MySQL dacherization in Uber

The Schemaless storage system developed by Uber engineers is used in several of the most important and large services of our company (for example, Mezzanine ). Schemaless is a scalable and fault-tolerant data warehouse that runs on MySQL clusters. When these clusters were 16, managing them was an easy task. But at the moment we have more than 1,000 of them, and at least 4,000 database servers are deployed in them. Managing such a system requires a completely different class of tools.
Of the many components included in Schemadock, a relatively small, but very important part is Docker. The transition to a more scalable solution has become a landmark event for us, and in this article we talked about how Docker helped us achieve this.
Initially, we used Puppet , various scripts to manage all the clusters, and also did many things manually. But the faster Uber grew and the more it became, the more difficult it was to continue using this approach. Therefore, we began to look for more convenient tools for managing MySQL clusters. The main requirements were as follows:
- Work multiple database servers on the same host.
- Full automation.
- Single entry point to organize management and monitoring of all clusters in all data centers.
As a result, a solution was born called Schemadock. Now our MySQL servers run in Docker containers that are managed by target states that define the cluster topology using configuration files. They may indicate that, for example, in cluster “A” there should be 3 servers, and which of them should become a master. Applying the appropriate roles to individual servers is performed by special agent programs. The unified service monitors the target states of all servers and in case of deviations from the norm performs the necessary actions to correct the situation.
Why docker?
Containers simplify the task of running multiple MySQL processes with different versions and configurations on the same host. It also allows several small clusters to be located on the same machine, which ultimately makes it possible to use a smaller number of hosts with the same number of clusters. Finally, we no longer depend on Puppet and have the same host settings.
As for Docker himself: at present, our engineers create all stateless services based on it, so we know this system well. Of course, it is not perfect, but at the moment it is the best alternative for us.
What is in addition to Docker?
The alternatives to Docker are as follows: full virtualization, LXC containers , as well as managing MySQL processes directly using, for example, Puppet. We didn’t choose for a very long time, because Docker had the best fit to the existing infrastructure. However, if we had not used Docker before, its implementation only for MySQL could be a rather large project, for which it would be necessary to master the creation and distribution of images, monitoring and updating Docker itself, collecting logs, networking features, and much more. .
This means that a Docker deployment requires resources and time. Moreover, Docker should be considered as a technology and should not be expected to solve all problems from it. We at Uber have very carefully approached the design of the MySQL database management system, where Docker is only one of the components. But not all companies have reached the scale of Uber, so they can better approach the option using Puppet, Ansible or similar software.
Image for Schemaless
Basically, our image only loads and installs Percona Server , and it also starts mysqld - almost the same thing that a standard Docker image with MySQL does onboard. However, several more operations are performed between download and installation.
- If there is no data on the mounted volume, then an initial download is required. For the master we start mysql_install_db, and also we create several standard users and tables. For a replica (minion in the terminology of Uber - approx. Transfer), we start loading data from a backup or another node in the cluster.
- Mysqld will be launched immediately after the data has been loaded.
- If copying data for some reason does not end, the container will be stopped.
The role of the container is set using environment variables. It is worth paying attention to the data acquisition mechanism - the image itself does not contain any logic for setting up replication topologies, status checking, etc. Since this logic changes more often than MySQL itself, it is very reasonable to separate them.
The MySQL data directory is mounted from the host's file system, which means there is no record-based overhead for the Docker. We still write the MySQL configuration into the image, which makes it unbutable. Although the configuration itself can be edited, these changes will never take effect, since we do not reuse the containers. If the container stops for any reason, it will not be used again. We delete the container, create a new one from the most recent image, using the same parameters (or new if the target state has changed since then), and run it.
This approach gives us the following benefits:
- It becomes much easier to control the configuration drift. The problem comes down to the version numbers of the Docker images, which we monitor closely.
- Much easier to update MySQL. We create a new image, and then stop the containers in order.
- If something breaks, it just restarts. We remove the problematic container and start a new one without trying to repair anything.
The same infrastructure is used for creating images, which ensures the operation of stateless-services. It also replicates the images between data centers to make them available in local registries.
There are drawbacks in the work of several containers on one host. Since there is no normal I / O isolation between containers, any of them can use all the bandwidth of the I / O system, which will adversely affect the work of other containers. I / O quotas appeared in Docker 1.10, but we have not yet had time to experiment with them. While we are struggling with this problem by controlling the number of containers on the host and constantly monitor the performance of each database.
Configuring containers and topologies
Now that we have a Docker image that can be configured as a master or replica, something needs to run the containers and configure the required replication topology on them. To do this, a special agent is launched on each host, which receives end-state information for all databases. A typical description of the final state is as follows:
“schemadock01-mezzanine-mezzanine-us1-cluster8-db4”: { “app_id”: “mezzanine-mezzanine-us1-cluster8-db4”, “state”: “started”, “data”: { “semi_sync_repl_enabled”: false, “name”: “mezzanine-us1-cluster8-db4”, “master_host”: “schemadock30”, “master_port”: 7335, “disabled”: false, “role”: “minion”, “port”: 7335, “size”: “all” } } Here it says that one replica of the Mezzanine database (port 7335) must be running on the schemadock01 host; the base for the schemadock30: 7335 should become the master for it. The size parameter is set to all. This means that this database is the only one on schemadock01, and it must use all the available memory.
The procedure for creating such a description of the target state is a topic for a separate publication, so we move on to the next steps: an agent running on a host receives and stores the description of the target state locally, and then starts processing it.
Processing is an infinite loop that runs every 30 seconds (something like Puppet running every half minute). The loop checks the compliance of the current and target states. For this, the following actions are performed:
- Check if the container is running. If not, create and run.
- Check container replication topology. If something is wrong with her, try to fix it.
- If it is a replica, but must be a master, make sure that the role change is safe. To do this, check whether the current master read-only status is set, and also whether all GTIDs are received and applied. If all conditions are met, you can remove the link to the previous wizard and enable the ability to record.
- If it is a master that should be disabled, enable read-only mode.
- If it is a replica, but replication is not performed, set up replication.
- Check various MySQL parameters (read_only and super_read_only, sync_binlog, etc.) according to the base role. On the wizards, write must be enabled, replicas must be read_only, etc. Moreover, we reduce the load on replicas by turning off binlog fsync and similar parameters².
- Start or stop all ancillary containers, such as pt-heartbeat and pt-deadlock-logger .
It is important to note that we are convinced supporters of the idea of “one process - one goal - one container”. In this case, we do not have to reconfigure working containers, and the upgrade is also much easier.
If any error occurs, the process generates a corresponding message and ends, and the whole procedure is repeated again during the next attempt. We try to configure the system in such a way as to minimize the need for coordination between agents. This means that we do not care about the order when initializing a new cluster, for example. If you do this operation manually, then you need to perform about the following steps:
- create a mysql master and wait until it is ready to work,
- create the first replica and connect it to the master,
- repeat the previous paragraph for the remaining replicas.
In the end, something like this is still happening. But at the same time, we absolutely do not care about the order in which the steps are taken. We only create target states that describe the configuration we need:
“schemadock01-mezzanine-cluster1-db1”: { “data”: { “disabled”: false, “role”: “master”, “port”: 7335, “size”: “all” } }, “schemadock02-mezzanine-cluster1-db2”: { “data”: { “master_host”: “schemadock01”, “master_port”: 7335, “disabled”: false, “role”: “minion”, “port”: 7335, “size”: “all” } }, “schemadock03-mezzanine-cluster1-db3”: { “data”: { “master_host”: “schemadock01”, “master_port”: 7335, “disabled”: false, “role”: “minion”, “port”: 7335, “size”: “all” } } This information is sent to the appropriate agents in random order, and they begin to perform the task. To achieve the target state, depending on the order, it may take several attempts. Usually there are not many of them, but some operations are restarted hundreds of times. For example, if the replicas start up first, they will not be able to connect to the master and will have to try to do it again and again until it comes online (which can take a long time):
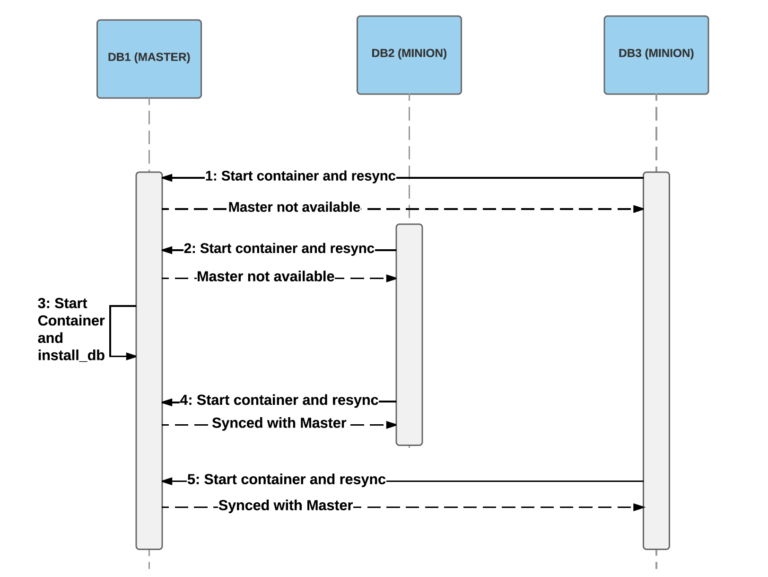
An example in which two replicas started before the master. In steps 1 and 2, they will not be able to get a snapshot from the wizard, so the startup process will fail. When the wizard finally starts (in step 3), the replicas will be able to connect and synchronize the data (steps 4 and 5).
Work in the Docker environment
Most of our hosts have Docker 1.9.1 installed with devicemapper on LVM . Using LVM for devicemapper turned out to be a more productive solution than loopback. Devicemapper has a lot of performance and reliability issues, but alternatives such as AuFS and OverlayFS are also far from ideal³. The community could not decide for a long time which variant of storage organization is better. But lately, more and more voices have been voiced in favor of OverlayFS, which also seems to have stabilized, so we are going to switch to this file system and at the same time upgrade to Docker 1.12.1.
One of the disadvantages of Docker is the requirement to restart containers when the service is restarted. This means that we need to control the update process, as we will not have working wizards during the update of the host. Fortunately, Docker v1.12 added the option to reboot and update the daemon without restarting the containers, so we hope that we will have to deal with this problem for the last time.
In every next version of Docker, there are a lot of improvements and new features, as well as a decent amount of errors. 1.12.1 seems to be better than the previous ones, but we still face certain problems:
- Sometimes the docker inspect hangs after the Docker has been working non-stop for several days.
- Using bridge networking with userland proxy leads to strange behavior when terminating TCP connections. Client connections sometimes do not receive the RST signal and remain open regardless of the timeout set.
- Container processes are sometimes reassigned to pid 1 (init), and Docker loses them.
- There are regular cases when the Docker daemon creates new containers for a very long time.
Conclusion
We began by defining a list of requirements for a storage cluster management system in Uber:
1) several containers on one host,
2) automation,
3) single entry point.
Now we can perform daily maintenance using a single user interface and simple tools, none of which require direct access to hosts:

Screenshot of our management console. Here you can see the process of reaching the target state: in this case, we divide the cluster into two parts, first adding the second cluster, and then breaking the replication link.
Due to running multiple containers on the same host, we more fully use computing resources. It became possible to perform a controlled update of the entire fleet. With the help of Docker, we quickly managed to achieve this. Docker also allows you to start the installation of the entire cluster in a test environment, which can be used to test various operational procedures.
We started the migration to Docker in early 2016, and now we have about 1,500 Docker production servers running (for MySQL only), which have about 2,300 MySQL databases deployed.
There are many other components in Schemadock, but Docker helped us a lot. With him, we got the opportunity to quickly move forward, experimenting a lot in close connection with the existing Uber infrastructure. The travel repository, which adds several million entries per day, is now based on documented MySQL databases (shared with other information repositories). In other words, now without Docker, Uber users literally will not get far.
Joakim Recht is a full-time software engineer at Uber Engineering's Aarhus office, as well as Schemaless infrastructure automation engineering.
¹ To be precise, Percona Server 5.6
² sync_binlog = 0 and innodb_flush_log_at_trx_commit = 2
³ A small collection of problems: https://github.com/docker/docker/issues/16653 , https://github.com/docker/docker/issues/15629 , https://developerblog.redhat.com/2014/09 / 30 / overview-storage-scalability-docker / , https://github.com/docker/docker/issues/12738
')
Source: https://habr.com/ru/post/322142/
All Articles