Training with reinforcements: from Pavlova to slot machines
The history of training with reinforcements, depending on how you count, ranges from a century and a half to 60 years. The last wave (which now overwhelms us all) began with the rise of the whole machine learning in the mid-90s of the 20th century. But people who are now on the crest of this wave started by itself not now, but during the previous surge of interest - in the 80s. In the process of exploring the story, we will meet many characters who played a role in the development of the teachings on artificial intelligence (which we discussed in the last article ). Of course, this is not surprising, because reinforcement training is an integral part of it. Although about everything in order.
The name “learning with reinforcement” is taken from the works of the famous Russian physiologist, Nobel laureate Ivan Petrovich Pavlov. In 1923, his work “Twenty years of experience in objectively studying the higher nervous activity (behavior) of animals” [1], known in the west as Conditional Reflexes [2], came out. But psychological approaches were known before.
Physiological studies
In addition to Pavlov, who gave the name of the region, several works from physiology are worth mentioning, for example, the work of Peter Kuzmich Anokhin in 1948 [3], the successor of Pavlov’s scientific school, Ross Ashby (W. Ross Ashby) 1952 “Brain architecture” [4 ]. In the future, these works influenced the second wave of interest in reinforcement training, in particular, the work of Harry Klopf (Harry Klopf).
Psychological origins
The main psychological idea that is used in training with reinforcement is the trial and error method. He was proposed by the scientist and philosopher Alexander Bain in 1855 in the book “Feeling and Intellect” [5]. Explaining the emergence of voluntary movements, Ban introduces an idea of the spontaneous activity of the nervous system, the manifestation of which are spontaneous movements. When a movement more than once coincides with a state of pleasure, the holding power of the spirit establishes associations between them. This idea will be developed not only in psychology, but also later in the subject of this article - training with reinforcement. Lloyd Morgan (Conway Lloyd Morgan) - a renowned 19th century psychologist, author of his own canon - developed this idea, in particular, in his fundamental work “Habit and Instinct” [6]. The canon of Lloyd Morgan says that “this or that action cannot in any way be interpreted as the result of the manifestation of any higher mental function, if it can be explained on the basis of the animal’s ability to take a lower level on the psychological scale,” which allows unconditioned reflexes from conscious activity (in modern exposition) and learned behavior. This is more clearly expressed by Edward Lee Thorndike in his writings on the intelligence of animals [7]. He derived the so-called “law of effect”: a useful action that causes pleasure reinforces and strengthens the connection between the situation and the reaction, and the harmful, causing displeasure weakens the connection and disappears. The law of effect formed the basis of many investigations afterwards, of which it is worth highlighting the work of behaviorists - the “theory of learning” by Clark L. Hull [8] and the experiments of Burres Frederic Skinner (Burrhus Frederic Skinner), in particular his work “The Concept of Reflex in the description of behavior "[9].
Electro-mechanical sales
The idea of implementing a trial and error method in hardware can be considered one of the earliest attempts to create artificial intelligence. In 1948, Alan Turing gave a report where he described the architecture of the system of “pain and pleasure” (rewards and punishments) [10]:
“When the system comes to a state where the action is not defined, a random selection is made for the missing data, a preliminary record is made of how to act, and the action is taken. If a painful stimulus arises, all preliminary recordings are erased, and if a pleasure stimulus arises, then they are made permanent. ”
Many machines have been made, demonstrating this approach. The earliest - the machine of Thomas Ross (Thomas Ross) of 1933 could go through a simple maze and remember the sequence of switches [11]. In 1952, Claude Shannon demonstrated a labyrinth [12] that ran a mouse named Theseus - it was a mechanism that moved through the labyrinth using three wheels and a magnet on the reverse side of the labyrinth, he could memorize the path through the labyrinth, thus exploring trial and error.

More details can be found in this video .
In his thesis [13], Marvin Minsky (1954) presented computational learning models with reinforcement, and also described an analog computing machine built on elements that he called SNARC - a stochastic calculator, trained through reinforcement similar to a neuron. These elements had to correspond to changeable semantic links in the brain. In general, the emergence of such electro-mechanical machines opened the way to writing programs for digital computers capable of different types of training, some of which were capable of learning by trial and error. Farley (Farley) and Clark (Clark) in 1954 described a digital model of a neural network, which was trained by this method [14]. But already in 1955 their interests shifted to the field of pattern recognition and generalization, that is, to the field of training with a teacher. This marked the beginning of a confusion between these two types of training (with reinforcement and with the teacher). For example, Rosenblatt (1962) [15], when creating the perceptron, was clearly guided by reinforcement training, using the terms of reward and punishment to describe, but nevertheless it was obviously training with a teacher. In the 60s, reinforcement training was a popular engineering idea. Particularly noteworthy was the work of Marvin Minsky of 1961, “Towards Artificial Intelligence” that influenced many [16]. It discusses such concepts as prediction, expectation, and what Minsky calls the problem of “finding the culprit” for complex systems of trainees through reinforcement: how to determine the significance of each of the chain of decisions that led to the current state? Many of the proposed approaches have not lost their relevance today.
Another pillar of origins is management theory.
In addition to the psychological approach, the approach of mathematical programming developed independently. Hence the term “optimal control”, it was introduced in the late 1950s to describe the problem of controlling the behavior of a dynamic system in time. One approach to this problem was formulated in the mid-1950s by Richard Bellman (together with colleagues) [17], who basically extended the ideas of 19th-century mathematicians William Hamilton and Karl Jacobi. This approach uses the concept of system state and the value function, otherwise the optimal return function is used to define a functional equation often called the Bellman [optimality] equation. The class of methods for solving problems of an optimal equation eventually became known as dynamic programming. In 1957, Bellman introduced the discrete stochastic version of the problem of optimal control, known as the Markov Decision Making Process (MDP), named after the Russian mathematician Andrei Andreyevich Markov, the author of the concept of the Markov process. In 1960, Ronald Howard proposed an iteration method for strategies for the MDP [18].
Second wave
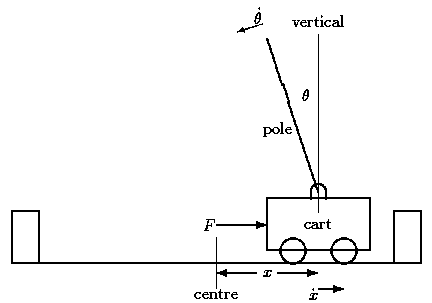
In 1968, Donald Michie (during World War II, he, like Alan Turing, worked as a cryptographer) and R. A. Chambers presented their version of the problem of balancing a pole on the platform (you can look at the title picture of the post) in “BOXES: Experiment in a controlled environment ”[19]. This task was put into the title for a reason, a lot of works of the 70s and 80s, for example, Andrew Barto and Rich Sutton [20], suggested a solution in this environment. Saton and Barto are the same people who, after 15 years, at the end of the 90s, will release their own classic textbook on learning with reinforcement [21]. Michie consistently advocated the importance of trial and error and learning as necessary components of artificial intelligence. Widrow, Gupta and Maitra (Widrow, Gupta, Maitra) in 1973 presented a work modifying the well-known least squares method to create a rule that was trained on the signals of success and failure instead of teaching examples [22]. They described this type of teaching as teaching with a critic, instead of teaching with a teacher. They showed that with the help of this rule you can learn the program to play blackjack.
A series of works by Mikhail Lvovich Tsetlin, Soviet biophysics and mathematics, according to the theory of mass service in the 1960s, was the impetus for the creation of the theory of multi-armed gangsters (by analogy with the “one-armed gangster” - a casino gaming machine), see for example [23]. In 1975, John Holland, an economist, not a psychologist, proposed a general theory of adaptive systems based on the principles of selection [24]. His goal was to get closer to the behavior of real economic agents; in 1976 and more fully in 1986, he introduced systems, trained through reinforcements, able to study associations and make choices. His systems included genetic algorithms, which as such cannot be considered related to learning with reinforcement, but the whole system is still possible (learning through evolution).
Perhaps the brightest scholar who contributed to the revival of interest in reinforcement training was Harry Klopf. He was the first to point out that important aspects of adaptive learning are lost in learning with a teacher. For example, the so-called hedonistic aspect: what the agent wants to get from the environment in the learning process. It was he, as well as his graduate students Barto and Sutton, who pointed out the difference in reinforcement and teacher training. In 1972, Klopf [25] described learning over time, based on his experience in studying the learning process in animals. Parallel Kuzmich Anokhin conducted similar research in many respects in the Soviet Union [26]. In 1981, Sutton and Barto proposed an architecture based on this principle [27]. In the same 1981, their architecture appeared “actor-critic” [28]. Somewhat earlier, in 1977, Ian Witten [29] published an unnoticed work [29], where the principle of learning over the course of time was applied to reinforcement training for the first time. What is important, in this work, TD-training was used to solve the MDP. What brought together the work on the theory of management and psycho-physiological work on learning. Finally, in 1989, Chris Watkins (Chris Watkins) completed this merger by offering Q-learning [30]. Well, that's all, we are ready for the present: it seems that all important concepts have already been invented. Of course, it is impossible to cover all the important work in the framework of the article, but now the reader is prepared to accept the current state of science in this field.
Modernity
In 2013, the DeepMind article (then still a small research company) published an article about training with reinforcement at Atari games [31]. Since then, a real boom of training has begun with reinforcements, a review of recent works in the form of lectures from young researchers (for example, Alexey Dosovitsky, who won the VizDoom competition) to veterans (the same Andrew Barto) on our youtube channel . By the way, in parallel with the school where the lectures were held, we conducted a hackathon on the topic of training with reinforcements, where the results also slightly moved the state of the art in complex Atari games. Participants of the hackathon will talk about their approaches this Saturday (February 25) at a Machine Learning training session .
- Pavlov I.P. Twenty years of experience in objective study of higher nervous activity (behavior) of animals: Conditioned reflexes: Coll. Art., lectures and speeches. - M .; PG: State Publishing House, 1923.
- Ivan Pavlov (1927). Conditioned reflexes: Anesthesia of the cerebral cortex.
- Anokhin P.K. "System genesis as a general pattern of the evolutionary process." // Bulletin of experimental biology and medicine. Number 8, t. 26 (1948).
- Ashby, WR, (1952). Design For a Brain, First Edition, Chapman and Hall: London, UK., John Wiley and Sons: New York, NY, 260 pp.
- Bain, A., (1855). The senses and the intellect. London: Parker.
- Morgan, CL, (1896). Habit and Instinct. London
- Thorndike, EL (1898, 1911). "Animal Intelligence: An Experimental Psychological Monographs # 8
- Hull, CL, (1943). Principles of Behavior: Behavior Theory. New York: D. Appleton-Century Company.
- Skinner, BF (1931). The concept of the reflex in the description of behavior, Ph.D. thesis, Harvard University.
- Turing, AM (1948). Intelligent Machinery, A Heretical Theory. Oxford.
- Ross, T. Machines That Think. Scientific American, April, 1933, pp. 206-209.
- Shannon, C. This Mouse Is Smarter Than You Are. Popular Science, March, 1952, pp. 99-101.
- Minsky, M. (1954) "Neural Nets and the Brain Model Problem," Ph.D. dissertation in Mathematics, Princeton.
- Farley, BG, & Clark, WA (1954). Simulation of self-organizing systems by digital computer. IRE Transactions on Information Theory, 4, 76–84.
- Rosenblatt, F. (1962): Principles of neurodynamics; perceptrons and the theory of brain mechanisms. Washington: Spartan Books.
- Minsky, M. (1961). Steps towards artificial intelligence. Proceedings of the IRE, 49 (1), 8-30.
- Bellman, R. (1956). Dynamic programming and Lagrange multipliers. Proceedings of the National Academy of Sciences, 42 (10), 767-769.
- Howard, RA (1960). Dynamic Programming and Markov Processes. MIT Press, Cambridge, Massachusetts.
- Michie, D., & Chambers, RA (1968). BOXES: An experiment in adaptive control. Machine intelligence, 2 (2), 137-152.
- Barto, AG, Sutton, RS, and Anderson, CW (1983) Neuronlike elements that can solve learning learning control problems. IEEE Transactions on Systems, Man, and Cybernetics, 13: 835-846
- R. Sutton, E. Barto. Training with reinforcements. M .: Publishing house Binom, 2011.
- WIDROW, B., GUPTA, NK, AND MAITRA, S. (1973), IEEE Trans. Systems, Man & Cybernetics SMC-3, 455.
- Finite automata and simulation of the simplest forms of behavior. M.L. Tsetlin. UMN, 18: 4 (112) (1963), 3–28
- Holland, J. (1975). Adaptation in natural and artificial systems. University of Michigan Press.
- Klopf, AH (1972). Brain function and adaptive systems — A heterostatic theory. Technical Report AFCRL-72-0164, Air Force Cambridge Research Laboratories, Bedford, MA.
- Anokhin P.K. Essays on the physiology of functional systems. M .: Medicine (1975).
- Barto, AG, Sutton, RS (1981). Goal seeking components for adaptive intelligence: An initial assessment. Technical Report AFWAL-TR-81-1070. Air Force Wright Aeronautical Laboratories / Avionics Laboratory, Wright-Patterson AFB, OH.
- Barto, AG, Sutton, RS (1981). Landmark learning: An illustration of associative search. Biological Cybernetics, 42: 1–8.
- Witten, IH (1977). An adaptive controller for discrete-time Markov environments. Information and Control, 34: 286–295.
- Watkins, CJCH (1989). Learning from Delayed Rewards. Ph.D. thesis, Cambridge University.
- Mnih, V. et al. Playing Atari With Deep Reinforcement Learning. NIPS Deep Learning Workshop, 2013.
')
Source: https://habr.com/ru/post/322404/
All Articles