Premature architecture optimization

Evgeny Potapov and Anton Baranov from ITSumma talk about optimization ahead of the curve. This is a transcript of the Highload ++ report.
We are engaged in round-the-clock support and administration of web sites. We have been working in Irkutsk since 2008. Now a staff of 50 people. The main office in Irkutsk, there is an office in St. Petersburg and Moscow. At the moment we have more than 200 active customers, with whom we have more than 100 active chats per day. We receive about 150 thousand active alerts per month about the problems of our clients. Among our clients are many different companies, there are well-known: Lingualeo, AlterGeo, CarPrice, Habrahabr, KupiVip, Nashe Radio. There are many online stores. The nature of our classes: we must react within 15 minutes to what has happened, and try to fix it quickly.
')
Where does the trouble come from, are these problems on the servers?
- The main reason is the new version of the application. We posted a new version of the site, updated the code - something broke, everything stopped working, you need to fix it.
- The second is the problems associated with increasing load and scaling. Either this is a project that is growing very quickly, and you need to do something about it. Either this is a project that organized a marketing campaign - Black Friday, many people came, were not ready, everything broke down - you need to scale and prepare for the future.
- The third statistics cause of accidents is very interesting. These are accidents due to project planning architecture errors. That is, the trouble that occurs not because the traffic came and everything fell, not because of an error in the code, but because the project architecture was designed in such a way that it led to an error.
Architecture planning errors
If you look at other industries, today it does not happen that after the construction of the building it collapses. If this happens, it is quite rare. After laying the water supply does not occur such that it breaks immediately. In IT, this happens quite often. Some kind of architecture is being built, and when it is released, it turns out that it does not fit the conditions that were, or it is done for a very long time, or other problems arise.
The IT industry itself is fairly new, not having gained old practices, and any new solutions create additional complexity that reduces the reliability of the operation of these solutions. The more complex the solution, the more difficult it is to exploit.
There is the so-called Law of Lusser . In the 1940s, Germany launched the V-2 missiles in the UK. Some flew exactly, some not. They decided to investigate the reason. It turned out that if you have a lot of different components and you complicate this system, then the complexity of the system (that is, the risk that it may not withstand) is not the likelihood that the system will crash, not the least likelihood of this system not one of the components of this system, but the product of the risk probabilities of each of the components.

If the probability of an accident involving one component is 5% and the other is 20%, then the total risk will not be 20%, but 24%. Everything will be very bad. The more components you have, the more trouble you have.
The reasons for creating complexity
Not every day we see an engineer who builds an offline system and says: “I’ll figure out how to make it harder”. And in development, in operation, we see a lot of situations when we replace the guys or the new team and see a system that is not clear why this was done, except that it was more interesting.
- The first option is a unique solution to this problem. It is impossible to find anywhere, how to solve this problem, what to do about it. We start to think up how to solve it, stepping on a rake, we understand that it needs to be redone and so on.
- Sometimes it happens that there is a solution, but we don’t know it, and we don’t have a chance to find it. Engineers in aeronautical engineering study for a long time, and technologies in IT change so quickly that a university cannot prepare for proven and ready-made practices. You have to learn all over again. Sometimes when creating a solution that was once executed, which is not known, you invent everything anew. Therefore, the system becomes more complicated, you take it to risk and everything becomes bad.
- An interesting case that occurs often enough. IT is one of the few professions where people are very interested in working. There are many very interesting technologies that you can try, there are many things that you want to see. For example, let's try to insert docker in our project. Many people want and try to think of exactly where to try it. As a result, the desire to try a solution of pure interest creates a particular complexity. For example, a plumber does not think when laying a pipe, maybe I will turn it on 4 times, I wonder if suddenly the water will still go to the tap. In IT, we see this quite often.
As a result, when creating this or that solution, we think that everything will be cool, but everything turns out to be much more complicated.

We want on the basis of the examples that we see from life, our practices. Trying to help on what things are not worth attacking and how to live with it.
Consider the development of the project in three categories. That is, how it is from the very start, when it is very small, or even the idea of a project develops to some large, high-loaded project, known throughout the country, around the world.
When you create a project, as a rule, you assume that after the start of the first advertising campaigns, in social networks with 25 subscribers, your attendance will be 3000-5000 RPS.
It is necessary to somehow prepare for this, so that the facilities withstand this attendance. Here we immediately recall, not for nothing at every corner marketers tell us about the clouds. Clouds are very reliable. This is very good, wonderful. Literally everywhere you can hear it.
To dispel this myth, we have provided statistics on the work of uptime Amazon.

Amazon's cloud is one of the fastest growing in the world, and also one of the largest. As you see, there is nothing perfect in this world. Even Amazon has Fails for one reason or another.
We are always told that the cloud is scaled. We can easily from one core, from 1 GB to a heap of cores, a heap of GB of memory to scale the server on which our project is located. In fact, all this is really a myth, because the clouds are located on physical machines, just like everything else. There is a limit, it will consist in the amount of RAM on this machine and the number of cores on this machine. Sooner or later, you will encounter the fact that the cloud will not allow you to scale to the size you need. The most ideal option for your project, even at the time of its launch is a separate dedicated server, nothing more reliable and simpler in this world has yet been invented. Now iron is quite inexpensive and for a little money you can buy a pretty good dedicated server.
What problems do we have on dedicated servers?
At some point, we understand that the project is growing and waiting for the load. Faced with questions that arise. This is a horizontal scaling and reservation project. We need to be sure that in case the main server crashes, the project will continue to work.
What do we do in such cases?
We balance the traffic to the project between several web instances. We also do several database server instances that are replicated and between which the load is balanced.
The main mistake that is made in this case is that all web services are in the same rack. That is, we have several physical web servers that are insured from everything, with one exception. This is all located in one data center, most often within the same rack. Of course, in the event of a fall in the data center, it will not protect against anything.
In this case we come to the conclusion that the backup instances, backup servers should be located in another data center. The second indisputable truth that we must understand. If we have backup instances for which we can send traffic in case of anything, this does not tell us that we have a backup. The most important thing to understand is that virtualization is more a pain than a relief of suffering. Because, as a rule, tangible problems are associated with virtualization, we do not recommend working with them.
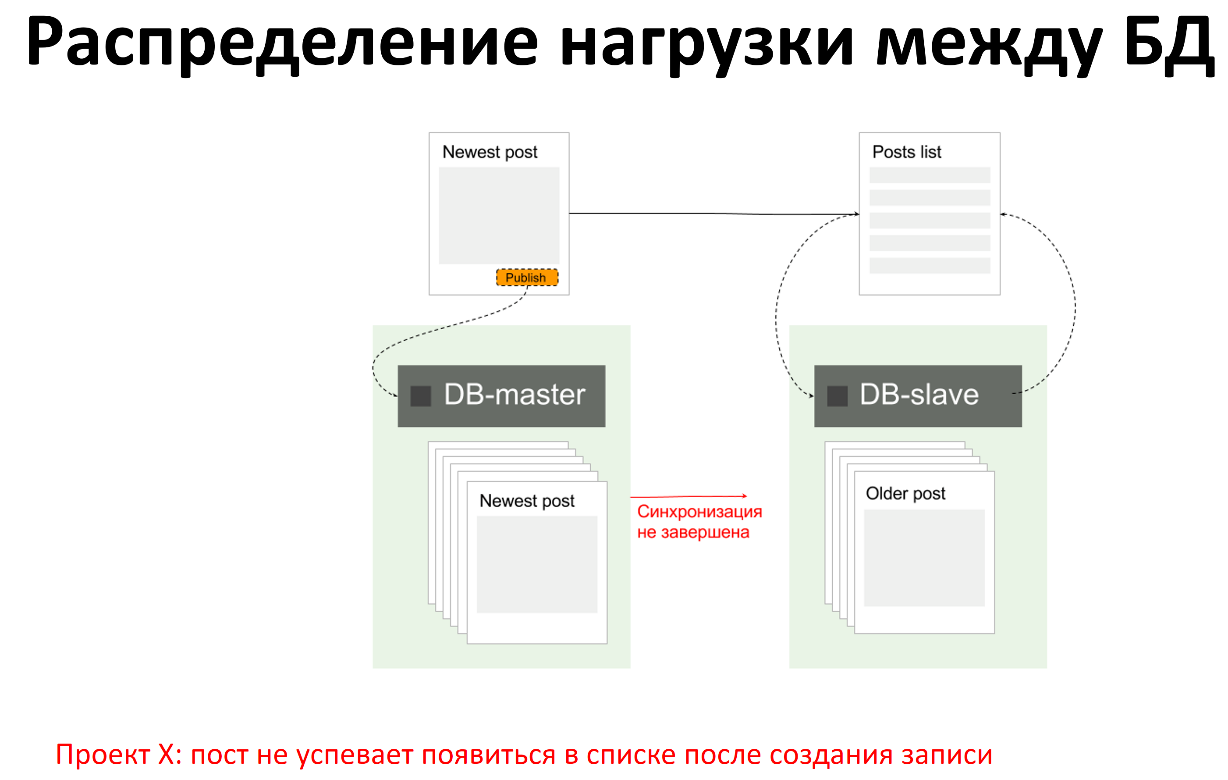
What problems do we have when we use multiple database server instances?
The most common problem, for example, when we have a write to master, is reading from a slave. When we recorded something on the master, at this time the application read something from the slave, but the changes have not yet been replicated and the slave still does not know that we recorded something on the master. In this case, we get irrelevant data from the slave.
In this case, we understand that we need:
- Monitoring replication status (whether it works or not)
- Monitoring replication lag, there are situations that there is replication, but because of the nuances and factors, it has a delay of a day or more
- Monitoring replication consistency (the data on the slave correspond to the data on the master)
Synchronous replication is not sufficient reason to make sure that everything will be fine.
In general, the idea to write something in master, and then read it from a slave is not very good, because of the problems with data integrity. But we often see it, I want to somehow avoid it.
When we use load balancing on a web project between several web nodes, we may have different problems. For example, a single load balancer is often used as an input point, that is, it is pointed to by an A-record, and the traffic through it is balanced between web nodes. In this case, the balancer is the point of failure. If it falls, the project will collapse, because there will be no one to balance the load between the web nodes.
There is such a delicate, delicate moment. Balancing traffic between your web nodes should be configured with failover. That is, when we balance, the application that balances it must constantly poll the web nodes in case some of them fail, then it should be excluded from the balancing process. Otherwise, it may turn out to be a bad situation, when we have half the project loaded and half not. Because to half of the resources were balanced on the web node, which fell 3 hours ago.
What to do with the files?
In our time, when there are a lot of media, pictures, videos on projects. I really want to have a shared storage, which will be connected to all web-nods and each web-nod can separately work with files, write, read. What do in this case?
The simplest and most understandable solution seems to be the use of NFS, this technology for many years, where it is used a lot, everyone has heard it, why not use it? Problems with synchronization were not there, the setting is not easy where. Very often begin to use this technology.
There are global problems with NFS. In the case when we have between servers, between the master NFS web nodes, on which this NFS is mounted, the connection is broken. Or in the case, for example, when we had to reboot the NFS master, we also need to reboot the web nodes. Why? Because, the mount hangs and nothing can be done with this point until the server is restarted physically. This long-standing NFS problem, it is ubiquitous, there is no adequate solution for this, within the framework of NFS.
Separately, an interesting topic, this is how the deployment of projects is organized. In fact, we have 1-2 servers, we have no difficulty to lay out the code with a simple git pull'a and a simple script that will save previous versions of the project in one place, deploy to a new one and replace all the links. But git pull is not very interesting. CI is much more interesting. Very often among our clients, small projects try to implement CI earlier than they need it. It takes a lot of resources to create an advanced deployment system with continuous integration / delivery, which creates additional complexity.
First of all, the most common mistake we see is a cool deployment system. People post the new code and cannot roll back the code with one button, while they have the usual relational bases, they roll up migrations, they do not take into account that these migrations can lead to the fact that the new version of the database will not be able to work with the old code. After laying out the deployment, it becomes clear that it is urgent to roll back, because everything is broken. We roll back to the old code, and the old code cannot work with the new database, but continues to write some data. We again put the new version, in order to somehow survive, we already have data from the old version, which were again recorded, data from the new version, which were also recorded, everything was mixed up and it was not clear how to live. There is an overhead to create, implement and maintain this system.
In fact, we are introducing a new system, we need to check that it works. Check that she herself does not post the code, and does not turn wwwroot into an empty space, as some of our clients had. Additional complexity in terms of deployment, if we have done some sort of calculation system and have not verified that it works well, the same rollback to production. How to check that you roll back? You need to choose the time, and if this project, which is beginning to bring money, then no one wants to put the project at risk, everyone thinks that everything will work, and when necessary we will be able to roll back. As a result, problems are created, be sure to check the ability of the rollback and check that everything works for you. It is better to stick to simple solutions at this stage, upload a new version of the code with the script and live with it.
At the stage when we come to the fact that our project has become medium in size, already rather big, but already not large. The question is brewing here that we need to do something with NFS, what should we replace it with?
From what comes handy, this is CEPH. It can be used, everything is good, the reviews are positive. But CEPH is quite difficult to configure, if you do not know the details, nuances and subtleties in the CEPH setup, then we may face the fact that this file system does not work the way we expect from it. In order to learn how to work with it you need to spend a lot of man-resources, a lot of time. Therefore, you can use something light, for example, MOOSEFS. Why not?
Everything is perfect, it is configured simply, it accumulates some data, the storage is spread over several nods, which are reserved only for storing files, everything is mounted everywhere, everything is great and works. But, a sudden power failure. In the data center, the main channel was cut off, the generator picked up, but a little later than it was necessary for the server not to be cut down.
What happens here?
We have a situation where we have several tens of terabytes of static that are spread over several servers, they must synchronize with each other after a power failure, after they have risen, etc. It took 2 days, we think a lot of files, we think that we need to wait a little longer, 4 days have passed, 90% synchronization of MOOSEFS fell and started to synchronize again. The project is already 5 days without static, it is not very good. We begin to look for a solution to the problem. We find a solution to the problem in the Chinese forum, in which three posts in the thread are devoted to how to fix this file system in a similar situation. There everything is in Chinese, everything is intelligible, there are samples of configs, everything is well written.
The online translator turned the tale a little, but most likely everything is fine. We cannot work with such a file system, which has such support. Therefore, we are still working with MOOSEFS, in case of power failure, we pray and weep. The issue with the choice of replacement is still open.
By this time we already have a deployment system, more or less debugged. These could be scripts, maybe this is CI and it all works. But we have deployment errors, in production they skip occasionally. It happens that prod rolls with 500 errors due to a bug in the code. With what it can be connected?
For example, we have a database on dev and on prod environments, with one subtle nuance. On the prod environment in the database we have 10 gigabytes of data, and on the dev environment there are 50 megabytes. For example, on dev'e there are a thousand entries in the tablets with which we work, and on prod'e a million. Accordingly, when our requests are executed on dev'e, it works out in hundredths of a second, and on prod it can take tens of seconds.
Another subtle point. When we test the code on the dev environment, we test the code on the environment where only this code is tested. There is no third-party load. On the prod'e load is always there. Therefore, you should always bear in mind that the results you received on a dev'e without a load on a prod'e may be different. That is, when the load from your new code coincides with the total system load, the results may not please you.
It also often happens. On dev'e, everything was tested, everything works, the databases are the same, everything is fine, everything should work, the load should not be shaken, everything is fine, with one fine exception, we deploy to prod, and we have a 500 error. Why is that? Because we have not installed any module or any extension, the setting is not registered somewhere. We have different software configurations. This is also worth considering.
This is less common, but occurs. For example, our script works on a dev server on one core, for example, it is 4 GHz, it worked quickly and everything is fine. A prod'e kernels a lot, but they are 2 GHz, the execution time of the code on one core is not the same as it was on the dev server. Such nuances in the difference between the hardware configurations of the dev and prod servers should also be taken into account and made a discount on them.
The stumbling block is a high database load.
This is one of the most common tasks in our practice. How to get rid of the load on the database?
The first thing that comes to mind is to put a more powerful iron. A more powerful processor, more memory, faster disks and the problem will be solved by itself. Not really. Because sooner or later we will rest in this iron and some kind of ceiling will come.
Tuning server. An excellent solution to the problem is when programmers come to the system administrators and say that the database server is not optimally configured. If you correct these settings, everything will be formed, the requests will be executed faster and everything will be better.
All our problems will be corrected by switching to another DBMS. That is, for example, we have MySQL slows down, if we switch to PostgeSQL, and better at MariaDB we will fix all these problems as a class, everything will work quickly, ideally, etc. It is worth looking for the problem to search not in the DBMS, but to dig deeper logically.
What are we doing to understand what is our stumbling block?
What is connected with the fact that the database began to generate a fairly large load and the iron can not cope. We need to collect statistics, to begin to understand what requests are executed the longest. We have accumulated a certain pool of requests in order to analyze them. Some requests form to identify common features, etc.
It is also necessary to compile statistics on the number of requests. For example, if we have a database to slow down only from 3 to 4 by midnight, then maybe the import occurs at this point, where we have the number of inserts in the database increases by an order. It is also worth thinking about data clustering. A vivid example, we have a sign with statistics. Suppose it is stored for the last year. We constantly make selections from it, 95% of these selections concern only the last week. Perhaps it makes sense to cluster the data in this table so that we have 12 different plates, each of them would store data for a specific month. In this case, when we are going to do some sort of sample, we will take data from one label, where there will be a conditional 12 times less records.
The most interesting thing is what happens on large projects.
Because there are not technological errors that we see often, and there are several trends. The project has grown, I want to experiment, I want everything to work by itself, and we can live with it.
The first thing we see is the love of technicians for new technologies. The project is large, everything works clearly, the tasks are regular, I want to come up with something really new. Because people want them to work was interesting. There are several quotes that we take into our tech chat games, where people want to use some kind of technology, but they don’t know what to use it for. We want to use docker and consul in our project. Scatter docker'y services, we will be through the consul who will understand where will go. Consul we put in one of the dockers, if the consul falls we lose everything, but you can live with it.
Let's update the configuration only via chef, if we urgently have to scatter some configuration and somewhere our chef clients fall, we will have to first set up a chef client, but we will be able to update the configuration centrally. But it will be difficult to update something separately on the servers, but it will be good.
Let's make a cluster. This is an interesting joke when people want to make a cluster of something. Let's make a cluster from RabbitMQ and read data from there and from there and everything will be fault tolerant. If one of RabbitMQ falls, the second will live, in fact, not, but that's okay.
Love for new technologies
You can not use technology for the sake of technology. Stop it in some way, but I am sure that it will not stop, because we all want to try new things, but sometimes we have to try to keep ourselves.
In a large project, simple actions become much more complicated. If we know that we want to always use the new software, if on some old project we had, where one server was good, then on the new one everything is update this complex operations and it takes not 2 hours, but it can take several weeks, especially bad , if we decide to do this in production by the developers, not by a well-coordinated team that has thought of how to update it.
The second painful thing that is becoming fashionable right now is the belief that automation works and admins are not needed. Our cluster will be fault tolerant, we will balance between all web servers, and our load-balancers will work. If we do this in the amazon web service, the whole region falls down, all balancers fall down, all instances, everything becomes bad.
"It rebalances itself in the event of an accident." A very frequent thing that we see when the automatic balancing leads to the fact that they have to spread from one place to another, but for some reason they transfer to the same code that is already slowing down, or starts to spread between instances that all slow down together, or just nowhere. The project begins to go into a system that does not exist.
Our stack of technologies completely eliminates this situation. The solution we read about on stackoverflow, reddit'e and Habrahabr cannot lie.
Literally two years ago, I gave a talk here about our experience using OpenStack, when so many companies wanted to use OpenStack, because it's cool to use a piece that allows you to take several large machines and quietly, like in amazon, to throw virtuals on them, and conveniently. Unfortunately, in OpenStack'e of that time, when you launch an instance and delete it, then it will be impossible not to start, not to delete, until you restart several daemons of OpenStack.
We were wondering at what point this is happening. Some work, others do not. Because the guys who said that we have OpenStack works fine, we have 4 people on fulltime who support it. They regularly watch that it works with OpenStack, if it does not work, they begin to repair it quickly. Those people who say that this or that technology works, they either have sufficient resources for this to use this technology, or do not know that this technology can break down and believe in it, or maybe they earn money on it, the same docker gets a huge investment.
How to live with it?
I prefer not to believe that it may not fall by itself, that one way or another it will never break and will rebalance itself. In addition, how to be paranoid, we can not give advice.
Very interesting thing in the work of large projects. The calculations go on constantly, the business wants constant changes. We have done a good project that lives, there is nothing to particularly slow down, so we forget about regular optimizations. One of the clients in one of the calculations finally had a calculation where on one of the pages generated 8 thousand sql queries.
Frequent deployments. They are so private that no change is visible.
What happens in practice?
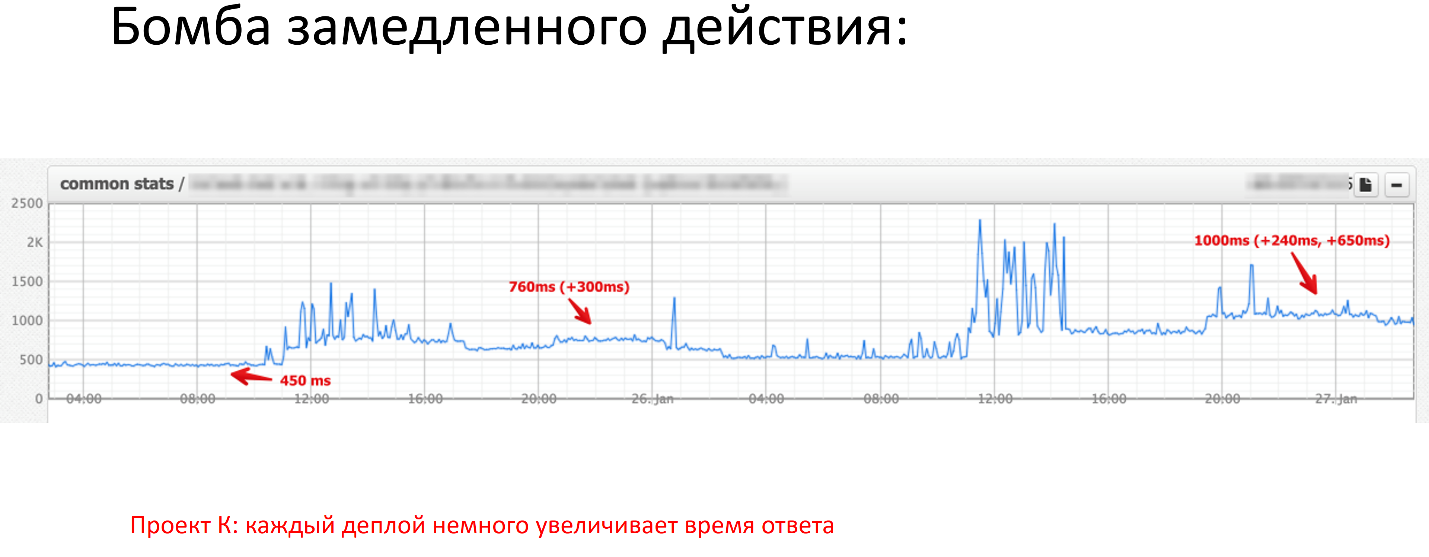
If we look at the chart in the last few hours, we had 3 deployments. The first deployment did only a little, adding 300 milliseconds to the 450 millisecond response, the next deployment added another 240 milliseconds, the next was already a total of 650 milliseconds.
We have already received a second response, everything is bad
Large projects do not check how in the end everything will be on production, not only testing deployment, but also increasing the load with some testing. In fact, many want to do it and learn how to do it, but very few people do. It would be cool if many big projects learn how to load test at least major versions of code calculations.
Instead of conclusions
- Not everything new is good.
- Not all that is interesting is necessary.
- Not all that cool is useful.
In many wisdom, a lot of sadness, because new technologies are cool, when we want to use something, sometimes it really helps. Sometimes you should not be afraid of the new.
Supplement about paranoia in deploy in large projects. When you have a lot of traffic you have the opportunity to test your deploy, how? You can roll out the new code to the server, where you send part of your visitors, conditionally 10%, see if there will be sharp load peaks from the fact that the user starts to poke a button, etc. This kind of deployment scheme, when we do the separation of clients and send part of them as focus groups, send them to a new code, it is quite widely used and can help avoid quite a lot of problems of the main part of clients. Much better to test at 10% than at 100%.
Evgeny Potapov and Anton Baranov - Premature Optimization of Architecture
Source: https://habr.com/ru/post/322242/
All Articles