Introduction to lock-free programming

In this post, we would like to once again raise the topic of programming without blocking, first defining it, and then select a few key points from the variety of information. We will show how these provisions relate to each other, using block diagrams, and then we touch on the details a little. The minimum requirement for a developer who comprehends lock-free is the ability to write the correct multi-threaded code using mutexes or other high-level synchronization objects, for example, semaphores or events.
Lock-free programming is a kind of test, and not so much because of the complexity of the task itself, but because of the difficulty of comprehending the essence of the subject.
I was lucky to get the first insight into the lock-free of Bruce Dawson's excellent detailed article “ Lockless Programming Considerations ”. And like so many others, I happened to apply Bruce's advice in practice, developing and debugging an unblocking code on platforms such as the Xbox 360.
')
Since then, many good works have been published, starting with abstract theory and proof of correctness and ending with practical examples and details of the hardware level. I will give a list of links in the notes. Sometimes the information in one source contradicts another, for example, some works assume sequential consistency (sequential consistency), which avoids the problems of memory ordering (memory ordering) - a real disaster for C / C ++ code. At the same time, the new library of atomic operations of the C ++ 11 standard makes you look at the problem in a new light and abandon the usual way of presenting lock-free algorithms.
What is it?
Non-blocking programming is usually described as programming without mutexes, also called locks . This is true, but it is only part of the picture. The generally accepted definition based on academic literature is slightly broader. “Without locks” is essentially a certain property that allows you to describe the code, without going into details about how it is written.
As a rule, if a part of your program satisfies the conditions listed below, then this part can be considered lock-free. And vice versa, if this part does not satisfy these conditions, it will not be lock-free.
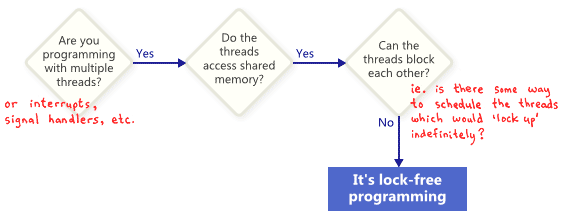
Translation: Do you work with multiple threads (interrupts, signal handlers, etc.)? - Yes. - Do threads have access to shared memory? - Yes. - Can threads block each other (in other words, can you schedule flows so that they are blocked indefinitely)? - Not. - This is non-blocking programming.
In this sense, the term lock in a lock-free does not refer directly to mutexes, but rather to the possibility that the application itself will somehow be blocked, be it a deadlock, a dynamic deadlock, or hypothetical planning. streams performed by your worst enemy. The last point may seem funny, but it is the key. Shared mutexes can easily be disabled: as soon as a single thread receives a mutex, your adversary may simply never again plan this stream. Of course, real operating systems do not work this way until we simply define the terms.
Here is a simple example of an operation that does not contain mutexes, but still is not lock-free. Initially, X = 0. As an exercise, think about how to plan the two threads so that none of them can get out of the loop.
while (X == 0) { X = 1 - X; } No one expects a large application to be completely lock-free. Usually, we select a subset of lock-free operations from all of the code. For example, in a nonblocking queue there may be a number of nonblocking operations:
push , pop , perhaps isEmpty , etc. Hirliha and Shavit, the authors of The Art of Multiprocessor Programming , tend to represent such operations as class methods and propose the following brief definition of lock-free: "With infinite execution, infinitely often, the called method always ends." In other words, as long as the program can call such lock-free operations, the number of completed calls will increase. During such operations, locking the system is algorithmically impossible.
Hirliha and Shavit, the authors of The Art of Multiprocessor Programming , tend to represent such operations as class methods and propose the following brief definition of lock-free: "With infinite execution, infinitely often, the called method always ends." In other words, as long as the program can call such lock-free operations, the number of completed calls will increase. During such operations, locking the system is algorithmically impossible.One of the important consequences of non-blocking programming: even if one thread is in a state of waiting, it will not interfere with the progress of the other threads in their own lock-free operations. This determines the value of non-blocking programming when writing interrupt handlers and real-time systems, when a specific task must be completed within a limited time, regardless of the state of the rest of the program.
Last clarification: operations specifically designed for blocking do not deprive the algorithm of lock-free status. For example, a pop operation of a queue may be intentionally blocked if the queue is empty. The remaining paths will still be considered non-blocking.
Non-locking programming mechanisms
It turns out that in order to satisfy the non-blocking condition, there is a whole family of mechanisms: atomic operations, memory barriers, and the avoidance of ABA problems are just some of them. And at this moment everything becomes hellishly difficult.
How do all these mechanisms relate? For illustration, I have drawn the following flowchart. Decipher every block below.
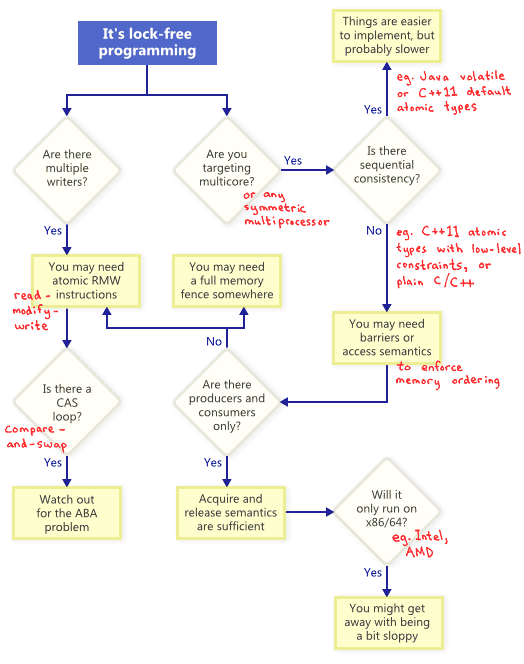
Atomic change operations (RMW, read-modify-write)
Atomic operations are operations that perform indivisible memory manipulations: no thread can observe such an operation at an intermediate stage of execution. In modern processors, many operations are already atomic. For example, usually are atomic aligned read / write operations of simple types.
 RMW operations go even further, allowing atomically to perform more complex transactions. They are especially useful when the non-blocking algorithm has to support several streams for writing, because if you try several streams to execute RMW at one address, they will promptly line up and perform these operations one by one. I already touched on RMW in this blog when I talked about the implementation of a lightweight mutex , a recursive mutex, and a lightweight logging system .
RMW operations go even further, allowing atomically to perform more complex transactions. They are especially useful when the non-blocking algorithm has to support several streams for writing, because if you try several streams to execute RMW at one address, they will promptly line up and perform these operations one by one. I already touched on RMW in this blog when I talked about the implementation of a lightweight mutex , a recursive mutex, and a lightweight logging system .Examples of RMW operations:
_InterlockedIncrement in Win32, OSAtomicAdd32 in iOS and std::atomic<int>::fetch_add in C ++ 11. Please note that the standard of atomic operations C ++ 11 does not guarantee that the implementation will be lock-free on any platform, so it is best to explore the capabilities of your platform and toolkit. For confidence, you can call std::atomic<>::is_lock_free .Different processor families support RMW differently . Processors such as PowerPC and ARM provide LL / SC instructions (load-link / store-conditional, load with mark / write attempt), which allows you to implement your own RMW transaction at a low level, although this is not often done. Ordinary RMW is usually sufficient.
As shown in the block diagram, atomic RMW is a necessary part of non-blocking programming, even on single-processor systems. Without atomicity, a thread can be interrupted in the middle of a transaction, which can lead to an inconsistent state.
Compare-And-Swap Cycles
Perhaps the most talked about RMW operation is compare-and-swap (CAS). In Win32, CAS is available using a family of built-in functions, such as
_InterlockedCompareExchange . Developers often run compare-and-swap in a loop to retry attempts to execute a stantation. This scenario usually involves copying a shared variable to a local one, doing some work on it and trying to publish the changes using CAS. void LockFreeQueue::push(Node* newHead) { for (;;) { // Copy a shared variable (m_Head) to a local. Node* oldHead = m_Head; // Do some speculative work, not yet visible to other threads. newHead->next = oldHead; // Next, attempt to publish our changes to the shared variable. // If the shared variable hasn't changed, the CAS succeeds and we return. // Otherwise, repeat. if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead) return; } } Such cycles are also considered lock-free, since if the test did not pass in one thread, it means that it should have passed in another, although some architectures offer a weaker version of CAS , where this is not always the case. During the implementation of the CAS cycle, you should try to avoid ABA problems .
Sequential consistency
Sequential consistency means that all threads agree with the order in which memory operations were performed, and that this order corresponds to the order of operations in the source code of the program. With consistent consistency, we will not suffer from memory reordering tricks like the one I described in the previous post .
A simple (but obviously impractical) way to achieve consistent consistency is to turn off compiler optimizations and run all threads on a single processor. The memory of one processor will never be in disarray, even if the threads are scheduled for a random time.
Some programming languages provide consistent consistency even for optimized code executed on multiple processors. In C ++ 11, you can declare shared variables as C ++ 11 atomic (atomic) types that provide ordering. In Java, you can mark all shared variables as
volatile . Here is an example from my previous post , rewritten in the style of C ++ 11: std::atomic<int> X(0), Y(0); int r1, r2; void thread1() { X.store(1); r1 = Y.load(); } void thread2() { Y.store(1); r2 = X.load(); } Since the atomic types of C ++ 11 ensure consistent consistency, it is impossible to get r1 = r2 = 0 at the output. To get the desired result, the compiler adds additional instructions — usually these are memory barriers or RMW operations. Because of these additional instructions, the implementation may be less efficient than the one where the developer works with memory sequencing directly.
Memory ordering (memory reordering)
As suggested in the flowchart, each time a lock-free development for a multi-core (or any other SMP -) system, when your environment does not guarantee consistent consistency, you need to think about how to deal with the problem of memory reordering .
In modern architectures, there are three groups of tools that ensure correct memory ordering at both the compiler level and the processor level:
- Lightweight instructions for synchronization and memory barriers, which I will discuss in future posts ;
- The complete instructions of the memory barriers that I have demonstrated before ;
- Memory operations based on acquire / release semantics (semantics of resource capture / release).
Acquire semantics provides memory ordering for subsequent operations, release semantics for previous ones. These semantics are partially suitable for the case of producer / consumer relations, when one thread publishes information and another reads it. We will discuss this in more detail in a future post .
Different processors have different memory models.
When it comes to memory reordering, all CPU families have their own habits . The rules are fixed in the documentation of each manufacturer and are strictly followed in the manufacture of iron. For example, PowerPC or ARM processors can change the order of instructions themselves, while the x86 / 64 family from Intel and AMD usually do not. It is said that the former have a weaker memory model .
There is a great temptation to abstract from these low-level details, especially when C ++ 11 provides us with a standard way to write portable code without blocking. But I think that at present most lock-free developers have at least some idea of the difference in hardware platforms. The key difference that is definitely worth remembering is that, at the instruction level in x86 / 64, each load from memory occurs with acquire-semantics, and each entry in memory - with release-semantics - at least for non-SSE instructions and not for write-combining memory. As a result, earlier quite often they wrote lock-free code that worked on x86 / 64, but fell on other processors .
If you are interested in technical details of how and why processors reorder the memory, I recommend reading Appendix C in Is Parallel Programming Hard . In any case, do not forget that the reordering of memory may also occur due to the fact that the compiler reordered the instructions.
In this post, I almost did not touch the practical side of programming without locks, for example, when should they be engaged? How much do we need it? I also did not mention the importance of testing your lock-free algorithms. Nevertheless, I hope that this introduction has allowed some readers to become familiar with the basic principles of lock-free, so that they can go deeper into the subject without feeling completely at a loss.
Additional links

- Anthony Williams blog and his book C ++ Concurrency in Action
- The site of Dmitriy V'jukov and various forum discussions
- Bartosz Milewski Blog
- Low-Level Threading series in the Charles Bloom blog
- Doug Lea, JSR-133 Cookbook
- Howells and McKenney, memory-barriers.txt document
- Hans Boehm, a collection of references on the C ++ 11 memory model
- Herb Sutter, Effective Concurrency series
Source: https://habr.com/ru/post/322094/
All Articles