How development with operation fell out - and how they made it up

What is the beginning of any project on IT infrastructure? If you thought about something like: the admins got together, discussed and someone suggested a solution, then you most likely hit the mark. This is exactly the situation with exploitation in Russian companies, and we have, until recently, too.
In the article I will talk about how we spent 5 million and almost half a year to make sure: excellent specialists and enthusiasm are not enough to implement something large-scale.
It all started with the realization that a couple of huge monolithic applications at the heart of the payment service is cumbersome and inconvenient. Layout , Portal and Yandex.Money Billing were serviced separately by several operating teams that rolled up updates and monitored the operation of the systems. The process, which has been working steadily for years, began to fail, when project teams began to form in the company and the frequency of releases increased exponentially.
The number of conflicts when working with the same parts of the code has increased, not to mention the acceptance testing, which sometimes lasted more than a month. What do modern companies do in such cases? They divide their monoliths into many small (micro) services.
OK, go to microservices
More services - more support load. After all, now 5-10 releases are released every day. According to the old process, after testing, each of them must be manually rolled onto several nodes - up to 100 manual updates were released per day. Taking into account the need to update test stands, the number of which is equal to the number of teams, the figure was calculated in thousands of manual operations.
Even the team of the best engineers of operation with intravenous caffeine supply will not master the daily update of thousands of systems - all this needs to be automated. No sooner said than done: the DevOps group was assigned from operation, which was entrusted with automation. Well, as allocated - for some time they, together with the administrators, were engaged in routine work and project work, and then separated themselves for specific tasks.
Programmers and testers patiently waited for the magic solution, and inspired by a big ambitious task, the guys from DevOps worked from morning to evening on the infrastructure of automatic installation of releases and the deployment of test stands "on the button".
In order to better understand what is happening, let's look at how the DevOps team presented the build and test system at the first stage:
We create a universal script to build each application for any environment.
We create settings for building applications for combat and various test environments.
We develop a virtualization environment that allows you to create test environments with customizations using a template.
With each release, we assemble and install the updated application on the combat environment, as well as on each of the existing test environments.
- The tweaks and changes that are carried out during the release process on the combat environment are repeated manually on each of the test ones.
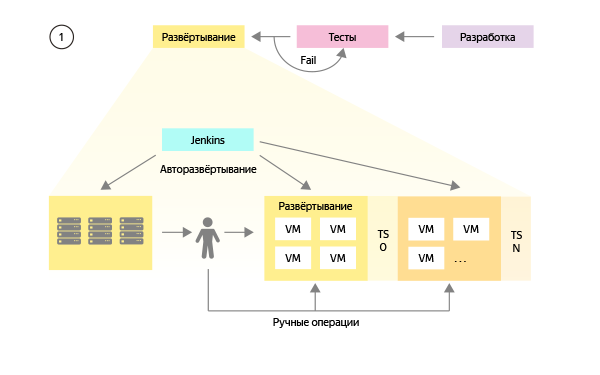
Over time, we planned to customize the GUI to manage all processes and gradually get rid of manual operations on all types of environments.
Several months have passed
Ansible-Jenkins, a system of virtual stands and release assemblies assembled in the laboratory, is confronted with the real world. And here the very first production testing revealed several fundamental problems:
One more or less working stand was assembled by hand in a few weeks , not hours. During the waiting period, the needs grew from tens to several hundred booths, which delays the completion of work somewhere in the next century.
Along the way, it turned out that each stand uses about 200 GB of disk space. If you multiply this volume by the number of required stands, this gives some indecent figures of daily “turnover” of disk space;
- Different teams had slightly different methods for developing, testing, configuring, and deploying services. Therefore, the proposed option did not completely suit any of the development teams.
You do remember that administrators are used to working without a project manager? When a bunch of problems are found, they usually put them all in backlog and solve them in turn. When the situation escalates, they continue to do the same, but faster or more.
In general, there is little that can demoralize a specialist as much as a low assessment of his hard work and frequent changes of priorities. Unfortunately, we stepped on this rake, since the efforts of exploitation were directed in the wrong direction. The result is logical: the new process did not work on time, but the old one finally broke down, throwing a bunch of problems to developers and testers.
At the same time, the agonizing period of attempts to use the arriving new stands began. Since each such stand added manual work to update it, the queue of tasks for administrators began to grow rapidly, and the attitude of developers to this project - just as rapidly deteriorate.
Intelligence around the head
Even the most inconvenient problem is important to recognize in time and start working on its elimination. Our key error was not related to technology, it was not enough attention to project management, defining requirements and assessing the expectations of interested parties:
DevOps, in principle, could not do this project alone. Until development and testing was involved in it, all work was largely done on the table.
Developers and testers generally asked little about what they needed. The sysadmins focused on deployment tasks, and the developers and testers really needed a tool to automatically raise the stands and run test scenarios.
The business customer had resource constraints. The development of new processes and the maintenance of old ones simply did not fit into it. It was discovered too late.
- And the most banal: without a project manager, the whole story was reduced to promises to complete the work tomorrow or the day after tomorrow, but the results did not appear even after six months.
When the first emotional reaction took place and all the key people met together to discuss their desires, it became obvious that the problem had to be solved first. Only this time we treated this as a project in development: with the goal, requirements, deadline, resources, customers, responsible, work plan, technical solution, etc.
The reassembled requirements included details that we missed at the first iteration. Details that proved fatal.
In the second approach, we took into account:
how many and what test benches will be needed in a couple of years, not right now;
how much data should be in each test bench;
how the stands will be isolated from each other and from the military environment;
what are the requirements for development teams to update them;
how testers will work on the stands;
- How will the test environment connections with external services be checked?
Understanding the details divided the seemingly solid project into subprojects related to the provision of virtual space, network isolation, update delivery, the ability to configure applications, etc.
As a result, the most efficient option was that in which there are exactly two environments: combat and reference test. And the whole multitude of team test environments is created by cloning a reference bench with customized components. In this scenario, development teams will need to make a minimum of changes in their components and stubs of external services. A decrease in the volume of test data 20 times will allow to transfer the database inside the stands. Stand isolation will be provided by network engineers at the level of subnets and DNS server settings.
The modified scheme looks like this:
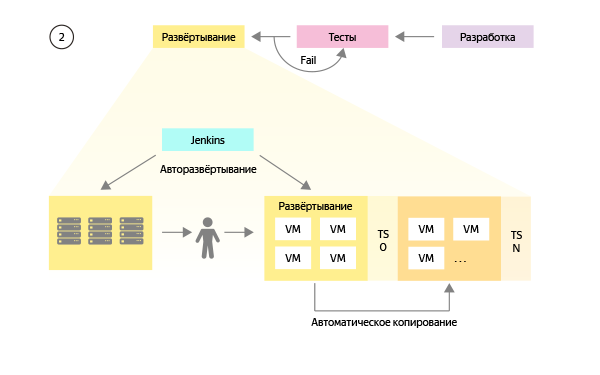
A small visual difference on the diagram (fewer manual operations) in work changes a lot, since the transfer of changes to all test environments occurs automatically and no longer requires close attention of engineers.
Conclusions after the passage of the "garden rake"
You might think that all of the above is obvious. However, things that are obvious in one area are not always obvious in another. There are a huge number of examples where large-scale infrastructure projects in operation change “on the knee”. You can successfully change the DC, launch new offices, move from DBMS to DBMS, leaving for the competence of engineers who have already done such projects before.
But when you come across a project in which the operation needs to work together with the development, support and much more, the probability of failure without project management increases many times. Have you seen a lot of dedicated infrastructure project managers in software companies?
Instead of concluding in the spirit of "they got married, they lived happily ever after," I would like to draw conclusions that we made for the future:
Project work is necessary for system administrators in the same way as developers. Without a project manager, each participant will have their own vision, which ultimately will not allow the entire team to come to a given point.
There is nothing worse for the motivation of a specialist than the awareness of the futility of time spent on the task. So that time is not wasted, there must be a clear understanding of what goals the project participants need to achieve and why. Regular meetings of developers, testers and admins helped us a lot.
It is necessary to find a way to check and try to use the interim results of the work of system administrators so that later they do not have to cross out all their many months of work.
- Even a team of top engineers with perfect motivation in a vacuum does not compensate for the inconsistency of the actions of the head and legs.
I wonder how you work on large-scale IT projects in your company - have you encountered similar problems of project management?
')
Source: https://habr.com/ru/post/322302/
All Articles