is a list of different issues that in my opinion it makes sense to consider. Now we will consider each of them in more detail.
What is most important in my opinion is to take into account the experience and preferences of the team. For many problems, both solutions are suitable. They can be done both this way and that way, it can be somewhat more complicated, it can be somewhat easier. But if you have a team that has worked with SQL databases for a long time and understands relational algebra and so on, it can be difficult to drag and force them to use non-relational databases such as MongoDB, where there is not even a full-fledged transaction.
And vice versa: if there is some command that uses MongoDB well, the SQL language can be difficult for it. It also makes sense to consider both the original development and further maintenance and administration, since all this is ultimately important in the application cycle.
What are the advantages of these systems?
If we talk about MySQL, it is a proven technology. It is clear that MySQL has been used by large companies for more than 15 years. Since it uses the SQL standard, it is possible to simply migrate to other SQL databases if you want. There is the possibility of transactions. Complex queries are supported, including analytics. And so on.
From the MongoDB point of view, the advantage is that we have a flexible JSON document format. For some tasks, and for some developers, it is more convenient than to suffer with the addition of columns in SQL databases. No need to learn SQL - for some it is difficult. Simple queries are less likely to cause problems. If you look at performance problems, they mostly arise when people write complex queries with
JOIN in a bunch of tables and GROUP BY . If there is no such functionality in the system, then creating a complex query is more difficult.MongoDB has fairly simple scalability built in using sharding technology. Difficult requests if arise, we usually solve them on the side of the application. That is, if we need to do something like a
JOIN , we can go and select the data, then go and select the data by reference and then process it on the application side. For people who know the language of SQL, it looks somehow miserable and unnatural. But in fact, for many, developing application servers is much easier than dealing with a JOIN .Development Approach and Application Lifecycle
If we talk about applications that use MongoDB, and what they focus on - this is a very fast development. Because everything can be constantly changed, you do not need to constantly take care of a strict document format.
The second point is the data schema. Here you need to understand that data always has a scheme, the only question is where it is implemented. You can implement the data scheme in your application, because in some way you use this data. Or this scheme is implemented at the database level.
Very often, if you have an application, only this application works with the data in the database. For example, we save data from this application to this database. The application level scheme works well. If we have the same data used by many applications, it is very inconvenient, difficult to control.
This also raises the question of the lifetime of the application. With MongoDB, it's good to make applications that have a very limited life cycle. That is, if we make an application that does not live long, for example, a site for launching a movie or an Olympiad. We lived a few months after this, and this application is almost never used. If the application lives longer, then there is another question.
If we talk about the distribution of the advantages and disadvantages of MySQL and MongoDB in terms of the application development cycle, they can be represented as follows:
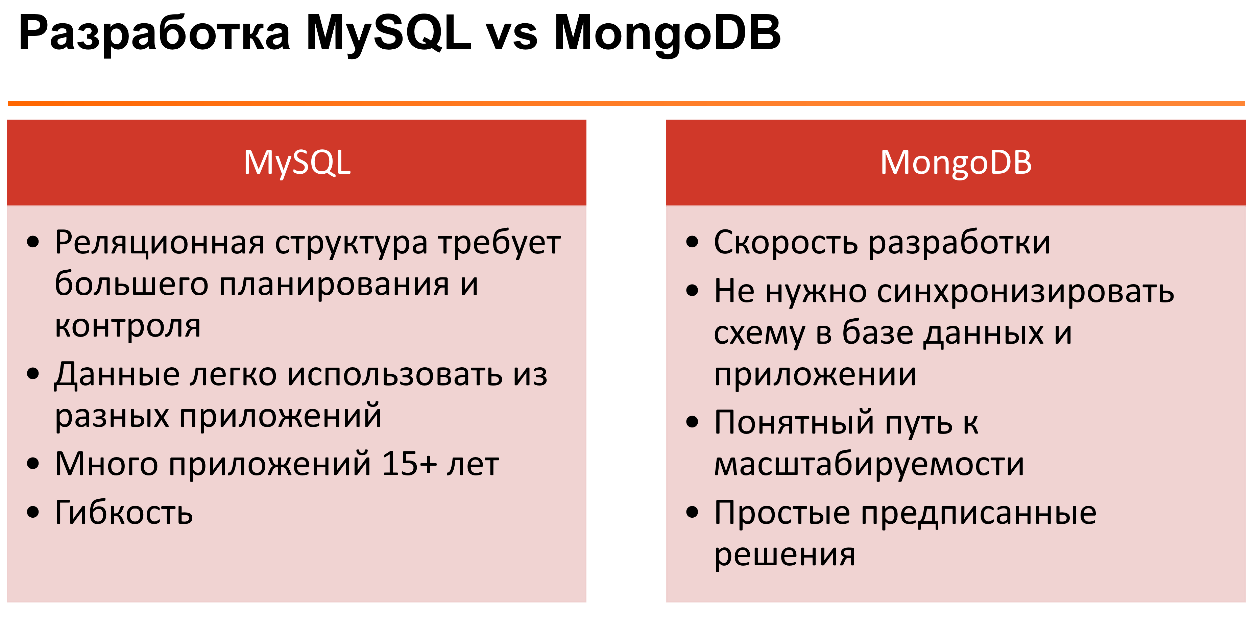
The data model is very dependent on the application and experience of the team. It would be strange to say that we have a relational or non-relational approach to databases better and always better.
If we compare them with each other, it is clear that we have. In MySQL, a relational database. We can easily map relationships between tables using a relational database. By normalizing data, we can make changes to data occur atomically in one place. When our data is denormalized, we don’t need to run and modify a bunch of documents with any changes.
Is it good or bad? The result is always a table. On the one hand, this is simple, on the other - some data structures do not always fit well on a table, we may be inconvenient to work with it.
This is all in theory. If we talk about the practical use of MySQL, we know that we often denormalize the data, sometimes for some applications we use something like this: we store JSON, XML or another structure in the application columns.
In MongoDB, the data structure is document based. The data of many web applications is very simple to display. Because if we store a structure - something like an associated array of an application, then it is very simple and understandable for the developer to be serialized into a JSON document. Laying it out in a relational database on different tables is a non-trivial task.
Results as a list of documents that may have a completely different structure - a more flexible solution.
Example. We want to save the contact list from the phone. It is clear that there are data that fit well into one relational table: Last Name, First Name, etc. But if you look at the phone numbers or email addresses, then one person may have several. If this is stored in a good relational form, then it would be nice for us to store it in separate tables, then collect it all
JOIN , which is less convenient than storing it all in one collection where there are hierarchical documents.
It should be said that this is all in a strictly relational theory - some databases support arrays. MySQL supports a JSON format in which you can stick things like multiple email addresses. Or for many years people have serialized it with pens: we need to save several email addresses, then let's write them separated by a comma, and then the application will figure it out. But somehow it is not very kosher.
Terms
Interestingly, between MySQL and MongoDB - in general, between relational and non-relational DBMS - something is the same, something is different. For example, in both cases we are talking about databases, but what we call a table in a relational database is often called a collection in a non-relational database. That in MySQL - a column, in MongoDB - a field. And so on.
From the point of view of using
JOIN , in MongoDB there is no such thing - it is generally a concept from a relational structure. There, we either make an inline document, which is close to the concept of denormalization, or we simply store the document identifier in some field, call it a link, and then use the pens to select the data we need.As for access: where we use the SQL language for relational data, a standard such as CRUD is used in MongoDB and many other NoSQL databases. This standard says that there are operations for creating, reading, deleting and updating documents.
A few examples.
As we can look at the most typical tasks for working with documents in MySQL and MongoDB:
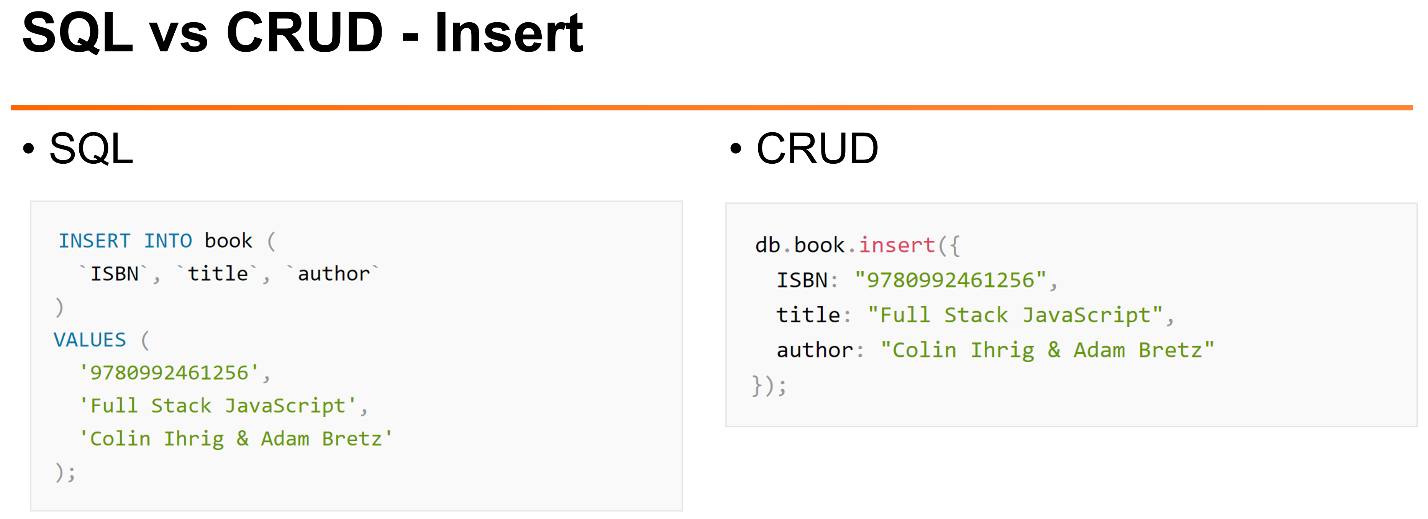
Here is an example insert.
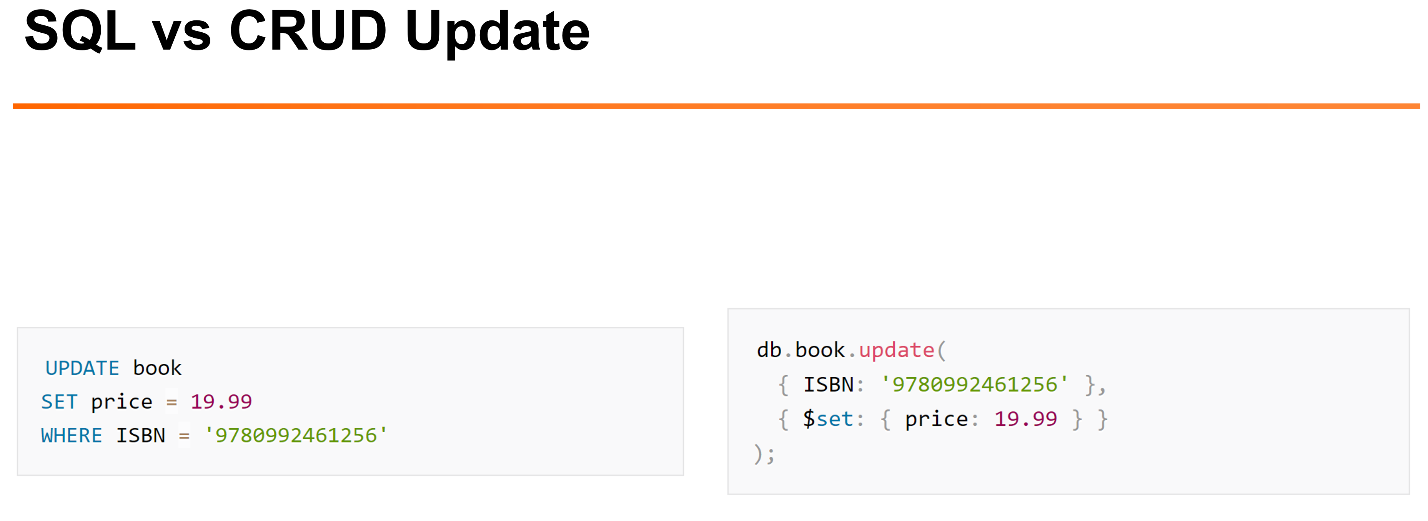
Sample update.
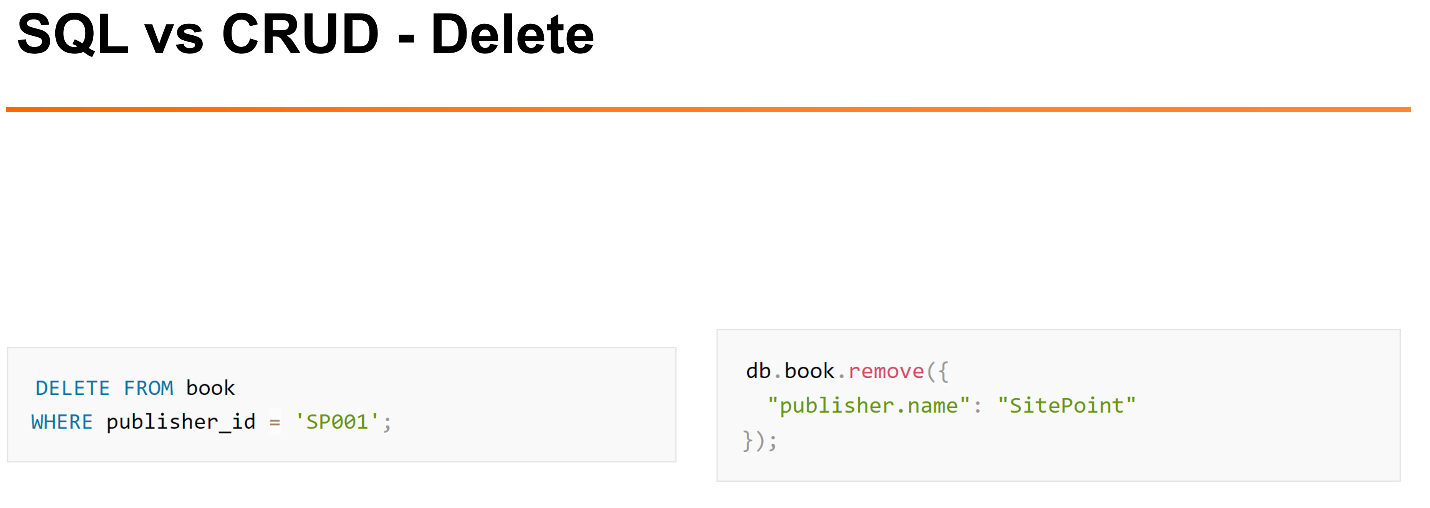
Removal example.
If you are a developer who is familiar with JavaScript, then the syntax CRUD (MongoDB) provides is more natural for you than SQL syntax.
In my opinion, when we have the simplest operations: search, insert, they all work quite well. When it comes to more interesting sampling operations, in my opinion, the SQL language is much more readable.
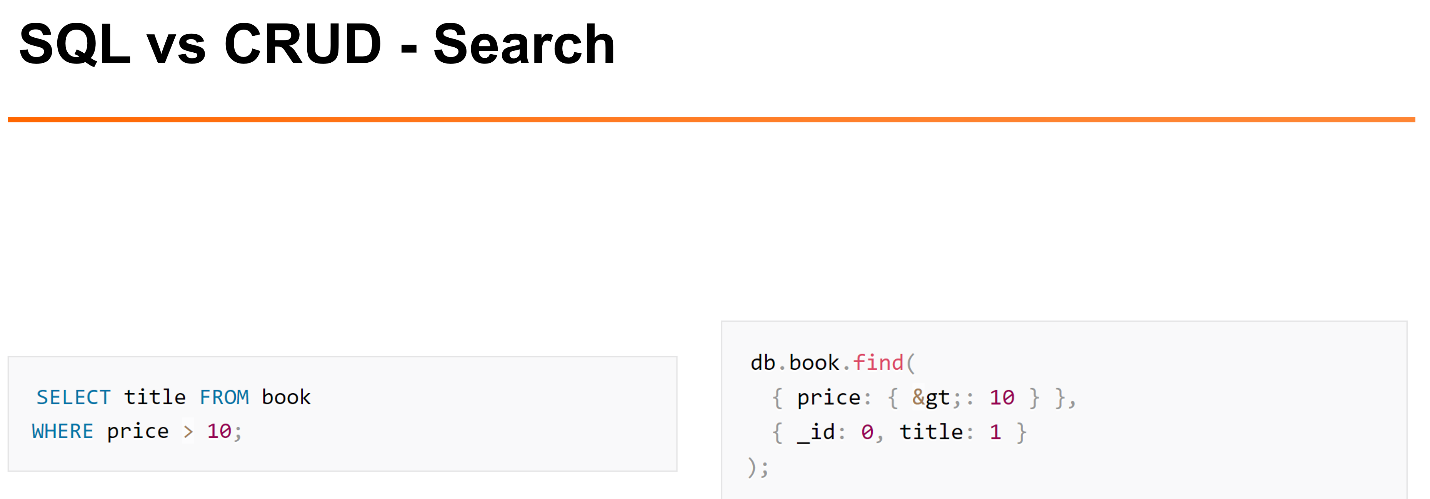
> instead of the simple “>” character. Not very readable, in my opinion.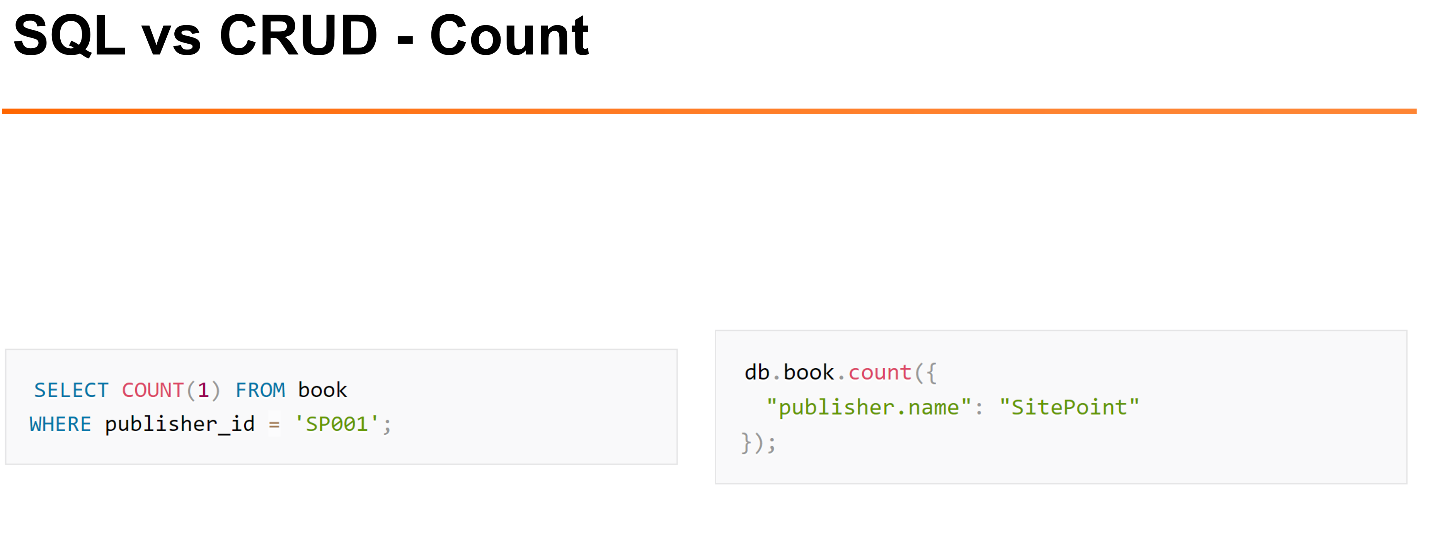
It's easy enough to do things using the interface, such as counting the number of rows in a table or collection.
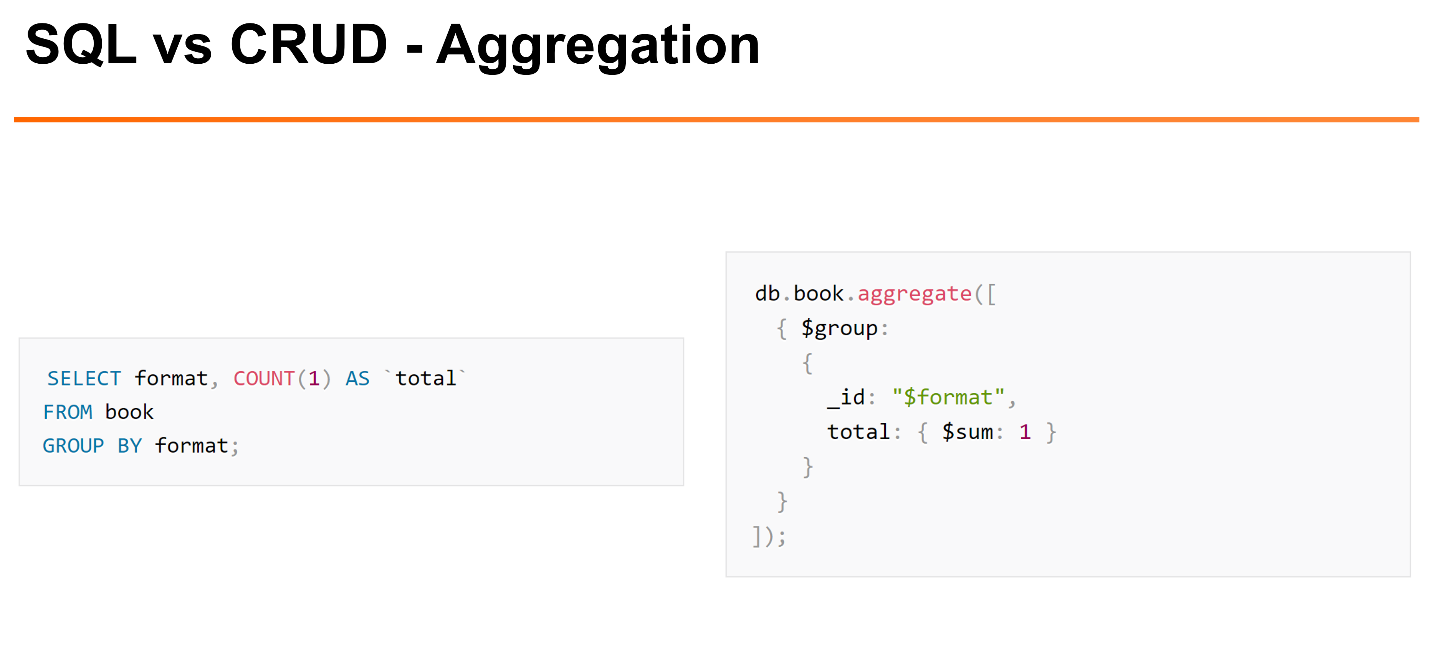
But if we do more complex things, for example,
GROUP BY , in MongoDB, this requires the use of the Aggregation Framework. This is a slightly more complex interface that shows how we want to filter, how we want to group, etc. The Aggregation Framework already supports something like JOIN operations.The next point is transactions and consistency (ACID). If you go and read the MongoDB documentation, there will be: "We support ACID transactions, but with restriction." In my opinion, it is worth saying: "We do not support ACID, but we support other minimum non-transactional guarantees."
What is the difference between them?
If we talk about MySQL, it supports ACID transactions of arbitrary size. We have the atomicity of these transactions, we have multi-versioning, you can choose the level of transaction isolation, which can start with
READ UNCOMMITED and end with SERIALIZABLE . At the node and replication level, we can configure how data is stored.We can configure in InnoDB how to work with a log file: save it to disk when committing a transaction or do it periodically. We can configure replication, enable, for example, Semisynchronous Replication, when we have the data considered as stored only when their copy is received on one of the slaves.
MongoDB does not support transactions, but it supports atomic operations on the document. This means that from the point of view of a single document, our operation will be atomic. If our operation changes several documents, and during this operation some kind of failure occurs inside, some of these documents can be changed, and some of them can not be changed.
Consistency is also done at the document level. In a cluster, we can choose flexible consistency. We can specify what guarantees we want - guarantees that we have data recorded on only one node, or they have been replicated to all cluster nodes. Reading consistency also occurs at the document level.
There is such an update option isolated, which allows you to perform the update in isolation from other transactions, but it is very inefficient - it switches the database to exclusive access mode, so it is used quite rarely. In my opinion, if we talk about transactions and consistency, then MongoDB is quite poor.
Performance
Performance is very difficult to compare directly, because we often make different database schemes, application design. But generally speaking, MongoDB was originally made to scale well to many nodes through sharding, so less attention was paid to efficiency.
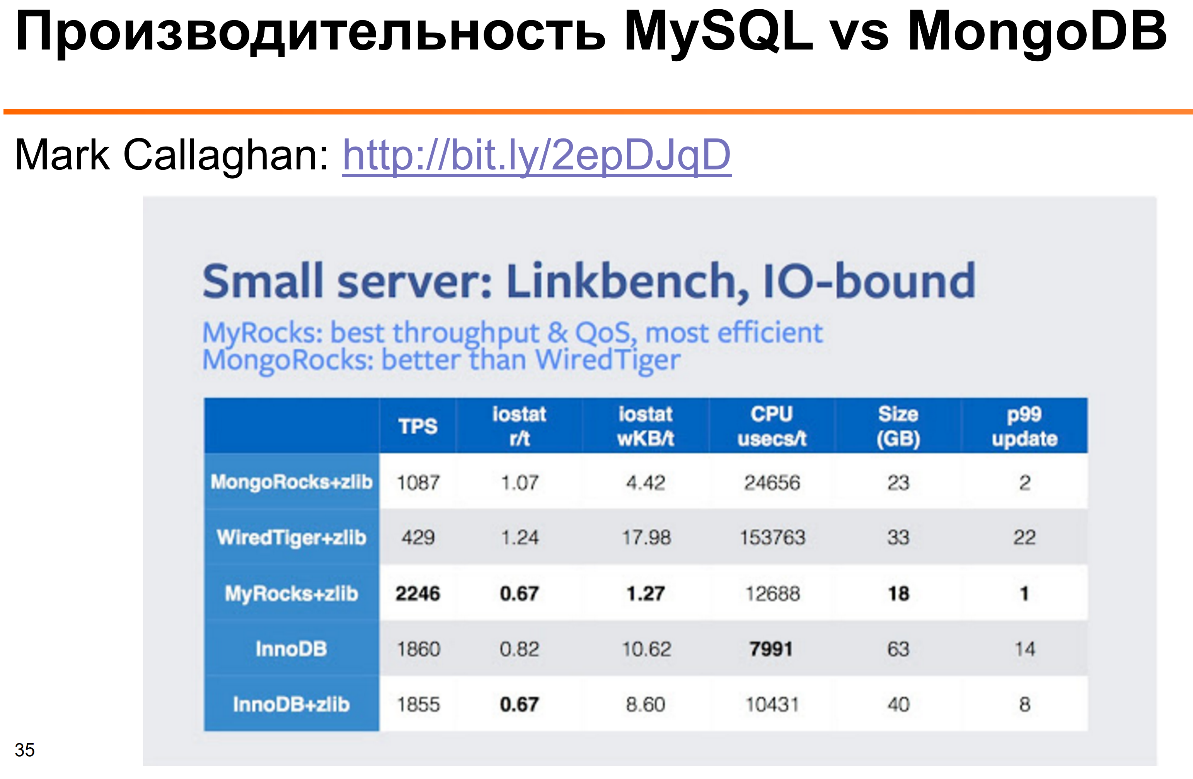
These are the benchmark results that Mark Callaghan did. Here you can see that in terms of processor utilization, MySQL input / output — both InnoDB and MyRocks — use significantly less CPU and disk I / O in the Facebook Linkbench benchmark operation.
Scalable.
What is scalability in this context? How easy it is for us to take our small application and scale it into many millions, maybe even billions of users.
Scalability is different. It is average, within the framework of one machine, when we want to support medium-sized applications, or scalability on a cluster, when our applications are already very large, when it is clear that even one of the most powerful machines cannot cope.
It also makes sense to talk about whether we scale reading, writing or data volume. In different applications, their priorities may vary, but in general, if the application is very large, they usually have to work with all of these things.
MySQL in new versions has very good scalability within a single node for LTP loads. If we have small transactions, there is some kind of hardware with 64 processors, it scales well enough. Analytics or complex queries do not scale well because MySQL can use only one stream for one query, which is bad.
Traditionally, reading in MySQL is scaled with replication, writing and data size is via sharding. If you look at all the big companies - Facebook, Twitter - they all use sharding. Traditionally, MySQL sharding is used manually. There are some frameworks for this. For example, Vitess is a framework that Google uses for scaling the YouTube service, they released it in open source. Prior to this was the framework Jetpants. MySQL does not offer a standard solution for sharding, often switching to sharding requires attention from developers.
In MongoDB, the focus was initially on scalability on many nodes. Even in cases with a small application, many people recommend using sharding from the very beginning. Maybe just a couple of replica set, then you will grow with your application.
In MongoDB Sharding, there are some limitations: not all operators work with it, for example, there is a isolated option to ensure consistency. It does not work if you use sharding. But at the same time, many basic operations work well in sharding, so people are allowed to scale-up applications much better. In my opinion, sharding and generally replication in MongoDB are made much better than MySQL, it is much easier to use for the user.
Administration
Administration is all those things that developers do not think about. At least first. Administration - this is what we have to back up the application, update versions, monitor, recover from failures, and so on.
MySQL is quite flexible, it has many different approaches. There are good open source implementations of everything, but this multitude of options begets complexity. I often communicate with users who are just starting to learn MySQL. They say: “Yolki-sticks, how many options do you have. That's just replication - which one should I use: statement replication, raw replication, or mix? And then there is gtid and standard replication. Why can't you say "just work"? "
In MongoDB, it is increasingly focused on the fact that it works in one standard way - there is a minimization of administration. But it is clear that this happens when flexibility is lost. The open source community for MongoDB is much smaller. From the point of view of recommendations, many things in MongoDB are rather tightly tied to Ops Manager, the commercial development of MongoDB.
Myths
Both MongoDB and MySQL have myths that have been fixed in the past, but people have good memory, especially if something is not working. I remember that after ten transactions with InnoDB appeared in MySQL, people for ten years said to me: “Are there no transactions in MySQL?”
MongoDB had many different MMAP storage engine performance problems: giant locks, inefficient use of disk space. Now in the standard WiredTiger engine there are no many of these problems. There are other problems, but not these.
“No control circuit” - still such a myth. In new versions of MongoDB, it is possible to define for each collection on a JSON structure, where the data will be validated. The data that we are trying to insert, and they do not correspond to some format, you can throw.
“No
JOIN analog” - the same. In MongoDB it appeared, but a few limited things. Only at the level of one shard and only if we use the Aggregation Framework, and not in standard queries.What are our myths in mysql? Here I will talk more about the support of NoMySQL solutions in MySQL, I will talk about this tomorrow. It should be said that now MySQL can also be used via the CRUD interface, used in NoSQL mode, similar to MongoDB.
A typical example where a MySQL solution is used is an e-commerce site. When we have a question about money, we often want full-fledged transactions and consistency. For such things, the relational structure that has been worked out is well suited, and commerce on relational databases has been done for many decades. So you can take one of the ready-made approaches to the data structure and use it.
Usually, from the point of view of e-commerce, the amount of data we have is not so large, so even quite large stores can work for a long time without sharding. Our applications are constantly being developed and improved over the years. And this application has many components that work with the same data: someone is counting on where to change prices, someone else is doing something.
MongoDB is often used as a backend of large online games. Electronic Arts uses MongoDB for so many games. Why? Because scalability is important. If a game shoots well, it has to be scaled significantly more than expected.
On the other hand, if it does not fire, we would like the infrastructure to be reduced. In many games it goes like this: we started the game, it has a peak, we have to make a large cluster. Then the game is already coming out of popularity, for it the backend needs to be compressed, saved and used. In this case, there is one application (game), the database, on the one hand, is simple, on the other - strongly attached to the application, which stores all the parameters important for the game.
Often, database consistency at the object level is sufficient here, because many consistency issues are solved at the application level. For example, data of one player saves only one application service.
Additional Information
I recommend this old, old, but very funny video to http://www.mongodb-is-web-scale.com/ [ YouTube ]. On it we will finish.
MySQL and MongoDB - when is it better to use?
Source: https://habr.com/ru/post/322532/
All Articles