Neural networks: practical application

Natalia Efremova immerses the public in the specifics of the practical use of neural networks. This is a transcript of the Highload ++ report.
Good afternoon, my name is Natalia Efremova, and I am a research scientist at NtechLab. Today I will talk about the types of neural networks and their application.
')
First, I will say a few words about our company. The company is new, maybe many of you still do not know what we are doing. Last year we won the MegaFace match. This is an international competition for face recognition. In the same year, our company was opened, that is, we have been on the market for about a year, even a little more. Accordingly, we are one of the leading companies in face recognition and biometric image processing.
The first part of my report will be sent to those unfamiliar with neural networks. I am directly involved in deep learning. I have been working in this field for more than 10 years. Although it appeared a little less than a decade ago, there used to be some beginnings of neural networks that were similar to deep learning.
In the past 10 years, deep learning and computer vision have been developing at an incredible pace. Everything significant has been done in this area that has happened in recent years 6.
I will talk about practical aspects: where, when, what to use in terms of deep learning for image and video processing, for pattern and face recognition, since I work for a company that does this. I will talk a little about the recognition of emotions, which approaches are used in games and robotics. I will also tell you about the non-standard use of deep learning, something that just comes out of scientific institutions and is still little used in practice, how it can be used, and why it is difficult to apply.
The report will consist of two parts. Since most are familiar with neural networks, first I will quickly tell you how neural networks work, what biological neural networks are, why it is important for us to know how it works, what artificial neural networks are, and which architectures are used in which areas.
Immediately I apologize, I will jump a little into English terminology, because I don’t even know much of what it’s called in Russian. Maybe you too.
So, the first part of the report will be devoted to convolutional neural networks. I will explain how the convolutional neural network (CNN), image recognition with the example of face recognition, works. I will talk a little about recurrent neural networks, recurrent neural network (RNN) and reinforcement learning on the example of deep learning systems.
As a non-standard application of neural networks, I will talk about how CNN works in medicine for recognizing voxel images, how neural networks are used for recognizing poverty in Africa.
What is neural networks
The prototype for creating neural networks was, oddly enough, biological neural networks. Perhaps many of you know how to program a neural network, but where it came from, I think some do not know. Two thirds of all sensory information that comes to us comes from visual organs of perception. More than one third of the surface of our brain is occupied by the two most important visual zones - the dorsal visual path and the ventral visual path.
The dorsal visual path begins in the primary visual zone, in our temechke and continues upward, while the ventral path begins on our nape and ends approximately behind the ears. All the important pattern recognition that we have going on, everything meaningful, what we are aware of, passes right there, behind the ears.
Why is it important? Because it is often necessary to understand neural networks. Firstly, everyone talks about it, and I’m used to what is happening, and secondly, the fact is that all areas that are used in neural networks for pattern recognition came to us from the ventral visual path, where each A small zone is responsible for its strictly defined function.
The image comes to us from the retina, passes a series of visual zones and ends in the temporal zone.
In the distant 60s of the last century, when the study of the visual areas of the brain was just beginning, the first experiments were carried out on animals, because there was no fMRI. The brain was examined using electrodes implanted into various visual zones.
The first visual zone was examined by David Hubel and Torsten Wiesel in 1962. They conducted experiments on cats. Cats were shown various moving objects. To which the brain cells reacted, that was the stimulus that the animal recognized. Even now, many experiments are carried out in these draconian ways. Nevertheless, this is the most effective way to find out what every smallest cell in our brain does.
In the same way, many more important properties of visual zones were discovered, which we use in deep learning now. One of the most important properties is an increase in the receptive fields of our cells as we move from the primary visual areas to the temporal lobes, that is, later visual areas. The receptive field is that part of the image that each cell of our brain processes. Each cell has its own receptive field. The same property is preserved in neural networks, as you probably know everything.
Also with increasing receptive fields, complex stimuli increase, which usually recognize neural networks.

Here you see examples of the complexity of stimuli, various two-dimensional forms that are recognized in zones V2, V4 and different parts of the temporal fields in macaques. A number of MRI experiments are also conducted.
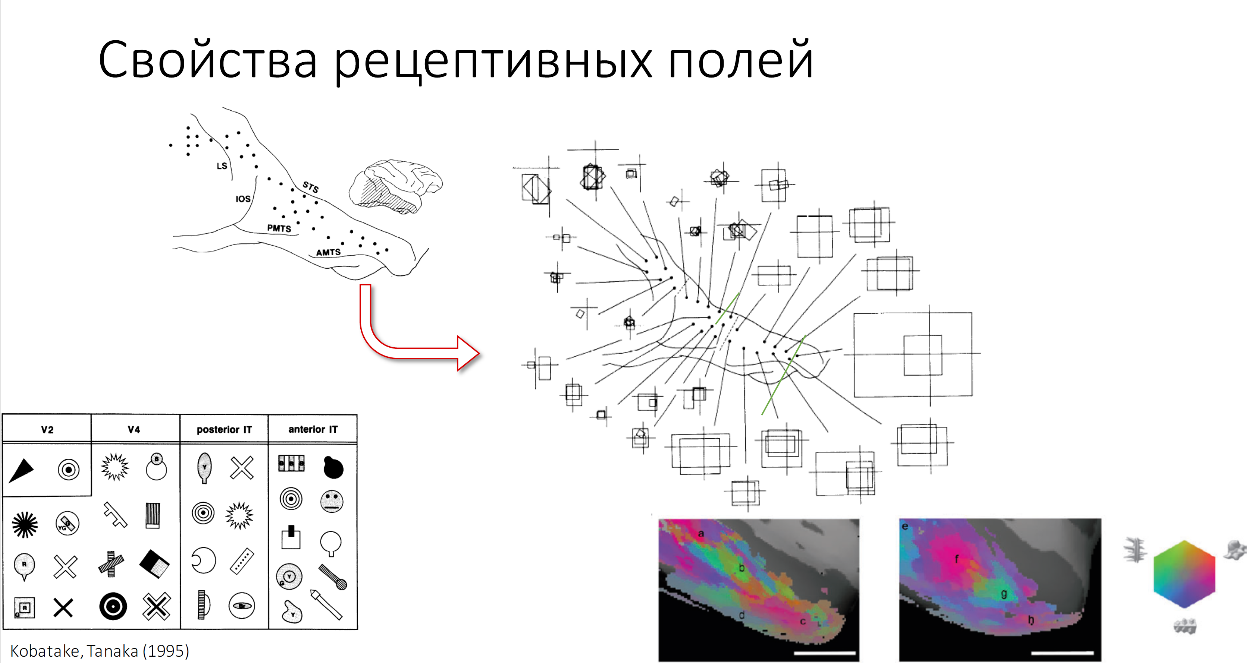
Here you see how such experiments are conducted. This is the 1 nanometer part of the IT cortex'a zones of the monkey when recognizing various objects. Highlighted where recognized.
Let's sum up. An important property that we want to learn from the visual zones is that the size of receptive fields increases, and the complexity of the objects that we recognize increases.
Computer vision
Before we learned to apply it to computer vision - in general, as such it was not there. In any case, it did not work as well as it does now.
We transfer all these properties to the neural network, and now it has worked, if we do not include a small digression to datasets, which I will discuss later.
But first, a little about the simplest perceptron. It is also formed in the image and likeness of our brain. The simplest element resembling a brain cell is a neuron. It has input elements, which by default are located from left to right, occasionally from bottom to top. On the left is the input part of the neuron, on the right the output part of the neuron.
The simplest perceptron is capable of performing only the simplest operations. In order to perform more complex calculations, we need a structure with a large number of hidden layers.
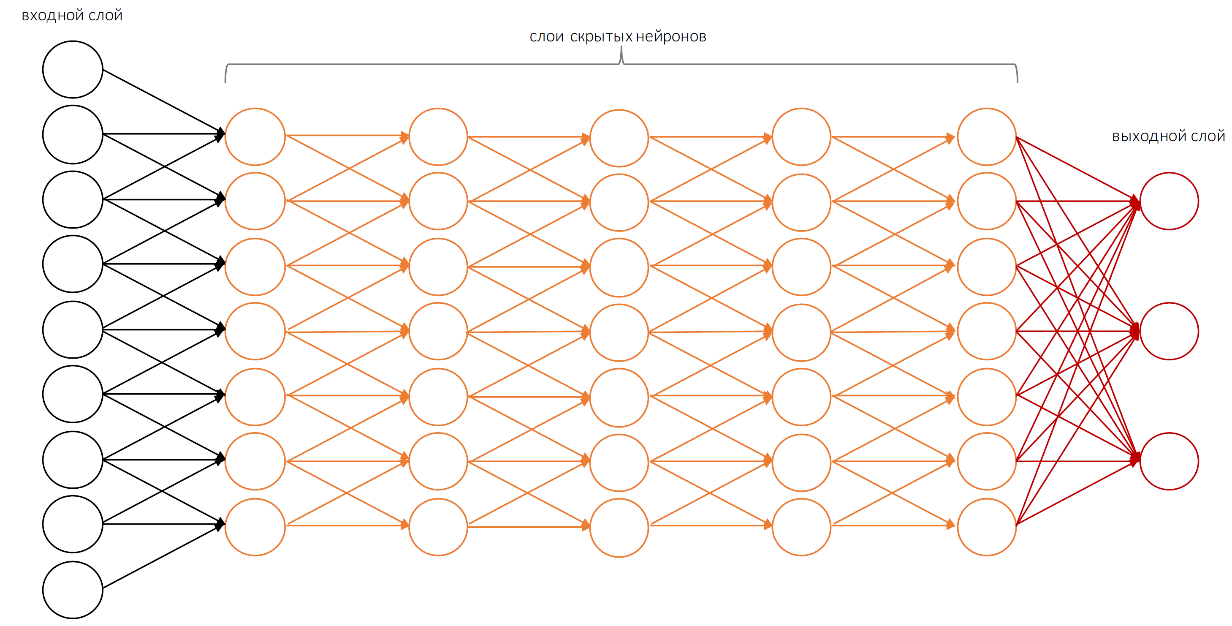
In the case of computer vision, we need even more hidden layers. And only then will the system intelligently recognize what it sees.
So, what happens when the image is recognized, I will tell on the example of faces.
For us to look at this picture and say that it shows exactly the face of the statue, quite simply. However, until 2010 it was an incredibly difficult task for computer vision. Those who dealt with this issue before this time probably know how hard it was to describe the object that we want to find in the picture without words.
We needed to do this in some geometrical way, describe the object, describe the interconnections of the object, how these parts can relate to each other, then find this image on the object, compare them and get what we recognized badly. Usually it was a little better than tossing a coin. Slightly better than chance level.
Now this is not the case. We break our image either into pixels or into certain patches: 2x2, 3x3, 5x5, 11x11 pixels - as convenient for the creators of the system in which they serve as an input layer to the neural network.
Signals from these input layers are transmitted from layer to layer using synapses, each layer has its own specific coefficients. So we pass from layer to layer, from layer to layer, until we get that we recognized the face.
Conventionally, all these parts can be divided into three classes, we denote them X, W and Y, where X is our input image, Y is a set of labels, and we need to get our weights. How do we calculate w?
With our X and Y, it seems simple. However, what is indicated by an asterisk is a very complex non-linear operation, which, unfortunately, has no inverse. Even with 2 given components of the equation, it is very difficult to calculate it. Therefore, we need to gradually, by trial and error, by selecting the weight W to make the error as small as possible, preferably to become equal to zero.

This process occurs iteratively, we are constantly reducing, until we find the value of the weight W, which suits us enough.
By the way, not a single neural network with which I worked reached an error equal to zero, but it worked quite well.

This is the first network that won the 2012 ImageNet international competition. This is the so-called AlexNet. This is the network that first declared itself, that there are convolutional neural networks and since then in all international competitions, convolutional neural nets have never surrendered their positions.
Despite the fact that this network is quite small (it has only 7 hidden layers), it contains 650 thousand neurons with 60 million parameters. In order to iteratively learn how to find the necessary weights, we need a lot of examples.
The neural network learns from the example of a picture and a label. As we are taught in childhood, "this is a cat, and this is a dog," so neural networks are trained in a large number of pictures. But the fact is that until 2010 there was not a sufficiently large data set, which could teach so many parameters to recognize images.
The largest databases that existed before this time: PASCAL VOC, which had only 20 categories of objects, and Caltech 101, which was developed by the California Institute of Technology. In the latter there were 101 categories, and that was a lot. Those who could not find their objects in any of these databases had to cost their databases, which, I will say, is terribly painful.
However, in 2010, ImageNet appeared in which there were 15 million images, divided into 22 thousand categories. This solved our problem of learning neural networks. Now everyone who has any academic address can safely go to the site of the base, request access and get this base to train their neural networks. They respond quickly enough, in my opinion, the next day.
Compared to previous data sets, this is a very large database.

The example shows how insignificant all that was before her was. Simultaneously with the ImageNet base, an ImageNet competition appeared, an international challenge, in which all teams willing to compete can take part.
This year, the network created in China won, it had 269 layers. I do not know how many parameters, I suspect, too many.
Deep neural network architecture
Conventionally, it can be divided into 2 parts: those who study, and those who do not study.
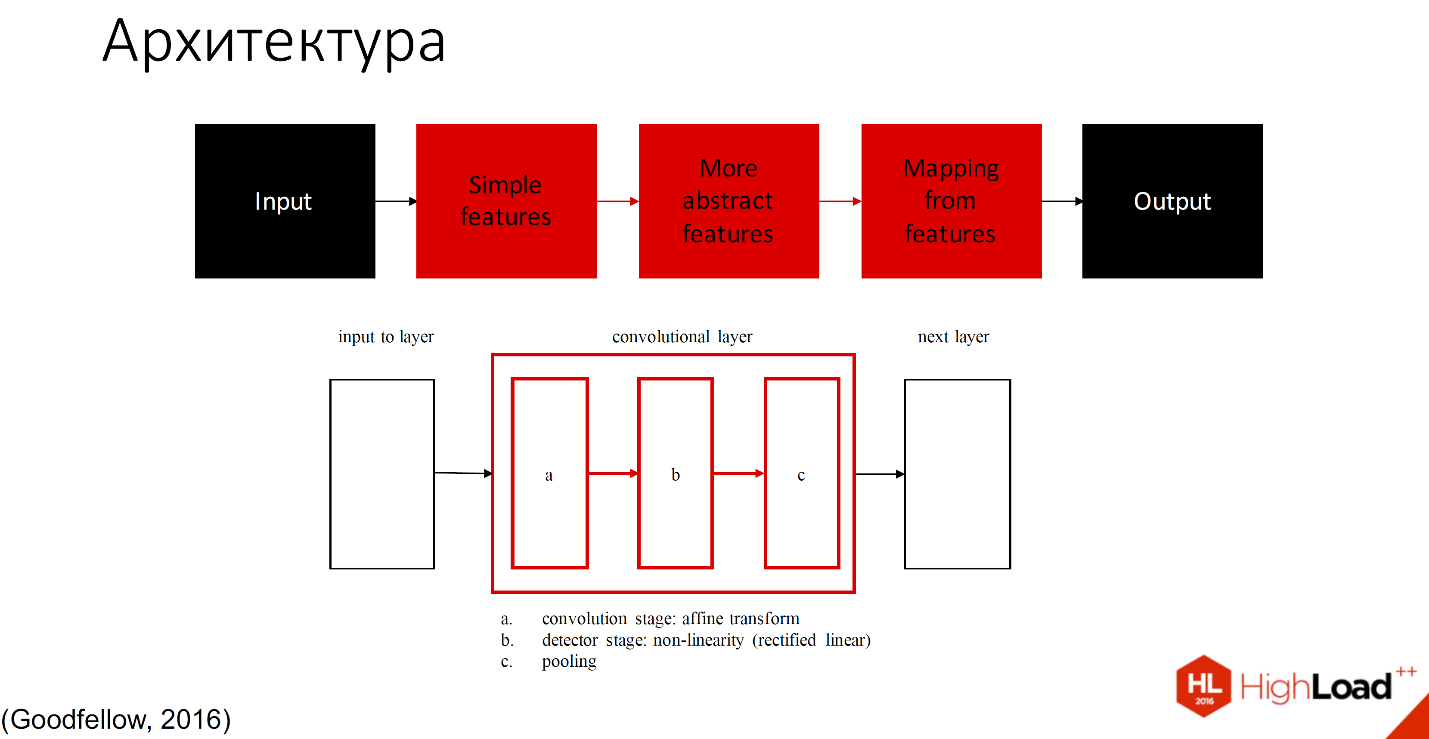
Black denotes those parts that do not study, all other layers are capable of learning. There are many definitions of what is inside each convolutional layer. One of the accepted notations - one layer with three components is divided into the convolution stage, detector stage and pooling stage.
I will not go into details, there will still be a lot of reports, which detail how it works. I'll tell you by example.
Since the organizers asked me not to mention a lot of formulas, I threw them out completely.

So, the input image falls into a network of layers, which can be called filters of different sizes and different complexity of elements that they recognize. These filters make up some of their index or set of attributes, which then falls into the classifier. Usually it is either SVM or MLP - a multilayer perceptron, to whom that is convenient.
In the image and likeness with a biological neural network, objects are recognized by different complexity. As the number of layers increases, all this has lost touch with cortex, since the number of zones in the neural network is limited there. 269 or many-many areas of abstraction, so only the increase in complexity, the number of elements and receptive fields is saved.
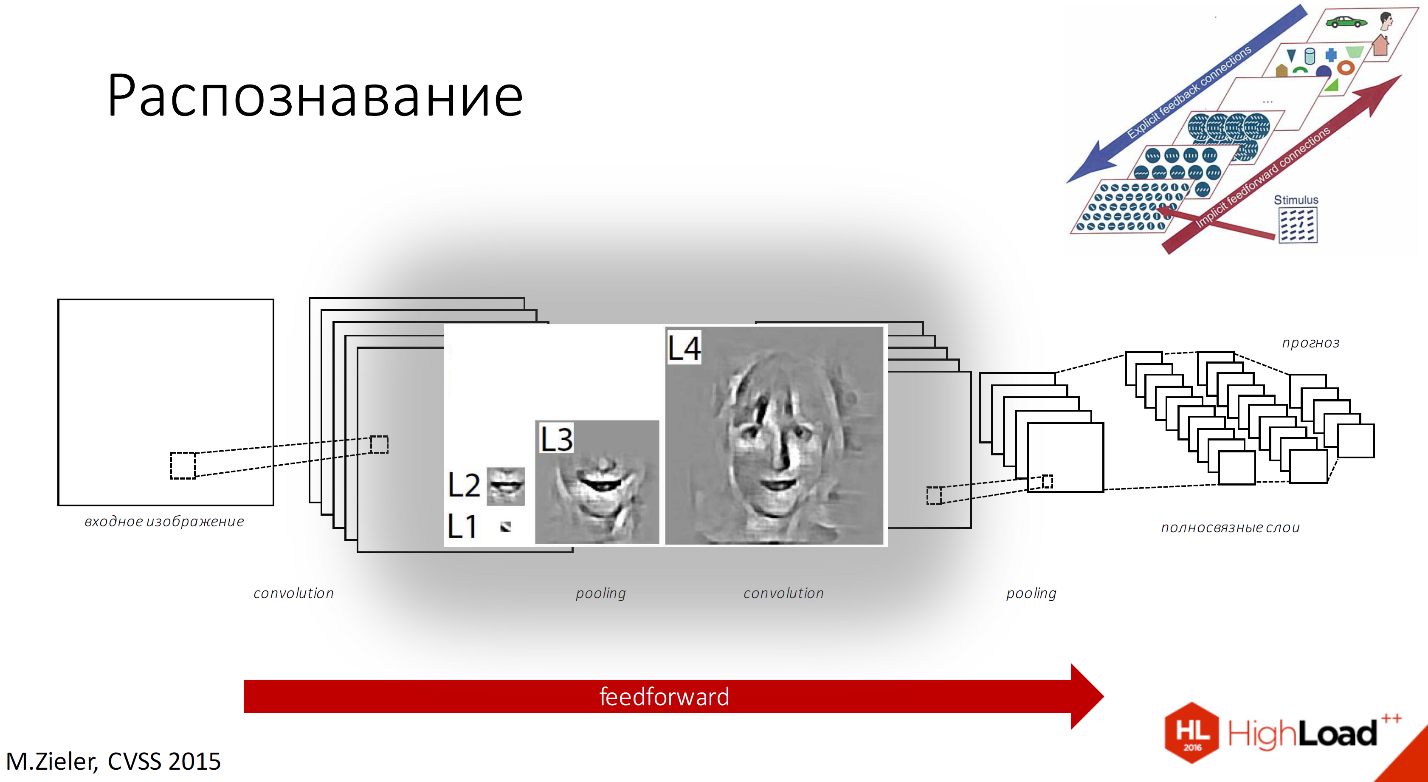
If we consider facial recognition as an example, then our receptive field of the first layer will be small, then a little more, more, and so on until we can finally recognize the whole face.

From the point of view of what we have inside the filters, there will first be slanted sticks plus a little color, then parts of the faces, and then all of the faces will be recognized by each cell of the layer.
There are people who claim that a person always recognizes better than a network. Is it so?
In 2014, scientists decided to test how well we recognize in comparison with neural networks. They took 2 of the best networks at the moment - these are AlexNet and the network of Matthew Ziller and Fergus, and compared with the response of different areas of the brain of a monkey, which was also taught to recognize some objects. The objects were from the animal world, so that the monkey does not get confused, and experiments were carried out, who can distinguish better.
Since it is clearly impossible to get a response from the monkey, electrodes were implanted into it and the response of each neuron was measured directly.
It turned out that under normal conditions, brain cells reacted as well as the state of the art model at that time, that is, the Matthew Ziller network.
However, with an increase in the speed of displaying objects, an increase in the number of noises and objects in the image, the recognition rate and its quality of our brain and the brain of primates decrease dramatically. Even the simplest convolutional neural network recognizes objects better. That is, officially neural networks work better than our brains.
Classical problems of convolutional neural networks
There are actually not so many of them; they belong to three classes. Among them are such tasks as identification of an object, semantic segmentation, face recognition, recognition of human body parts, semantic definition of boundaries, selection of objects of attention in an image and selection of surface normals. They can be divided into 3 levels: from the lowest-level tasks to the highest-level tasks.

Using this image as an example, let's consider what each of the tasks is doing.
- Determination of boundaries is the lowest-level task for which convolutional neural networks are already classically applied.
- The definition of the vector to the normal allows us to reconstruct the three-dimensional image from the two-dimensional.
- Saliency, the definition of objects of attention - this is what people would pay attention to when considering this picture.
- Semantic segmentation allows you to divide objects into classes according to their structure, without knowing anything about these objects, that is, before they are recognized.
- Semantic selection of boundaries - is the selection of boundaries, divided into classes.
- Isolation of parts of the human body .
- And the highest-level task is the recognition of the objects themselves , which we will now consider using the example of face recognition.
Face recognition
The first thing we do is run through the face detector in the image in order to find the face. Next, we normalize, center the face and launch it for processing into the neural network. Then we get a set or vector of signs that uniquely describes the features of this person.
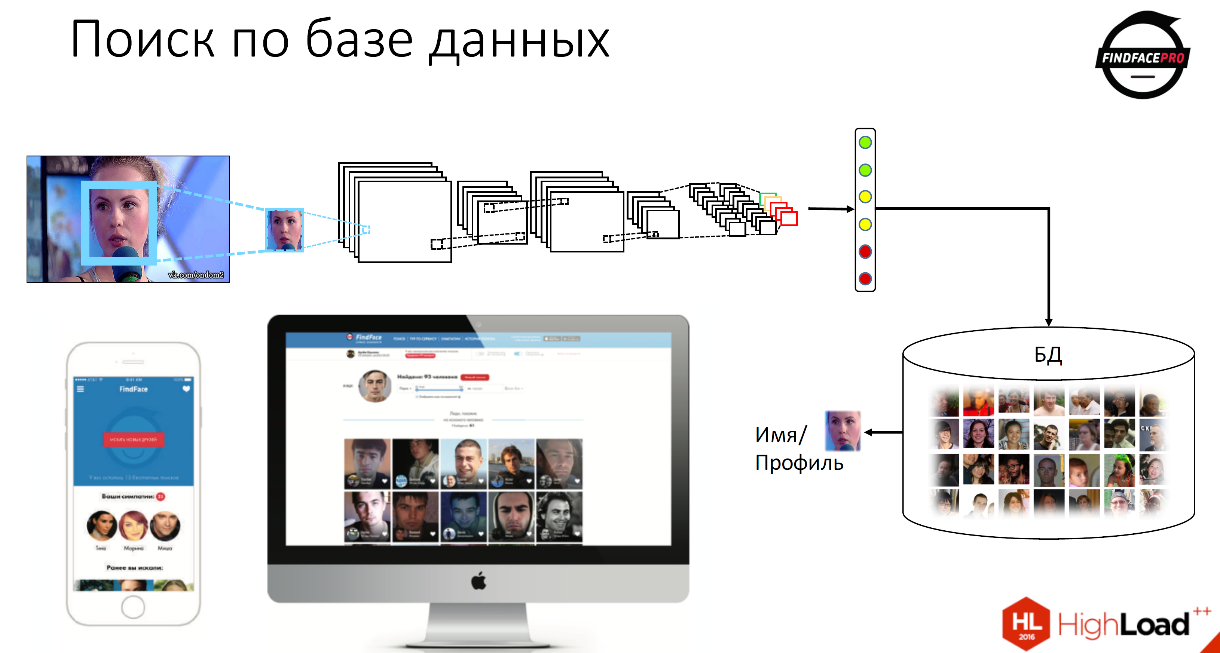
Then we can compare this feature vector with all feature vectors that are stored in our database, and get a reference to a specific person, in his name, to his profile - everything that we can have in the database.
This is how our product FindFace works - it is a free service that helps to search for profiles of people in the VKontakte database.
In addition, we have an API for companies that want to try our products. We provide a service for the detection of persons, verification and identification of users.
Now we have developed 2 scenarios. The first is identification, search for a person in the database. The second is verification, this is a comparison of two images with a certain probability that it is one and the same person. In addition, we are now in the development of the recognition of emotions, image recognition on video and liveness detection - it is an understanding of whether a person is alive in front of a camera or a photograph.
Some statistics. When identifying, when searching for 10 thousand photos we have an accuracy of about 95%, depending on the quality of the base, 99% accuracy of verification. And besides this, this algorithm is very resistant to change - we don’t have to look into the camera, we may have some obstructing objects: glasses, sunglasses, a beard, a medical mask. In some cases, we can conquer even such incredible difficulties for computer vision, like glasses and a mask.
Very fast search, it takes 0.5 seconds to process 1 billion photos. We have developed a unique quick search index. We can also work with low quality images obtained from CCTV cameras. We can handle this all in real time. You can upload photos via the web interface, via Android, iOS and search for 100 million users and their 250 million photos.
As I already said, we won first place at the MegaFace competition - an equivalent for ImageNet, but for face recognition. It has been held for several years already; last year we were the best among 100 teams from all over the world, including Google.
Recurrent Neural Networks
We use recurrent neural networks when it is not enough for us to recognize only the image. In cases where it is important for us to follow the sequence, we need the order of what happens to us, we use ordinary recurrent neural networks.
It is used for natural language recognition, video processing, even used for image recognition.
I will not tell about the recognition of a natural language - after my report there will be two more that will be directed towards the recognition of a natural language. Therefore, I will tell about the work of recurrent networks on the example of recognition of emotions.
What are recurrent neural networks? This is about the same as regular neural networks, but with feedback. We need feedback in order to transmit the previous state of the system to the input of the neural network or to one of its layers.
Suppose we process emotions. Even in a smile - one of the simplest emotions - there are several moments: from a neutral expression to the moment when we have a full smile. They go one after the other consistently. To understand this well, we need to be able to observe how this happens, transfer what was in the previous frame to the next step of the system.
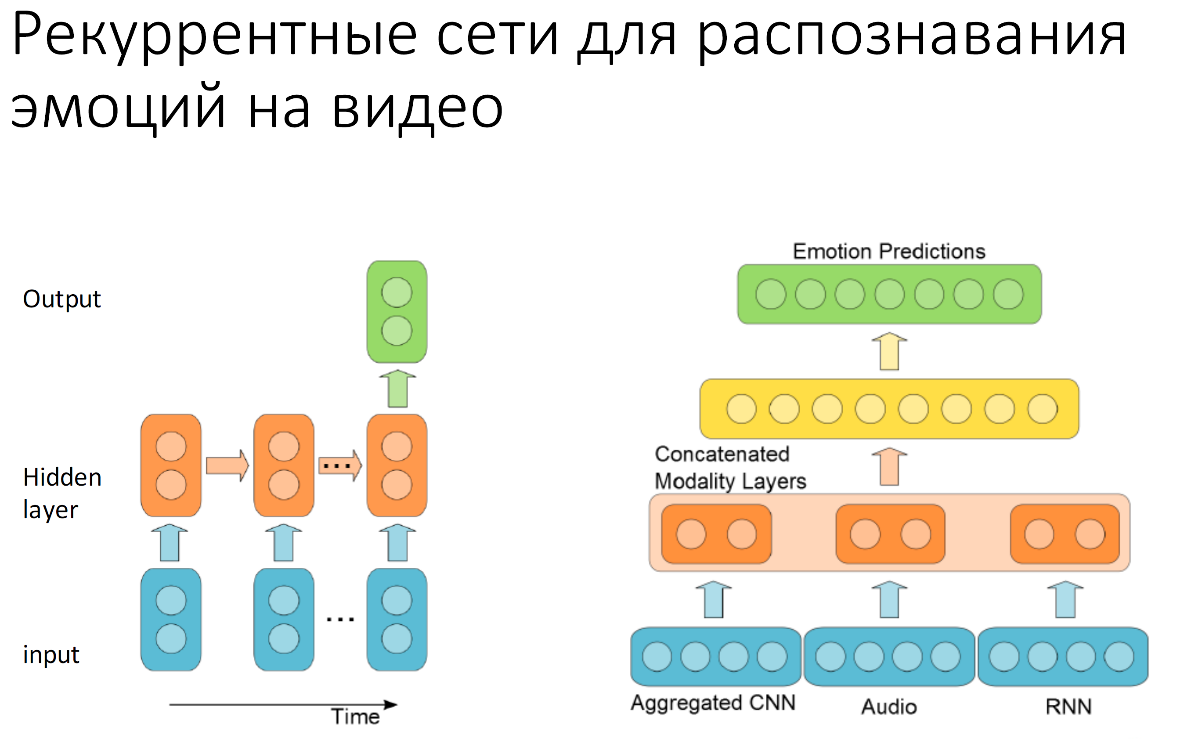
In 2005, in a contest called Emotion Recognition in the Wild, a team from Montreal presented a recurrent system that looked very simple for emotion recognition. She had only a few convolutional layers, and she worked exclusively with video. This year, they also added audio recognition and aggregated frame-by-frame data, which are obtained from convolutional neural networks, audio signal data with the operation of a recurrent neural network (with a return of state), and received first place in the competition.
Reinforcement training
The next type of neural networks, which is very often used recently, but has not received such wide publicity as the previous 2 types - is deep reinforced learning, reinforcement learning.
The fact is that in the previous two cases we use databases. We have either data from individuals, or data from images, or data with emotions from videos. If we don’t have it, if we cannot shoot it, how can we teach the robot to take objects? We do this automatically - we do not know how it works. Another example: compiling large databases in computer games is difficult, and it is not necessary, it can be done much easier.
Everyone probably heard about the success of deep reinforcement learning in Atari and in go.
Who heard about Atari? Well, someone heard, good. I think everyone heard about AlphaGo, so I will not even tell you exactly what is happening there.

What happens in Atari? On the left, the architecture of this neural network is depicted. She learns by playing with herself in order to get the maximum reward. The maximum reward is the fastest possible outcome of the game with the highest score possible.
Top right - the last layer of the neural network, which depicts the entire number of states of the system, which played itself against itself for only two hours. The red shows the desired outcomes of the game with the maximum reward, and the blue - undesirable. The network builds a certain field and moves along its trained layers to the state it wants to achieve.
In robotics, the situation is a little different. Why? Here we have several difficulties. First, we do not have many databases. Secondly, we need to coordinate three systems at once: the perception of the robot, its actions with the help of manipulators and its memory - what was done in the previous step and how it was done. In general, this is all very difficult.
The fact is that not a single neural network, even deep learning at the moment, can cope with this task quite effectively, so deep learning is only an exception of what the robots need to do. For example, recently Sergei Levin provided a system that teaches the robot to grab objects.
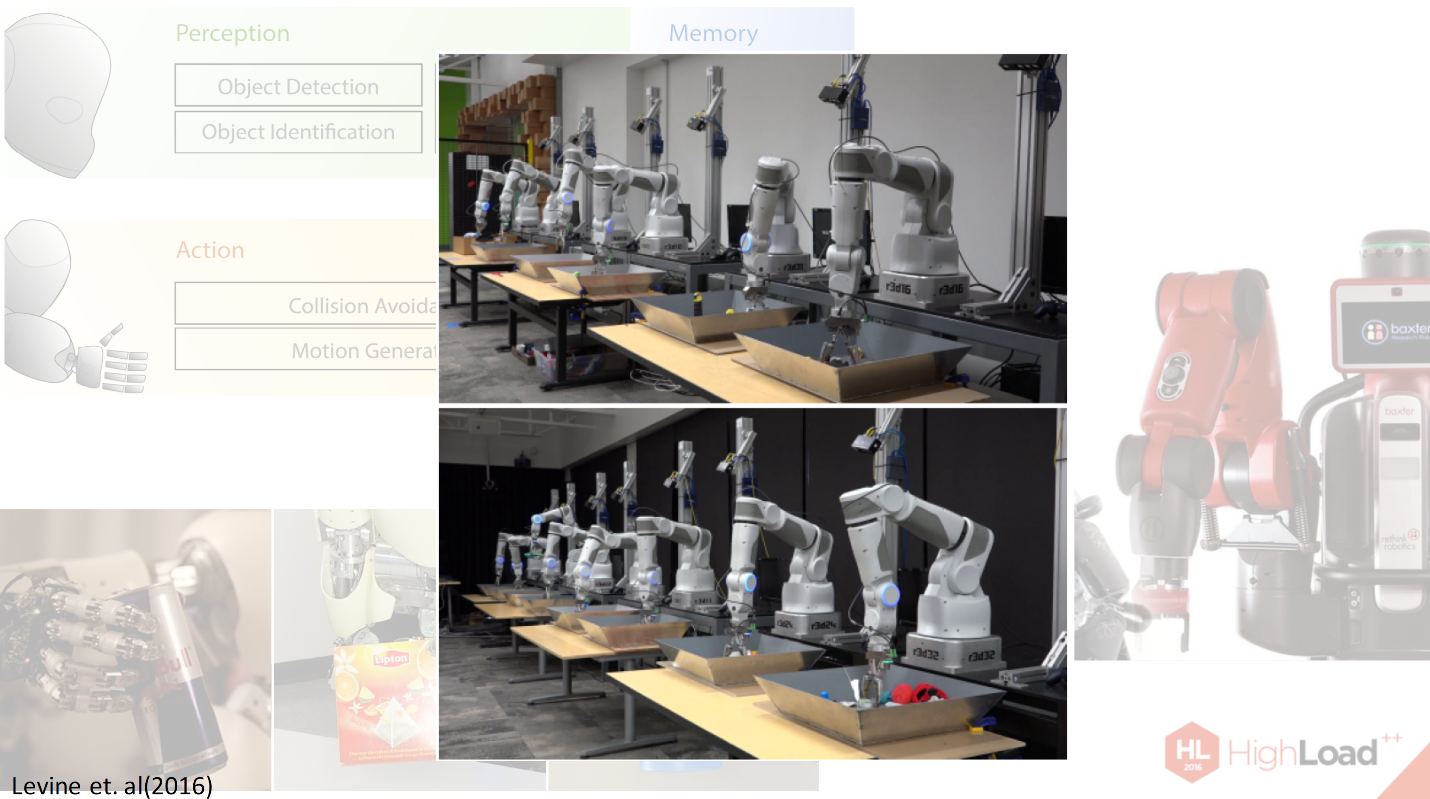
Here are the experiments that he conducted on his 14 robot manipulators.
What's going on here? In these basins, which you see in front of you, there are various objects: pens, erasers, smaller and bigger circles, rags, different textures, and different hardness. It is unclear how to teach the robot to capture them. For hours, and even, like, weeks, the robots were trained to be able to capture these items, they were compiled about this database.
Databases are a kind of response from the environment that we need to accumulate in order to be able to train the robot to do something in the future. In the future, robots will be trained on this set of system states.
Non-standard applications of neural networks
This is unfortunately the end, I do not have much time. I will tell you about those non-standard solutions that now exist and which, according to many forecasts, will have some kind of application in the future.
So, Stanford scientists recently came up with a very unusual use of CNN's neural network to predict poverty. What did they do?
In fact, the concept is very simple. The fact is that in Africa the poverty level goes beyond all imaginable and inconceivable limits. They do not even have the ability to collect social demographic data. Therefore, since 2005, we generally have no data on what is happening there.
Scientists collected day and night maps from satellites and fed them to the neural network for some time.
The neural network was pre-configured on ImageNet. That is, the first layers of filters were set up so that she knew how to recognize already some very simple things, for example, the roofs of houses, to search for settlements on the daily maps. Then the day maps were compared with the night light maps of the same surface area in order to say how much money the population has to at least cover their homes during the night.

Here you see the results of the forecast built by the neural network. The forecast was made with different resolutions. And you see - the very last frame - real data collected by the Ugandan government in 2005.
It can be noted that the neural network has made a fairly accurate forecast, even with a slight shift since 2005.
There were of course side effects. Deep learning scientists are always surprised to find different side effects. For example, like those that the network has learned to recognize water, forests, large construction sites, roads — all without teachers, without pre-built databases. Generally completely independently. There were some layers that reacted, for example, to the roads.
And the last application I would like to talk about is semantic segmentation of 3D images in medicine. In general, medical imaging is a complex area that is very difficult to work with.
There are several reasons for this.
- We have very few databases. It is not so easy to find a picture of the brain, besides it is damaged, and you can't take it from anywhere either.
- Even if we have such a picture, we need to take the medic and make him manually place all the multi-layered images, which is very long and extremely inefficient. Not all doctors have the resources to do this.
- Need very high accuracy. The medical system cannot be mistaken. When recognizing, for example, cats, they didn’t recognize - nothing terrible. And if we did not recognize the tumor, then this is not very good. Here are particularly fierce requirements for system reliability.
- Images in three-dimensional elements - voxels, not in pixels, which gives additional complexity to system developers.
But how did this question get around in this case? CNN was two-way. One part processed a more normal resolution, the other a slightly more degraded resolution in order to reduce the number of layers that we need to train. Due to this, the time for training the network was slightly reduced.
Where it is used: the definition of damage after a stroke, to look for a tumor in the brain, in cardiology to determine how the heart works.
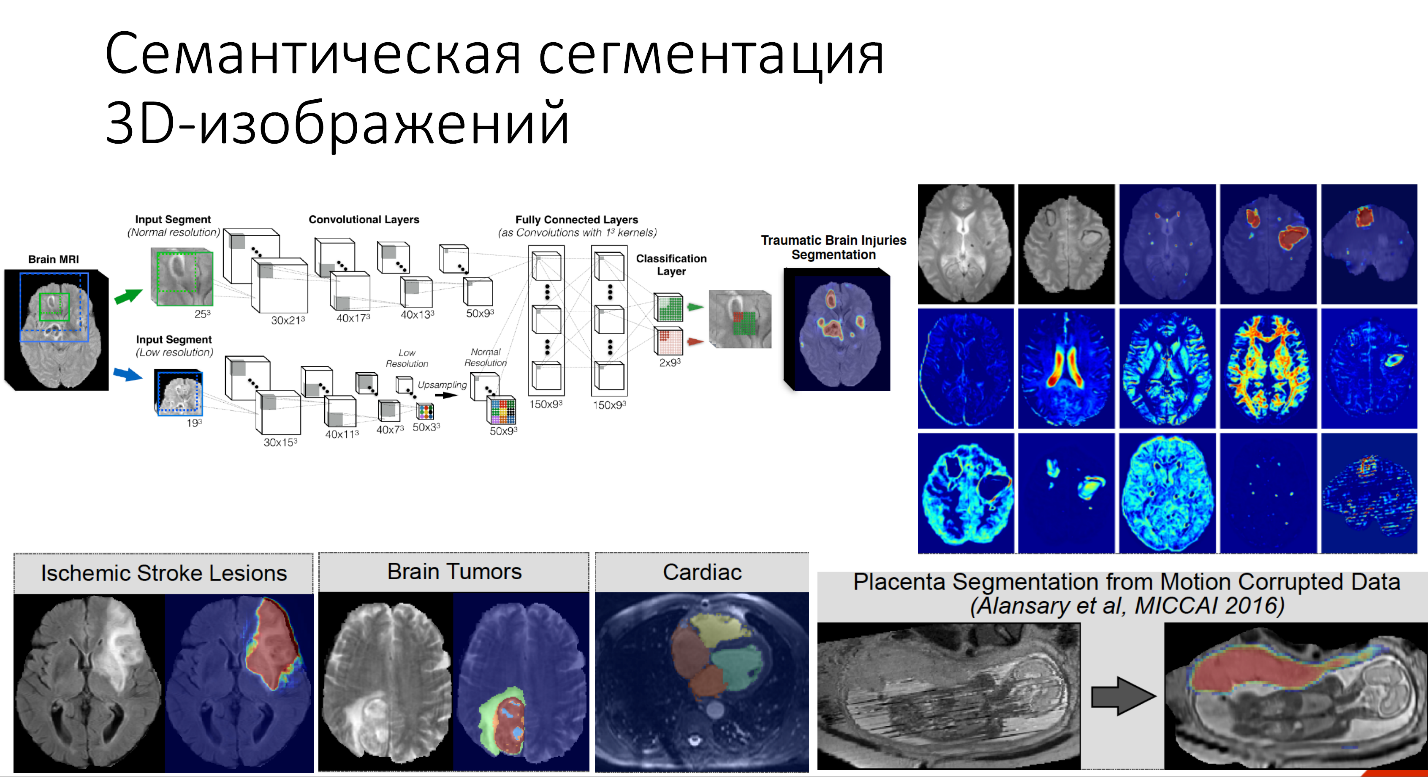
Here is an example to determine the volume of the placenta.
Automatically it works well, but not so much that it is released into production, so it is only just beginning. There are several startups to create such medical vision systems. In general, in deep learning there are a lot of startups in the near future. It is said that in the past six months, venture capitalists have allocated more budgets for startups to deep learning than in the past 5 years.
This area is actively developing, many interesting directions. We live in an interesting time. If you are engaged in deep learning, then it’s probably time for you to open your startup.
Well, on this I probably will round out. Thank you very much.
Report: Neural networks - practical application .
Source: https://habr.com/ru/post/322392/
All Articles