The first way to generate collisions for SHA-1

Collisions exist for most hash functions, but for the best of them, the number of collisions is close to the theoretical minimum. For example, for ten years since the invention of SHA-1, not a single practical method of generating collisions was known. Now there is one. Today, the first algorithm for generating collisions for SHA-1 was presented by employees of Google and the Center for Mathematics and Computer Science in Amsterdam.
Here's the proof: two PDF documents with different content, but the same SHA-1 digital signatures.
')
$ls -l sha*.pdf -rw-r--r--@ 1 amichal staff 422435 Feb 23 10:01 shattered-1.pdf -rw-r--r--@ 1 amichal staff 422435 Feb 23 10:14 shattered-2.pdf $shasum -a 1 sha*.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf On the website shattered.it, you can check any file to see if it is in the space of possible collisions. That is, is it possible to select another data set (file) with the same hash. The attack vector is clear here: an attacker can spoof a “good” file with his own instance with a bookmark, a malicious macro, or a Trojan downloader. And this “bad” file will have the same hash or digital signature.
Cryptographic hash functions like SHA-1 is a universal cryptographic tool that is commonly used in practical applications. They are needed when building associative arrays, when searching for duplicates in data sets, when building unique identifiers, when calculating checksums for error detection. For example, SHA-1 hashes are completely relied upon by the Git software version control system.
But more importantly, hashing is critical in the field of information security: it is used when saving passwords, when generating an electronic signature, etc. In general, hash functions convert any large data array into a small message.
Given the ubiquitous distribution of hash functions, a very important requirement is the minimum number of collisions when two different blocks of input data are converted into two identical hashes.
In an official report, the authors say that this finding was the result of a two-year study, which began shortly after the publication in 2013 of the work of cryptographer Mark Stevens from the Center for Mathematics and Computer Science in Amsterdam on the theoretical approach to creating SHA-1 collision. He further continued the search for practical methods of hacking, along with colleagues from Google.
Google has long expressed its disbelief in SHA-1, especially in the quality of using this feature to sign TLS certificates. Back in 2014, shortly after the publication of the work of Stevens, the Chrome development team announced a phasing out of the use of SHA-1. Now they hope that a practical attack on SHA-1 will increase the awareness of the information security community, so that many will speed up the abandonment of SHA-1.
Experts began searching for a practical attack method by creating a PDF prefix specially selected for generating two documents with different content, but with the same SHA-1 hash.

PDF prefix
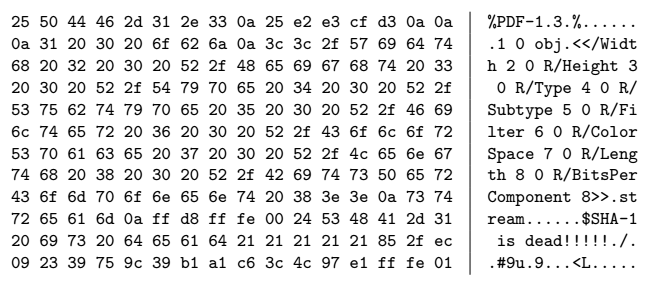
Identical prefix for collisions based on Google infrastructure
They then used Google’s infrastructure to perform calculations and test theoretical calculations. Developers say it was one of the largest calculations Google ever performed. In total, nine quintillion calculations of SHA-1 (9,223,372,036,854,775,808) were made, which required 6,500 processor years in the first phase and 110 years in the GPU in the second phase of the attack.
The numbers seem large, but in fact such an attack is quite practical for an attacker who has a large computer cluster or just money to pay for processor time in the cloud. According to Google, the attack is about 100,000 faster than brute force, which can be considered impractical.
To imagine the number of hashes that Google cheated during brute force, we can mention that about the same number of hashes SHA-256 is counted in the Bitcoin network every three seconds, so there’s nothing fantastic about the attack. It is possible to assume that in the cryptographic departments of some organizations with large data centers , SHA-1 collisions have long been calculated. However, to pick a collision for a specific TLS certificate, you need some other method, because an identical prefix from Google’s research for PDF will not work there. On the other hand, the contents of the certificates largely coincide, so that theoretically a prefix for collisions can be chosen.
Now Mark Stevens and co-authors have published a scientific paper in which they describe the general principles of generating documents with message blocks that are prone to SHA-1 collisions.
Message blocks that are prone to SHA-1 collisions
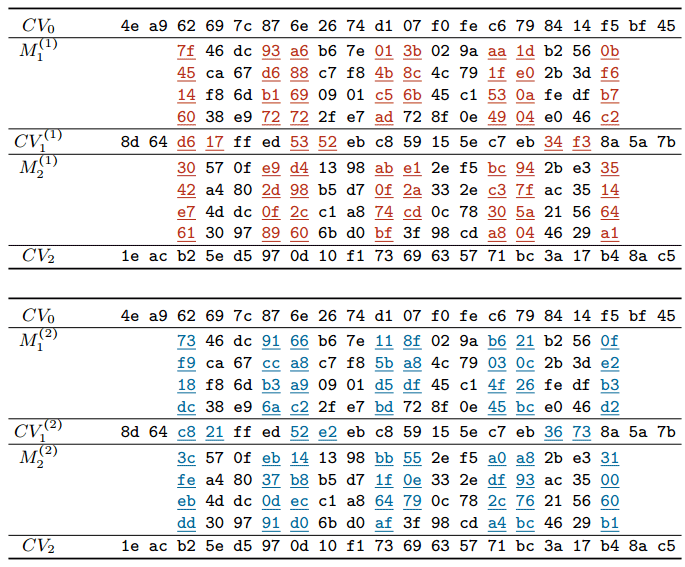
In accordance with the accepted rules for disclosing vulnerabilities, Google promises to publish the full code for the attack in 90 days in open access. Then anyone can create different documents with the same SHA-1 digital signatures. Maybe even different certificates, different software updates in Git, different distributions on torrents (DHT hashes), different old PGP / GPG keys, etc. However, one should not exaggerate the danger of such attacks, because not every document will be subject to an attack on the search for a collision. That is, the attacker will have to initially create two files: one “good” and the second “bad” with the same signature. Then distribute a “good” document through normal channels (for example, via Git or a torrent tracker), and later try to replace it with a “bad” file with the same digital signature. However, all this is purely theoretical reasoning.
Protection against documents prone to collisions hashes SHA-1 is already built into the software Gmail and GSuite. As mentioned above, the detector of vulnerable documents works in the public domain on the website shattered.io . In addition, a library for collision detection is published on Github .
As a defense against the SHA-1 collision detection attack, Google recommends switching to higher-quality cryptographic hash functions SHA-256 and SHA-3.
Source: https://habr.com/ru/post/322478/
All Articles