Development of transactional microservices using Aggregates, Event Sourcing and CQRS (Part 2)

This is the completion of a translation article on the development of transactional applications using the microservice architecture. Start
In the first part of the article, we said that the main obstacle in using the microservice architecture is that domain model (domain model), transactions and requests are surprisingly resistant to separation according to a functional basis. It was shown that the solution is to implement the business logic of each service in the form of a set of DDD units. Each transaction updates or creates a single aggregate. Events are used to maintain data integrity between aggregates (and services).
')
In the second part of the article we will see that the key task in using events is the atomic change of the state of the aggregate and the simultaneous publication of the event. Let's see how to solve this problem using Event Sourcing - using an event-oriented approach to designing business logic and state saving systems. After that, we describe how the microservice architecture makes it difficult to implement queries to the database, and how the approach, called Command Query Responsibility Segregation (CQRS), helps implement scalable and productive queries.
Key points:
- Event sourcing is a mechanism for reliably changing state and publishing events that allows you to overcome the limitations of other solutions.
- Event-oriented approach using Event Sourcing, is in good agreement with the microservice architecture.
- Snapshots can improve the performance of requests for the state of aggregates by combining all the events that occurred before a certain point in time.
- Event sourcing can create problems for queries, but they are overcome with the help of CQRS and materialized views.
- Event sourcing and CQRS do not require any special tools or software; many existing frameworks can take on some of the necessary low-level functionality.
Reliable status update and event publishing
At first glance, ensuring consistency between the aggregates through events seems a fairly simple task. A service, creating or updating an aggregate in a database, simply publishes an event. But there is a problem: updating the database and publishing the event must be done atomically. For example, if something broke after updating the database, but before the event was published, the system would be in an unstable state. The traditional solution in this case are distributed transactions involving a database and a message broker. But, for the reasons described in the first part of the article, distributed transactions are not a viable option.
There are several ways to solve this problem without using distributed transactions. For example, you can use a message broker (like Apache Kafka ).
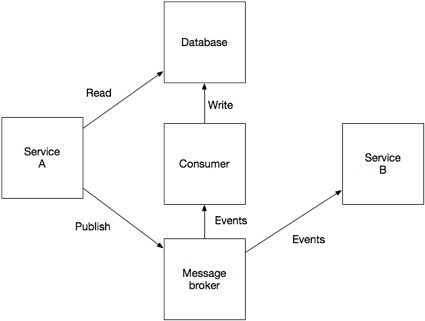
A separate recipient of messages subscribes to the broker's messages, and upon receiving them, updates the database. This approach ensures that both the database is updated and the event is published. Its disadvantage is that it is a much more complex consistency model, in which the application cannot immediately read what it sent itself to write to the database.
Another solution can be the Transaction log tailing pattern : take entries from the transaction log, convert them to events, and send them to the message broker. An important advantage of this approach is that it does not require any changes to the application. The disadvantage, however, is that this can make it difficult to reverse-engineer high-level business events — the reason for updating the database — from low-level changes to rows in tables.

The third solution is to use a database table as a temporary message queue. When a service updates an aggregate, it adds an event to a special table in the EVENTS database within a local transaction. A separate process periodically scans the EVENTS table and publishes events by sending them to a message broker.
A nice feature of this solution is that the service can publish high-level business events. Disadvantage: this approach is potentially error prone since the event publishing code must be synchronized with the business logic.

All three options have significant drawbacks. Publishing events through a message broker with a pending database update does not provide the conditions for the Read-your-writes model. Publishing events based on the transaction log provides consistency in reading data, but it cannot always publish high-level business events. Using a database table as a message queue ensures consistency in reading and publishing high-level business events, but implies that the developer must remember to publish the event when the state changes.
Fortunately, there is another solution. This is an event-oriented approach to state preservation and business logic, known as Event Sourcing.
Development of microservices using Event Sourcing
Event sourcing is an event-oriented approach to state preservation. This is not a new idea. I first learned about Event Sourcing more than five years ago, but it remained a wonder until I started developing microservices. Event sourcing was a great way to implement an event-oriented microservice architecture.
A service that uses Event Sourcing stores the state of the aggregates as a sequence of events. When an aggregate is created or updated, the service stores one or more events in a special event store in the database.
To get the current state of the unit, the events are downloaded and played back. In terms of functional programming, the service reconstructs the current state of the aggregate by performing the fold / reduce functionality on events. Since events are now a state, we no longer have problems with the atomicity of state updates and the publication of events.
Consider, for example, the service Order. Instead of storing each order as lines in the ORDERS table, it stores each unit Order as a sequence of events, such as Order Created , Order Approved , Order Submitted , etc. Here's how it could be stored in an online store on a SQL database.
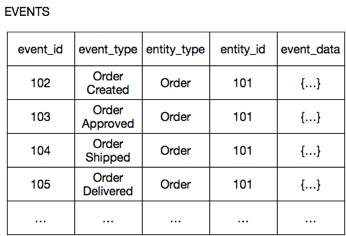
The columns entity_type and entity_id columns are aggregate identifiers.
event_id is the event identifier.
event_type is an event type.
event_data - serialized event attributes in JSON format.
Some events contain a lot of data. For example, the OrderCreated event contains order composition information, billing information, and shipping information. The Order event sent contains a minimum of information and is simply a transition between states.
Event Sourcing and Event Publishing
Strictly speaking, Event Sourcing simply stores the state of the aggregates as events. It is very easy to use as a reliable mechanism for publishing events. Preserving an event is by its nature an atomic operation, which ensures that the event repository will provide access to events to all interested services. For example, if events are stored in the EVENTS table mentioned above, then subscribers can simply periodically poll the table for new events. More complex event repositories will use a different approach, which gives similar guarantees, but is more productive and scalable. For example, Eventuate Local uses the Transaction log tailing pattern. It reads events inserted into the EVENTS table from the MySQL replication stream, and publishes them using Apache Kafka.
Using state snapshots to improve performance
The Order unit is characterized by a relatively small number of transitions between states, and therefore it has only a small number of events. In this case, the request from the event storage and the reconstruction of the current state of the Order aggregate will be effective. However, some units have a large number of events. For example, a Client unit may potentially have multiple Credit Reserved events. Over time, their loading and processing would become inefficient.
A common solution is to periodically save the state of the aggregate snapshot. The application restores the state of the aggregate by loading the last snapshot and only those events that have occurred since its creation. In terms of functional programming, the snapshot is the initial value for fold / reduce. If the aggregate has a simple, easily serializable structure, then the snapshot may be, for example, in JSON format. Pictures of more complex units can be made using the Memento pattern.
For example, the Client unit in an online store has a very simple structure: customer information, its credit limit, and data on the reservation of its loan funds. A Client snapshot is simply a collection of its state data in JSON format. The figure shows how to recreate the state of the Client from the snapshot corresponding to the state of the Client at the time of receipt of the event 103. The client service simply needs to load the snapshot and process the events that occurred after the 103rd.
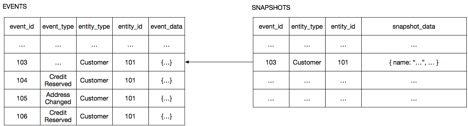
The client service recreates the state of the client, deserializing the snapshot JSON, and then loading and processing events 104 through 106.
Implementing Event Sourcing
The event store is a hybrid database and message broker. It is a database because it has an API for inserting and retrieving event aggregates using the primary key, but it also has a message broker because it has an API for subscribing to events.
There are several different ways to implement an event store. One of them is to create your own event sourcing framework. You can, for example, save events to RDBMS. This is a simple, albeit low-performing way to post events. Subscribers simply periodically poll the table EVENTS for new events.
Another option: use a special event repository, which, as a rule, provides a rich set of functions, higher performance and scalability. Greg Young, a pioneer in event sourcing, created an .NET open source event repository called the Event Store (https://geteventstore.com). Lightbend , formerly known as Typesafe, developed the Lagom microservice framework based on event sourcing. It is possible to note the startup Eventuate , which has an event sourcing framework, which is available as a cloud service, is an open source project and uses Kafka and RDBMS.
Advantages and disadvantages of Event Sourcing
Event sourcing has both advantages and disadvantages. The main advantage of the approach is that events are guaranteed to be published whenever the state of the aggregate changes. This is a good foundation for an event-driven microservice architecture. In addition, since each event can record the identity of the user who made the changes, event sourcing provides an audit log that is guaranteed to be accurate. The event flow can be used for other purposes, including sending notifications to users.
Another advantage of event sourcing is the storage of the entire history of each unit. You can easily implement temporary requests that return the state of the aggregate to the past. In order to determine the state of the aggregate at a particular point in time, you simply need to handle the events that occurred before that moment. For example, you can easily calculate a client's available credit at some point in the past.
By saving the event rather than the aggregate itself, Event sourcing usually avoids the problem of “loss of compliance” (impedance mismatch). Events tend to have a simple, easily-serializable structure. Through serialization, a service can take a snapshot of the state of a complex aggregate. The Memento pattern adds a level of indirection between an aggregate and its serialized representation.
However, in event sourcing technology, not everything is so smooth, and it has some drawbacks. This is another, unusual programming model that needs to be studied. In order for an existing application to start using event sourcing, you need to rewrite its business logic. Fortunately, this is quite a mechanical transformation that can be done when transferring an application to a microservice structure.
Another disadvantage of event sourcing is that the message broker usually guarantees at least one delivery. Event handlers that are not idempotent should independently detect and reject repetitive events. In this case, event sourcing framework can help by assigning an auto-incrementing identifier to each event. The event handler can then detect duplicates by tracking the maximum identifier for the events it has already processed.
Another problem of event sourcing is that the pattern of events (and snapshots!) Will evolve over time. Since events are saved forever, the service may need to process events corresponding to several different versions of the circuit to reconstruct the state of the aggregate. One way to simplify the service is to force the event sourcing framework to bring all events to the latest version of the schema when it loads them from the event store. As a result, the service will only need to process only the latest version of events.
Another disadvantage of event sourcing is that querying an event store can be a complex task by itself. Imagine that you need to find customers who are worthy of a loan with a low credit limit. You can’t just write SELECT * FROM CUSTOMER WHERE CREDIT_LIMIT <? AND CREATION_DATE>? .. There is no column containing a credit limit. Instead, you should use a more complex and potentially inefficient query containing nested SELECTs to calculate the credit limit by processing the event, setting the initial credit limit and then changing it. To make matters worse, NoSQL event repositories usually support searching only by the primary key. Therefore, you must implement queries using the Command Query Responsibility Segregation (CQRS) approach.
Implementing Queries with CQRS
Event sourcing is one of the main obstacles to the implementation of effective queries in the microservice architecture. However, this is not the only problem. Consider, for example, a SQL query that finds new customers who have placed expensive orders.
SELECT * FROM CUSTOMER c, ORDER o WHERE c.id = o.ID AND o.ORDER_TOTAL > 100000 AND o.STATE = 'SHIPPED' AND c.CREATION_DATE > ? In the microservice architecture, you cannot join the CUSTOMER and ORDER tables in one query. Each table belongs to its own service and is available only through the API of this service. You cannot write traditional queries that join tables belonging to different services. Event sourcing exacerbates the situation by making it difficult to write simple direct requests. Let's look at the method of implementing requests in the microservice architecture.
Use CQRS
A good way to implement queries is to use an architectural pattern known as Command Query Responsibility Segregation ( CQRS ). The application is divided into two parts:
- the command part processes commands (for example, HTTP POST, PUT, DELETE) to create, update and delete aggregates. Of course, these units are implemented using Event sourcing.
- The request part of the application processes requests (for example, HTTP GET), requesting one or more materialized views of the aggregates. The request part maintains views synchronized with aggregates by subscribing to events published by the command part.
Depending on the requirements, the request part of the application may use one or more of the following databases:
| If you need | Then use | for example |
|---|---|---|
| Search JSON objects by primary key | A document- oriented database, for example, MongoGB , or a key-value data repository, for example, Redis . | Implementing an order history using a MongoDB customer document containing all of its orders. |
| Regular search for JSON objects | Document-oriented database, for example, MongoGB. | Implementing a view for clients using MongoDB. |
| Full text search | Full-text search engine, for example, Elasticsearch . | Implement full-text search in orders using Elasticsearch documents for each order. |
| Graph query | Graph database management system, for example, Neo4j . | Implement a fraud detection system using customer graph, orders and other data. |
| Traditional SQL Queries | RDBMS | Standard business reports and analytics. |
In many ways, CQRS is a more general event-oriented version of the widely used approach of using RDBMS as a data warehouse and search engine for full-text search (like Elasticsearch). CQRS uses a wider range of database types, rather than full-text search engines. In addition, by subscribing to events, it updates the views of the request part of the application in almost real time.
The following illustration shows the CQRS scheme for an online store.
Customer Service and Order Service are included in the command part of the application. They provide APIs for creating and updating customers and orders. Customer View Service is included in the request part. It provides an API for retrieving customer data using queries.

The Customer View Service subscribes to events posted by the command part of the application, and updates the view repository implemented in MongoDB. The MongoDB collection contains documents, one for each client. Each document has attributes that describe a particular customer, as well as an attribute with the latest customer orders. This collection supports a variety of requests, including the above.
Advantages and disadvantages of CQRS
The main advantage of CQRS is that thanks to it, it is possible to implement requests in the microservice architecture, especially those using event sourcing. This allows the application to efficiently support a diverse set of requests. Another advantage is that the division of responsibility often simplifies the command and request part of the application.
One of the drawbacks is that CQRS requires additional efforts to develop and operate the system. It is necessary to create and deploy a request part service that can update views and query them. In addition, you need to deploy a repository of views.
Another disadvantage of CQRS is related to the time lag between teams and requests. As one would expect, there is a delay between the moment when the command part updates the aggregate and when the views of the request part are ready to reflect these changes. The client application that updates the aggregate and then immediately makes a request using views can see the previous version of the aggregate. Therefore, the application must be written in such a way as to prevent the user from receiving this potential inconsistency.
Summary
One of the main problems in using events to maintain data integrity between services is the atomic update of the database and the simultaneous publication of events. The traditional solution is to use distributed transactions using a database and message broker. However, this approach is not viable for modern applications. The best solution is to use Event sourcing, an event-oriented approach to designing business logic and state preservation systems.
Another problem in the microservice architecture are requests. They often need to combine data belonging to several services. However, joins are no longer so easy to use, since the data is private for each service. Event sourcing makes it even more difficult to effectively implement queries, since the current state is not stored by itself. The solution is to use CQRS and keep one or more materialized views up to date, which you can easily query.
Source: https://habr.com/ru/post/322214/
All Articles