Vertica + Anchor Modeling = start growing your mycelium
Some time ago I wrote an article on Habré . It also promised to continue in a couple of weeks. But, as you know, they have been waiting for the promised three years - and indeed, three years have passed since then. If you do not remember from the time of that article, then I remind you - I work in Avito, I build a repository based on Vertica.
From what has changed - now I can not just write an article, but do it in a company blog. And, I hope, not once. Self-PR is over, now to the point.

My repository is based on the Anchor Modeling methodology. In 2013, this choice of methodology was, in many ways, a leap of faith. Now, after almost 4 years, we can say that the jump was a success. The first article gave quite a lot of arguments for Anchor Modeling. Now these arguments remained true, but faded into the background.
Today, the main argument for using Anchor Modeling + Vertica is one: almost unlimited growth is possible. Growth in volume, rate of receipt and in diversity - all that is called 3V (Volume, Velocity, Variety), and that characterizes big data.
')
Imagine that your vault is a little mycelium. It starts with one dispute, and then begins to grow, covering meter by meter, twining the trees until a multi-ton monster turns out ... whose growth does not stop ... does not stop at all.
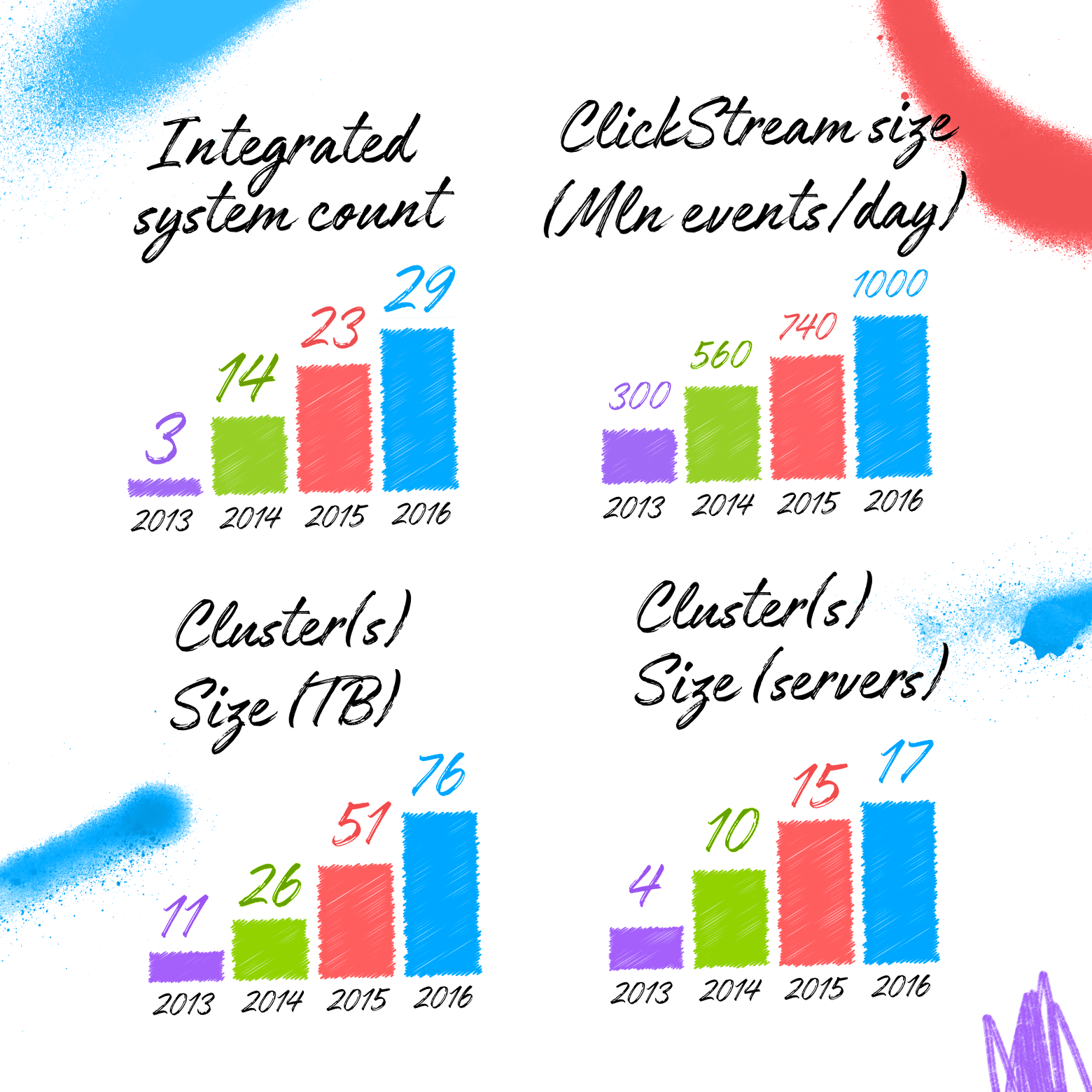
Imagine yourself in the place of the repository architect. It is good when you can estimate at the start the approximate data volumes, integrable systems, data analysis algorithms. Then you can choose the data model and processing platform for your situation. And not the fact that in this case, the choice of Vertica + Anchor Modeling will be optimal.

Anchor is a noun, a real-world object. Item, user, payment. Accordingly, each noun has its own table. Anchor table should store ONLY a surrogate key (in Vertica, the best key is an int ) and several technical fields. Conceptually, Anchor is only needed for one task - to load each unique product / user / payment only once. Avoid reloading, and remember at what point and from which system the original entry came. Everything.
To understand how the task of identifying the product / user / payment is solved, go to the second entity.

Attribute is a table for storing a property, an attribute of an object. Names of goods, username and date of birth of the user, the amount of payment. One property of the object is one Attribute table. The ten properties of the object (name, surname, date of birth, gender, registration address, ...) - ten Attribute tables. It's simple. It is difficult for the psyche, because the number of tables at the beginning is very scary, but simple.
Each Attribute-table contains a surrogate key of the object, which is a link to the corresponding Anchor, a field for the attribute value, and, optionally, a date for historicity and technical fields. Accordingly, the Attribute-table for the name (Name) of the buyer (Customer) should be called S_Customer_Name and contain the fields Customer_id (surrogate key), Name (attribute value) and Actual_date (date for SC2 historicity). As you can see, the name of the table and the names of all its fields are uniquely determined by its contents (the name of the buyer).
What nuance adds Vertica? ... Everything is simple, all Attribute tables for one Anchor must be identically segmented : segmented by the surrogate key hash, sorted by the surrogate key and by the date of historicity. A simple rule, following which, you will receive a guarantee that all the join between Attribute-tables of one Anchor will be MERGE JOIN - the most efficient join in Vertica. Similarly, the specified segmentation ensures the optimality of the window functions necessary for maintaining ETL operations with SC2 historicity on a single date.
In the previous section, a description of the approach to identifying objects was announced: a string of data about the user arrives - how to understand, is this user already in Anchor, or is he new? Naturally, the answer to this question is sought in the attributes. The main advantage of Anchor Modeling is the ability to use some attributes first (full name), and then start using other attributes (full name + TIN). And taking into account the historicity.

Tie is a table for storing links between objects. For example, a table for storing the fact that the buyer has citizenship in a particular country. Accordingly, the table should contain the surrogate key of the left object (customer_id), the right object (country_id) and, if necessary, the date of historicity and technical fields.
From the point of view of Vertica, the following nuance is added - the Tie table should be created with two projections - segmented along the left surrogate and segmented along the right surrogate. So that at least one of the JOINs of this table was a MERGE JOIN.
An important nuance from the point of view of simulations - Anchor Modeling is very different from Data Vault in that in Data Vault you can hang data (satellites) on a link (link), and in Anchor Modeling data (Attribute) can be hung only on Anchor, on Tie it is impossible ( important - DO NOT). This seemingly redundant constraint allows you to more accurately model the real physical world. For example, the traditional connection with properties in the Data Vault is the fact that a product is sold to a customer whose property is the amount of the sale. Anchor Modeling makes you think a little and understand that the fact of selling a product to a customer is not an element of the real world, but an abstraction. An element of the real world is a check (piece of paper) with a number, date, etc. Accordingly, in Anchor the described example is described by three Anchor - Buyer, Check, Item, and two Tie: Buyer-Check and Check-Item.
(An attentive reader will notice that even the example picture at the beginning of the section is not entirely correct. The fact of citizenship is recorded by a certain document (passport), and it is more accurate to present the specified data through Anchor with a passport).
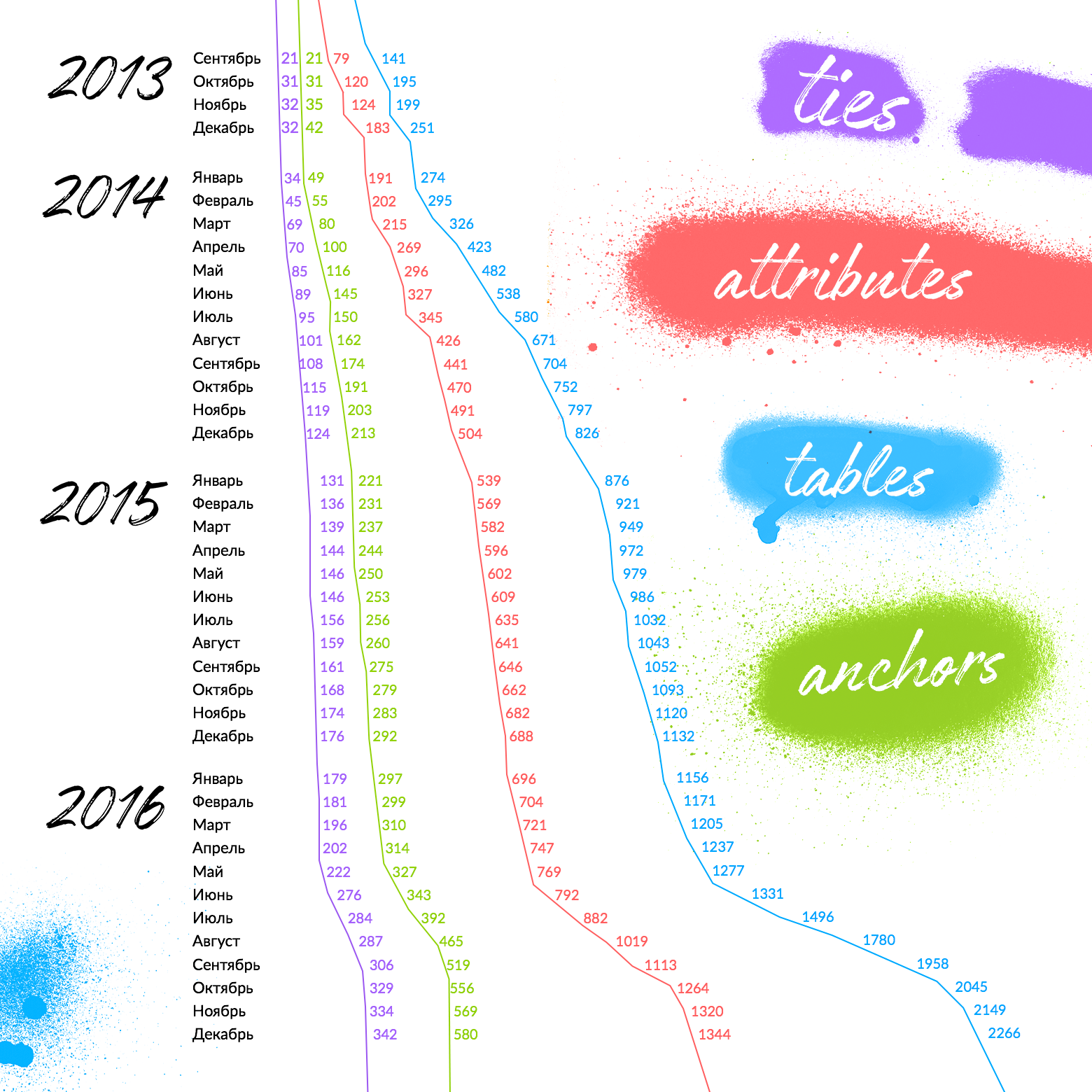
When you first read about Anchor Modeling, it becomes scary.
Scary to drown in the tables. Fear is fair, it is important not to stop it. The above illustration shows the growth rate of the amount of each type of table in Avito over 4 years (the right graph is the total amount of Anchor + Attribute + Tie).
Let me remind you the first graph in the article - Avito storage at the end of 2016 included data from more than 29 source systems. As you can see, there are many tables. But not terribly much. It can be said that a large jump in the number of tables occurs at the beginning, and then, due to the increasing reuse of old tables, the growth rate decreases. The sharp jump in the number of tables at the end of 2016 is due to the connection of an unusually large number of new systems and demonstrates that, despite the size of the system, it is still capable of expanding.
The second reason to fear a large number of tables is the complexity of the analysis from external analysts.
On the way to deal with such fears, I will discuss in the next article. I hope this time it will not have to wait for another three years :) In the meantime, you can study the records of my speeches on the topic at seminars , conferences and webinars .
Ps. Lars has completed his online course for those who want to understand the nuances of Anchor Modeling.
anchor.teachable.com/courses/enrolled/124660 . Recommend. There's even one video about Avito's case :).
From what has changed - now I can not just write an article, but do it in a company blog. And, I hope, not once. Self-PR is over, now to the point.
My repository is based on the Anchor Modeling methodology. In 2013, this choice of methodology was, in many ways, a leap of faith. Now, after almost 4 years, we can say that the jump was a success. The first article gave quite a lot of arguments for Anchor Modeling. Now these arguments remained true, but faded into the background.
Today, the main argument for using Anchor Modeling + Vertica is one: almost unlimited growth is possible. Growth in volume, rate of receipt and in diversity - all that is called 3V (Volume, Velocity, Variety), and that characterizes big data.
')
Imagine that your vault is a little mycelium. It starts with one dispute, and then begins to grow, covering meter by meter, twining the trees until a multi-ton monster turns out ... whose growth does not stop ... does not stop at all.
Imagine yourself in the place of the repository architect. It is good when you can estimate at the start the approximate data volumes, integrable systems, data analysis algorithms. Then you can choose the data model and processing platform for your situation. And not the fact that in this case, the choice of Vertica + Anchor Modeling will be optimal.
Essence One - Anchor
Anchor is a noun, a real-world object. Item, user, payment. Accordingly, each noun has its own table. Anchor table should store ONLY a surrogate key (in Vertica, the best key is an int ) and several technical fields. Conceptually, Anchor is only needed for one task - to load each unique product / user / payment only once. Avoid reloading, and remember at what point and from which system the original entry came. Everything.
To understand how the task of identifying the product / user / payment is solved, go to the second entity.
Essence Two - Attribute
Attribute is a table for storing a property, an attribute of an object. Names of goods, username and date of birth of the user, the amount of payment. One property of the object is one Attribute table. The ten properties of the object (name, surname, date of birth, gender, registration address, ...) - ten Attribute tables. It's simple. It is difficult for the psyche, because the number of tables at the beginning is very scary, but simple.
Each Attribute-table contains a surrogate key of the object, which is a link to the corresponding Anchor, a field for the attribute value, and, optionally, a date for historicity and technical fields. Accordingly, the Attribute-table for the name (Name) of the buyer (Customer) should be called S_Customer_Name and contain the fields Customer_id (surrogate key), Name (attribute value) and Actual_date (date for SC2 historicity). As you can see, the name of the table and the names of all its fields are uniquely determined by its contents (the name of the buyer).
What nuance adds Vertica? ... Everything is simple, all Attribute tables for one Anchor must be identically segmented : segmented by the surrogate key hash, sorted by the surrogate key and by the date of historicity. A simple rule, following which, you will receive a guarantee that all the join between Attribute-tables of one Anchor will be MERGE JOIN - the most efficient join in Vertica. Similarly, the specified segmentation ensures the optimality of the window functions necessary for maintaining ETL operations with SC2 historicity on a single date.
In the previous section, a description of the approach to identifying objects was announced: a string of data about the user arrives - how to understand, is this user already in Anchor, or is he new? Naturally, the answer to this question is sought in the attributes. The main advantage of Anchor Modeling is the ability to use some attributes first (full name), and then start using other attributes (full name + TIN). And taking into account the historicity.
Essence Three - Tie
Tie is a table for storing links between objects. For example, a table for storing the fact that the buyer has citizenship in a particular country. Accordingly, the table should contain the surrogate key of the left object (customer_id), the right object (country_id) and, if necessary, the date of historicity and technical fields.
From the point of view of Vertica, the following nuance is added - the Tie table should be created with two projections - segmented along the left surrogate and segmented along the right surrogate. So that at least one of the JOINs of this table was a MERGE JOIN.
An important nuance from the point of view of simulations - Anchor Modeling is very different from Data Vault in that in Data Vault you can hang data (satellites) on a link (link), and in Anchor Modeling data (Attribute) can be hung only on Anchor, on Tie it is impossible ( important - DO NOT). This seemingly redundant constraint allows you to more accurately model the real physical world. For example, the traditional connection with properties in the Data Vault is the fact that a product is sold to a customer whose property is the amount of the sale. Anchor Modeling makes you think a little and understand that the fact of selling a product to a customer is not an element of the real world, but an abstraction. An element of the real world is a check (piece of paper) with a number, date, etc. Accordingly, in Anchor the described example is described by three Anchor - Buyer, Check, Item, and two Tie: Buyer-Check and Check-Item.
(An attentive reader will notice that even the example picture at the beginning of the section is not entirely correct. The fact of citizenship is recorded by a certain document (passport), and it is more accurate to present the specified data through Anchor with a passport).
Total - 4 years with Anchor Modeling
When you first read about Anchor Modeling, it becomes scary.
Scary to drown in the tables. Fear is fair, it is important not to stop it. The above illustration shows the growth rate of the amount of each type of table in Avito over 4 years (the right graph is the total amount of Anchor + Attribute + Tie).
Let me remind you the first graph in the article - Avito storage at the end of 2016 included data from more than 29 source systems. As you can see, there are many tables. But not terribly much. It can be said that a large jump in the number of tables occurs at the beginning, and then, due to the increasing reuse of old tables, the growth rate decreases. The sharp jump in the number of tables at the end of 2016 is due to the connection of an unusually large number of new systems and demonstrates that, despite the size of the system, it is still capable of expanding.
The second reason to fear a large number of tables is the complexity of the analysis from external analysts.
On the way to deal with such fears, I will discuss in the next article. I hope this time it will not have to wait for another three years :) In the meantime, you can study the records of my speeches on the topic at seminars , conferences and webinars .
Ps. Lars has completed his online course for those who want to understand the nuances of Anchor Modeling.
anchor.teachable.com/courses/enrolled/124660 . Recommend. There's even one video about Avito's case :).
Source: https://habr.com/ru/post/322510/
All Articles